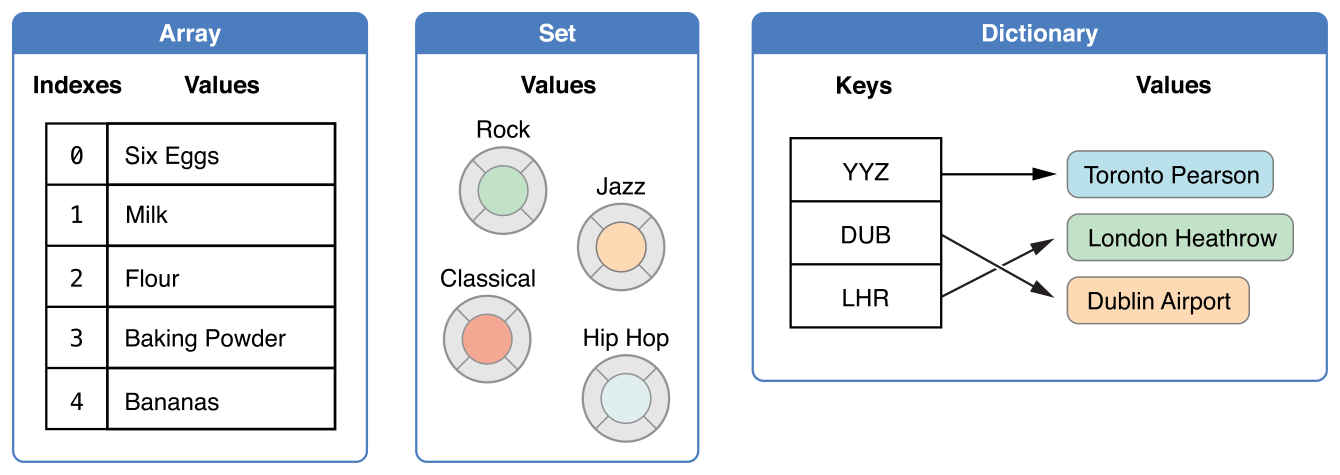
Collection Types
Swift는 Array, Set, Dictionary 세 가지 핵심 컬렉션 타입을 제공한다. Array는 순서가 있는 값들의 집합이며, Set은 순서가 없는 값들의 집합이다. Dictionary는 순서가 없는 key-value 쌍의 집합이다.
컬렉션의 변경
var로 선언했다면 변경 가능한 컬렉션이 된다. 이는 컬렉션 생성 이후에 추가, 삭제, 컬렉션 내부 아이템 변경 등의 작업이 가능하다는 뜻이다. let으로 선언했다면 변경할 수 없다.
컬렉션의 변경이 필요하지 않은 곳에서는 가급적 변경 불가능한 컬렉션으로 만드는 것이 좋다.
배열 (Array)
배열(Array)은 같은 타입의 값들을 저장하며, 순서가 존재한다. 같은 값이라도 배열의 다른 위치에서 나타날 수 있다.
Swift의 배열 타입은 Foundation의
NSArray클래스와 연결되어 있다.
배열의 축약형 문법
Swift의 배열은 Array<Element>와 같이 작성한다(Element는 배열에 들어갈 값들의 타입). 이는 [Element]와 같은 형태로 축약할 수 있다. 두 형태는 기능적으로 같지만, 축약형이 더 선호되는 경향이 있다.
빈 배열 생성하기
var someInts = [Int]()
print("someInts is of type [Int] with \(someInts.count) items.")
// Prints "someInts is of type [Int] with 0 items."someInts 변수의 타입은 initializer의 타입으로부터 [Int]로 추론된다.
만약 문맥적으로 타입 정보를 이미 제공했다면(함수의 인자 또는 상수/변수 선언 등), 빈 배열 리터럴인 []으로 새로운 빈 배열을 만들 수 있다.
someInts.append(3)
// someInts now contains 1 value of type Int
someInts = []
// someInts is now an empty array, but is still of type [Int]기본 값과 함께 빈 배열 생성
Swift의 배열 타입은 같은 기본값으로 채워진 특정 크기의 배열을 생성하는 initializer를 제공한다.
var threeDoubles = Array(repeating: 0.0, count: 3)
// threeDoubles is of type [Double], and equals [0.0, 0.0, 0.0]다른 배열을 추가한 배열 생성
기존에 존재하는 두 배열을 합쳐서 새로운 배열을 만들 수 있다. 합쳐지는 두 배열의 타입이 호환되어야만 가능하다.
var anotherThreeDoubles = Array(repeating: 2.5, count: 3)
// anotherThreeDoubles is of type [Double], and equals [2.5, 2.5, 2.5]
var sixDoubles = threeDoubles + anotherThreeDoubles
// sixDoubles is inferred as [Double], and equals [0.0, 0.0, 0.0, 2.5, 2.5, 2.5]배열 리터럴을 이용한 배열 생성
[value 1, value 2, value 3]과 같은 형태로 배열을 생성할 수 있다.
var shoppingList: [String] = ["Eggs", "Milk"]
// shoppingList has been initialized with two initial itemsshoppingList의 원소가 String 타입이기 때문에 [String] 타입으로 선언한다. 때문에 오직 문자열 값만을 저장할 수 있게 된다.
Swift의 타입 추론을 이용하여 타입 선언을 생략할 수 있다.
var shoppingList = ["Eggs", "Milk"]배열 접근 및 수정
배열의 메소드와 프로퍼티, 또는 subscript 문법을 이용하여 배열에 접근하거나 배열을 수정할 수 있다.
count : 배열의 원소 개수를 확인.
print("The shopping list contains \(shoppingList.count) items.")
// Prints "The shopping list contains 2 items."isEmpty : 배열이 비어 있는지 확인.
if shoppingList.isEmpty {
print("The shopping list is empty.")
} else {
print("The shopping list is not empty.")
}
// Prints "The shopping list is not empty."append : 배열에 새로운 원소 추가. 덧셈 할당 연산자를 이용하여 배열을 합칠 수도 있다.
shoppingList.append("Flour")
// shoppingList now contains 3 items, and someone is making pancakes
shoppingList += ["Baking Powder"]
// shoppingList now contains 4 items
shoppingList += ["Chocolate Spread", "Cheese", "Butter"]
// shoppingList now contains 7 itemssubscript syntax : 배열의 특정 인덱스에 있는 원소를 검색. 새로운 값으로 수정할 수도 있다. 범위를 지정하여 교체하는 것이 가능하다.
var firstItem = shoppingList[0]
// firstItem is equal to "Eggs"
shoppingList[0] = "Six eggs"
// the first item in the list is now equal to "Six eggs" rather than "Eggs"
shoppingList[4...6] = ["Bananas", "Apples"]
// shoppingList now contains 6 items반드시 유효한 인덱스 번호를 사용해야 하며, 범위를 넘어설 경우 런타임 에러가 발생한다.
insert(_:at:) : 특정 인덱스에 원소를 삽입.
shoppingList.insert("Maple Syrup", at: 0)
// shoppingList now contains 7 items
// "Maple Syrup" is now the first item in the listremove(at:) : 특정 인덱스의 원소를 삭제.
let mapleSyrup = shoppingList.remove(at: 0)
// the item that was at index 0 has just been removed
// shoppingList now contains 6 items, and no Maple Syrup
// the mapleSyrup constant is now equal to the removed "Maple Syrup" string배열의 범위를 넘어서는 인덱스에 삽입, 삭제 메소드를 실행할 경우 런타임에러가 발생한다.
원소가 삭제되었을 때의 갭은 사라진다.
firstItem = shoppingList[0]
// firstItem is now equal to "Six eggs"removeLast() : 배열의 마지막 원소 삭제. 마지막 원소를 삭제할 때 remove(at:)은 count 프로퍼티를 사용해야 하기 때문에 권장하지 않는다.
배열 순회
for-in 반복문을 통해 전체 배열을 순회할 수 있다.
for item in shoppingList {
print(item)
}
// Six eggs
// Milk
// Flour
// Baking Powder
// Bananas만약 값과 인덱스가 모두 필요하다면, enumerated() 메소드를 사용한다. enumerated() 메소드는 각각의 원소에 대해 인덱스와 값을 튜플 형태로 반환한다.
실제로 인덱스가 반환되는 것은 아니며, 0부터 시작해 1씩 증가해 나가는 정수 값을 반환한다.
for (index, value) in shoppingList.enumerated() {
print("Item \(index + 1): \(value)")
}
// Item 1: Six eggs
// Item 2: Milk
// Item 3: Flour
// Item 4: Baking Powder
// Item 5: Bananas셋 (Set)
셋(Set)은 같은 타입의 중복되지 않는 값을 순서가 없이 저장한다. 순서가 중요하지 않거나, 각 원소가 오직 하나만 있을 것이라 확신할 수 있는 경우, 배열 대신 셋을 사용할 수 있다.
Swift의 셋 타입은 Foundation의
NSSet클래스와 연결되어 있다.
hashable한 타입만이 셋에 저장될 수 있다. 해시 값은 동일하게 비교되는 모든 오브젝트에 대해 동일한 Int 값이다. 만약 a == b라면 a.hashValue == b.hashValue이다.
Swift의 모든 기본 타입(String, Int, Double, Bool)은 hashable하며, 셋의 값이나 딕셔너리의 키로 사용될 수 있다.
Swift 표준 라이브러리의
Hashable프로토콜을 준수함으로써 셋과 딕셔너리에 쓰일 수 있는 커스텀 타입을 만들 수 있다.Hashable프로토콜을 준수하는 타입은 반드시hashValue라 불리는Int프로퍼티를 제공해야 한다. 이 프로퍼티에는 게터가 설정돼야 한다.
Hashable프로토콜은Equatable프로토콜을 준수하기 때문에 동일 연산자(==)도 반드시 구현해야 한다. 동일 연산자의 구현은 다음 세 가지 조건을 만족해야 한다.
- a == a (Reflexivity)
- a == b이면 b == a이다. (Symmetry)
- a == b && b == c이면 a == c이다. (Transitivity)
셋 타입 문법
Swift의 셋은 Set<Element>와 같이 작성한다. Element는 셋에 저장되는 것이 허용된 타입이다. 배열과 달리 축약형이 존재하지 않는다.
빈 셋 생성하고 초기화
var letters = Set<Character>()
print("letters is of type Set<Character> with \(letters.count) items.")
// Prints "letters is of type Set<Character> with 0 items."만약 문맥적으로 타입 정보를 이미 제공했다면(함수의 인자 또는 상수/변수 선언 등), 빈 배열 리터럴인 []으로 새로운 빈 셋을 만들 수 있다.
letters.insert("a")
// letters now contains 1 value of type Character
letters = []
// letters is now an empty set, but is still of type Set<Character>배열 리터럴을 이용한 생성
하나 또는 그 이상의 원소를 배열 리터럴에 작성함으로써 셋을 초기화 할 수 있다.
var favoriteGenres: Set<String> = ["Rock", "Classical", "Hip hop"]
// favoriteGenres has been initialized with three initial itemsfavoriteGenres의 원소가 String 타입이기 때문에 Set<String> 타입으로 선언한다. 때문에 오직 문자열 값만을 저장할 수 있게 된다.
let을 사용해 상수로 선언한다면 셋에 원소를 추가하거나 제거할 수 없다.
셋 타입은 배열 리터럴만으로는 추론되지 않는다. 따라서 Set 타입을 반드시 명시적으로 선언해 줘야 한다. 하지만 타입 추론 덕분에 배열 리터럴로 초기화 할 때 셋에 들어갈 원소의 타입은 작성할 필요가 없다. favoriteGenres의 초기화는 다음과 같이 축약할 수 있다.
var favoriteGenres: Set = ["Rock", "Classical", "Hip hop"]셋 접근 및 수정
count : 셋의 원소 개수를 확인.
print("I have \(favoriteGenres.count) favorite music genres.")
// Prints "I have 3 favorite music genres."isEmpty : 셋이 비어 있는지 확인.
if favoriteGenres.isEmpty {
print("As far as music goes, I'm not picky.")
} else {
print("I have particular music preferences.")
}
// Prints "I have particular music preferences."insert(_:) : 새로운 원소를 셋에 삽입.
favoriteGenres.insert("Jazz")
// favoriteGenres now contains 4 itemsremove(_:) : 만약 원소가 셋에 있다면 삭제하고 그 원소를 반환한다. 없다면 nil을 반환한다.
removeAll() : 셋의 모든 원소를 삭제.
if let removedGenre = favoriteGenres.remove("Rock") {
print("\(removedGenre)? I'm over it.")
} else {
print("I never much cared for that.")
}
// Prints "Rock? I'm over it."contains(_:) : 셋에 특정 원소가 있는지 확인.
if favoriteGenres.contains("Funk") {
print("I get up on the good foot.")
} else {
print("It's too funky in here.")
}
// Prints "It's too funky in here."셋 순회
for-in 반복문을 사용해 셋을 순회할 수 있다.
for genre in favoriteGenres {
print("\(genre)")
}
// Classical
// Jazz
// Hip hopSwift의 셋은 정의된 순서를 갖지 않는다. 특정한 순서로 셋을 순회하기 위해선 sorted() 메소드를 사용한다. sorted() 메소드는 < 연산자를 사용하여 정렬한 배열(오름차순)과 같이 셋의 원소들을 반환한다.
for genre in favoriteGenres.sorted() {
print("\(genre)")
}
// Classical
// Hip hop
// Jazz셋 연산
두 셋을 합치거나, 공통된 원소를 빼내거나 하는 등의 셋 연산을 효율적으로 사용할 수 있다.
기본적인 셋 연산
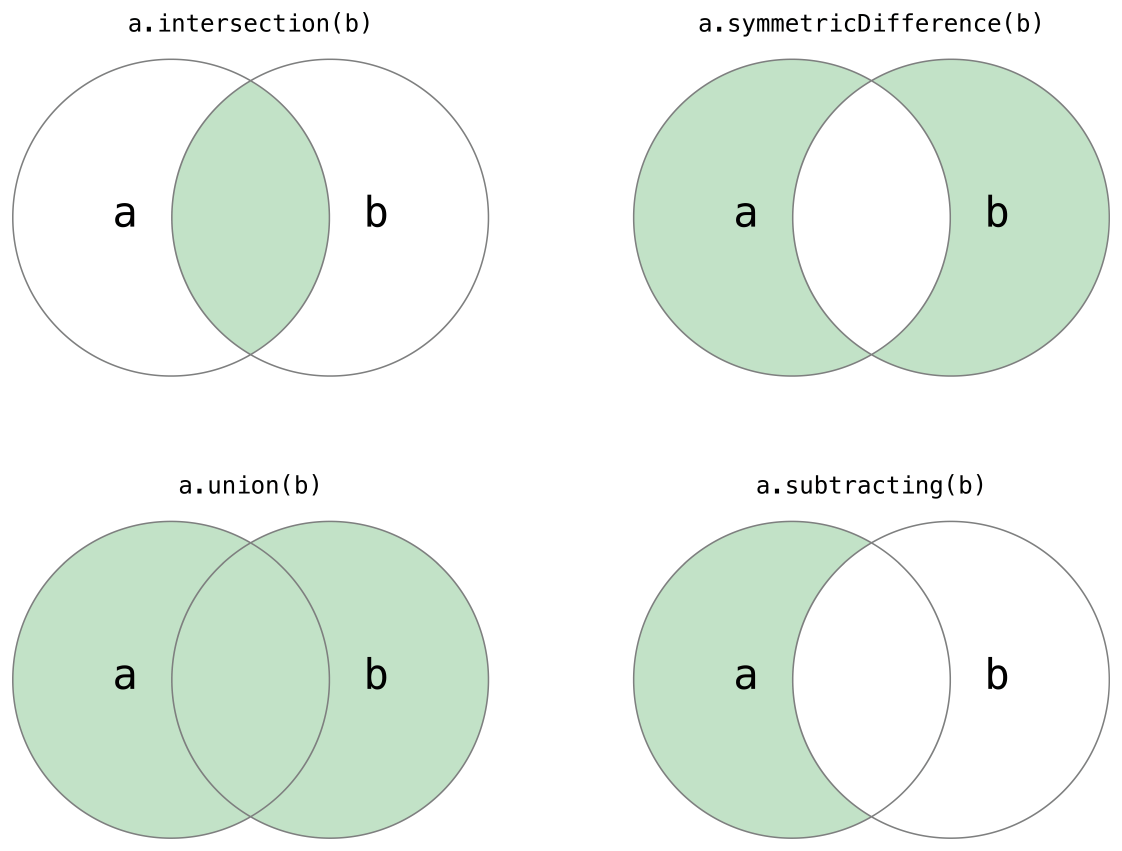
intersection(_:): 두 셋의 공통된 값들을 반환.symmetricDifference(_:): 두 셋의 공통되지 않은 값들을 반환.union(_:): 두 셋의 모든 값들을 반환.subtracting(_:): a에만 존재하는 값들을 반환.
let oddDigits: Set = [1, 3, 5, 7, 9]
let evenDigits: Set = [0, 2, 4, 6, 8]
let singleDigitPrimeNumbers: Set = [2, 3, 5, 7]
oddDigits.union(evenDigits).sorted()
// [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
oddDigits.intersection(evenDigits).sorted()
// []
oddDigits.subtracting(singleDigitPrimeNumbers).sorted()
// [1, 9]
oddDigits.symmetricDifference(singleDigitPrimeNumbers).sorted()
// [1, 2, 9]셋의 멤버십과 동등 비교
아래 그림에서 a는 b의 초월집합(superset)이고, b는 a의 부분집합(subset)이다. b와 c는 서로소(disjoint)이다.
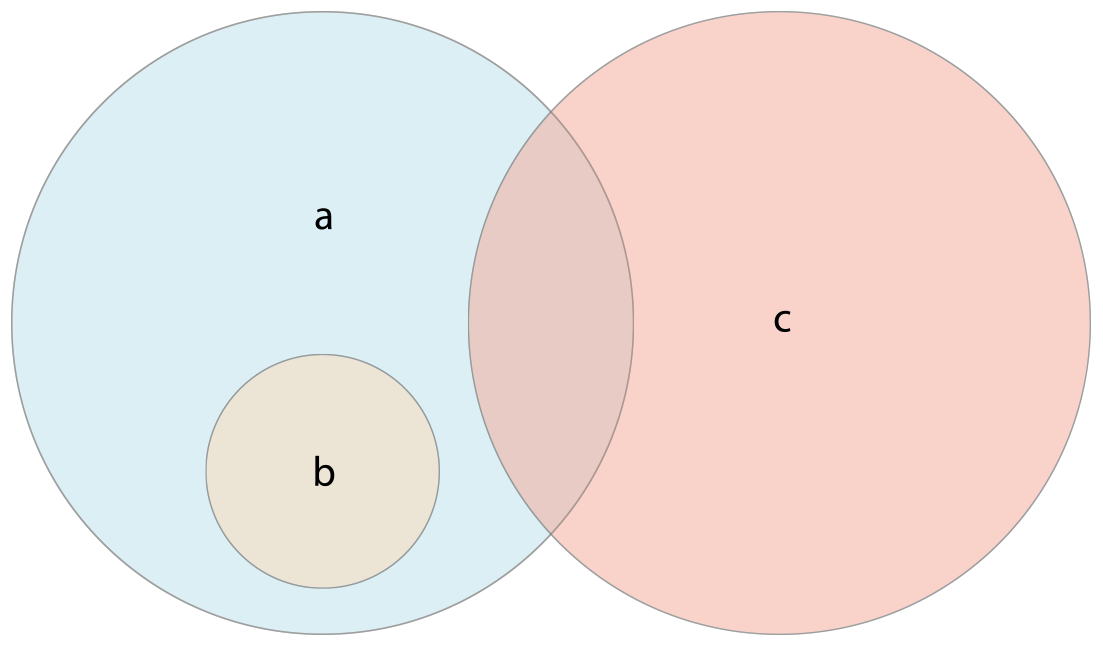
동등 연산자(==): 두 셋이 포함하고 있는 값이 모두 같은지 검사하는 연산자.isSubset(of:): 셋의 모든 값이 다른 셋에 포함되어 있는지 확인하는 메소드.isSuperset(of:): 셋이 다른 셋의 모든 값을 포함하고 있는지 확인하는 메소드.isStrictSubset(of:),isStrictSuperset(of:): 셋이 다른 셋의 부분집합 혹은 초월집합이지만 동일하지는 않은 경우인지를 판단하고자 할 때 사용하는 메소드isDisjoint(with:): 두 셋이 공통적으로 가지는 값이 하나도 없는지 확인하는 메소드.
let houseAnimals: Set = ["🐶", "🐱"]
let farmAnimals: Set = ["🐮", "🐔", "🐑", "🐶", "🐱"]
let cityAnimals: Set = ["🐦", "🐭"]
houseAnimals.isSubset(of: farmAnimals)
// true
farmAnimals.isSuperset(of: houseAnimals)
// true
farmAnimals.isDisjoint(with: cityAnimals)
// true딕셔너리 (Dictionary)
딕셔너리(Dictionary)는 키(key)와 값(value)의 쌍으로 이루어진 집합을 순서 없이 저장한다. 각각의 키는 고유하며, 식별자로서 딕셔너리에서 사용된다. 배열과 다르게 순서가 존재하지 않는다. 식별자에 기반한 값을 찾아야 할 필요가 있을 때 사용할 수 있다.
Swift의 딕셔너리 타입은 Foundation의
NSDictionary클래스와 연결되어 있다.
딕셔너리 타입 축약 문법
Swift의 딕셔너리는 Dictionary<Key, Value> 형태로 작성된다.
딕셔너리의 키는 반드시
Hashable프로토콜을 준수해야 한다.
[Key: Value]와 같은 형태로 축약하여 사용할 수 있다.
빈 딕셔너리 생성
배열과 같이, initializer를 사용하여 특정 타입의 빈 딕셔너리를 생성할 수 있다.
var namesOfIntegers = [Int: String]()
// namesOfIntegers is an empty [Int: String] dictionary만약 문맥적으로 타입 정보를 이미 제공했다면(함수의 인자 또는 상수/변수 선언 등), 빈 딕셔너리 리터럴인 [:]으로 새로운 빈 딕셔너리를 만들 수 있다.
namesOfIntegers[16] = "sixteen"
// namesOfIntegers now contains 1 key-value pair
namesOfIntegers = [:]
// namesOfIntegers is once again an empty dictionary of type [Int: String]딕셔너리 리터럴를 이용한 생성
배열과 비슷한 방법으로, 하나 또는 그 이상의 키-값 쌍을 딕셔너리 리터럴에 작성함으로써 초기화 할 수 있다.
[key 1: value 1, key 2: value 2, key 3: value 3]과 같은 형태로 딕셔너리를 생성할 수 있다.
var airports: [String: String] = ["YYZ": "Toronto Pearson", "DUB": "Dublin"]airports의 원소가 String-String 타입이기 때문에 [String: String] 타입으로 선언한다. 때문에 오직 문자열 값만을 저장할 수 있게 된다.
let을 사용해 상수로 선언한다면 딕셔너리에 원소를 추가하거나 제거할 수 없다.
Swift의 타입 추론을 이용하여 타입 선언을 생략할 수 있다.
var airports = ["YYZ": "Toronto Pearson", "DUB": "Dublin"]딕셔너리 접근 및 수정
딕셔너리의 메소드와 프로퍼티, 또는 subscript 문법을 이용하여 딕셔너리에 접근하거나 배열을 수정할 수 있다.
count : 딕셔너리의 원소 개수를 확인.
print("The airports dictionary contains \(airports.count) items.")
// Prints "The airports dictionary contains 2 items."isEmpty : 딕셔너리가 비어 있는지 확인.
if airports.isEmpty {
print("The airports dictionary is empty.")
} else {
print("The airports dictionary is not empty.")
}
// Prints "The airports dictionary is not empty."subscript syntax를 사용하여 새로운 키-값 쌍을 추가하거나 수정할 수 있다.
airports["LHR"] = "London"
// the airports dictionary now contains 3 items
airports["LHR"] = "London Heathrow"
// the value for "LHR" has been changed to "London Heathrow"updateValue(_:forKey:) : 이 메소드로도 특정 키의 값을 수정할 수 있다. 키가 존재하지 않을 경우 값을 할당하고, 반대의 경우에는 값을 수정한다. subscript와는 달리 업데이트 하기 이전의 값(기존 값)을 반환한다. 키가 없었다면 nil을 반환한다. updateValue()가 반환하는 값은 옵셔널이다.
if let oldValue = airports.updateValue("Dublin Airport", forKey: "DUB") {
print("The old value for DUB was \(oldValue).")
}
// Prints "The old value for DUB was Dublin."subscript syntax 역시 딕셔너리에 특정 키가 있는지 검색하는 데 사용할 수 있다. 키가 존재한다면 값 타입의 옵셔널 값을 반환한다. 키가 딕셔너리에 없다면 nil을 반환한다.
if let airportName = airports["DUB"] {
print("The name of the airport is \(airportName).")
} else {
print("That airport is not in the airports dictionary.")
}
// Prints "The name of the airport is Dublin Airport."키를 제거하기 위해선 nil을 할당한다.
airports["APL"] = "Apple International"
// "Apple International" is not the real airport for APL, so delete it
airports["APL"] = nil
// APL has now been removed from the dictionaryremoveValue(forKey:) : 키-값 쌍을 삭제하고 반환한다. 존재하지 않았다면 nil을 반환한다.
if let removedValue = airports.removeValue(forKey: "DUB") {
print("The removed airport's name is \(removedValue).")
} else {
print("The airports dictionary does not contain a value for DUB.")
}
// Prints "The removed airport's name is Dublin Airport."딕셔너리 순회
for-in 반복문을 사용해 딕셔너리를 순회할 수 있다. 각각의 원소는 (key, value)의 튜플 형태로 반환된다.
for (airportCode, airportName) in airports {
print("\(airportCode): \(airportName)")
}
// LHR: London Heathrow
// YYZ: Toronto Pearsonkeys와 values 프로퍼티를 통해 키 또는 값에만 접근할 수 있다.
for airportCode in airports.keys {
print("Airport code: \(airportCode)")
}
// Airport code: LHR
// Airport code: YYZ
for airportName in airports.values {
print("Airport name: \(airportName)")
}
// Airport name: London Heathrow
// Airport name: Toronto Pearson만약 딕셔너리의 키나 값을 배열 인스턴스로 만들고 싶다면, keys 또는 values 프로퍼티와 함께 새로운 배열을 초기화 한다.
let airportCodes = [String](airports.keys)
// airportCodes is ["LHR", "YYZ"]
let airportNames = [String](airports.values)
// airportNames is ["London Heathrow", "Toronto Pearson"]