Strings and Characters
Swift의 String과 Character 타입은 빠르고, 코드를 작성할 때 유니코드를 준수할 수 있도록 한다. 모든 문자열은 유니코드 형식에 비의존적인 인코딩으로 구성된다. 다양한 유니코드 형식의 문자에 접근할 수 있도록 지원한다.
Swift의
String은Foundation프레임워크의NSString이 bridge된 타입이기 때문에NSString의 메소드를String에서 캐스팅 없이 사용 가능하다.
문자열 리터럴 (String Literals)
문자열 리터럴은 쌍따옴표(")로 둘러싸인 문자의 연속이다.
let someString = "Some string literal value"Swift는 someString의 초기값이 문자열 리터럴로 들어왔기 때문에 String 타입으로 추론하게 된다.
여러 줄 문자열 리터럴
여러 줄에 걸쳐 문자열을 작성해야 할 경우, 문자 시퀀스를 쌍따옴표 세 개로 감싸서 사용할 수 있다.
let quotation = """
The White Rabbit put on his spectacles. "Where shall I begin,
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on
till you come to the end; then stop."
"""여러 줄 문자열 리터럴은 맨 처음 """ 다음 첫 번째 줄부터 시작해 마지막 """ 직전에 끝난다.
let singleLineString = "These are the same."
let multilineString = """
These are the same.
"""여러 줄 문자열 리터럴을 사용할 때, 줄바꿈 역시 문자열의 값으로 인식된다. 따라서 줄바꿈을 통해 코드의 가독성을 높이고 싶지만 줄바꿈을 문자열의 값에 포함시키고 싶지 않다면 각 줄의 끝에 백슬래시(\)를 추가한다.
let softWrappedQuotation = """
The White Rabbit put on his spectacles. "Where shall I begin, \
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on \
till you come to the end; then stop."
"""문자열의 시작과 끝 빈 줄을 넣고 싶다면 한 줄을 띄어서 문자열을 입력한다.
let lineBreaks = """
This string starts with a line break.
It also ends with a line break.
"""마지막 """의 위치를 기준으로 들여쓰기가 가능하다. 닫는 """ 위치 앞에 있는 문자들은 전부 무시되고 그 이후의 공백은 문자열에 반영된다.
let linesWithIndentation = """
This line doesn`t with whitespace.
This line begins with four spaces.
This line doesn`t with whitespace.
"""문자열 리터럴의 특수 문자
\0: 빈 문자
\\: 백슬래시
\t: 수평 탭
\n: 줄바꿈
\r: 캐리지 리턴
\": 쌍따옴표
\': 홑따옴표
\u{n}: 유니코드 스칼라. n은 1에서 8자리 16진수로 구성된다.
let wiseWords = "\"Imagination is more important than knowledge\" - Einstein"
// "Imagination is more important than knowledge" - Einstein
let dollarSign = "\u{24}" // $, Unicode scalar U+0024
let blackHeart = "\u{2665}" // ♥, Unicode scalar U+2665
let sparklingHeart = "\u{1F496}" // 💖, Unicode scalar U+1F496여러 줄 문자열 리터럴은 세 개의 쌍따옴표를 사용하기 때문에, 백슬래시 없이 쌍따옴표를 넣을 수 있다. 세 개의 쌍따옴표를 넣으려면 적어도 하나의 쌍따옴표 앞에 백슬래시를 붙여야 한다.
let threeDoubleQuotationMarks = """
Escaping the first quotation mark \"""
Escaping all three quotation marks \"\"\"
"""확장된 문자열 구분 문자 (Extended String Delimiters)
확장된 문자열 구분 문자 안에 문자열 리터럴을 넣음으로써 특수 문자의 효과가 사라지게 할 수 있다. # 안에 문자열 리터럴 혹은 여러 줄 문자열 리터럴을 넣는다. 만약 특수 문자의 효과가 필요하다면 이스케이프 문자(\) 뒤에 #을 붙이면 된다.
let extendedStringDelimiters = #"""
Here are three more double quotes: """
"""#
// Prints "Here are three more double quotes: """"
let extendedSingleLine = #"Line 1\nLine 2"#
// Prints "Line 1\nLine 2"
let extendedUseSpecial = #"Line 1\#nLine 2"#
// Prints Line 1
// Line 2빈 문자열 초기화
빈 문자열 리터럴("")을 변수에 할당하거나, initializer를 통해 새로운 String 인스턴스로 초기화하여 빈 문자열을 만들 수 있다.
var emptyString = "" // empty string literal
var anotherEmptyString = String() // initializer syntax
// these two strings are both empty, and are equivalent to each otherisEmpty 프로퍼티를 사용해 빈 문자열인지 확인할 수 있다.
if emptyString.isEmpty {
print("Nothing to see here")
}
// Prints "Nothing to see here"문자열 수정
문자열을 변수로 선언하면 수정하거나 변경할 수 있지만, 상수로 선언하면 할 수 없다.
var variableString = "Horse"
variableString += " and carriage"
// variableString is now "Horse and carriage"
let constantString = "Highlander"
constantString += " and another Highlander"
// this reports a compile-time error - a constant string cannot be modified이러한 접근법은
NSString과NSMutableString으로 구분하는 Objective-C, Cocoa와 다르다.
값 타입 문자열
Swift의 String은 값 타입(value type)이다. 그래서 String이 다른 함수 혹은 메소드로 부터 생성되거나 상수/변수로 String값이 할당 될때, 이전 String의 레퍼런스를 할당하는 것이 아니라 값을 복사해서 생성한다.
Swift의 copy-by-default String behavior는 다른 메소드, 함수에서 반환 받은 문자열이 그 자신의 값을 가지고 있는 것을 보장한다. 그 문자열을 수정해도 원본 문자열이 변하지 않기 때문에 편하게 사용할 수 있다.
뒤에서 Swift의 컴파일러는 복사본이 실질적으로 필요한 만큼만 공간을 갖게 하여 String의 사용을 최적화한다.
문자 (Characters)
for-in 반복문에서 문자열을 순회할 때 각각의 Character에 접근할 수 있다.
for character in "Dog!🐶" {
print(character)
}
// D
// o
// g
// !
// 🐶Character 타입을 지정함으로써 단일 문자 상수/변수를 만들 수도 있다.
let exclamationMark: Character = "!"Character의 배열을 String의 initializer에 인자로 넣어서 문자열을 생성할 수 있다.
let catCharacters: [Character] = ["C", "a", "t", "!", "🐱"]
let catString = String(catCharacters)
print(catString)
// Prints "Cat!🐱"문자열과 문자의 결합
덧셈 사칙 연산자(+)를 사용하여 문자열을 합칠 수 있다.
let string1 = "hello"
let string2 = " there"
var welcome = string1 + string2
// welcome now equals "hello there"덧셈 합성 할당 연산자를 써서 기존의 문자열에 더할 수 있다.
var instruction = "look over"
instruction += string2
// instruction now equals "look over there"append() 메소드를 사용해 문자열에 문자를 더하는 것이 가능하다.
let exclamationMark: Character = "!"
welcome.append(exclamationMark)
// welcome now equals "hello there!"반대로
Character에String이나Character를 더하는 것은 불가능하다.Character는 반드시 하나의 단일 문자만을 가져야 하기 때문이다.
만약 여러 줄 문자열 리터럴을 사용 중이라면, 마지막 줄을 포함한 모든 줄의 끝에 개행문자를 포함시키고 싶을 것이다.
let badStart = """
one
two
"""
let end = """
three
"""
print(badStart + end)
// Prints two lines:
// one
// twothree
let goodStart = """
one
two
"""
print(goodStart + end)
// Prints three lines:
// one
// two
// three위의 코드에서, badStart와 end를 더했을 때, badStart의 마지막에는 개행문자가 없기 때문에 결과가 두 줄로 나온다. 반면 goodStart는 마지막에 한줄 띄어져 있기 때문에 의도한 대로 결과가 나온다.
문자열 보간 (String Interpolation)
문자열 보간은 상수, 변수, 리터럴, 표현식의 값을 문자열 리터럴에 포함시킴으로써 새로운 문자열을 만드는 방법이다. \()의 괄호 안에 각각의 아이템을 넣는다.
let multiplier = 3
let message = "\(multiplier) times 2.5 is \(Double(multiplier) * 2.5)"
// message is "3 times 2.5 is 7.5"확장된 문자열 구분 문자에서 문자열 보간을 사용하려면 백슬래시와 괄호 사이에 #을 삽입해 줘야 한다.
print(#"Write an interpolated string in Swift using \(multiplier)."#)
// Prints "Write an interpolated string in Swift using \(multiplier)."
print(#"6 times 7 is \#(6 * 7)."#)
// Prints "6 times 7 is 42."괄호 안에 들어가는 문자열은 단일 백슬래시(\), 캐리지 리턴, 개행 문자를 포함할 수 없다. 다른 문자열 리터럴은 가능하다.
유니코드 (Unicode)
유니코드는 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 국제 표준이다. Swift의 문자열과 문자 타입은 유니코드에 순응(compliant)한다.
유니코드 스칼라 (Unicode Scalar)
Swift의 네이티브 문자열 타입은 유니코드 스칼라 값으로 만들어졌다. 하나의 유니코드는 고유한 21비트 숫자로 구성돼 있다. 예를 들면 U+0061는 라틴어의 소문자 a를 나타내고 U+1F425는 정면의 병아리 🐥 를 나타낸다.
모든 21비트 유니코드 스칼라가 문자로 할당되는 것은 아니다(미래에 UTF-16 인코딩으로 사용하기 위해 예약되기도 한다). 문자에 할당된 스칼라 값은 일반적으로 이름을 가진다.
확장된 문자소 클러스터 (Extended Grapheme Clusters)
스위프트 문자 타입의 모든 인스턴스는 하나의 확장된 문자소 클러스터를 대표한다. 확장된 문자소 클러스터는 읽을 수 있는 단일 문자를 제공하는 하나 또는 그 이상의 유니코드 스칼라 의 시퀀스다.
예를 들어, é는 단일 유니코드 스칼라 é로 대표될 수 있다. 이 문자는 표준 문자 e와 COMBINING ACUTE ACCENT 스칼라 쌍으로도 대표될 수 있다. Unicode-aware text-rendering system에 의해 é로 렌더링 된다.
두 가지 경우 모두 é는 Swift의 단일 문자 값으로 대표된다. 첫 번째 케이스에서는 단일 스칼라가, 두 번째 케이스에서는 두 개의 스칼라 집합이 된다.
let eAcute: Character = "\u{E9}" // é
let combinedEAcute: Character = "\u{65}\u{301}" // e followed by ́
// eAcute is é, combinedEAcute is é확장된 문자소 클러스터는 복잡하게 구성되어 있는 단일 문자 값을 유연하게 표현할 수 있게 해준다.
let precomposed: Character = "\u{D55C}" // 한
let decomposed: Character = "\u{1112}\u{1161}\u{11AB}" // ᄒ, ᅡ, ᆫ
// precomposed is 한, decomposed is 한확장된 문자소 클러스터는 enclosing marks를 단일 문자의 일부분으로써 다른 유니코드 스칼라에 덧붙일 수 있게 한다.
let enclosedEAcute: Character = "\u{E9}\u{20DD}"
// enclosedEAcute is é⃝단일 문자 값을 만들기 위해 지역 구분 심볼 유니코드 스칼라를 결합할 수 있다.
let regionalIndicatorForUS: Character = "\u{1F1FA}\u{1F1F8}"
// regionalIndicatorForUS is 🇺🇸문자열 세기
문자열 안에 있는 문자의 개수를 세기 위해, count 프로퍼티를 사용한다.
let unusualMenagerie = "Koala 🐨, Snail 🐌, Penguin 🐧, Dromedary 🐪"
print("unusualMenagerie has \(unusualMenagerie.count) characters")
// Prints "unusualMenagerie has 40 characters"Swift는 확장된 문자소 클러스터를 사용하기 때문에, 문자열의 연결이나 수정이 항상 문자열의 count에 영향을 미칠 수 있는 것은 아니다.
예를 들어 "cafe"라는 문자열에 COMBINING ACUTE ACCENT를 더할 경우, 네 번째 문자 e가 é로 바뀌어 전체 문자열 길이는 변하지 않게 된다.
var word = "cafe"
print<("the number of characters in \(word) is \(word.count)")
// Prints "the number of characters in cafe is 4"
word += "\u{301}" // COMBINING ACUTE ACCENT, U+0301
print("the number of characters in \(word) is \(word.count)")
// Prints "the number of characters in café is 4""확장된 문자소 클러스터는 여러 개의 유니코드 스칼라로 구성될 수 있다."
이 말은 다른 문자(또는 다르게 표현되는 같은 문자)는 서로 다른 양의 메모리를 차지하고 있다는 뜻이다.
count프로퍼티로 구한 문자의 개수는NSString의length프로퍼티로 구한 것과 항상 같지는 않다.NSString의 길이는UTF-16의 16비트에 기반을 두고 있기 때문이다.
문자열 접근 및 수정
문자열 인덱스
각각의 문자 값은 관련된 인덱스 타입인 String.Index를 갖고 있다.
서로 다른 문자는 다른 양의 메모리 공간을 요구한다. 때문에 각 Character의 특정한 위치를 결정하기 위해선 문자열의 처음부터 끝까지 각 유니코드 스칼라를 순회해야 한다. 이러한 이유로 Swift의 문자열은 정수 값의 인덱스를 가질 수 없다.
startIndex: 첫 번째 문자의 인덱스.
endIndex: 마지막 문자의 다음 위치. 따라서endIndex는 문자열 범위에 포함되지 않는다.
index(before:): 특정 인덱스 이전.
index(after:): 특정 인덱스 이후.
index(_:offsetBy:): 특정 인덱스에서 offsetBy만큼 떨어진 인덱스.
let greeting = "Guten Tag!"
greeting[greeting.startIndex]
// G
greeting[greeting.index(before: greeting.endIndex)]
// !
greeting[greeting.index(after: greeting.startIndex)]
// u
let index = greeting.index(greeting.startIndex, offsetBy: 7)
greeting[index]
// a문자열 범위를 벗어난 인덱스에 접근하려 할 경우 런타임 에러가 발생한다.
greeting[greeting.endIndex] // Error
greeting.index(after: greeting.endIndex) // Errorindices 프로퍼티를 사용해 문자열 내 모든 문자의 인덱스에 접근할 수 있다.
for index in greeting.indices {
print("\(greeting[index]) ", terminator: "")
}
// Prints "G u t e n T a g ! "
startIndex,endIndex,index(before:),index(after:),index(_:offsetBy:)메소드는String뿐만 아니라Collection프로토콜에도 적용할 수 있다.
삽입과 삭제
단일 문자를 문자열의 특정 인덱스에 삽입하고자 할 때 insert(_:at:) 메소드를 사용한다. 다른 문자열을 삽입하려면 insert(contentsOf:at:) 메소드를 써야 한다.
var welcome = "hello"
welcome.insert("!", at: welcome.endIndex)
// welcome now equals "hello!"
welcome.insert(contentsOf: " there", at: welcome.index(before: welcome.endIndex))
// welcome now equals "hello there!"특정 인덱스의 단일 문자를 삭제하려면 remove(at:)을, 특정 범위의 부분 문자열을 삭제하려면 removeSubrange(_:) 메소드를 사용한다.
welcome.remove(at: welcome.index(before: welcome.endIndex))
// welcome now equals "hello there"
let range = welcome.index(welcome.endIndex, offsetBy: -6)..<welcome.endIndex
welcome.removeSubrange(range)
// welcome now equals "hello"위 메소드들은
RangeReplaceableCollection프로토콜에도 적용할 수 있다.
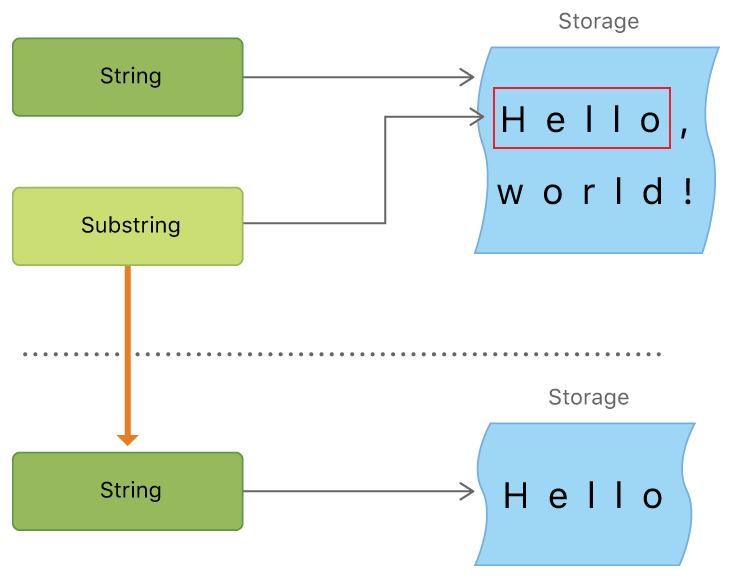
부분 문자열 (Substrings)
문자열에서 부분 문자열을 얻을 때 String이 아닌 Substring의 인스턴스를 결과로 반환받게 된다. Swift의 Substring은 문자열에서 쓸 수 있는 대부분의 메소드를 사용할 수 있다. 하지만 문자열과 달리 부분 문자열은 짧은 기간에만 쓰는 것이 좋다. 긴 시간 동안 부분 문자열을 저장해야 한다면 부분 문자열을 문자열의 인스턴스로 바꿔야 한다.
let greeting = "Hello, world!"
let index = greeting.firstIndex(of: ",") ?? greeting.endIndex
let beginning = greeting[..<index]
// beginning is "Hello"
// Convert the result to a String for long-term storage.
let newString = String(beginning)부분 문자열도 문자열처럼 메모리 공간을 갖고 있다. 성능 최적화 관점에서 둘에 차이점이 존재하는데, 부분 문자열은 원본 문자열 혹은 다른 부분 문자열 메모리 일부분을 참조해 재사용한다.
때문에 SubString을 계속 이용하는 이상은 원본 String이 계속 메모리에 남아 있게 된다. 사용하지 않는 문자열까지도 남게 되는 것이다. 그렇게 때문에 SubString을 오래 사용하고자 한다면 String에서 인스턴스로 만들어 사용하고자 하는 문자만 메모리에 올려놓고 사용하는 것이 관리 효율면에서 좋다.
String과SubstringStringProtocol프로토콜을 따른다. 그래서 문자 조작에 필요한 편리한 메소스들을 공통으로 사용할 수 있다.
문자열 비교
Swift는 세 가지 문자열 비교 방법을 제공한다.
- 문자열과 문자 동등
- 접두사 동등
- 접미사 동등
문자열과 문자 동등 (String and Character Equality)
== 연산자와 != 연산자를 사용하여 문자열과 문자가 같은지 비교한다.
let quotation = "We're a lot alike, you and I."
let sameQuotation = "We're a lot alike, you and I."
if quotation == sameQuotation {
print("These two strings are considered equal")
}
// Prints "These two strings are considered equal"두 문자열(또는 두 문자) 값의 확장된 문자소 클러스터가 동일하다면, 같은 것으로 취급한다.
// "Voulez-vous un café?" using LATIN SMALL LETTER E WITH ACUTE
let eAcuteQuestion = "Voulez-vous un caf\u{E9}?"
// "Voulez-vous un café?" using LATIN SMALL LETTER E and COMBINING ACUTE ACCENT
let combinedEAcuteQuestion = "Voulez-vous un caf\u{65}\u{301}?"
if eAcuteQuestion == combinedEAcuteQuestion {
print("These two strings are considered equal")
}
// Prints "These two strings are considered equal"반면, 같은 유니코드 문자여도 유니코드가 다르면 다른 문자로 판별한다. 영어권에서 사용되는 라틴 문자 "A"와 러시아권에서 사용하는 카톨릭 문자 "A"는 다르게 취급된다. 언어적 의미가 다르기 때문이다.
let latinCapitalLetterA: Character = "\u{41}"
let cyrillicCapitalLetterA: Character = "\u{0410}"
if latinCapitalLetterA != cyrillicCapitalLetterA {
print("These two characters are not equivalent.")
}
// Prints "These two characters are not equivalent."Swift에서 문자열과 문자의 비교는 언어를 고려하지 않는다. 언어와 상관없이 같은 문자면 같은 것으로 여긴다.
접두사와 접미사 비교
hasPrefix(_:), hasSuffix(_:) 메소드를 사용하여 접두사와 접미사를 비교할 수 있다.
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
"Act 1 Scene 4: A street outside Capulet's mansion",
"Act 1 Scene 5: The Great Hall in Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
"Act 2 Scene 4: A street in Verona",
"Act 2 Scene 5: Capulet's mansion",
"Act 2 Scene 6: Friar Lawrence's cell"
]
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("There are \(act1SceneCount) scenes in Act 1")
// Prints "There are 5 scenes in Act 1"
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) mansion scenes; \(cellCount) cell scenes")
// Prints "6 mansion scenes; 2 cell scenes"접두사, 접미사 비교 역시 문자열과 문자 비교와 동일한 방식으로 수행된다.
문자열의 유니코드 표현
유니코드 문자열이 텍스트 파일또는 저장소의 다른 파일로 쓰여졌을 때, 그 문자열의 유니코드 스칼라는 다양한 유니코드 인코딩 형태 중 하나로 인코딩된다. 각각의 형태는 문자열을 코드 유닛으로 알려진 작은 청크로 인코딩한다. UTF-8(8비트 코드 유닛으로 인코딩), UTF-16, UTF-32 등을 포함한다.
Swift는 문자열의 유니코드 표현에 몇 가지 다른 접근 방식을 제공한다.
- UTF-8 코드 유닛의 컬렉션 (문자열의
utf8프로퍼티로 접근한다.) - UTF-16 코드 유닛의 컬렉션 (문자열의
utf16프로퍼티로 접근한다.) - 21비트 유니코드 스칼라 값의 컬렉션 (이는 UTF-32와 동일하게 취급되며, 문자열의
unicodeScalars프로퍼티로 접근한다.)
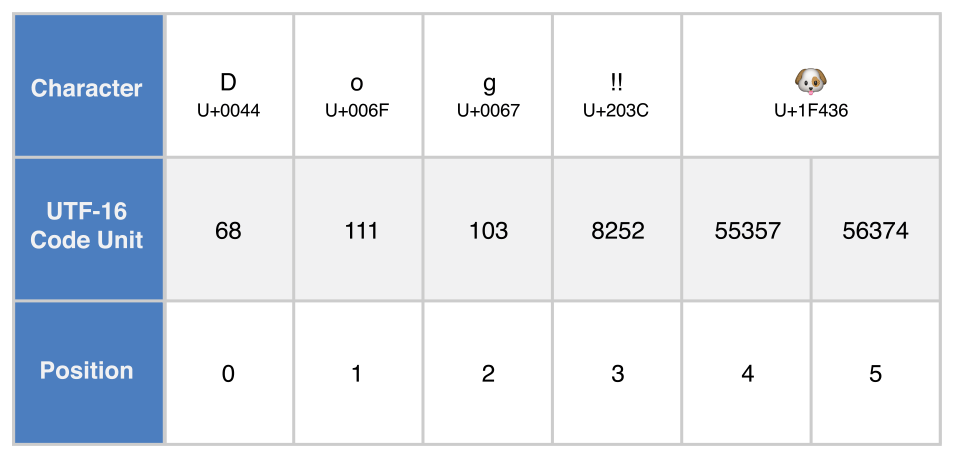
let dogString = "Dog‼🐶"UTF-8 표현
utf8 프로퍼티는 String.UTF8View 타입으로, UInt8 값의 컬렉션이다.
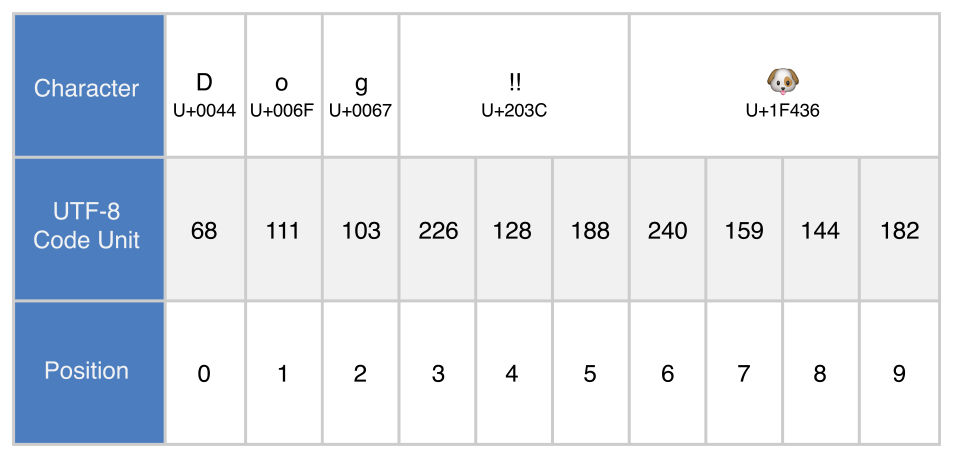
for codeUnit in dogString.utf8 {
print("\(codeUnit) ", terminator: "")
}
print("")
// Prints "68 111 103 226 128 188 240 159 144 182 "UTF-16 표현
utf16 프로퍼티는 String.UTF16View 타입으로, UInt16 값의 컬렉션이다.
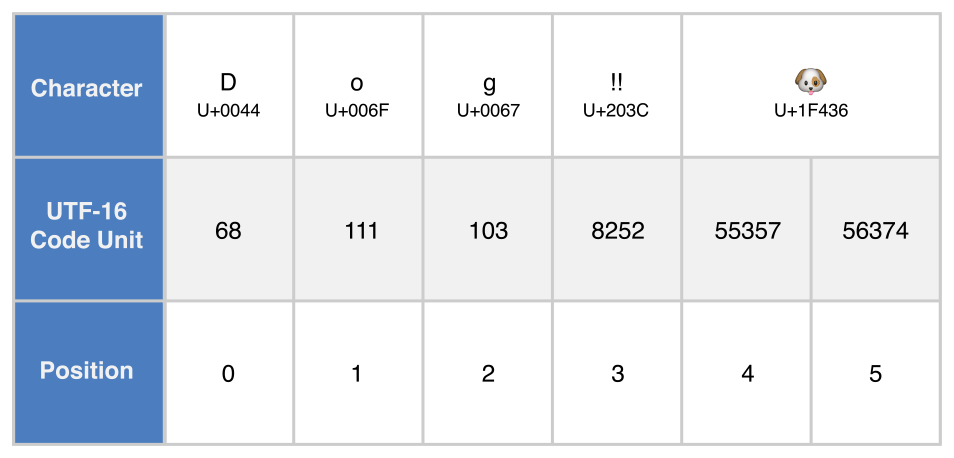
for codeUnit in dogString.utf16 {
print("\(codeUnit) ", terminator: "")
}
print("")
// Prints "68 111 103 8252 55357 56374 "유니코드 스칼라
unicodeScalars 프로퍼티는 UnicodeScalarView 타입으로, UnicodeScalar 값의 컬렉션이다. 각각의 UnicodeScalar는 Uint32 값으로 표현되는 21비트 스칼라 프로퍼티를 가진다.
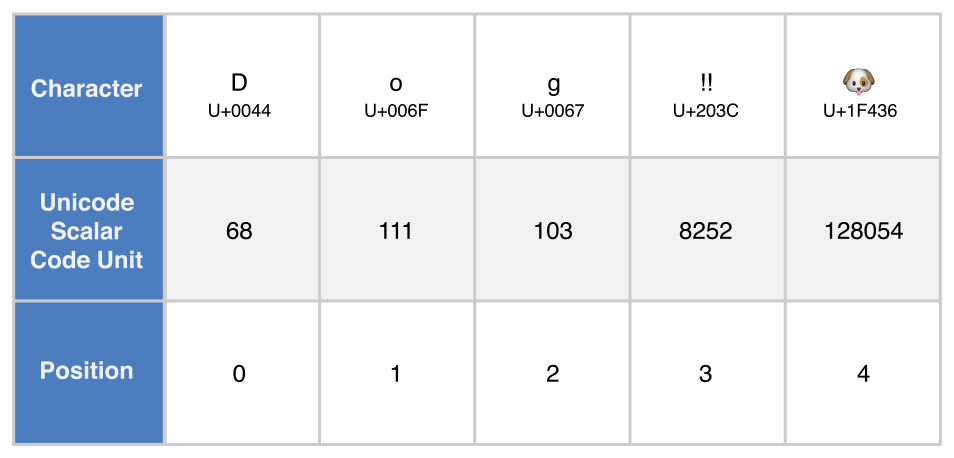
for scalar in dogString.unicodeScalars {
print("\(scalar.value) ", terminator: "")
}
print("")
// Prints "68 111 103 8252 128054 "
for scalar in dogString.unicodeScalars {
print("\(scalar) ")
}
// D
// o
// g
// ‼
// 🐶