Scraping & Crawling
Scraping
-
웹 스크래핑(Web scraping)은 특정 페이지의 HTML 문서에 소스 중에서 원하는 정보만 추출하는 기술이다.
-
웹스크래핑은 네이버 쇼핑 최저가 검새그 인스타그램 태그 검색 등 많은 곳에 사용 되고 있다.
필요한 Library
-
Axios
- 브라우저와 Node환경에서 사용하는 Promise 기반의 HTTP Client로 사이트의 HTML을 가져올 때 사용할 라이브러리이다. -
Cheerio
- Node.js환경에서 JQuery 처럼 DOM Selector 기능들을 제공합니다. Axios의 결과로 받은 데이터에서 필요한 데이터를 추출 하는데 사용하는 라이브러리 입니다.
Example
우선 예제를 가져오기전에 라이브러리들을 설치해야합니다.
yarn add axios cheerio import axios from "axios";
import cheerio from "cheerio";
async function createMessage() {
const url = "https://www.naver.com";
// 2. _axios.get으로 요청해서 html 코드 받아오기 _
const result = await axios.get(url);
// console.log(result.data);
// 3. _스크래핑 결과에서 OG(오픈그래프) 코드 골라내서 변수에 저장하기_
const $ = cheerio.load(result.data);
$ ("meta").each((i, el) => {
if ($(el).attr("property")?.includes("og:")) {
const key = $(el).attr("property");
const value = $(el).attr("content");
console.log(key, value);
}
});
}먼저 cheerio의 함수들의 기능들을 보자면,
-
load : 인자로 html 문자열을 받아 cheerio 객체를 반환한다.
-
each : 인자로 콜백함수를 받아 태그들의 배열을 순회 하면서 콜백함수를 실행한다.
-
attr : 위에서 해당 meta태그에서 속성이 property인 경우 og:title이면 title을 가져오고 content 속성의 값도 가져와 정보르 저장할 수 있다.

이렇게 필요한 부분을 반환 받아 log함수로 출력하게 되면 위에 이미지 처럼 출력이 된다.
Crawling
-
웹상의 정보들을 탐색하고 수집하는 작업을 의미히나다.
-
인터넷을 돌아다니며 여러 웹사이트에 접속하고 페이지의 내용과 링크의 복사본을 생성하여 다운로드하고 요약본을 만듭니다.
Crawling & Scraping 의 장점
- 심층 분석과 실시간 정보 제공에 유용한 -크롤링-
- 웹 크롤링은 웹상을 돌아다니며 방대한 양의 정보를 수집하기 때문에, 특정 키워드에 대한 심층 분석이 필요할 때 유용하다. 또한 실시간 정보 수집을 위해 계속해서 작동하므로 자주 변하는 데이터를 파악하기가 좋다.
- 정확한 정보를 요구할 때 쓰는 -스크래핑-
- 특정 사이트나 페이지에 대한 정보를 찾는데 집중하므로 데이터 포인트를 정확히 잡고 확실한 정보만을 수집할 수 있다. 장기적으로 서비스 대역폭이나 비용을 절약할 수 있다.
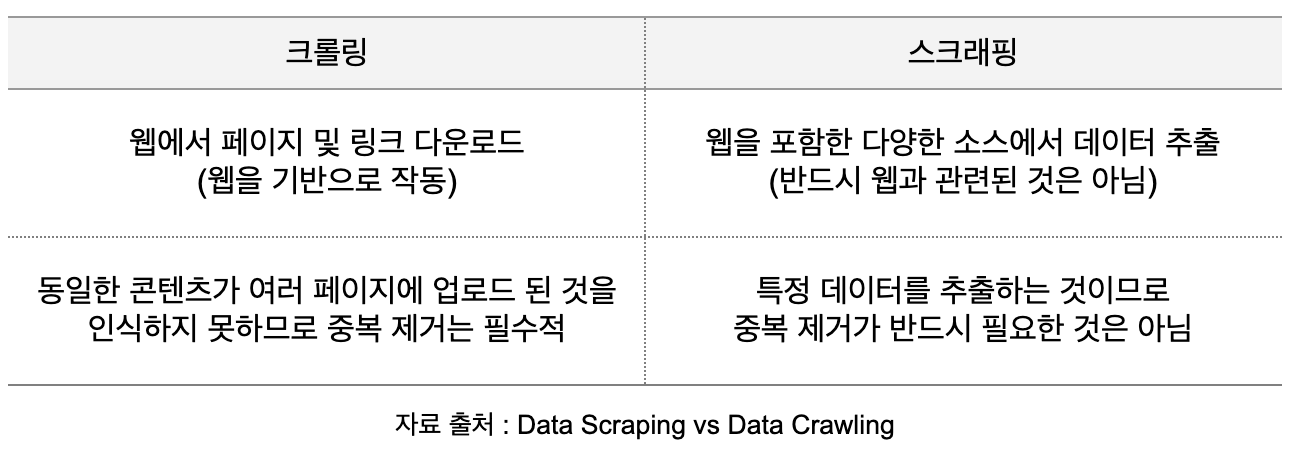
Crawling & Scraping 의 차이점
크롤링과 스크래핑은 '원하는 데이터를 모을 수 있다'는 점이 비슷하여 의미가 자주 혼용되곤 한다. 또한 기술적으로 함께 사용되는 경우가 많아 더욱 헷갈린다. 하지만 크롤링은 링크를 타고 계속해서 탐색을 이어나가지만, 스크래핑은 데이터 추출을 원하는 대상이 명확하여 특정한 사이트만 추적한다는 차이점이 있다.
마무리 하며,
끝으로,
크롤링은 모든 데이터를 모으기 때문에 정보의 확장성이 넓다는 장점이 있지만, 서버의 자리를 많이 차지하여 리소스가 많이 들어간다는 단점이 있다는 것을 알았고,
스크래핑은 반대로, 적은 리소를 들여 정확한 정보를 가져올 수 있지만 그만큼 데이터의 한계가 있다는 것을 알았다. 그리고 마구잡이로 데이터를 끌고 오게 되면 법적으로 문제가 있으니 참고해야겠다.
