
RNN의 기본구조
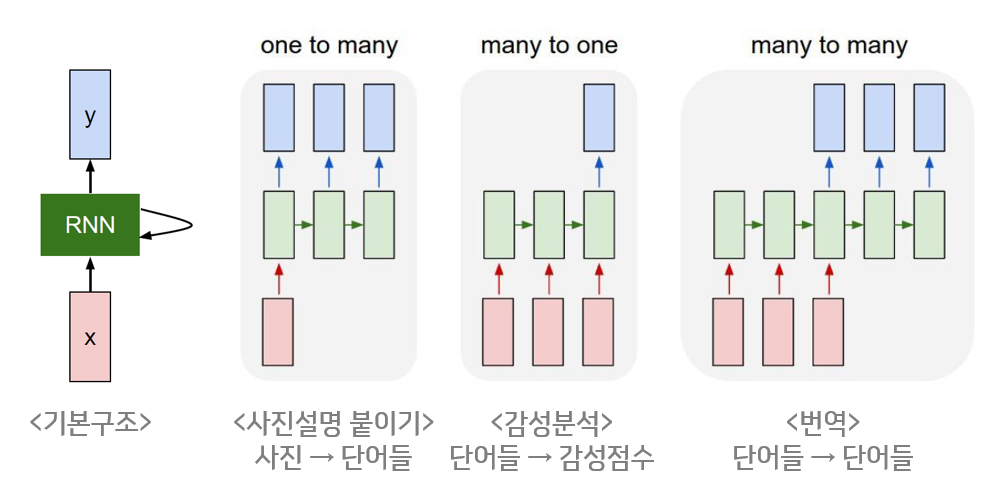
RNN은 히든 노드가 방향을 가진 엣지로 연결돼 순환구조를 이루는(directed cycle) 인공신경망의 한 종류이다. 음성, 문자 등 순차적으로 등장하는 데이터 처리에 적합한 모델로 많이 알려져 있다.
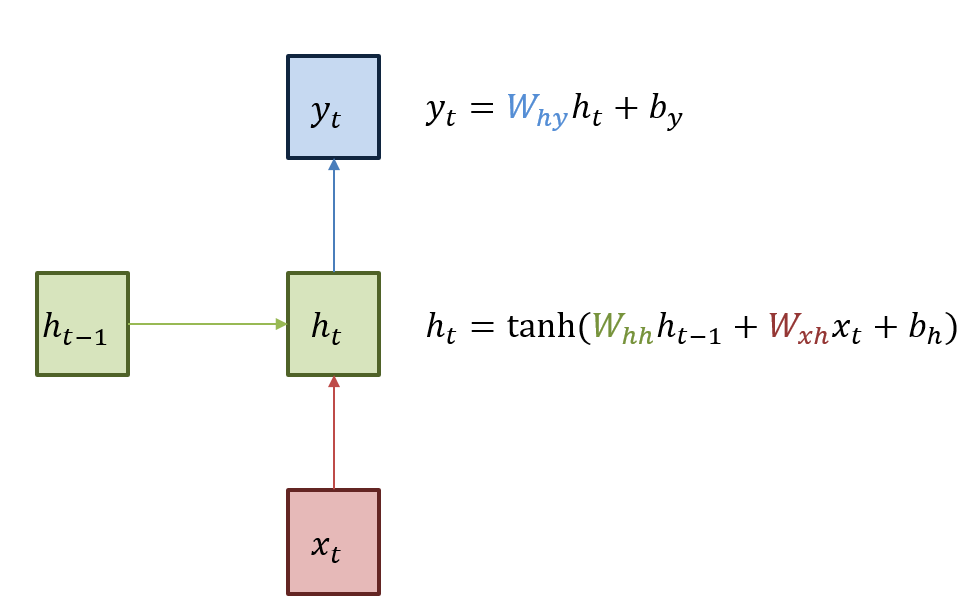
RNN의 기본구조를 설명하면, 녹색으로 된 박스는 hidden state를 의미를 하며, 빨간색은 input , 파란색은 output 를 의미한다. RNN은 현재 상태의 hidden state 는 직전시점의 hidden state 를 받아 갱신된다.
현재 상태의 output 는 를 전달받아 갱신되는 구조이다. 수식에서도 알 수 있듯 hidden state의 활성함수(activation function)은 Nonlinear 함수인 (tanh)함수이다.
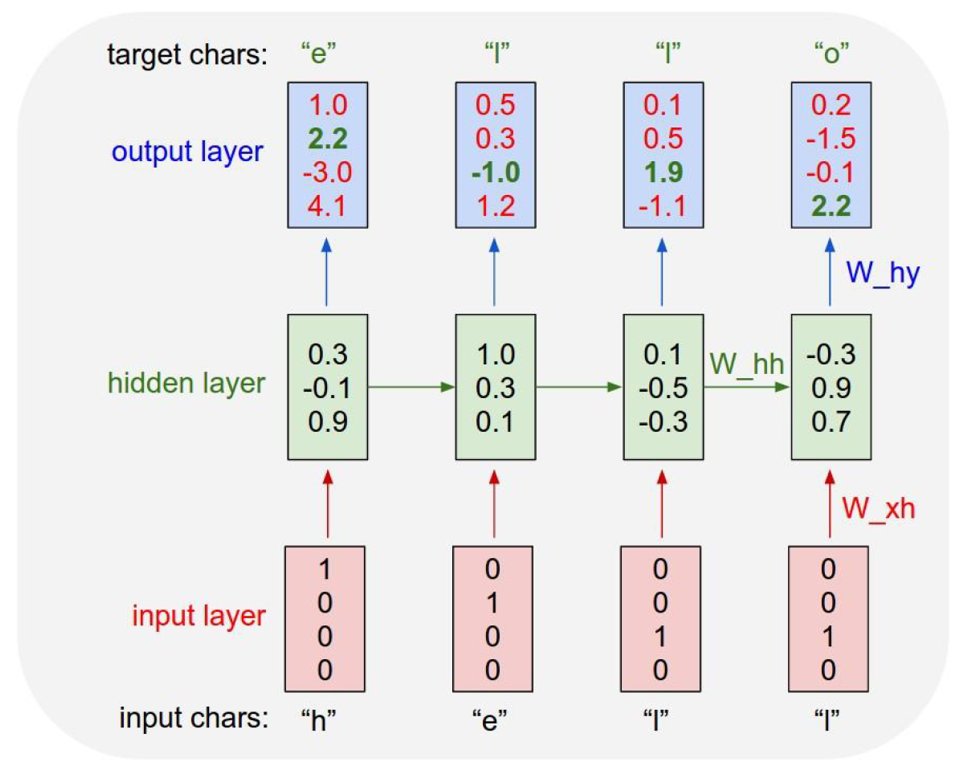
예시를 들면, RNN모델에 "hell"을 넣어서 "o"를 반환하게해 결과적으로 "hello"를 출력하게 만들겠다고 해보자.
먼저 우리가 가진 학습데이터는 "h","e","l","l"인데 이를 one-hot vector로 바꾸게 되면이 되게 된다.
은 이고 이를 기반으로 인 를 만들게 된다.(는 없기 때문에 random으로 값을 넣어준다. 또 이 을 기반으로 로 생성을하고 그 다음 단계들도 모두 값을 갱신하게 한다. 이 과정을 순전파(Foward Propagation)이라고 한다.
다른 인공신경망과 마찬가지로 RNN도 정답을 필요로 하는데, 모델에 정답을 알려줘야 모델이 "parameter"를 적절히 갱신해 나가기 때문에 이 경우엔 바로 다음 글자가 정답이 되게 된다. ‘h’의 다음 정답은 ‘e’, ‘e’ 다음은 ‘l’, ‘l’ 다음은 ‘l’, ‘l’ 다음은 ‘o’가 정답이 되게 된다.
위의 그림을 기준으로 설명을 하면 첫번째 정답인 ‘e’는 두번째 요소만 1이고 나머지가 0인 one-hot-vector이다. 그림을 보면 output에 진한 녹색으로 표시된 숫자들이 있는데 정답에 해당하는 index를 의미한다. 이 정보를 바탕으로 역전파(backpropagation)를 수행해 parameter값들을 갱신해 나가게 된다.

RNN의 hidden layer 연산을 그림으로 표현하면 위와 같은데, input 를 hidden layer 로 보내는 , 이전 hidden layer 에서 다음 hidden layer 로 보내는 , hidden layer 에서 output 로 보내는 가 바로 "parameter"가 되게 된다. 모든 시점의 state에서 이 parameter는 동일하게 적용된다.
RNN의 Forwardpropagation
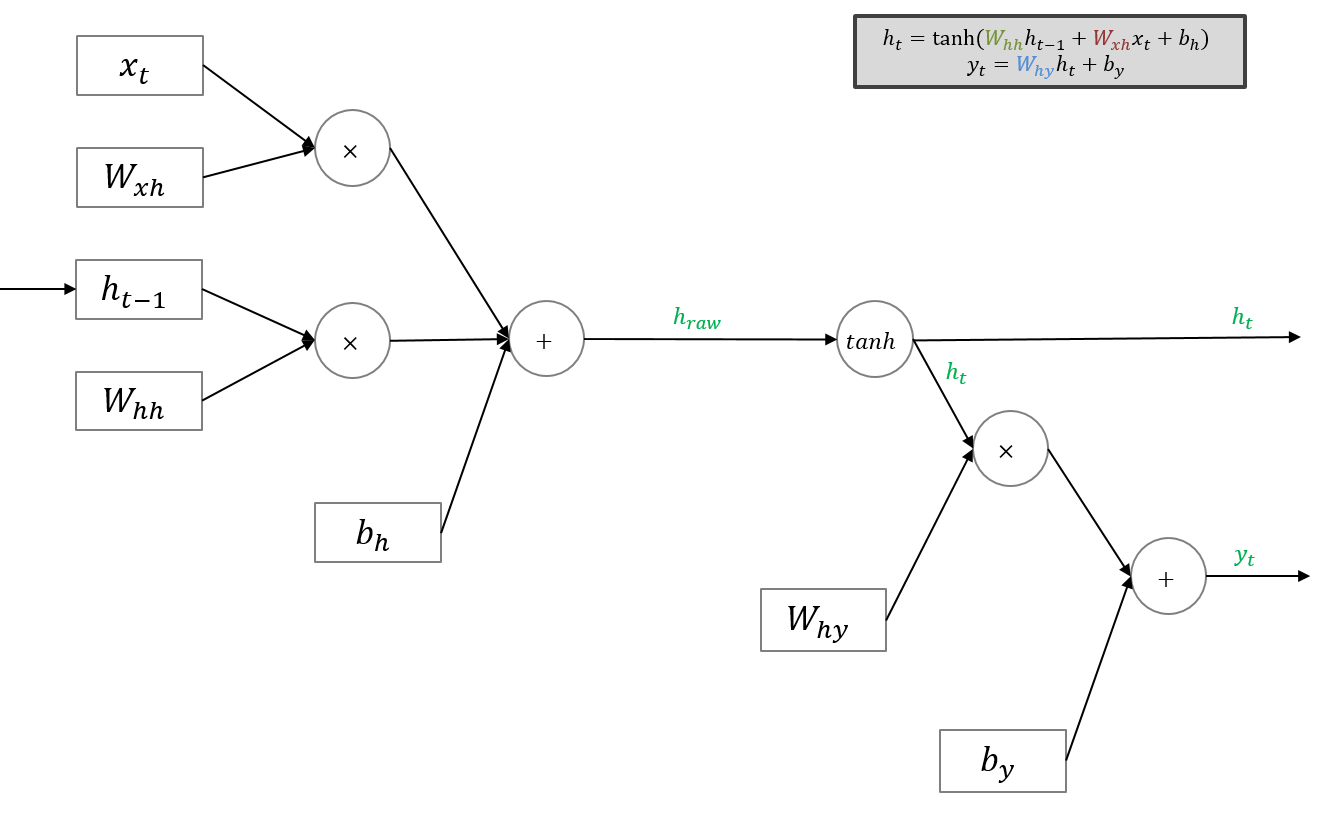
위에서 설명한 수식을 그래프로 옮겨놓은 것 뿐이다.
RNN의 Backpropagation
Backpropagation을 하는 이유
- Forwardpropagation시에 Parameter가 매우 많고 layer가 여러개 있을때 가중치와 를 학습시키기 어려웠다는 문제이다. 이를 해결하기 위해 Backpropagation을 하는 것인데 각 layer에서 기울기 값을 구하고 그 기울기 값을 이용하여 Gradient descent 방법으로 가중치와 를 update시키면서 해결된 것이다.
- 즉, layer에서 기울기 값을 구하는 이유는 Gradient descent를 이용하여 가중치를 update하기 위함!!!
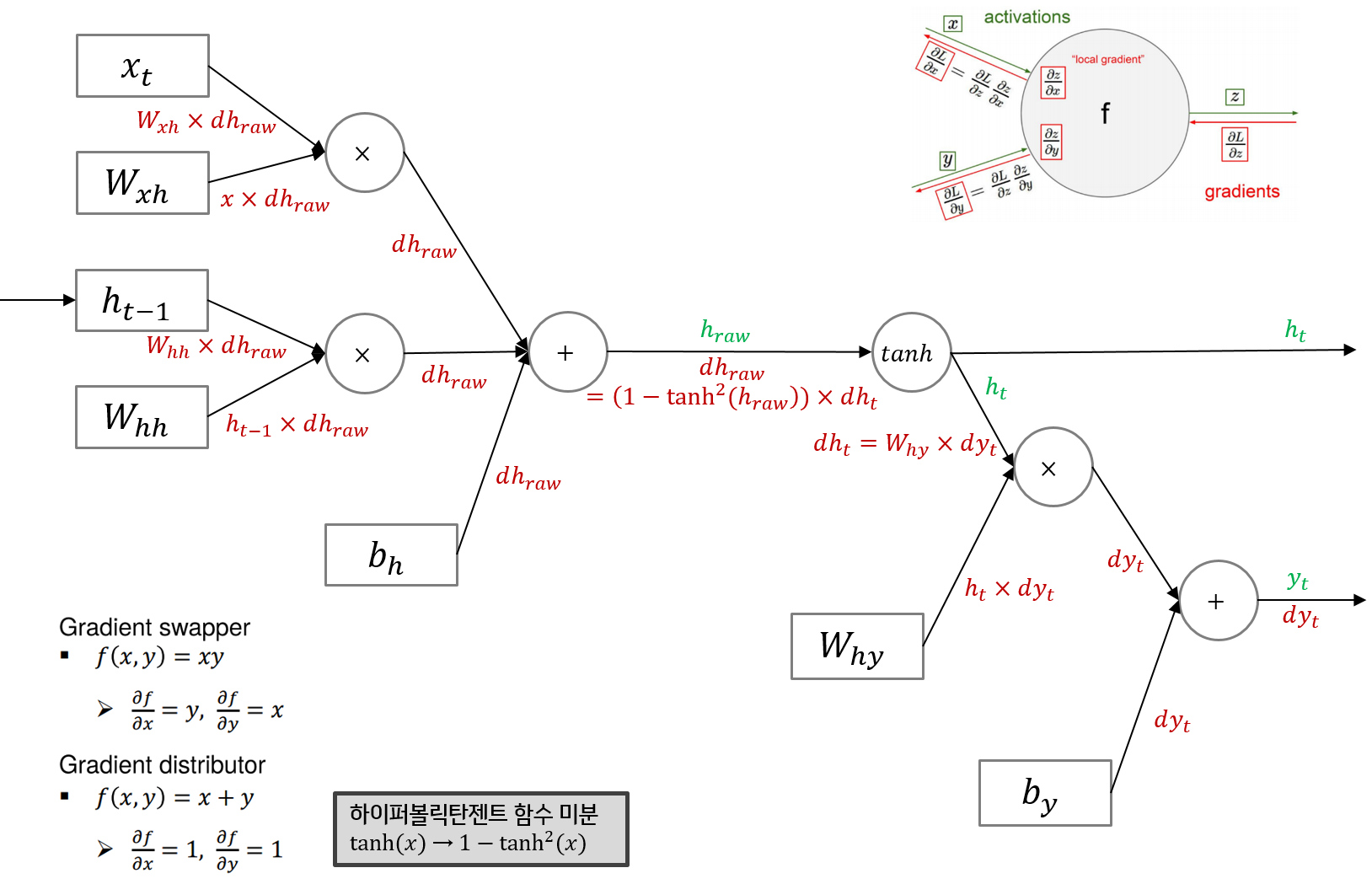
우선 forward pass를 따라 최종 출력되는 결과는 이다. 최종 Loss에 대한 의 그래디언트()가 RNN의 역전파 연산에서 가장 먼저 등장한다. 이를 편의상 라고 표기했고, 순전파 결과 와 대비해 붉은색으로 표시했다.
는 덧셈 그래프를 타고 양방향에 모두 그대로 분배가 되고 는 흘러들어온 그래디언트 에 로컬 그래디언트 를 곱해 구한다. 는 흘러들어온 그래디언트 에 를 곱한 값이다. 는 흘러들어온 그래디언트인 에 로컬 그래디언트인 을 곱해 구하게되고, 나머지도 동일한 방식으로 구하게된다.
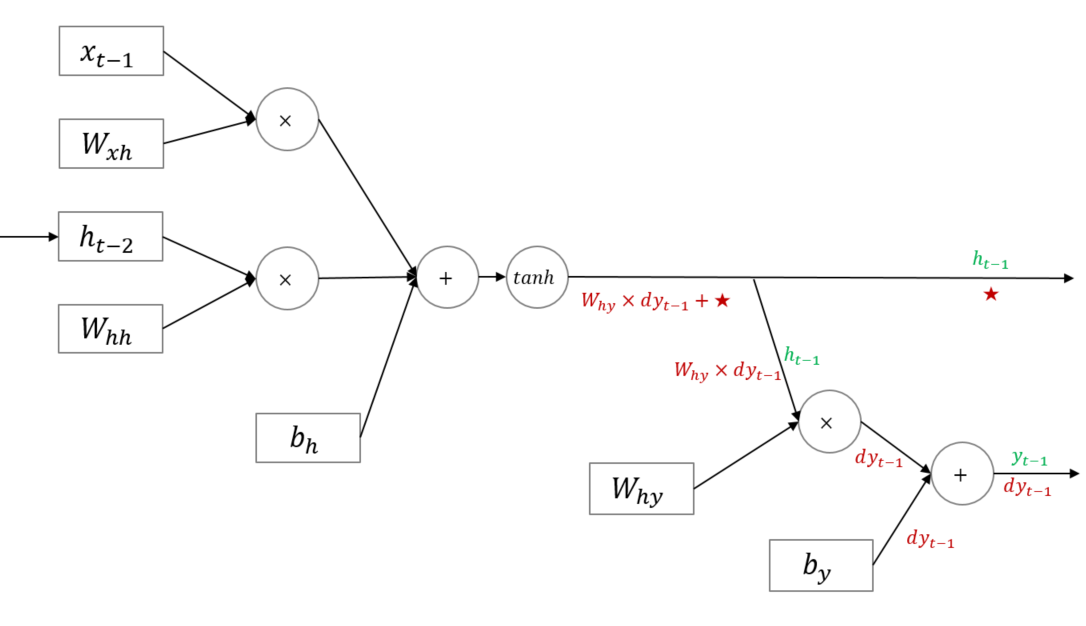
다만 위 그림에 주의할 필요가 있는데, RNN은 Hidden node가 순환 구조를 띄는 신경망이다. 즉 를 만들 때 가 반영된다. 바꿔 말하면 아래 그림의 은 시점의 Loss에서 흘러들어온 그래디언트인 뿐 아니라 ★에 해당하는 그래디언트 또한 더해져 동시에 반영된다는 뜻이다.
참고자료
- https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
(ratsgo`s bolog, RNN과 LSTM을 이해해보자!) - https://ganghee-lee.tistory.com/31
- https://wikidocs.net/22886
