[영화 줄거리로 장르 분류하기]
1. 머신러닝이란?
2. 데이터 전처리
3. 벡터화
👉4. 머신러닝👈
5. 모델 사용하기 및 불용어 제거
[목차]
- 나이브 베이즈 분류기
- Logictic Regression
- 선형 Support Vector Machine
4. 머신러닝
예측모델에 필요한 모듈 임포트
from sklearn.naive_bayes import MultinomialNB # 다항분포 나이브 베이즈 모델
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score # 정확도 계산
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer벡터화
x_train과 x_test에 대해서 DTM, TF-IDF를 생성한다.
# DTM 벡터화를 위한 객체 생성
dtmvector = CountVectorizer()
# 훈련용 데이터 DTM 벡터화 진행
x_train_dtm = dtmvector.fit_transform(x_train)
# TF-IDF를 위한 객체 생성
tfidf_transformer = TfidfTransformer()
# TF-IDF 행렬로 변환
tfidfv = tfidf_transformer.fit_transform(x_train_dtm)
# 테스트용 데이터 벡터화
x_test_dtm = dtmvector.transform(x_test)
tfidfv_test = tfidf_transformer.transform(x_test_dtm)✋ 오류
[ValueError: X has 120614 features, but MultinomialNB is expecting 121110 features as input.]
테스트 데이터에 fit_transform()으로 학습을 시킴..수정 후 다시 실행해도 안 되고 행렬로 변환하는 거 부터 다 지우고 다시 학습을 시켜야한다.
○ 나이브 베이즈 분류기
나이브 베이즈 분류기는 베이즈 정리에 기반한 모델이다.
참고 : https://wikidocs.net/22892
사이킷런이 제공하는 머신러닝 모델들은 공통적으로 fit()이라는 함수를 제공한다.
훈련 데이터와 해당 훈련 데이터에 대한 레이블을 인자를 사용하면 모델이 학습을 하게 된다.
# 나이브 베이즈 분류기 모델을 이용한 학습
mod = MultinomialNB()
mod.fit(tfidfv, y_train)predict() 함수로 예측값을 얻어서 정확도를 측정한다.
# 테스트 데이터에 대한 예측
predicted = mod.predict(tfidfv_test)
# 예측값과 실제값 비교
print("정확도:", accuracy_score(y_test, predicted))
#Result
정확도: 0.4426752767527675예측 그래프 출력
predict_proba()를 이용하면 각 클래스 별로 몇 %의 확신을 가졌었는지를 리턴한다. 이를 matplot을 이용해 그래프로 나타낸다.
import matplotlib.pyplot as plt
plt.subplot(211)
plt.rcParams["figure.figsize"] = (10,10)
plt.bar(mod.classes_, mod.predict_proba(tfidfv_test[3])[0])
plt.xlim(-1, 21)
plt.xticks(mod.classes_)
plt.xlabel("Genre")
plt.ylabel("Probability")
plt.show()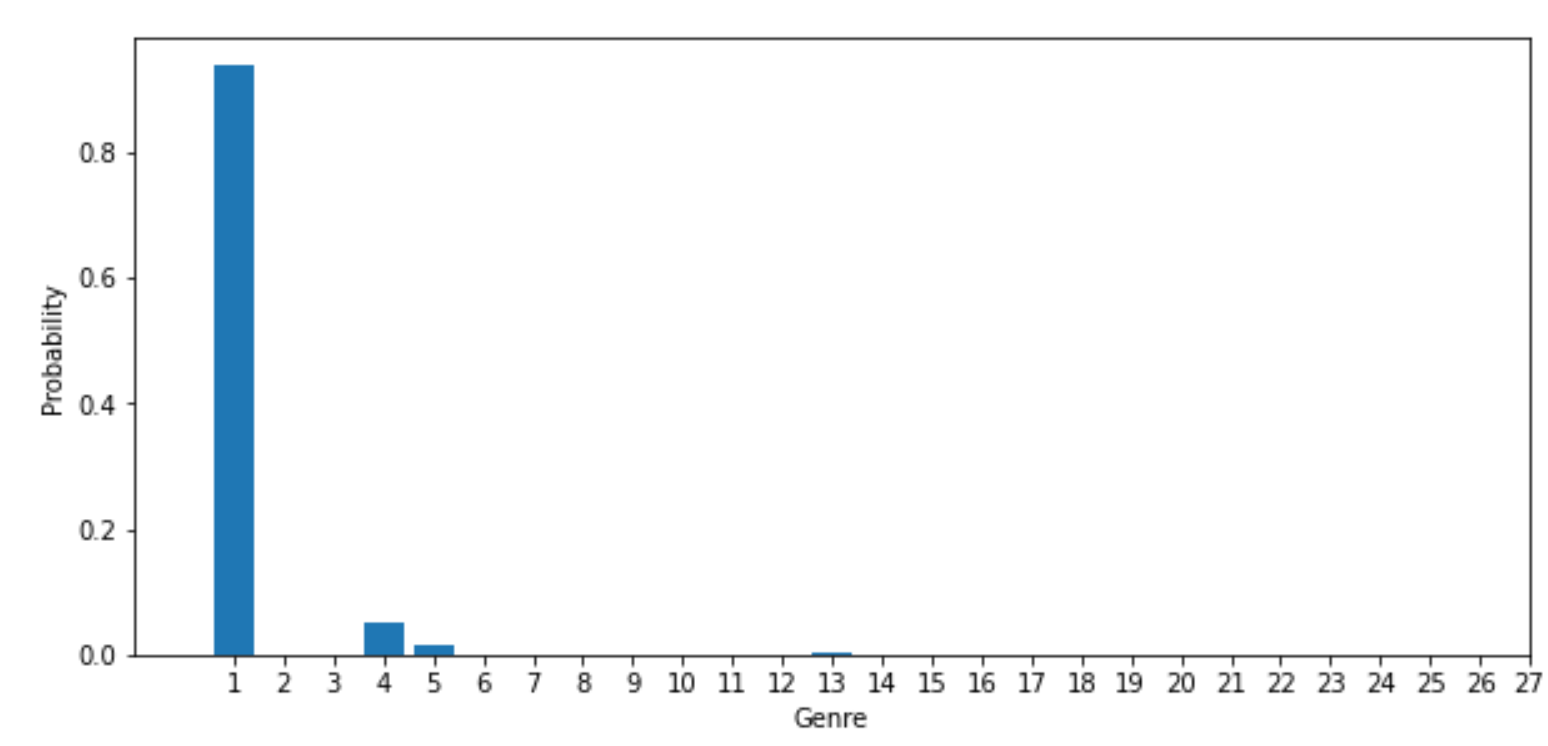
○ Logistic Regression
로지스틱 회귀는 소프트맥스 (softmax)함수를 사용한 다중 클래스 분류 알고리즘을 지원한다. 다중 클래스 분류를 위한 로지스틱 회귀를 소프트맥스 회귀 (softmax regression)라고도 한다.
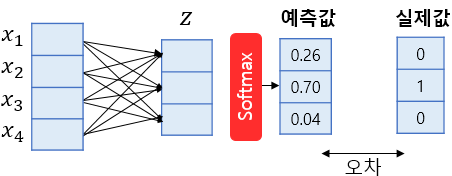
소프트맥스 함수는 클래스가 N개일 때, 각 클래스가 정답일 확률을 표현하도록 하는 함수이다. 위 그림에서 화살표 각각은 이후에 선형 회귀에서 배울 가중치(weight)에 해당한다. 이 값들은 처음에는 랜덤값이지만, 학습이 진행되면서 모델이 정답을 잘 맞출 수 있는 값으로 변하게 된다.
진행하는 실습에서 장르가 27개 이므로, 소프트맥스함수는 각각 장르에 해달할 확률 27개를 모두 계산한다. 그리고 그 값 중에 가장 높은 값을 가진 것이 예측 결과로 나오게 된다.
로지스틱 회귀는 오차를 줄이기 위해 최적화를 계속하기 때문에 오래걸린다. 그럼에도 오차가 남아있는 경우에는 오류를 띄운다.
# 로지스틱 회귀을 이용한 학습
lr = LogisticRegression(C=10000, penalty='l2')
lr.fit(tfidfv, y_train)# 테이트 데이터를 이용해 정확도 측정
predicted = lr.predict(tfidfv_test) #테스트 데이터에 대한 예측
print("정확도:", accuracy_score(y_test, predicted)) #예측값과 실제값 비교
#Result
정확도: 0.5868265682656827✋ 직접 입력 시 주의할 점!
penalty입력 시 '12'라고 입력하고 계속 오류남.
코랩에서는 아주 똑같게 보인다. 아래 캡쳐에서 위쪽 주석처리한 것이 내가 '12'라고 입력한 것, 아래는 'l2'라고 입력되어 있는 것이다. 오류 내용은 penalty 값이 없다는 내용이었다.

○ 선형 Support Vector Machine
서포트 벡터 머신 (SVM)은 결정 경계 (Decision Boundary), 즉 분류를 위한 기준 선을 정의하는 모델이다. 그래서 분류되지 않은 새로운 점이 나타나면 경계의 어느 쪽에 속하는지 확인해서 분류 과제를 수행할 수 있다.
# Linear SVM을 이용한 학습
lsvc = LinearSVC(C=1000, penalty='l2', max_iter=500)
lsvc.fit(tfidfv, y_train)
# 정확도 측정
predicted = lsvc.predict(tfidfv_test)
print("정확도:", accuracy_score(y_test, predicted))
#Result
정확도: 0.5208671586715867더 높은 정확도를 얻고 싶으면
자연어처리(NLP)를 깊게 공부해야 한다. 벡터 임베딩의 다양한 기법을 시도해보고,딥러닝까지 적용한다면 훨신 높은 정확도를 만들 수 있다.
