Pandas 라이브러리에는 데이터 분석에 유용한 여러 가지 함수(메소드)가 있다.
'Garbage in, garbage out.'이라는 말이 있듯이 좋은 데이터를 가지고 분석하여야 좋은 결과를 도출할 수 있다. 정말로 잘 설계되고, 수집된 데이터가 아니라면 raw data를 바로 분석에 사용하기에는 어렵다. 좋은 데이터를 만들기 위해서는 탐색적 데이터 분석(EDA)과 Feature Engineering을 통해 raw data를 잘 가공해야 한다.
데이터를 잘 가공하기 위해서는 raw data의 정보를 파악하고 분석해야 한다. 아래의 함수들을 이용하여 데이터프레임의 각 정보를 확인할 수 있다.
목차
- columns
- shape
- dtypes / select_dtypes
- unique / nunique
- value_counts
- info
- describe
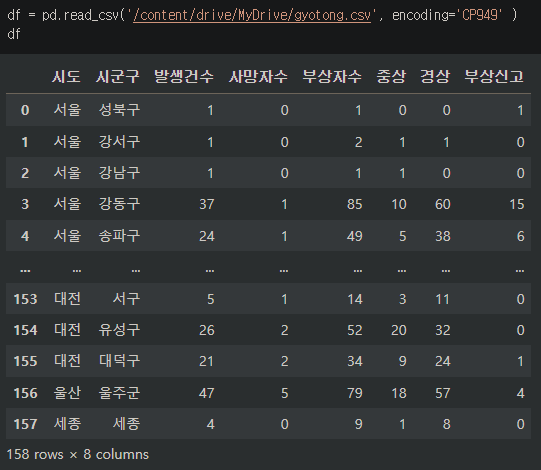
이번블로깅에서 사용한 데이터는 전국 지역별 교통사고 발생건수 데이터이다.
1. columns
.columns 로 데이터프레임의 컬럼명을 확인할 수 있다.

2. shape
.shape 로 데이터프레임의 (행,열) 크기를 확인할 수 있다.

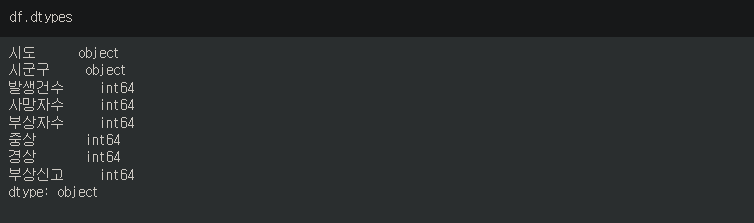
3. dtypes / select_dtypes
.dtpyes 로 각 column의 데이터타입을 확인할 수 있다.
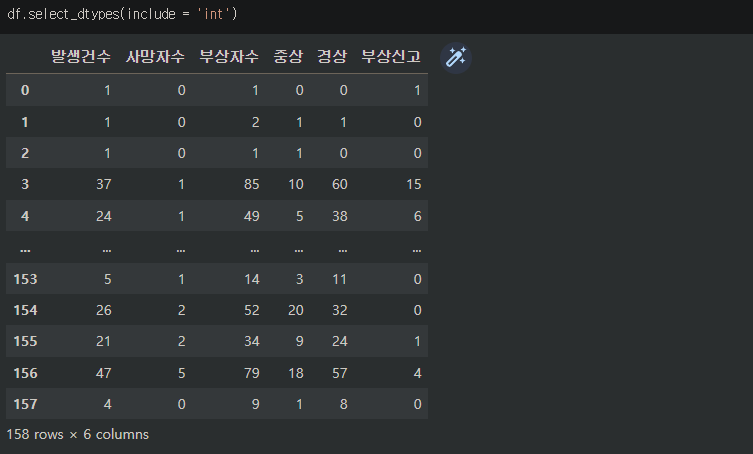
.select_dtypes() 로 선택한 데이터타입의 데이터만 선택하여 볼 수 있다.
4. unique / nunique
.unique() 로 선택한 column을 구성하고 있는 데이터의 고유값을 확인할 수 있다.

.nunique() 로 구성하고 있는 데이터의 고유값의 개수를 확인할 수 있다.
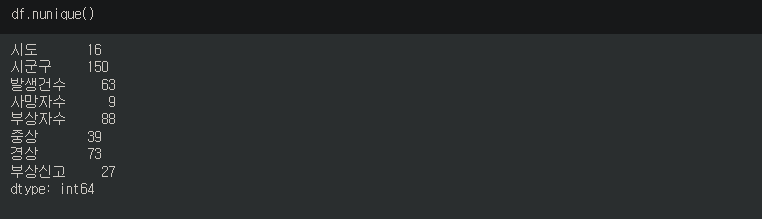
5. value_counts
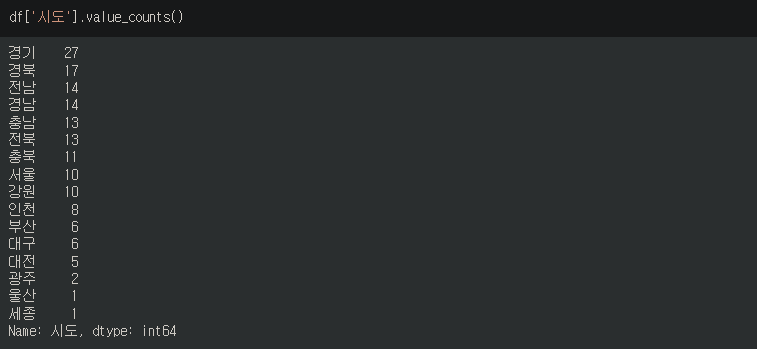
.value_counts() 로 데이터의 고유값이 아닌 각 데이터의 전체 개수를 확인할 수 있다.
기본적으로 내림차순으로 정렬되며 value_counts(ascending=True) 로 오름차순으로 정렬할 수 있다.
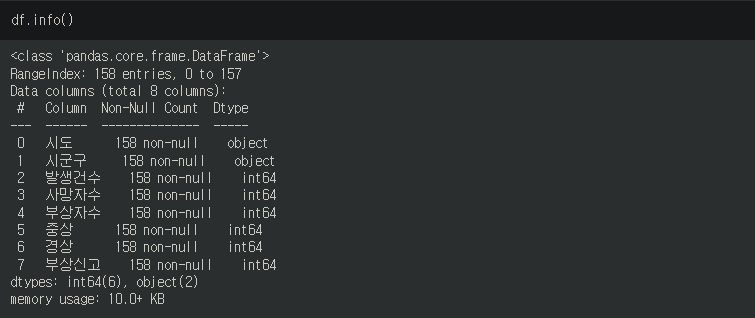
6. info
.info() 로 데이터셋의 컬럼명, 컬럼별 데이터 수, 데이터 타입을 확인할 수 있다.
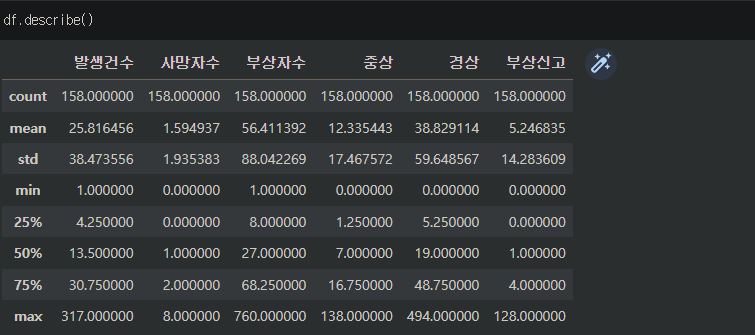
7. describe
.describe() 로 데이터셋에 있는 수치형 데이터의 컴럼별 주요 통계량을 확인할 수 있다.