
이 포스팅에서는 nGrinder설치와 Pinpoint설치 과정에 대해서는 다루지 않습니다!
처음 진행해보는 부하테스트이므로 잘못된 부분이 있을 수 있습니다. 혹시 그런부분이 있다면 알려주시면 감사하겠습니다🙏
우아한테크코스 과정중에 누구나 코드리뷰를 받을 수 있도록 리뷰어와 리뷰이를 매칭해주는 코드리뷰 플랫폼인 👀코드봐줘 서비스를 개발하고 있습니다.
누구나 코드리뷰를 받을 수 있는
👀 코드봐줘
(GitHub: https://github.com/woowacourse-teams/2021-drop-the-code)
일정에 맞게 계획했던 기능들은 거의 구현이 된 상태여서(아직 필요한 기능들이 많지만..) 서비스의 성능을 파악할 필요가 있었습니다. 이번 포스팅에서는 nGrinder와 Pinpoint를 사용하여 코드봐줘 서비스의 성능/부하테스트를 진행하여 분석하고 이를 토대로 개선해가는 과정을 기록하려 합니다.
❓왜 nGrinder & Pinpoint?
성능/부하테스트 도구로는 nGrinder, k6, Apache JMeter, Gatling, Locust 등 여러 가지가 있습니다.
제대로 된 테스트를 위해서는 아래의 3가지 기능을 지원하는게 좋습니다.
- 시나리오 기반의 테스트가 가능해야 합니다.
- 동시 접속자 수, 요청 간격, 최대 Throughput 등 부하를 조정할 수 있어야 합니다.
- 부하 테스트 서버 스케일 아웃을 지원하는 등 충분한 부하를 줄 수 있어야 합니다.
저는 그중에 nGrinder를 선택했는데요. 그 이유는 다음과 같습니다.
- 위의 3가지 기능 제공(스크립트를 통한 시나리오 작성 가능, 부하 조정 가능, Agent를 이용하여 충분한 부하를 줄 수 있음)
- 한글 지원
- groovy문법 지원
- 사용하기 편함
추가적으로 모니터링을 위해 Pinpoint를 사용했습니다.
- 현재 인프라 구조, 요청수를 한 눈에 볼 수 있음
- 요청에 대한 성공/실패, 응답 시간을 그래프로 볼 수 있음
- 콜스택을 이용하여 병목 지점을 쉽게 확인할 수 있음
📝 테스트 계획
바로 테스트에 들어가기 전에 테스트 계획부터 세워야합니다. 부하테스트는 시스템의 응답 성능과 한계치를 파악하기 위한 테스트입니다.
- 서비스가 어느 트래픽까지 처리할 수 있는지(어느 정도의 부하를 견디는지) → 어떻게 대응할지 알 수 있음
- 병목이 발생하는 부분이 어디인지 → 어떻게 개선할지 알 수 있음
이를 파악하기 위한 지표는 아래와 같습니다.
- Users: 동시에 사용할 수 있는 사람
- TPS: 일정 시간 동안 얼마나 처리할 수 있는지
- 한 명만 사용해도 처리량이 좋지 않으면 → scale up
- 부하 증가시 문제 → scale out
- Time: 얼마나 빠른지
테스트 환경
성능/부하 테스트는 실제 사용자가 접속하는 환경과 유사해야합니다. 따라서 동일하게 AWS를 이용하여 인프라를 구성했습니다.
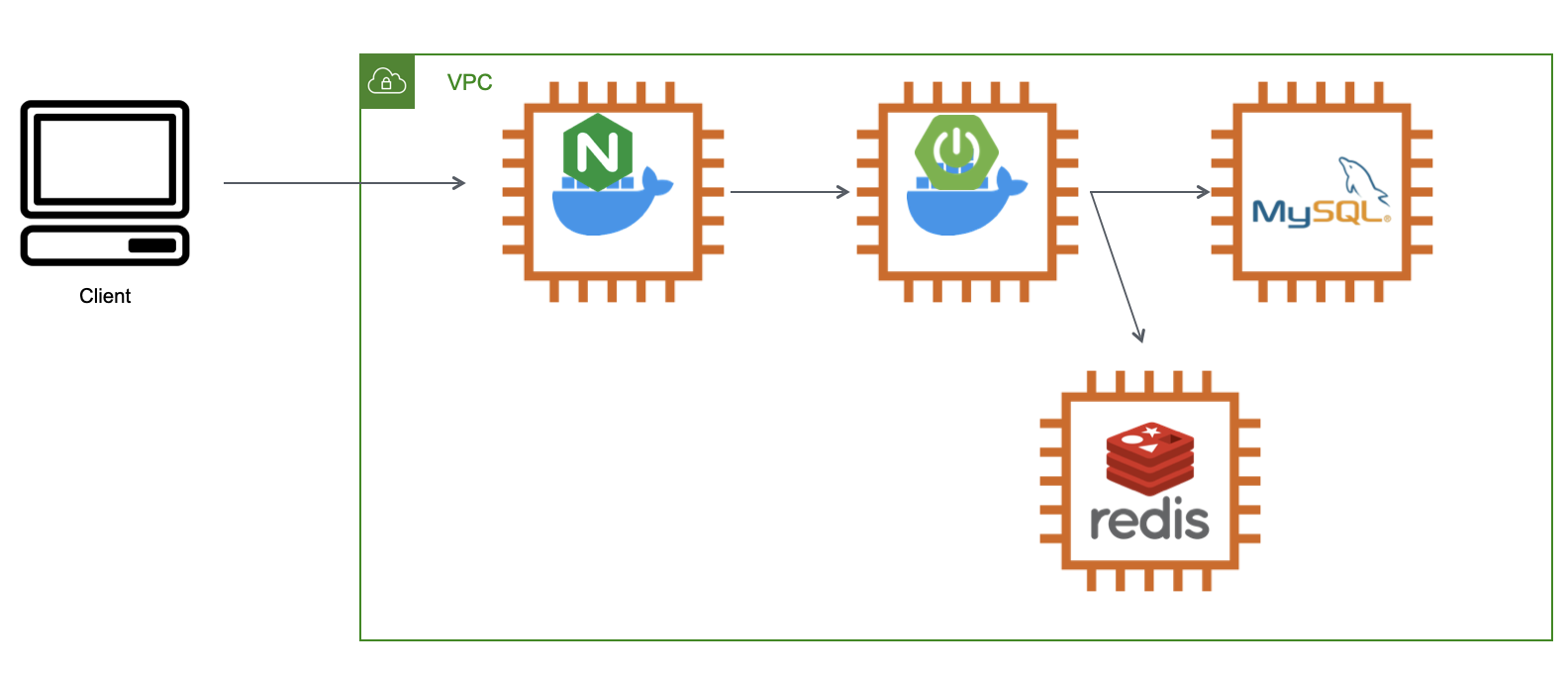
또 데이터의 양도 동일해야합니다. 하지만 코드봐줘는 현재 사용량이 거의 없기 때문에 임의로 많은 데이터를 넣어서 진행합니다.
OAuth 로그인과 같이 외부와 소통하는 로직이 포함된 경우 별도의 서버를 구성해야합니다. 객체를 Mocking하는 경우 Http Connection Pool, Connection Thread 등을 미사용하게 되고 IO가 발생하지 않습니다. 같은 애플리케이션에 Dummy Controller를 구성하는 경우 테스트 시스템의 자원과 리소스를 같이 사용하므로 테스트의 신뢰성이 떨어집니다. 코드봐줘는 Github OAuth 로그인이 포함되어 있으므로 별도의 Fake OAuth 서버를 만들어 진행합니다.
전제조건
먼저 전제조건을 정해야합니다.
- 테스트하려는 Target 시스템의 범위를 정해야 합니다.
- 부하 테스트시에 저장될 데이터 건수와 크기를 결정하세요. 서비스 이용자 수, 사용자의 행동 패턴, 사용 기간 등을 고려하여 계산합니다.
- 목푯값에 대한 성능 유지기간을 정해야 합니다.
- 서버에 같이 동작하고 있는 다른 시스템, 제약 사항 등을 파악합니다.
1) Target 시스템의 범위
2가지 범위로 테스트를 해보려고 합니다.
Was부터 시작하는 범위
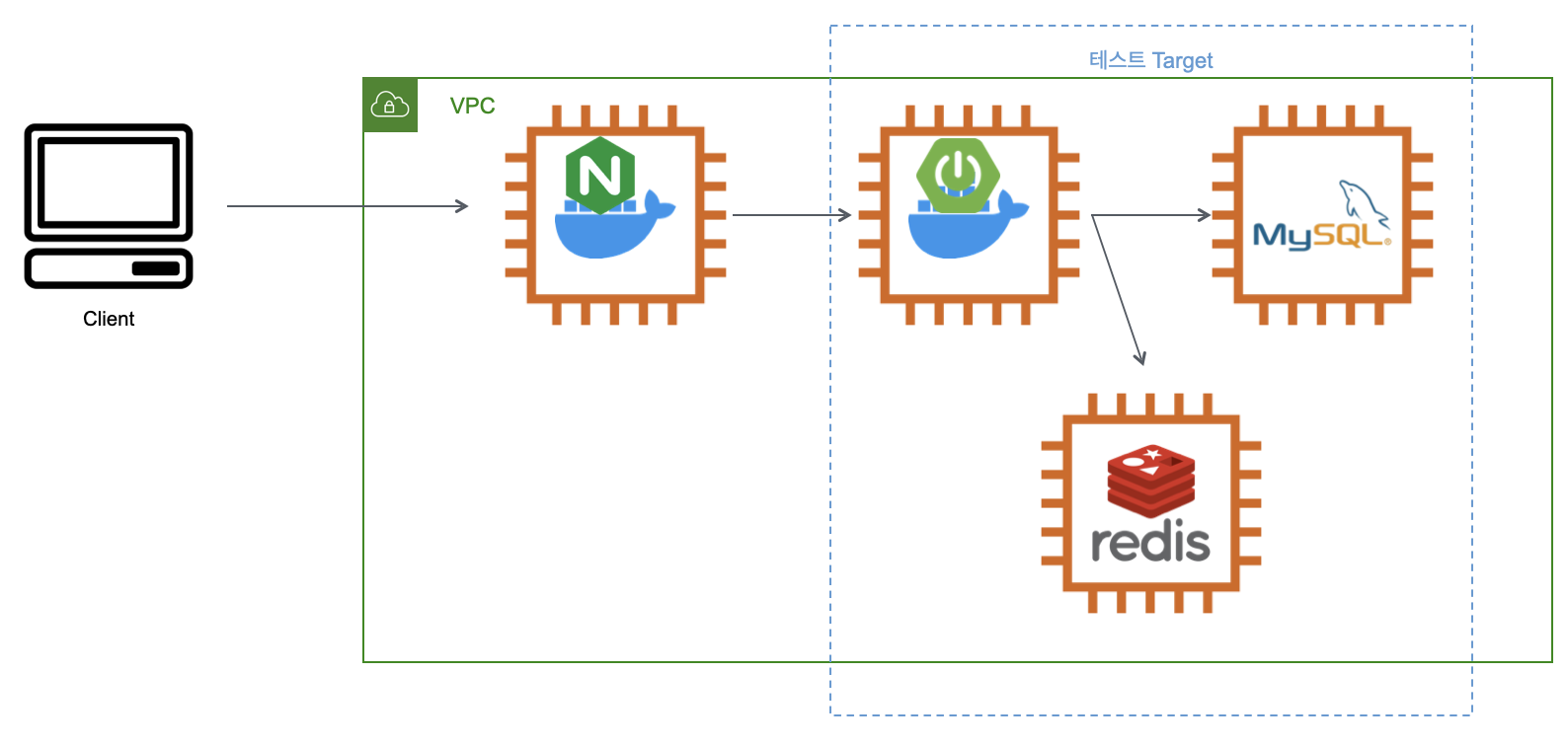
Reverse Proxy를 포함한 범위
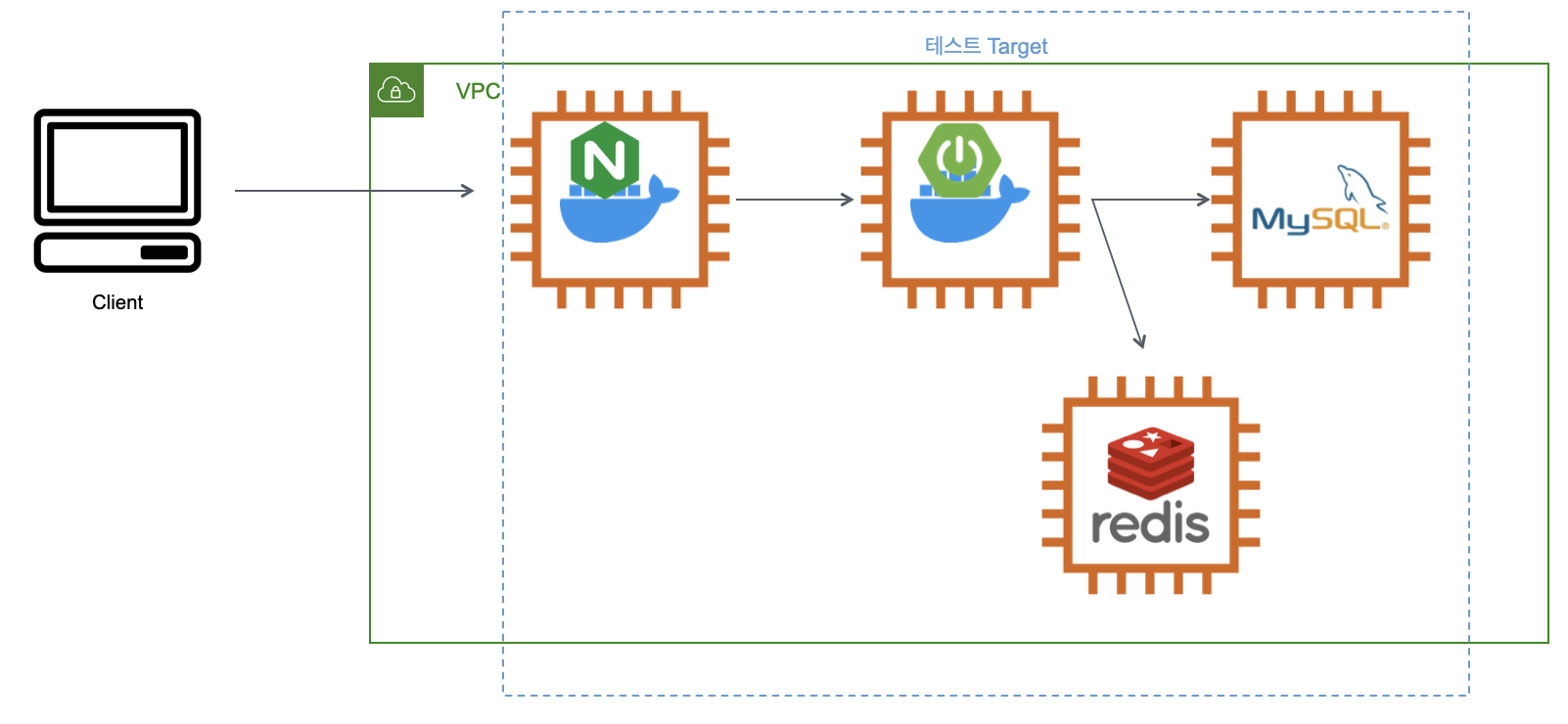
2) 데이터 수
아직 개발중인 서비스이기 때문에 서비스 이용자 수, 사용자의 행동 패턴, 사용 기간 등의 정보가 없습니다. 따라서 이번에는 임의로 데이터 수를 정하고 테스트를 진행하려합니다. 코드봐줘 서비스의 주요 기능은 리뷰어 조회, 리뷰 요청입니다. 따라서 해당 기능에서 사용되는 member, teacher_profile, reivew, teacher_language, teacher_skill 테이블에 각각 20만개의 초기 더미 데이터를 넣고 진행합니다.
3) 목푯값에 대한 성능 유지기간
주요 기능의 성능이 30분 동안 유지되는 것을 목표로 테스트 & 개선해보려고 합니다.
4) 제약 사항
딱히 서버에 같이 동작하고 있는 다른 시스템, 제약 사항 등이 없으므로 넘어가겠습니다.
테스트 종류
크게 테스트는 3종류가 있습니다.
1) Smoke 테스트
- VUser: 1 ~ 2
- 최소의 부하로 시나리오를 검증해봅니다.
2) Load 테스트
- 평소 트래픽과 최대 트래픽일 때 VUser를 계산 후 시나리오를 검증해봅니다.
- 결과에 따라 개선해보면서 테스트를 반복합니다.
3) Stress 테스트
- 최대 사용자 혹은 최대 처리량인 경우의 한계점을 확인하는 테스트입니다.
- 점진적으로 부하를 증가시켜봅니다.
- 테스트 이후 시스템이 수동 개입 없이 자동 복구되는지 확인해봅니다.
성능 목표 설정
성능 목표를 정하기 위해서는 VUser를 구해야합니다.(Load 테스트인 경우)
VUser를 구하기 위해서는 아래와 같은 지표들이 필요합니다.
- DAU(일일 활동 사용자 수)
- 피크시간대 집중률(최대 트래픽 / 평소 트래픽)
- 1명당 1일 평균 요청 수
코드봐줘의 경우 실제 사용자가 거의 없기 때문에 정확하지는 않지만 similarweb을 이용해 비슷한 서비스의 트래픽을 보고 지표들을 가정하여 진행해보려고 합니다.(사이트 주소를 입력하시면 간단한 트래픽 정보를 볼 수 있습니다.)
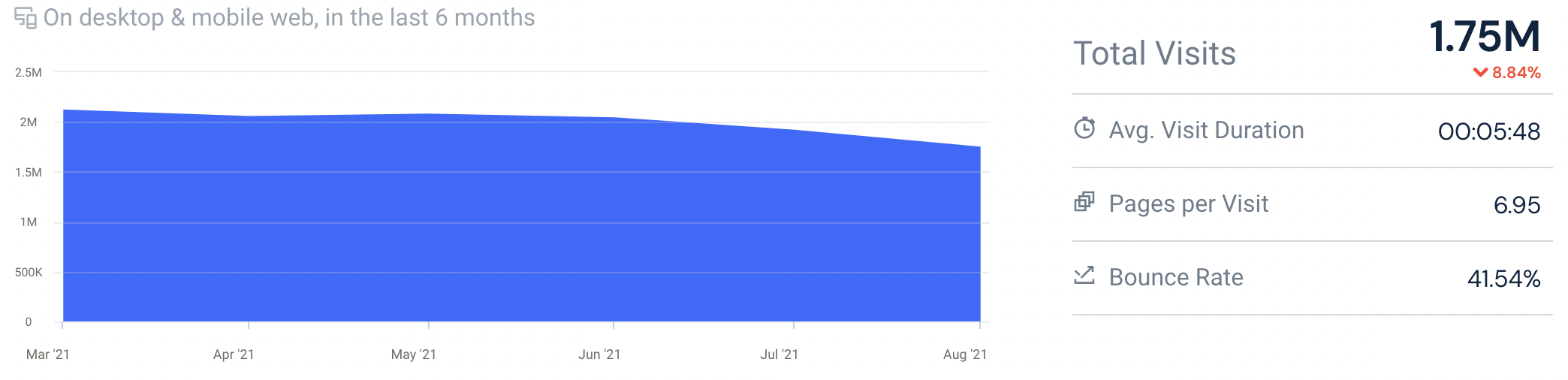
위 사이트는 한달에 약 210만명이 방문하고 있습니다. 따라서 정확하지는 않겠지만 DAU를 210만/30(한달)로 계산하여 7만명으로 잡고 계산하겠습니다. 피크시간대 집중률은 저녁 시간대에 늘어날 것으로 예상은 되지만, 최대 트래픽과 평소 트래픽의 차이가 크게는 없을 것이라고 생각하여 3배로, 1명당 1일 평균 요청 수는 14정도로 가정하고 진행하겠습니다.
- DAU(일일 활동 사용자 수): 70000
- 피크시간대 집중률(최대 트래픽 / 평소 트래픽): 3
- 1명당 1일 평균 요청 수: 14
위의 정보를 가지고 throughput(1일 평균 rps ~ 1일 최대 rps)를 계산할 수 있습니다.
- DAU * 1명당 1일 평균 접속수 = 1일 총 접속수
→ 70000 * 14 = 980000 - 1일 총 접속수 / 86400(초 / 일) = 1일 평균 rps
→ 980000 / 86400 = 약 11.3 - 1일 평균 rps * (최대 트래픽 / 평소 트래픽) = 1일 최대 rps
→ 11.3 * 3 = 약 34
즉 throughput은 11.3(1일 평균 rps) ~ 34(1일 최대 rps)가 나오게 됩니다. 이 정보를 통해서 VUser를 계산할 수 있습니다.
VUser: (목표 rps * T) / R
- R: 시나리오에 포함된 요청의 수
- T: 시나리오 완료 시간보다 큰 값(VUser 반복을 완료하는데 필요한 시간보다 큰 값)
T = (R * 왕복시간(http_req_duration)) + 지연시간(내부망일 경우 추가하기! - 외부에서 처리되는 시간을 보정해주기 위함!)- 왕복 시간 = 얼마 안에 끝나야 하는지
이번에 테스트해 볼 시나리오에 포함된 요청의 수는 7, http_req_duration을 0.5s, 지연시간을 1s로 설정한다면 아래와 같은 결과가 도출됩니다.
- R = 7
- T = (7 * 0.5) + 1 = 4.5
- 평소 트래픽 VUser: (11.3 * 4.5) / 8 = 약 7
- 최대 트래픽 VUser: (34 * 4.5) / 8 = 약 22
보통 VUser(active user)가 80정도면 헤비한 트래픽이 발생하는 것이라고 생각한다고 합니다. 보통은 10 ~ 15명 정도로도 충분하다고 합니다.
테스트 목표
구한 값을 토대로 각 테스트별 목표를 정리해보겠습니다.
1) Smoke 테스트
- VUser: 1 ~ 2
- Throughput: 11.3 ~ 34 이상
- Latency: 50 ~ 100ms 이하
2) Load 테스트
- 평소 트래픽 VUser: 7
- 최대 트래픽 VUser: 22
- Throughput: 11.3 ~ 34 이상
- Latency: 50 ~ 100ms 이하
- 성능 유지 기간: 30분
3) Stress 테스트
- VUser: 점진적으로 증가시켜보기
시나리오
시나리오 대상은 접속 빈도 높거나 서버 리소스 소비량이 많거나 DB를 사용하는 기능을 선택해보는게 좋습니다.
코드봐줘의 경우 가장 접속 빈도가 높으면서 DB를 많이 사용하는 부분은 리뷰어 조회, 리뷰 조회일 것입니다.
이번에는 전체적인 조회에 대한 시나리오를 진행하려고 합니다.
1) 시나리오1
로그인 - 언어 기술 목록 조회 - 리뷰어 목록 조회 - 리뷰어 단일 조회 - 내가 받은 리뷰 목록 조회 - 내가 리뷰한 리뷰 목록 조회 - 리뷰 상세 조회
추후에 CUD관련 부분도 테스트 해보려고 합니다.
2) 시나리오2
로그인 - 언어 기술 목록 조회 - 리뷰어 목록 조회 - 리뷰어 선택 - 리뷰 요청
테스트 계획 템플렛
퀄리티는 구리지만 구글 스프레드 시트로 테스트 계획 템플렛을 만들어봤습니다.
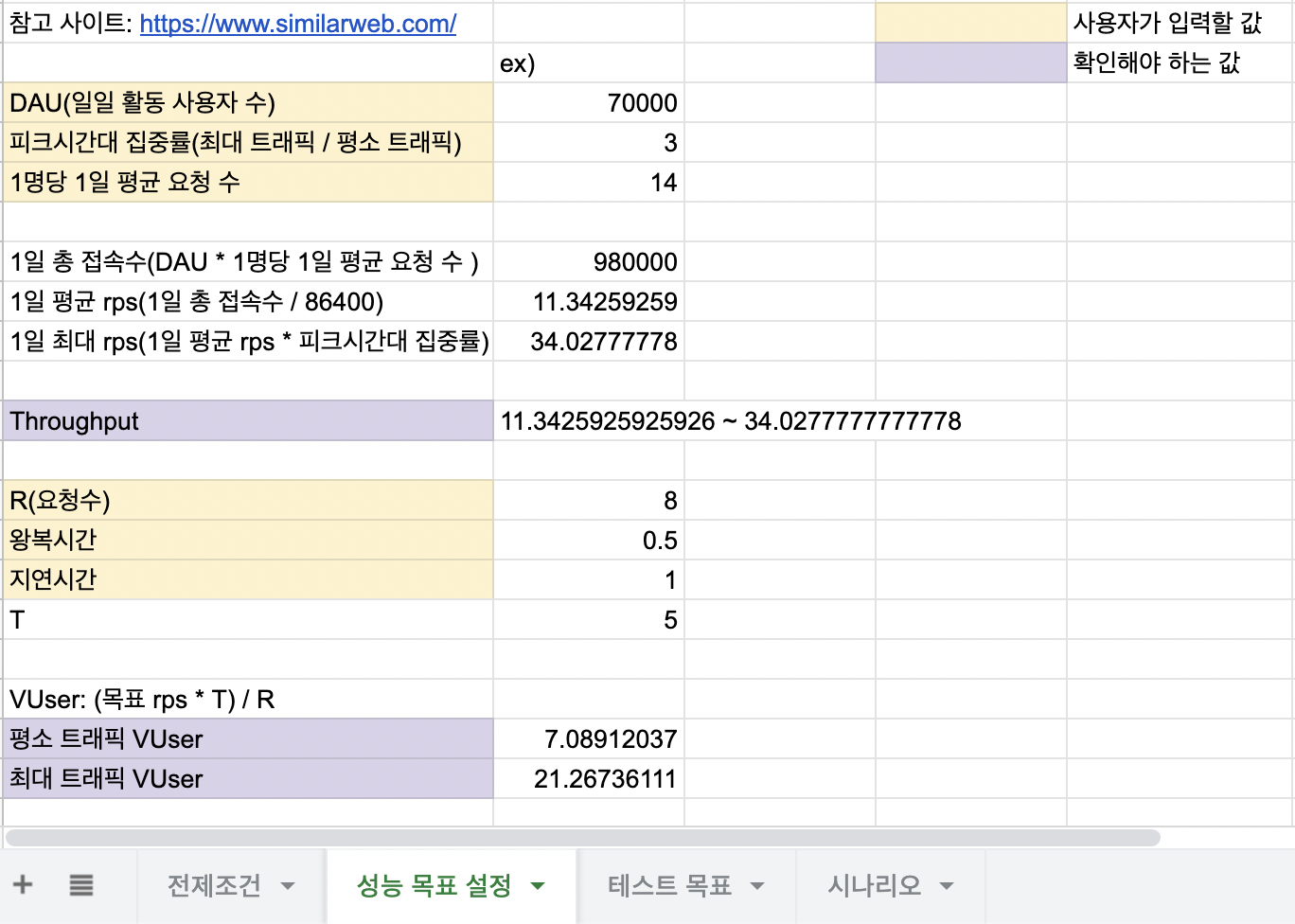
🔎 테스트 계획 템플렛
🌱nGrinder & Pinpoint 환경
nGrinder
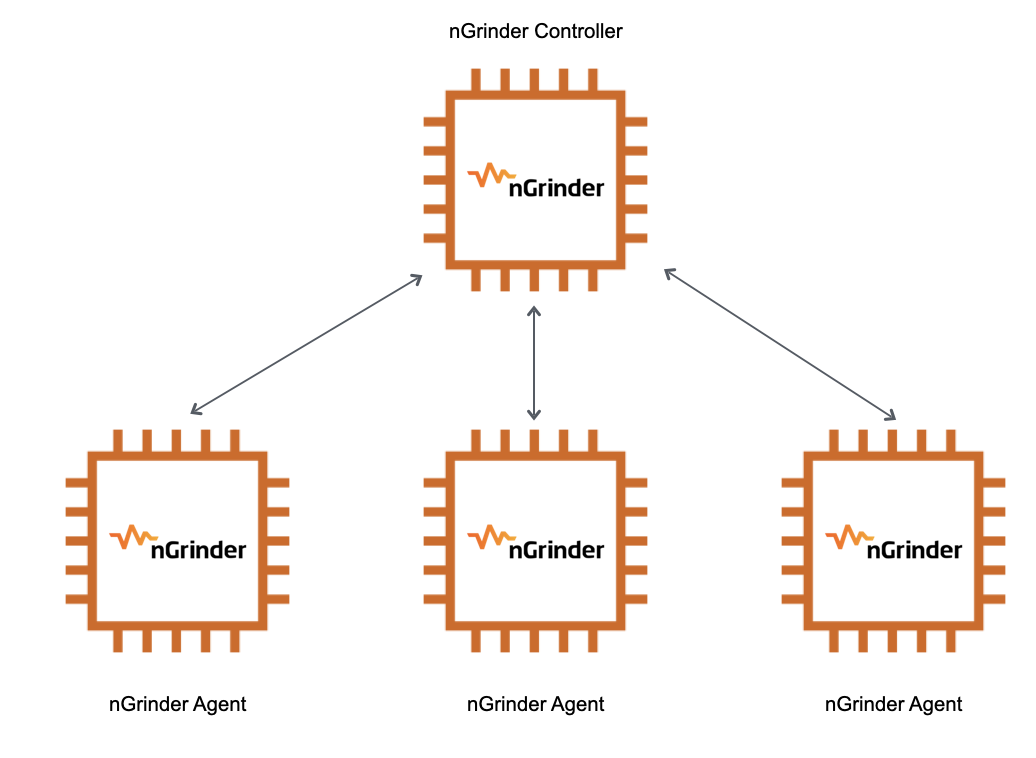
nGrinder는 Controller와 Agent로 나눠져 있습니다.
Controller
- 부하테스트를 위한 웹 인터페이스 제공
- 테스트 스크립트 작성
- 테스트 결과를 수집하여 통계로 보여줌
Agent
- Controller의 명령을 받아 실제로 target에 부하를 발생시킴
- CPU, memory 모니터링도 가능
저는 하나의 Controller와 3개의 Agent를 둬서 테스트를 진행합니다.
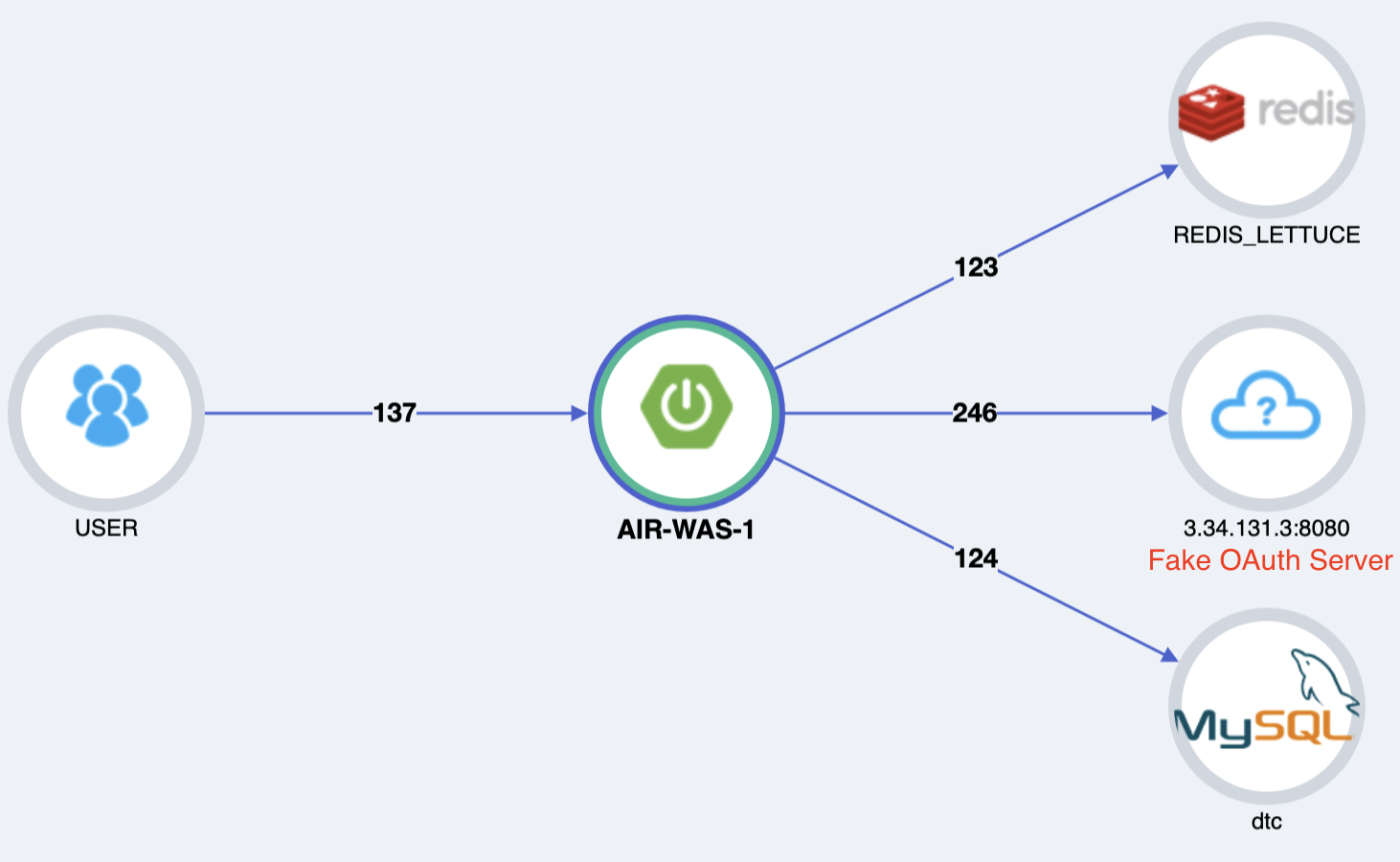
Pinpoint
Pinpoint 구성환경입니다. 숫자는 요청 수를 나타냅니다.
이번 포스팅에서는 테스트 계획을 세워봤습니다. 다음 포스팅에서는 시나리오를 바탕으로 스크립트를 작성해보겠습니다.
Reference
- 우아한테크코스
- 스프링캠프 2015:[B-2]: 내가 써본 nGrinder

부하테스트 시나리오 구성을 어떻게해야할까 막막했는데 이 글 덕분에 많은 도움을 얻었습니다!!
그런데 글의 성능 목표 설정 부분에서 VUser 계산하는 부분에서 관련해서 궁금한 점이 있습니다.
글에서 공식이
(목표 rps * T) / R그리고 T=4.5, R=7 이라고 하셨는데요.계산할때 8을 나누셔서 오타인지 아니면 제가 놓친 부분이 있는지 궁금해서 질문드립니다!