
GAN이란?
-
GAN은 '생성적 적대 신경망'의 약자로 풀어서 쓰면, 생성자와 식별자가 서로 경쟁(Adversarial)하며 데이터를 생성(Generative)하는 모델(Network)을 뜻한다.
-
만약, GAN으로 인물 사진을 생성해 낸다면 인물 사진을 만들어내는 것을 Generator(생성자)라고 하며 만들어진 인물 사진을 평가하는 것을 Discriminator(구분자)라고 한다.
-
생성자와 구분자가 서로 대립하며(Adversarial:대립하는) 서로의 성능을 점차 개선해 나가는 쪽으로 학습이 진행되는 것이 주요 개념이다.
GAN의 구조와 원리
- Generator(생성자) : 생성된 z를 받아 실제 데이터와 비슷한 데이터를 만들어내도록 학습
- Discriminator(구분자) : 실제 데이터와 생성자가 생성한 가짜 데이터를 구별하도록 학습
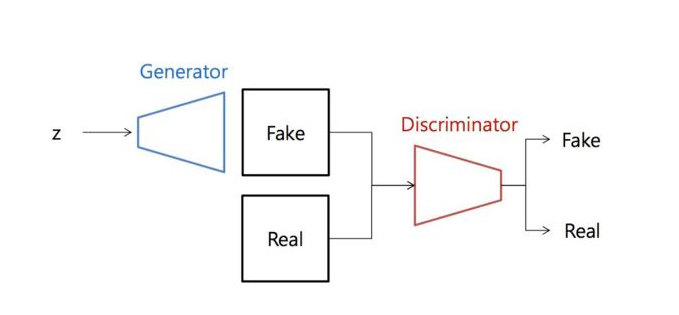
Generator는 입력 데이터의 분포(distribution)를 알아내도록 학습한다. 이 분포를 재현하여 원 데이터의 분포와 차이가 없도록 하고 Discriminator는 실데이터인지 가짜 데이터인지 구별해서 각각에 대한 확률을 추정한다.
Generator는 맨 위의 수식을 '최소화'시키는 방향으로, Discriminator는 '최대화'하는 방향으로 가게하는 minmax Problem
만약 Generator가 정확히 입력 데이터의 분포를 표현할 수 있으면 거기서 뽑은 샘플은 실제 데이터와 구별이 불가능 할 것입니다. Discriminator는 현재 데이터의 샘플이 진짜 데이터(입력)인지, 아니면 Generator로부터 만들어진 것인지 구별해서 각각의 경우에 대한 확률을 평가합니다.
실제 데이터의 분포에 가까운 데이터를 생성하는 것이 GAN이 가진 궁극적인 목표이며, 생성자(Generator)는 구분자(Discriminator)가 거짓으로 판별하지 못하도록 가짜 데이터를 진짜 데이터와 가깝게 생성하도록 노력한다. 이 과정을 통해 생성자(Generator)와 구분자(Discriminator)의 성능이 점차 개선되고 궁극적으로는 구분자(Discriminator)가 실제 데이터와 가짜 데이터를 구분하지 못하게 만드는 것이 목표이다.
GAN의 학습
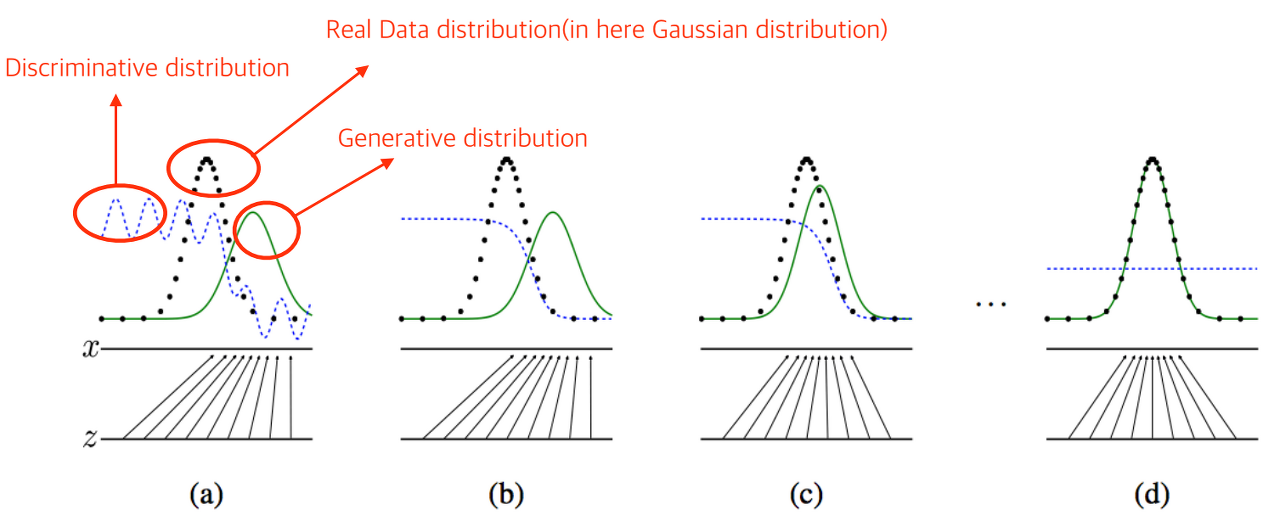
GAN의 구성요소인 두 모델 Generator와 Discriminator의 학습 진행 방법은 이러하다.
처음 학습이 진행되기 이전에 Real데이터의 확률분포, Generator의 확률분포, Discriminator의 확률분포의 그림이 (a)인데, Discriminator는 Generator와 기존 확률 분포가 얼마나 다른지 판단하게 된다. 그리고 Generator는 Real 확률분포에 맞춰 Discriminator를 속이기 위한 쪽으로 생성모델을 수정해 나가고 궁극적으로 Generator의 확률분포가 Real데이터의 확률분포와 차이를 줄여나가는 과정을 가지게 된다. (D(x)=0.5파란선)
GAN은 결국 주어진 데이터의 확률 분포를 예측하는 모델이다.
여기서 확률 분포간 차이를 계산하기위해 'JSD'를 사용한다. JSD는 두개의 'KLD'를 통해서 이루어지며 공식은 다음과 같다.
○ KLD(Kullback-Leibler Divergence)
: 같은 확률변수 x에 대한 2개의 확률분포 P(x)와 Q(x)가 있을 때, 이 두 분포사이의 차이를 의미
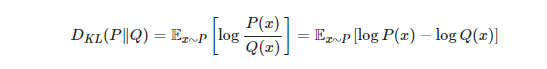
○ JSD(Jessen-Shannon Divergence)
: KLD의 문제는 asymmetric하다는 것. KL(P|Q)KL(P|Q)와 KL(Q|P)KL(Q|P)의 값이 서로 다르기 때문에 이를 “거리”라는 척도로 사용하기에는 애매한 부분이 존재하며 JSD는 이러한 문제를 해결할 수 있는 방법.
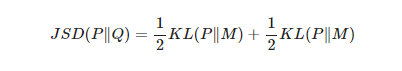
- P : 원 확률분포
- Q : Generator의 확률분포
- M : 원 확률분포와 Q의 평균
P와 M과 / Q와 M을 각각 KLD하여 두 분포의 차이에서 평균 값을 구해 두 확률 분포 간의 차이를 구한다.
이러한 발산 과정을 통해, 원 데이터의 확률분포가 Generator가 생성한 확률분포인 Q 간의 JSD가 0이 되면 두 분포간 차이가 없다는 것으로 학습이 완료되며 GAN의 궁극적인 목표에 도달하게 된다.
출처: https://ebbnflow.tistory.com/167 [Dev Log : 삶은 확률의 구름]
