
데이터셋에 존재하는 결측값은 EDA 과정, 머신러닝 분석 과정에서 부정적인 영향을 줄 수 있는 요소이다.
따라서 분석을 진행하기 전 결측값을 처리하는 과정은 매우 중요하다. 결측값은 삭제하거나 특정 값으로 대체하여 처리할 수 있다.
결측값은 탐색적 데이터 분석에서도, 그 후 더 나아가 머신러닝 알고리즘을 통해 분석을 할 때에도 성능에 영향을 줄 수 있는 값이다. 따라서 결측값은 아예 제거하거나, 특정 값으로 대체해야한다.
목차
- isna, isnull, notnull
- fillna
- dropna
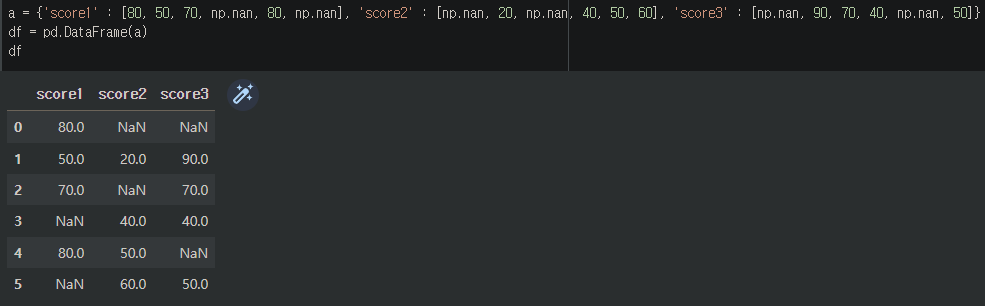
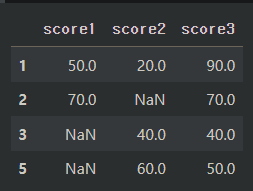
직접 값을 입력하여 간단한 데이터프레임을 만들었다.
score1, score2, score3의 컬럼이 있고 각 열에는 결측값이 존재한다.
1. isna, isnull, notnull
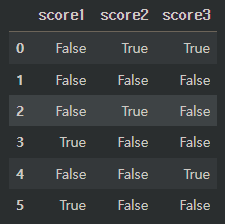
데이터프레임에 존재하는 결측값을 확인하는 함수들이다.
df.isna() # = df.isnull().isna() 와 .isnull() 은 이름은 다르지만 같은 함수이다.
결측값을 True로 반환한다.
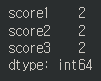
df.isna().sum().isna().sum() 과 같이 뒤에 .sum() 함수를 붙여 각 컬럼별 결측치 개수를 확인할 수 있다.
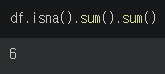
df.isna().sum().sum()뒤에 한번 더 .sum()을 붙인다면 데이터프레임 전체의 결측값의 개수를 반환한다.
df.notnull().notnull() 은 위의 함수와 반대로 결측값이 아닌 값들을 반환한다.
결측값을 False로 아닌 값들을 True로 반환한다.
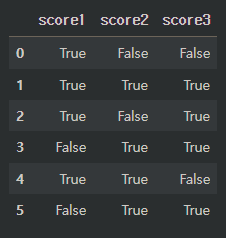
2. fillna
결측값을 채우기 위해서 사용하는 함수이다. fillna() 안에 특정값을 넣어 결측값을 대체할 수 있고, method 인자를 사용하여 결측값을 대체하는 값을 정해줄 수도 있다.
- 결측값을 특정 값으로 대체 : df.fillna(특정값)
df.fillna(100) # 동일한 하나의 값으로 입력하는 경우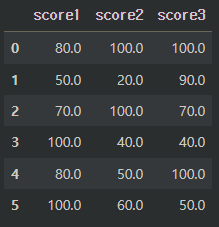
df.fillna({'score1':11, 'score2':22, 'score3':33}) # 컬럼별로 다른 값을 입력하는 경우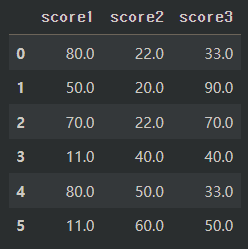
- 결측값을 특정 값으로 대체 : df.fillna(특정값)
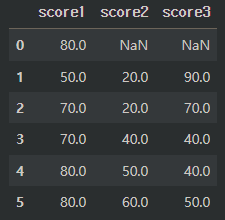
df.fillna(method='ffill')
df.fillna(method='pad')앞의 행 값이 없는 첫번째 행의 경우 결측값이 채워지지 않는다.
- 결측값을 결측값의 뒷 행의 값으로 대체 : df.fillna(method='bfill') / df.fillna(method='backfill')
df.fillna(method='bfill')
df.fillna(method='backfill')다음 행 값이 없는 마지막 행의 경우 결측값이 채워지지 않는다
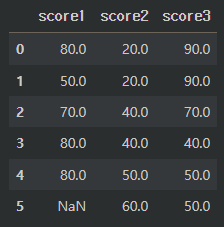
- 결측값을 각 열의 평균 값으로 대체 : df.fillna(df.mean())
df.fillna(df.mean())mean() 뿐만아니라 min(), max(), sum() 등 모두 사용 가능하다.
3. dropna
dropna() 함수는 결측값이 존재하는 행 또는 열을 삭제한다.
- 결측값의 개수에 따른 제거
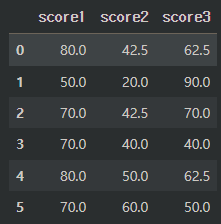
df.dropna(how='any') # 행에 결측값이 하나라도 있으면 행 제거 (default)
df.dropna(how='all') # 행에 있는 값이 모두 결측값일시 행 제거두번째 행을 제외하고 모두 결측값을 가지고 있어 나머지 행들은 제거되었다.
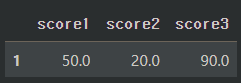
- dropna(thresh = N)
df.dropna(thresh=2) # 2개 이상의 값을 가지는 행만 출력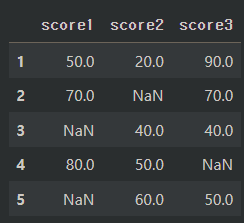
- dropna(subset = [ ])
df.dropna(subset = ['score3']) # subset에서 지정한 열에 결측값이 존재하는 경우 해당 행을 제거'score3' 컬럼에는 index 0과 4의 행에 결측값이 존재하여 해당 행이 삭제되었다.
- 결측값이 있는 행 or 열 제거
df.dropna(axis=0) # 결측값이 있는 행 제거 (default)
df.dropna(axis=1) # 결측값이 있는 열 제거결측치가 있는 '열'을 제거하고 싶으면 axis 파라미터의 값을 1로 변경한다.
