이 글에 대해서
- 현재 토이 프로젝트로 그룹 지도 서비스를 개발하고 있습니다.
- https://github.com/squad-map/squad-map-project/tree/BE
- API 성능 테스트와 기본적인 실수에서부터 비롯된 성능 개선 과정에 대한 기록입니다.
테스트를 진행하기 앞서서 더미 데이터 삽입
- 회원 500명
- 지도 1,000개 (회원당 2개)
- 그룹멤버 1,000개(지도 주인 ‘HOST’ 권한 데이터)
- 카테고리 10,000개 (지도당 10개)
- 장소 1,000,000 개 (지도당 1000개, 카테고리당 100개)
테스트하고자 하는 API
-
/map/public
- 전체 공개 지도 리스트에 대해서 조회하는 API
- 페이징 정보 및 지도에 대한 정보 리스트를 반환하는 API
-
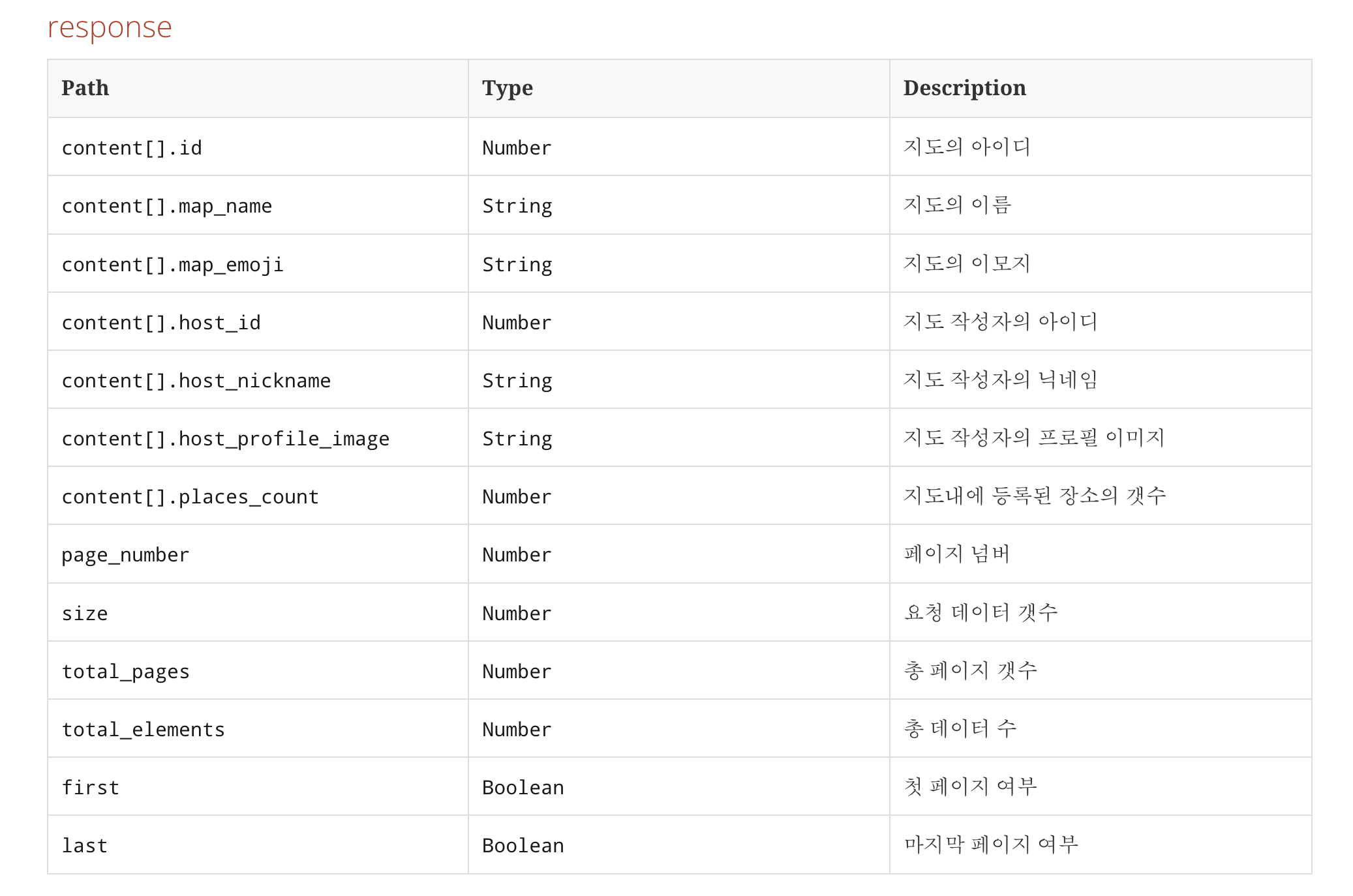
Response body 예시
{
"page_number" : 0,
"size" : 10,
"total_pages" : 1,
"total_elements" : 1,
"first" : true,
"last" : true,
"content" : [ {
"id" : 1,
"map_name" : "changed map",
"map_emoji" : "U+1F600",
"host_id" : 1,
"host_nickname" : "nickname",
"host_profile_image" : "image",
"places_count" : 2
} ]
}- restdocs API Response Body 명세
Test script tip
- Test script를 작성할 때, Grooy를 사용해보지 않았다면 꽤나 불편하다.
- Java와 매우 흡사해서 대부분의 메서드들이 Java와 비슷하게 작동하고, Web에서 Validate 버튼을 통해서 코드를 확인할 수는 있다.
- 그래도 IDE의 도움을 받고 싶다면, Intellij에서 gradle 프로젝트로 Groovy 언어를 추가하고 생성
- build-gradle 파일에 ngrinder-core 의존성 버전에 맞게 추가
- https://mvnrepository.com/artifact/org.ngrinder/ngrinder-core
Test script logic
- 테스트 하고자 하는 API의 경우 비로그인 사용자도 호출 가능
- pageNumber와 size에 대해서만 랜덤으로 호출하도록 조작
- size를 30으로 제한을 두었지만, 랜덤이기 때문에 사이즈가 30에 가깝게 나오는 비율이 높다면 테스트 작동 때마다 비교적 더 많은 데이터를 당겨오기에 테스트 결과에서 차이를 조금씩 보일 수 도 있다.
import static net.grinder.script.Grinder.grinder
import static org.junit.Assert.*
import static org.hamcrest.Matchers.*
import net.grinder.script.GTest
import net.grinder.script.Grinder
import net.grinder.scriptengine.groovy.junit.GrinderRunner
import net.grinder.scriptengine.groovy.junit.annotation.BeforeProcess
import net.grinder.scriptengine.groovy.junit.annotation.BeforeThread
// import static net.grinder.util.GrinderUtils.* // You can use this if you're using nGrinder after 3.2.3
import org.junit.Before
import org.junit.BeforeClass
import org.junit.Test
import org.junit.runner.RunWith
import org.ngrinder.http.HTTPRequest
import org.ngrinder.http.HTTPRequestControl
import org.ngrinder.http.HTTPResponse
import org.ngrinder.http.cookie.Cookie
import org.ngrinder.http.cookie.CookieManager
/**
* A simple example using the HTTP plugin that shows the retrieval of a single page via HTTP.
*
* This script is automatically generated by ngrinder.
*
* @author admin
*/
@RunWith(GrinderRunner)
class TestRunner {
public static GTest test
public static HTTPRequest request
public static Map<String, String> headers = [:]
public static Map<String, Object> params = [:]
public static List<Cookie> cookies = []
public static Random random = new Random()
@BeforeProcess
public static void beforeProcess() {
HTTPRequestControl.setConnectionTimeout(300000)
test = new GTest(1, "127.0.0.1")
request = new HTTPRequest()
headers.put("Content-Type", "application/json")
grinder.logger.info("before process.")
}
@BeforeThread
public void beforeThread() {
test.record(this, "test")
grinder.statistics.delayReports = true
grinder.logger.info("before thread.")
}
@Before
public void before() {
request.setHeaders(headers)
CookieManager.addCookies(cookies)
grinder.logger.info("before. init headers and cookies")
}
@Test
public void test() {
String path = "http://127.0.0.1:8080/map/public?page=%d&size=%d"
int[] arr = getRandomPageAndSize(getRandomSize())
int pageNumber = arr[1]
int size = arr[0]
String uri = String.format(path, pageNumber, size);
HTTPResponse response = request.GET(uri)
if (response.statusCode == 301 || response.statusCode == 302) {
grinder.logger.warn("Warning. The response may not be correct. The response code was {}.", response.statusCode)
} else {
assertEquals(response.statusCode, is(200))
}
}
public int getRandomSize() {
int limit = 29
return random.nextInt(limit) + 1;
}
public int[] getRandomPageAndSize(int size) {
int[] arr = new int[2]
arr[0] = size
int count = 500
int pageLimit = count / size
int page = random.nextInt(pageLimit)
arr[1] = page
return arr
}
}테스트 설정
- Agent 1
- Vuser 102 (Process 3 / Thread 34)
- 3분간 실행
- Ramp-up(부하를 점진적으로 가중시키는 기능) 사용 X
실행환경
- Mac M1 Ram 16GB
- ngrinder-controller, ngrinder-agent, WAS(Spring boot), DB(docker - MySQL 8.0.22) 모두 로컬환경
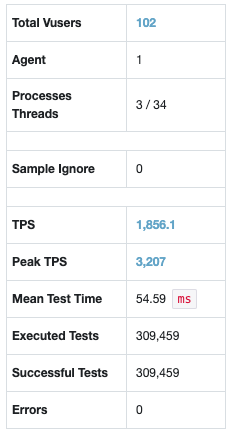
처참한 테스트 결과
-
TPS : (Tests Per Seconds) 7.5
-
Mean Test Time : 13.324.42ms (약 13.3초)
-
TPS 그래프 또한 안정적인 그래프를 지향해야하는데, 아주 들쭉날쭉하다.
-
실제 서비스라고 생각한다면…. 아찔하다.
-
포스트맨으로 간단히 API 호출을 했을때, API 응답속도는 704ms

사실 이 테스트의 목적은 ngrinder의 사용법을 익히는것과…
- 인덱싱 또는 쿼리 튜닝 해보기
- 그리고 Caching을 적용 전에 대한 성능을 기록하고자 시작한 테스트이다.
아주 익사이팅한 결과의 이유 찾아보기
- Controller에서의 로직

-
name 파라미터가 들어오면 name에 해당하는 지도를 검색해서 반환한다.
-
부하테스트에서는 검색조건이 없는 전체 리스트를 조회했다.
-
이름 검색 또한 들어가면…
%name%형태의 like 쿼리인데 index가 작동하지않아, 풀스캔을 하기 때문에 더 많은 성능 저하가 예상된다. TODO 포인트
- 문제는 쿼리 로그와 서비스 로직에서 문제의 코드를 확인할 수 있었다.
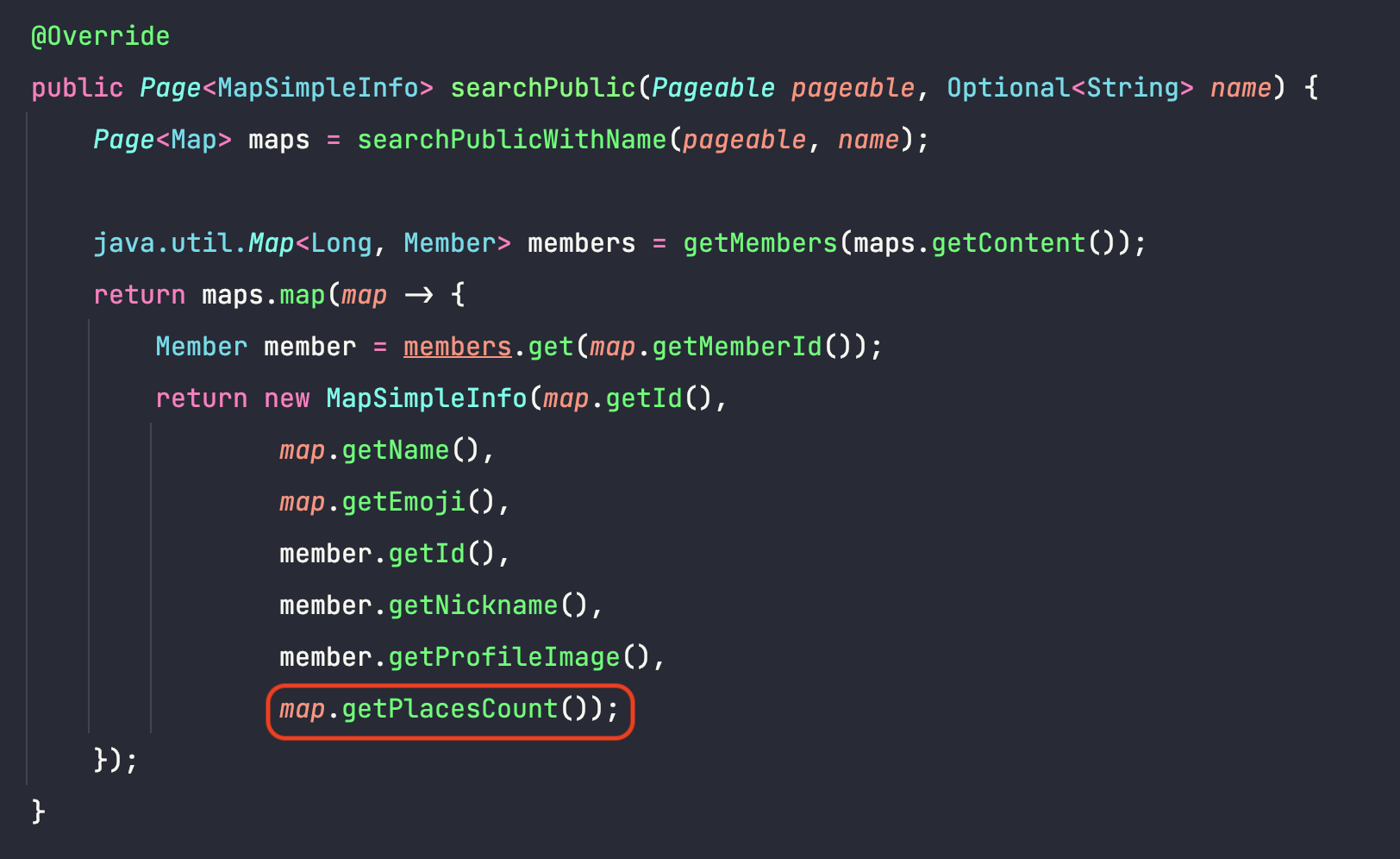
- 프로젝트 진행 초기에 만든 로직이었는데, 초창기 설계에서 간접참조와 직접참조(연관관계 매핑)에 대해서 고민을 하는 과정 중 RestDocs를 통한 API 명세 작성을 위해 대략적으로 구성을 했었다.
- 그래서 default-batch-size를 100으로 지정해주고 넘어갔고, fetch-join도 사용하지 않았다.
- Map(지도)에서 Place(장소)를 OneToMany 관계로 places(List)를 가지게 구성했다.
- 연관관계의 주인은 Place
- Place의 경우 Fetch-Type이 Lazy로,
map.getPlacesCount()(this.places.size())를 호출하면 모든 Place를 select 쿼리를 통해서 로딩한다. 데이터가 Map당 1000개의 Place를 가지고있으니 1000번의 가까운 추가쿼리가 나갈뿐만 아니라(나의 경우 batch_fetch_size로 인해서 1000번의 쿼리가 발생하지는 않는다.), 단순히 갯수만이 필요한데 place의 모든 데이터를 로딩하는 엄청난 비효율이 발생하는 것이다.
Batch_fetch_size 설정 증가해보기
-
Batch-size 설정을 증가시킴에 따른 성능 변화를 테스트해보고자 했다.
-
default_batch_fetch_size100 → 1000 -
N+1문제를 해결하기위한 방법 중 하나로 1000으로 증가 시킨 후에 다시 테스트 해보았지만 TPS에서 유의미한 차이는 발생하지 않았다.
-
Place의 갯수만 필요한데 place의 모든 필드를 다 반환하는 비효율의 문제가 크다. 그리고 Batch_fetch_size 를 증가시켜도 데이터양이 워낙 많아, 유의미한 결과가 나오지 않은 것 같다.
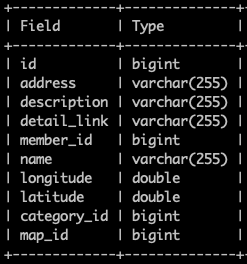
- Place table의 field들
Count 쿼리로 수정하기
-
지도 내의 장소의 갯수를 조회하는 로직을 쿼리로 채우도록 해보았다.
-
placeRepository.countPlacesByMap()jpql 네이밍 쿼리를 활용했다.
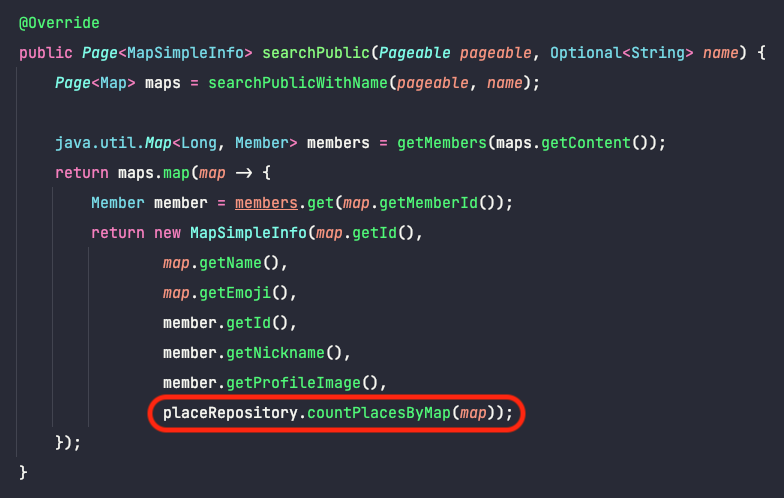
- 기존 지도마다 장소 1000개의 모든 정보를 가져오는 것과 다르게 지도내의 장소갯수만을 세서 반환한다.
그래서 결과는..
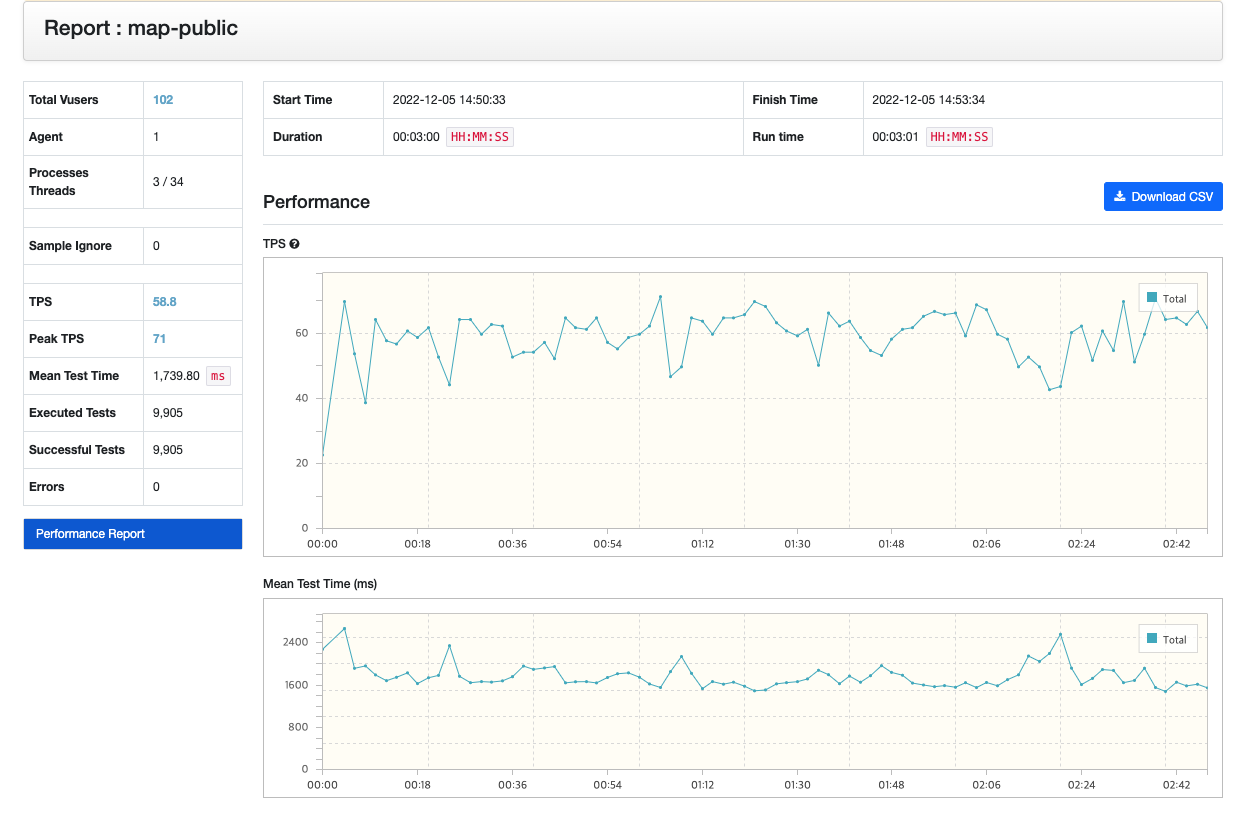
- 꽤나 유의미한 결과를 얻을 수 있었다.
- TPS 7.5 → 58.8, 거의 8배 가깝게 성능이 향상되었다.
- Mean Test Time 13.3초→ 1.7초
- 위에서 테스트 스크립트를 설명할 때 말했던 것과 같이 사이즈가 랜덤값이기 때문에 오차는 생길 수 있다.
- 그래도 TPS, MTT 가 만족스럽지는 않다.
- Paging 쿼리를 no offset 쿼리로 수정하면 더 큰 성능적 개선를 얻을 수 있지만, 프론트와의 협의를 진행하고 API를 전반적으로 개선해야 하기 때문에 캐싱부터 적용해보자.
Redis를 통한 캐싱으로 성능 개선해보기
-
Redis 설정에 대해서는 따로 정리하고 링크 남길 예정
-
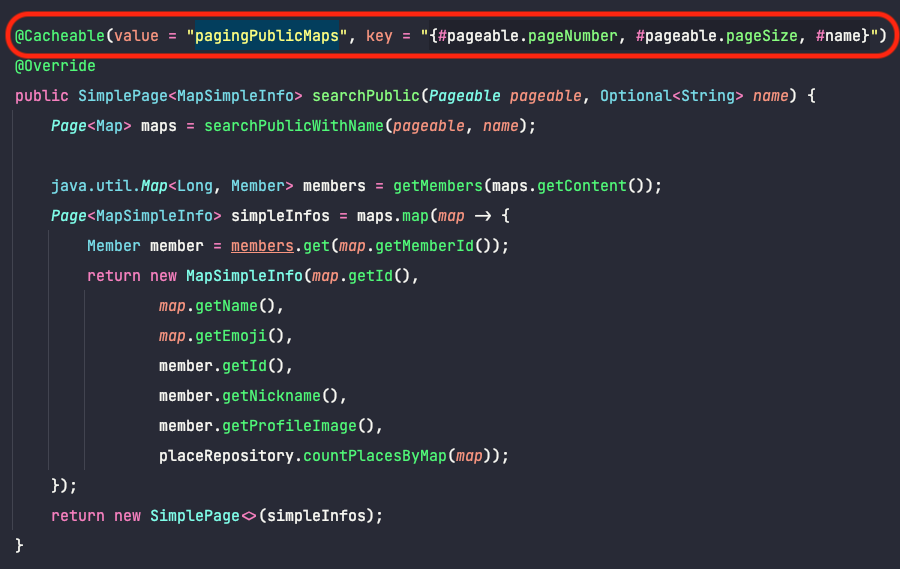
캐싱할 서비스 로직은 이렇게 수정이 되었다.
-
Spring에서 적용하는 Cache 추상화를 통해서 @Cachealble 과 같은 어노테이션을 적용하면
CacheManager를 활용해서 @Transactinal 과 같이 AOP로 기존 코드에는 영향을 주지않고 캐싱이 가능하다. -
해당 어노테이션안의 정보를 통해서 key를 만들고 메서드의 반환값을 Value로 저장한다.
- 반환타입이 객체이기 때문에 CacheManager 설정을 통해서 Value를 Json 형태로 직렬화한다.
-
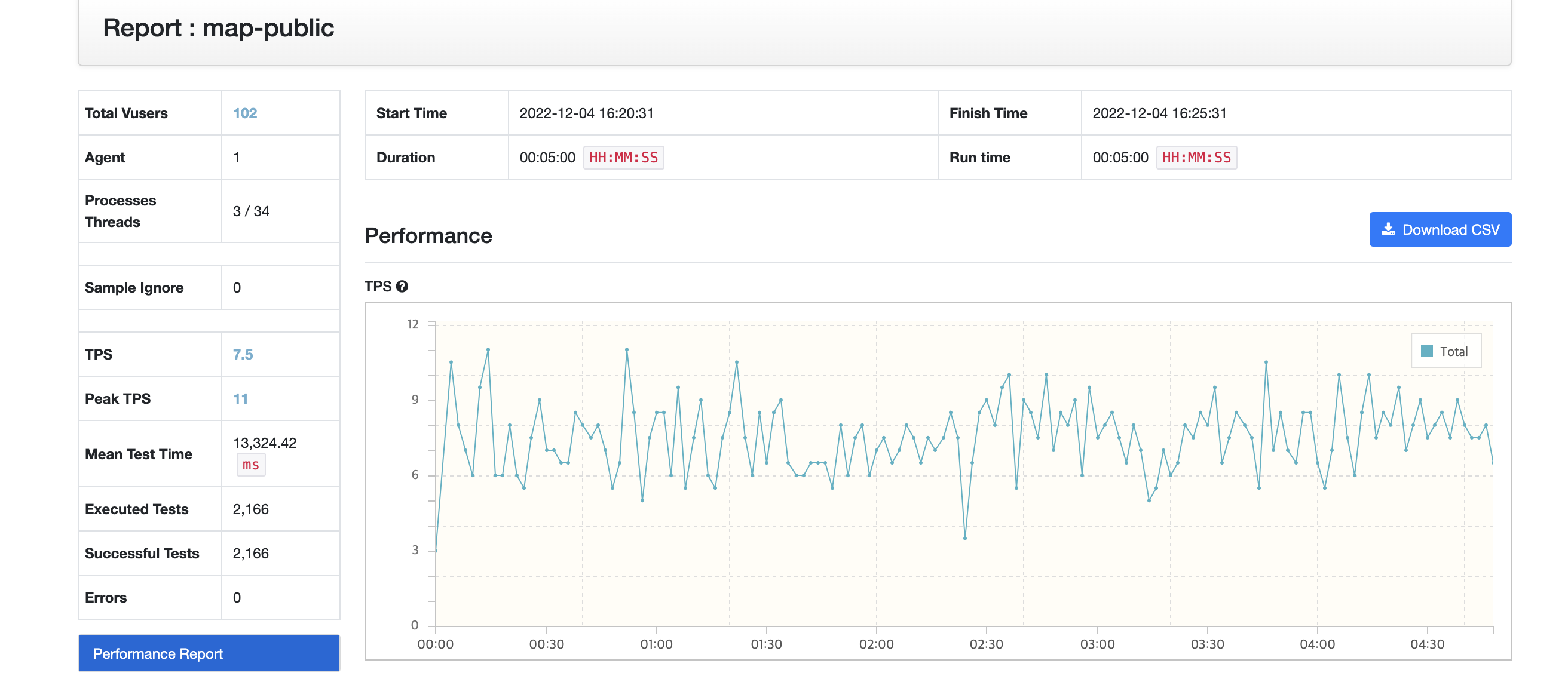
"pagingPublicMaps::[3,21,Optional.empty]”와 같은 Key가 만들어져서 저장된다. -
/map/public?page=3&size=21와 같이 API를 호출하면 Redis에서 파라미터를 통해서 Key를 만들어서 Key가 존재하는지 확인하고, 존재한다면 메서드의 로직들이 호출되지 않고, 저장되어있는 Value를 반환한다. -
Key가 존재하지 않는다면, 로직을 실행하고 반환할 때, Key와 Value를 저장한다.
아주 익스트림한 캐싱의 결과
-
첫 테스트의 결과가 아주 익사이팅한 것과 같이 캐싱의 결과도 아주 익사이팅했다.
-
Cache Hit를 통해서 오래걸리는 쿼리 로직의 실행을 막기 위해서는 메서드의 pageNumber, size, name 파라미터가 같아야한다. 테스트에서는 name 검색 조건은 없지만 랜덤으로 pageNumber와 size를 요청하기 때문에 Cache Hit가 과연 잘 될까라는 생각을 했었다.
-
테스트의 결과
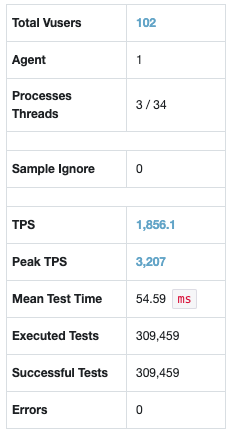
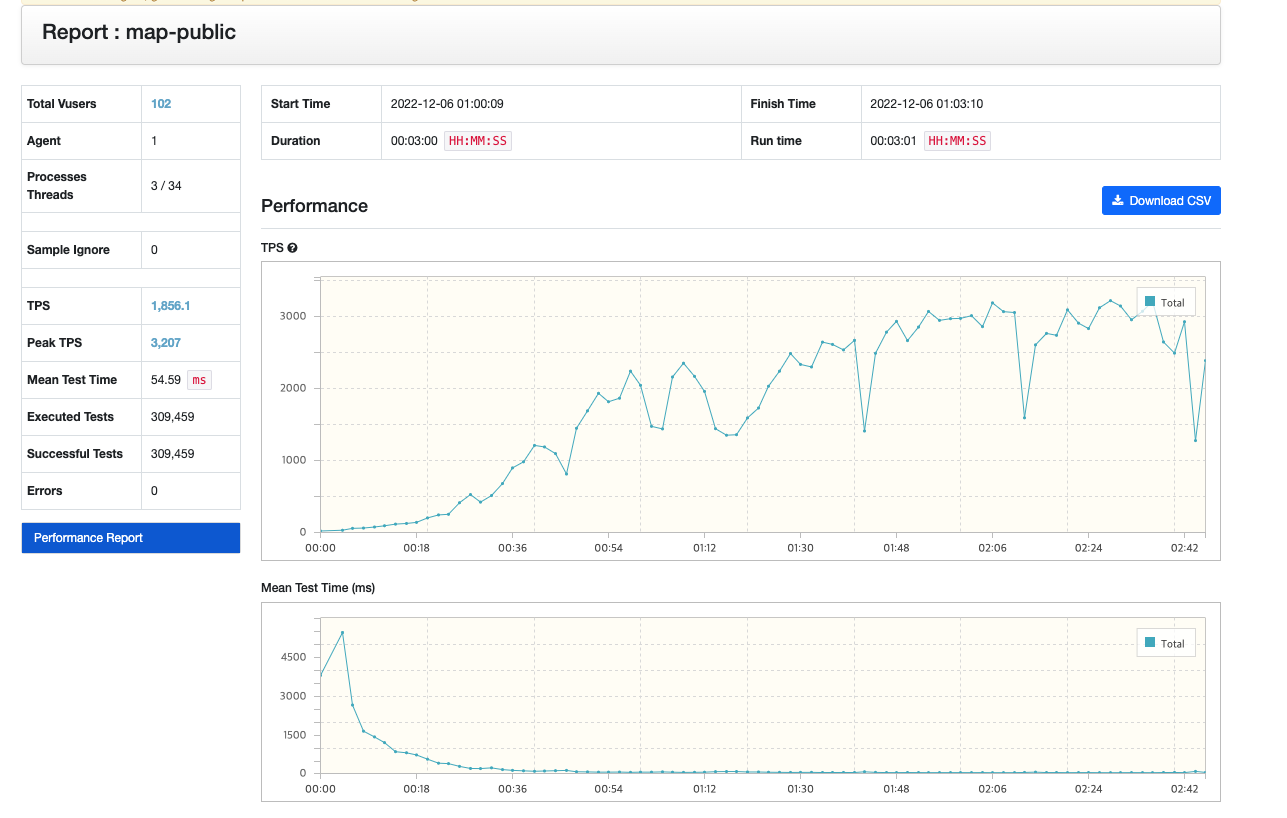
TPS 58.8 → 1856 약 30배가 증가했다.
MTT 1,739ms → 54ms
- 그래프에서 볼 수 있듯이 초반 Cache Miss가 많이 나오기 때문에 TPS가 굉장히 낮다.
- 하지만 뒤로 갈수록 Cache Hit가 굉장히 많이 발생하기 때문에 TPS가 상승하는 것을 볼 수 있다.
- 그래프 중간 중간 TPS가 급격하게 떨어지는 것도 Cache Miss가 발생하는 것으로 보인다.
- 유의미한 테스트 결과를 얻었다.
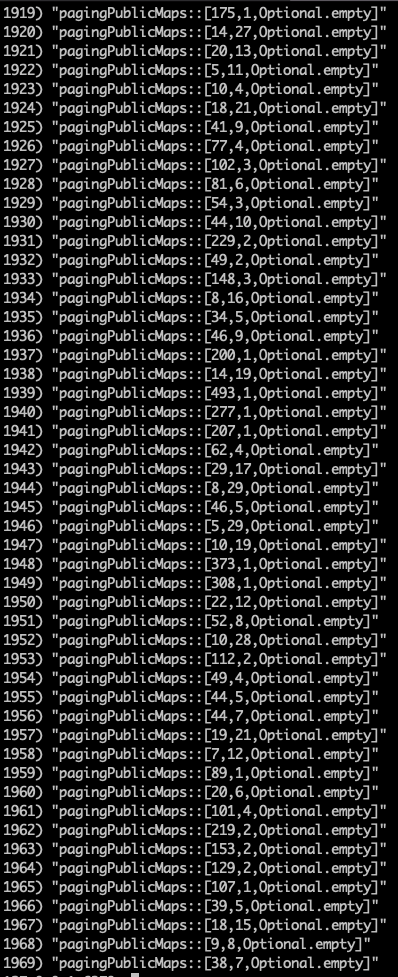
- 1969개의 데이터가 캐싱되었다.
결론 및 느낀점
-
데이터를 많이 넣지않고 테스트 및 클라이언트들에게 API를 제공했기에 로직의 문제를 파악하지 못했었다.
-
또한, 개발 프로세스와 일정들이 명확하지 않았기에, 아주 기본적인 것도 놓치고 있었다는 생각이 든다.
-
org.ngrinder.common.exception.NGrinderRuntimeException: Can not check available ports because given local IP address
여담으로 우리집 와이파이 Issue로 ngrinder-controller가 실행되지 않아서, .ngrinder/system.conf, etc/hosts 파일을 설정해보려는 등등 원인을 찾지못하는 에러로 시간을 꽤나 낭비하면서 테스트를 시작도 못할 뻔 했다.
Caused by: org.ngrinder.common.exception.NGrinderRuntimeException: Can not check available ports because given local IP address '218.38.137.27' is unreachable. Please check the /etc/hosts file or manually specify the local IP address in ${NGRINDER_HOME}/system.conf.단순 네트워크 문제다. 다른 네트워크환경에서는 정상적으로 작동했다.
-
-
Spirng Cache와 관련해서 캐시를 수정, 삭제하는 과정에서 캐시의 변화,그리고 기본적인 TTL과 같은 설정과 Clustering을 비롯한 Redis에 대한 이해가 더 필요하다고 느껴진다. (Serializer만 해도 고려해볼 요소가 많다.)
-
또 다른 API들을 테스트 해보면서 리팩토링을 지속하고 싶다.
-
캐싱을 통해서 그룹 멤버 검증에 대한 로직 리팩토링하고, 다시 포스팅 해볼 예정이다.
-
TODO : 배포환경을 구축하고 PinPoint까지도 찍먹해보고 싶다.
References
- https://github.com/naver/ngrinder/wiki
- https://docs.spring.io/spring-boot/docs/2.1.6.RELEASE/reference/html/boot-features-caching.html#boot-features-caching-provider-redis
- https://docs.spring.io/spring-framework/docs/5.0.0.M5/spring-framework-reference/html/cache.html
- https://mangkyu.tistory.com/179
- https://docs.spring.io/spring-data/data-redis/docs/current/reference/html/#reference
- https://velog.io/@max9106/nGrinderPinpoint-test1

4개의 댓글



혹시 local IP address '218.38.137.27' 이슈는 해결할 수 없는건가여... 아파트 공용 인터넷 사용중인데 주륵..
잘봤습니다.. 도움이 많이 되었네요 ㅎㅎ