✍️ 붓꽃 데이터의 탐색적 데이터 분석을 진행하고, 여러가지 차트들을 그려주세요.
[목차]
- 데이터 탐색 및 전처리
- 상관계수 및 히트맵 그리기
- 산점도 그리기
- 파이차트 그리기
- Groupby
- Bar chart
- 배운 점
1. 데이터 탐색 및 전처리
○ 데이터 로드 및 데이터프레임 생성
# 과제에 필요한 패키지는 아래의 두 가지가 전부가 아닙니다.
# 여러분들의 필요에 따라서 패키지를 지속 추가하셔도 됩니다.
import pandas as pd
from sklearn import datasets
# 붓꽃 데이터 로드
iris_data = datasets.load_iris()
#데이터 모양 확인
iris_data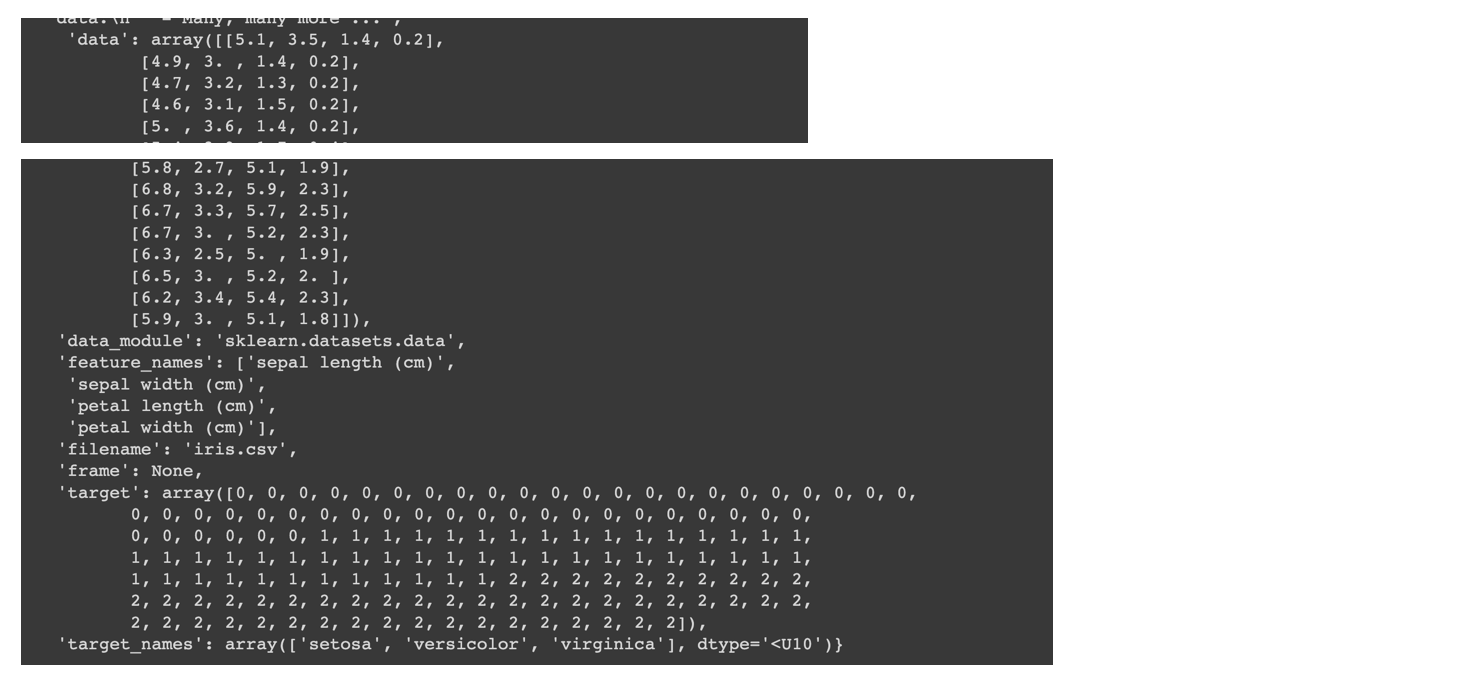
'data' 키값에 value로 리스트들이 담겨 있고, 'feature_names'에 열의 이름이 있다. 그리고 'target'이라는 키값에 정수로 이루어진 리스트가 있고, 'target_names'에 이름이 담겨있다.
따라서
1) 'data'와 'feature_names'을 이용하여 데이터프레임을 생성하고,
2) 그 데이터프레임에 'target'열을 추가하고
3) 'target_names'이름을 이용하여 [0, 1, 2]순서에 맞게 'target'열을 문자열 치환을 해줄 것이다.
#1)데이터프레임 생성
#sepal: 꽃받침 / petal:꽃잎
iris_df = pd.DataFrame(iris_data['data'], columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'])
#2)target열 생성
iris_df['species'] = iris_data['target']
iris_df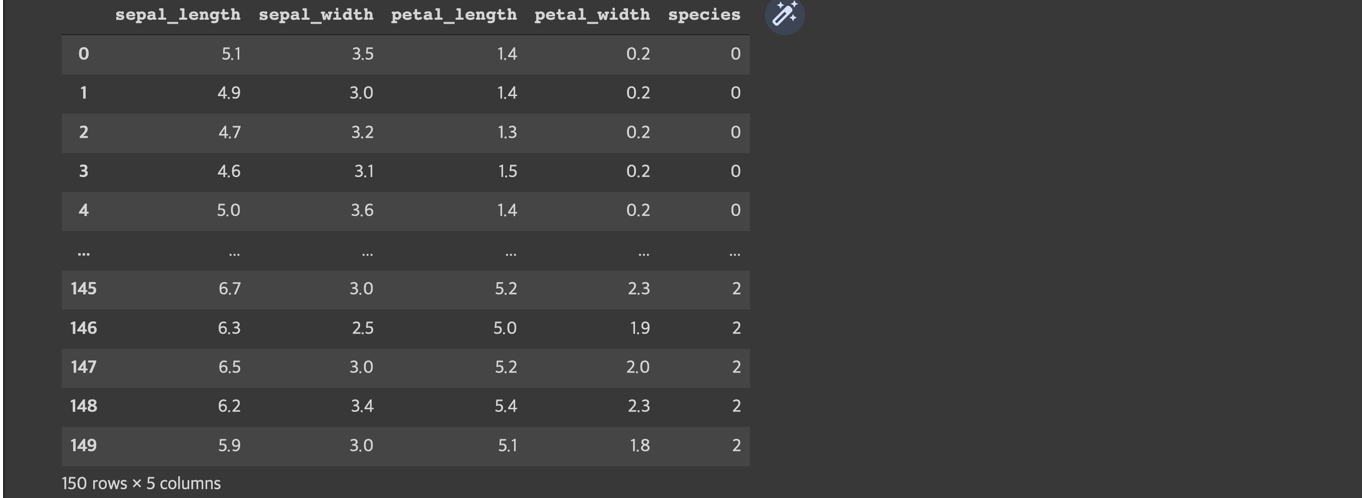
#3)문자열 치환해주기
iris_df.replace({'species':mapping}, inplace=True)
iris_df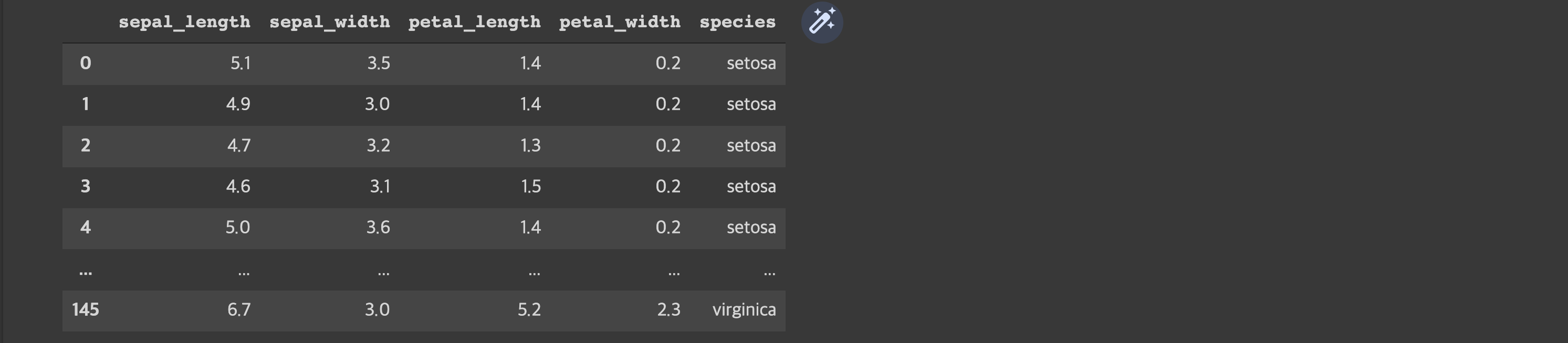
○ 데이터 전처리
- 데이터프레임 모양 확인
#데이터프레임 모양 확인
iris_df.info()
#result
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length 150 non-null float64
1 sepal_width 150 non-null float64
2 petal_length 150 non-null float64
3 petal_width 150 non-null float64
4 species 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
#샘플 확인
iris_df.sample(10)
#결측치 확인
iris_df.isnull().sum()
#result
sepal_length 0
sepal_width 0
petal_length 0
petal_width 0
species 0
dtype: int64
#데이터분포 확인
iris_df['species'].value_counts()
#result
setosa 50
versicolor 50
virginica 50
Name: species, dtype: int64
#열의 통계 파악하기
iris_df.describe()
#result
sepal_length sepal_width petal_length petal_width
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.057333 3.758000 1.199333
std 0.828066 0.435866 1.765298 0.762238
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.5000002. 상관계수 및 히트맵 그리기
👉필요한 패키지 임포트
import matplotlib.pyplot as plt
import seaborn as sns○ 상관계수
#상관계수
cols = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
corr = iris_df[cols].corr(method = 'pearson')
corr
#result
sepal_length sepal_width petal_length petal_width
sepal_length 1.000000 -0.117570 0.871754 0.817941
sepal_width -0.117570 1.000000 -0.428440 -0.366126
petal_length 0.871754 -0.428440 1.000000 0.962865
petal_width 0.817941 -0.366126 0.962865 1.000000○ 히트맵
#히트맵 그리기
#상관계수 데이터프레임 리스트
corr.values
#컬럼명
column_names = ['Sepal len', 'Sepal wid', 'Petal len', 'Petal wid']
#히트맵
# 레이블의 폰트 사이즈를 조정
sns.set(font_scale=1)
hm = sns.heatmap(corr.values, # 상관계수 데이터
cbar=True, # 오른쪽 컬러 막대 출력 여부
annot=True, # 차트에 숫자를 보여줄 것인지 여부
square=True, # 차트를 정사각형으로 할 것인지
fmt='.2f', # 숫자의 출력 소수점자리 개수 조절
annot_kws={'size': 12}, # 숫자 출력시 숫자 크기 조절
yticklabels=column_names, # y축에 컬럼명 출력
xticklabels=column_names) # x축에 컬럼명 출력
plt.tight_layout() # 그래프 간격 유지 설정
plt.show() # 그래프 표시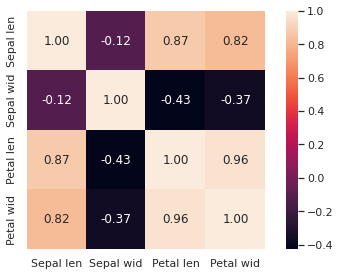
3. 산점도 그리기
sns.set(style='whitegrid') # 배경을 하얗게 한다
# plt.figure(figsize=(4,4))
# plt.rcParams['figure.figsize'] = (5, 5)
sns.pairplot(iris_df[cols])
plt.show()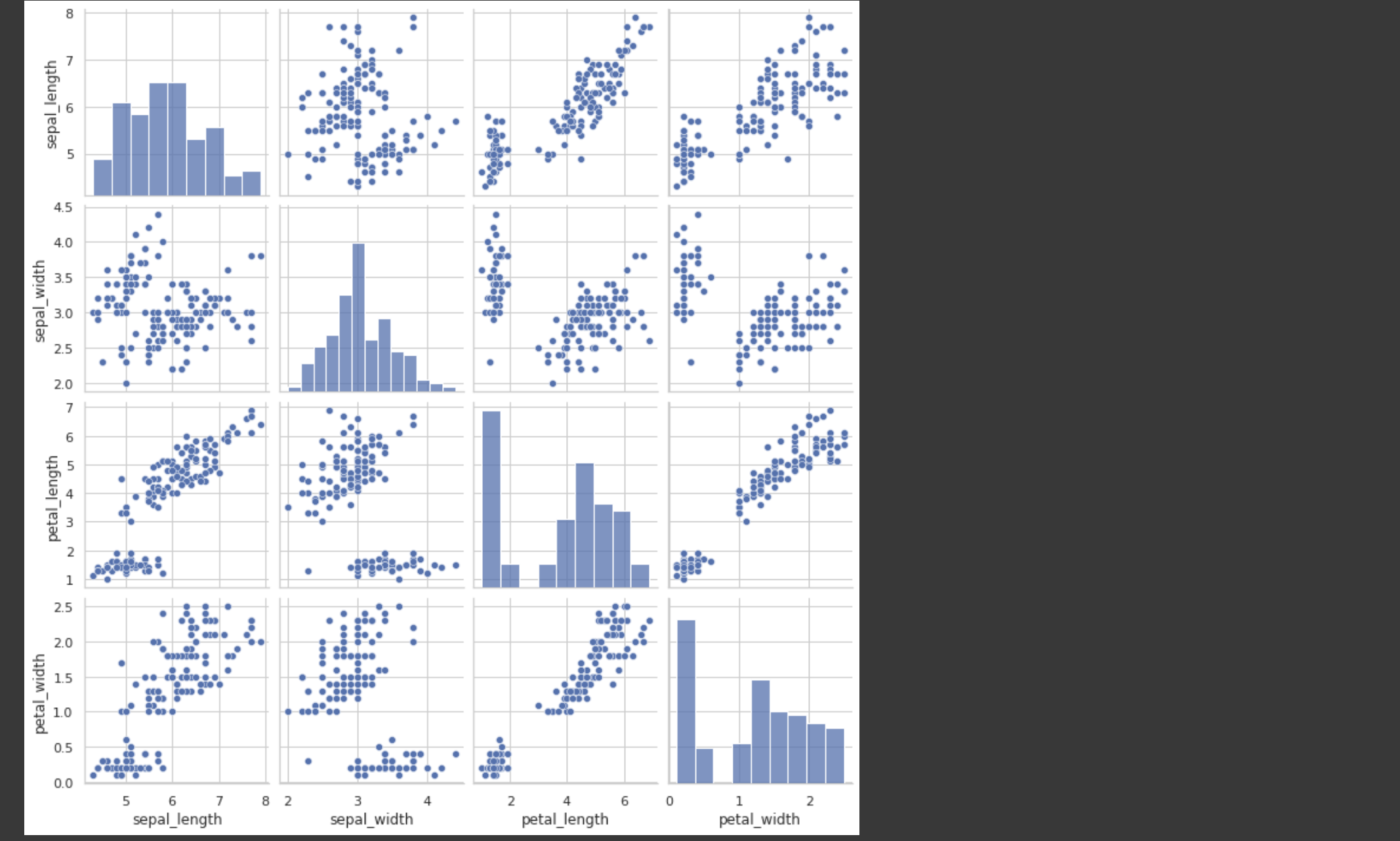
4. 파이차트 그리기
#리스트 생성
pie_labels = iris_data['target_names']
pie_values = iris_df['species'].value_counts().values.tolist()
#그래프 생성
plt.pie(pie_values, labels=pie_labels, autopct = '%.02f%%')
plt.title('Percentage of species')
plt.show()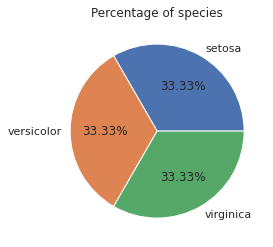
5. Groupby
- 꽃 종류별로 그룹 나눠서 통계치 보기
#꽃 종류별로 평균값확인
iris_df.groupby('species').mean()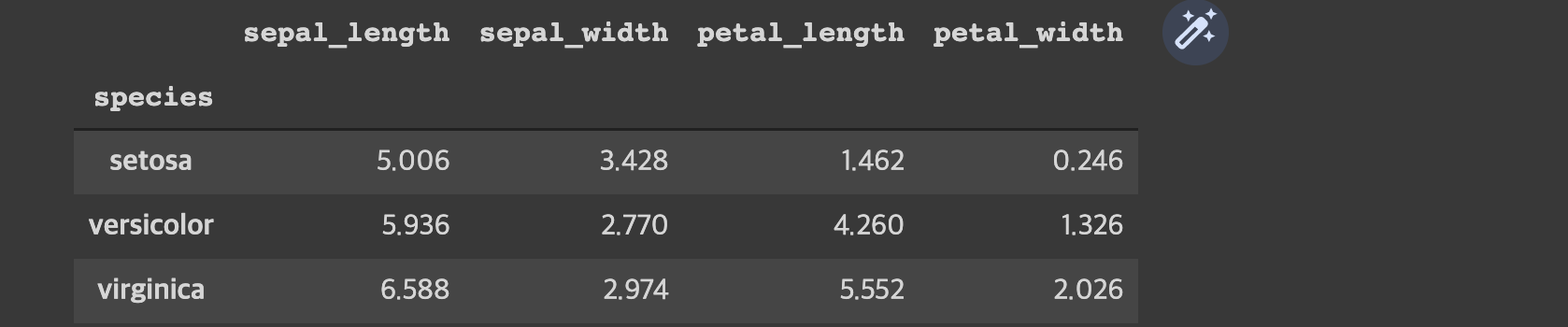
○ 질문1
#꽃받침 길이 평균이 가장 긴 종은?
longest_sepal = iris_df.groupby('species')['sepal_length'].mean().idxmax()
longest_sepal
#result
'virginica'○ 질문2
#꽃잎의 길이가 전체평균보다 작은 종은?
avr_petal_length = iris_df['petal_length'].mean()
species_mean = iris_df.groupby('species').mean()
species_mean[species_mean['petal_length'] < avr_petal_length]
6. Bar chart
- 꽃 종별로 열별로 평균을 나타내는 다중 막대 그래프를 그린다.
- groupby를 이용하여 종별로 평균, 최대, 최소를 나타내는 데이터테이블을 만든다. (평균만 나오는 걸로 만들어도 되나, 연습이니까 다 해본다.)
species_info = iris_df.groupby('species').agg(['mean', 'min', 'max'])
species_info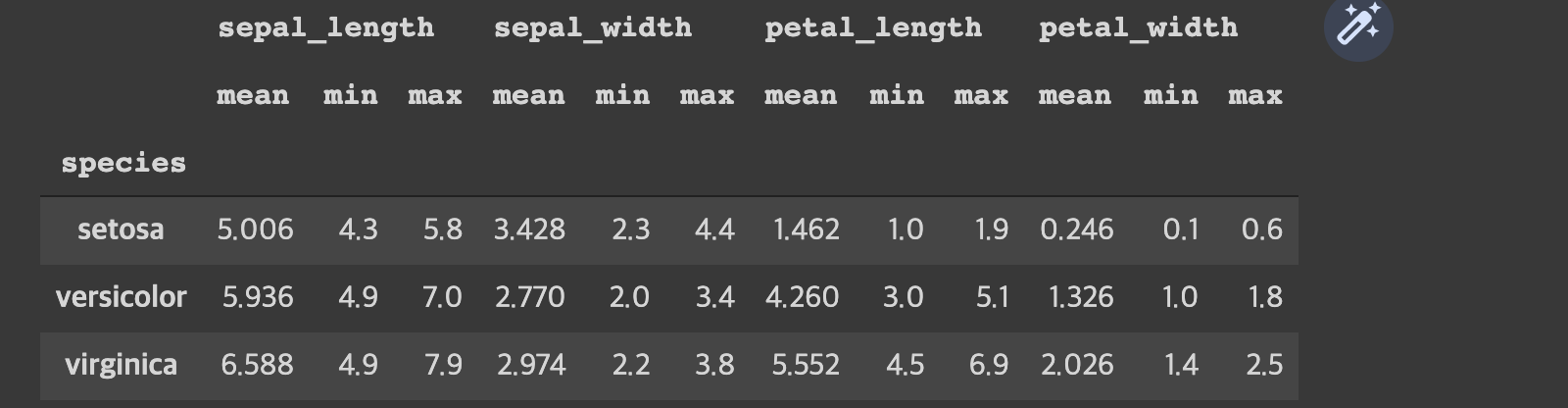
- 다중 막대 그래프를 그린다.
#종별 각 값에 대한 평균을 이용해 막대그래프를 그린다
import matplotlib.pyplot as plt
import numpy as np
#그림 사이즈, 바 굵기 조정
fig, ax = plt.subplots(figsize=(12,6))
bar_width = 0.15
#종이 3개로 index 3개
index = np.arange(3)
#values list 만들기
sep_len_mean = species_info['sepal_length']['mean'].values.tolist()
sep_wid_mean = species_info['sepal_width']['mean'].values.tolist()
pet_len_mean = species_info['petal_length']['mean'].values.tolist()
pet_wid_mean = species_info['petal_width']['mean'].values.tolist()
#label list 만들기
labels = species_info.index.tolist()
#종 별로 4개의 bar를 순서대로 나타냄. 각 그래프는 0.25의 간격을 두고 그려짐
b1 = plt.bar(index, sep_len_mean, bar_width, alpha=0.4, color='r', label='Septal Length')
b2 = plt.bar(index+bar_width, sep_wid_mean, bar_width, alpha=0.4, color='g', label='Septal Width')
b3 = plt.bar(index+bar_width*2, pet_len_mean, bar_width, alpha=0.4, color='b', label='Petal Length')
b4 = plt.bar(index+bar_width*3, pet_wid_mean, bar_width, alpha=0.4, color='pink', label='Petal Width')
#x축 위치를 정 가운데로 조정하고 x축의 텍스트를
plt.xticks(np.arange(bar_width, 4+bar_width, 1), labels)
#x축, y축 이름 및 범례 설정
plt.xlabel('Species', size = 13)
plt.ylabel('Mean (cm)', size = 13)
plt.title('Mean by Species')
plt.legend()
plt.show()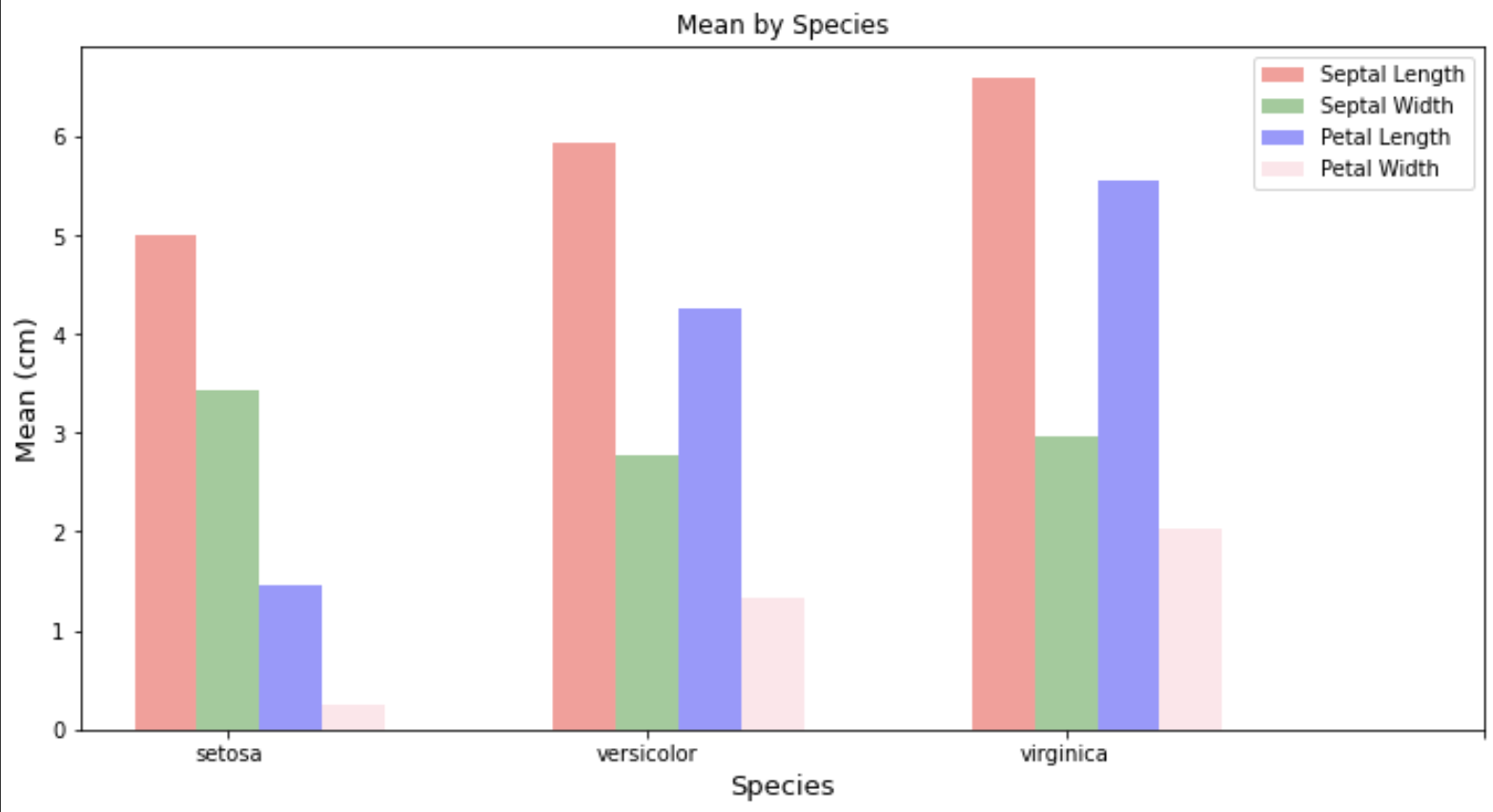
7. 배운 점 또는 복습
○ 복습) Datasets을 dataframe으로 만들기
✋ dataframe 생성하기
방법1) 열별로 만들기
pd.DataFrame(
{"컬럼명1":[데이터 입력],
"컬럼명2":[데이터 입력]
,,,,
"컬럼명n":[데이터 입력]},
index = 리스트 형태[ ])방법2) 행별로 만들기
pd.DataFrame(
[[1행], ,,, ,[막행]],
index = [],
columns = [컬럼명])○ 복습) 데이터분석 하기 전 확인
- 결측치 확인 :
데이터프레임이름.isnull().sum()
있으면 제거 :데이터프레임이름.dropna(inplace=True)
- 중복 확인 :
데이터프레임이름['열의이름'].nunique() - 데이터 분포 확인 :
데이터프레임이름['열의이름'].value_counts()
특정 열에 존재하는 각 종류의 값을 카운트하여 숫자로 출력.
○ 데이터프레임에서 문자열 치환
참고:https://seong6496.tistory.com/234?category=903876
df.replace(1,100)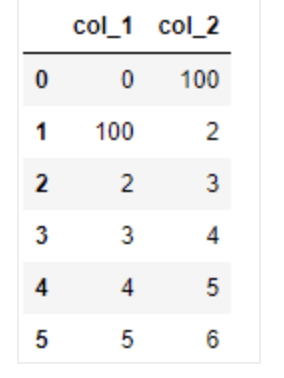
- 위 처럼 하면 target 열에 있는 숫자뿐만 아니라 데이터값까지 문자열로 치환이 되었다. 이를 막기 위해 열을 지정해서 치환을 할 수 있다.
df.replace({'col_1':{1:100}, 'col_2':{2:200}})○ 열의 값이 최대인 행 찾기
이건 원래 수업 자료에도 있던 것인데 함수이름을 잘못알고 있어서 한참 고생했다...모든걸 의심해보자...
longest_sepal = iris_df.groupby('species')['sepal_length'].mean().idmax()
longest_sepal
#Error
AttributeError: 'Series' object has no attribute 'idmax''idmax()'가 아니라 'idxmax()'였다.
○ 다중 막대 그래프 그리기
참고:https://jimmy-ai.tistory.com/40
막대 여러개로 그려보고 싶어서 찾아봤다. 그냥 서식에 맞게 따라해보았다.

훈이야 화이팅