Redis
REmote DIctionary Server
‘키-값’ 구조의 데이터를 저장하고 관리하기 위한 오픈 소스 기반의 in-momory data structure store
- In-Memory Data Strucrue store
- Open Source (BSD 3 License)
- Support data structures
- Strings, set, sorted-set, hashes, list
- Hyperloglog, bitmap, geospatial index
- Stream
- Only 1 Committer : Redis 소스코드 수정 가능한 사람 1명
특징
○ In-memory data structure
문자열, hash, list, set, sorted set, stream 등의 자료형을 지원하는 “data structure server”
○ Programmability
Lua를 사용한 server-side scripting과 Redis Functions를 이용한 server-side 저장 과정
○ Persistence
빠른 액세스를 위해 데이터 세트를 메모리에 보관하지만, 재부팅 및 시스템 오류가 발생해도 영구 스토리지에 대한 모든 쓰기를 유지할 수도 있다.
○ Clusturing
해시 기반 샤딩을 통한 수평적 확장성, 클러스터 성장 시 자동 재파티션을 통해 수백만 개의 노드로 확장.
○ High availability
독립 실행형 및 클러스터된 배포 모두에 대해 자동 장애 조치가 포함된 replication.

📎 redis는 주로 캐싱에 사용되는데, 관련 내용은 Cache 포스팅에 있습니다.
Collection
reids에서는 다양한 자료구조를 지원하는데 이 자료구조가 필요한 이유와 어디에 쓰이는 지에 대해 알아본다.
📌 Collection이 필요한 이유
1️⃣ 개발 난이도가 낮아진다.
멤캐시드는 collection을 제공하지 않는다. Redis는 제공한다.
라이브러리로 미리 구현해놓으면 훨씬 편하게 개발하는 것처럼 멤캐시드는 구현해야할 것이 많으나 Redis는 구현해놓은 것이 많아서 쓰기만 하면 된다.
예를 들어,
랭킹 서버에서 DB에 넣고 정렬을 하면 갯수가 많아질수록 느려진다.
하지만, Redis의 sorted-set을 이용하면 개발 난이도가 낮아지게 된다.
2️⃣ 문제를 줄여줄 수 있다.
Redis는 자료구조가 Atomic하기 때문에 Race Condition을 피할 수 있다. (그래도 잘못짜면 발생 가능 ex. 따닥)
✅ Race condition : transaction이 두개가 동시에 진행될 때, ACID하지 않을 수 있다.
→ 외부의 Collection을 잘 이용하는 것으로 여러가지 개발 시간을 단축시키고, 문제를 줄여줄 수 있기 때문에 Collection이 중요하다.
📌 Redis의 사용
Remote Data Store
- A서버, B서버, C서버에서 데이터를 공유하고 싶을 때
한 대에서만 필요하다면, 전역 변수를 쓰면 되지 않을까?
- Redis 자체가 single thread라 Atomic을 보장해준다.
✅ 이 외 주로 많이 쓰는 곳들
- 인증 토큰 등을 저장 (String 또는 hash)
- Ranking 보드로 사용 (Sorted set)
- 유저 API Limit
- 좌표 (list)
📌 Redis Collections
자료구조에 따라서 어떤 상황에서 활용되는지 알아보자.
-
Strings
- key-value
- key를 어떻게 설정하느냐에 따라 분산이 바뀔 수 있다.
-
List
- 데이터 추가 : Lpush, Rpush / 데이터 꺼내기 : LPOP, RPOP
Lpush <key> <data>
- 좌표 저장에 많이 사용
- 데이터 추가 : Lpush, Rpush / 데이터 꺼내기 : LPOP, RPOP
-
Set
SADD <key> <value>: value가 이미 key에 있으면 추가되지 않는다.SMEMBERS <key>: 모든 value를 돌려줌SISMEMBER <key> <value>: value가 존재하면 1, 없으면 0- 특정 유저를 follow하는 목록을 저장
-
Sorted-set
ZADD <key> <score> <value>: score 값으로 정렬된다. value가 이미 key에 있으면 해당 score로 변경된다.ZRANGE <key> <startindex> <endindex>: 해당 index 범위 값을 모두 돌려준다.- Zrange testkey 0 -1 : 모든 범위를 가져온다.

- 유저 랭킹 보드로 사용할 수 있다.
- ⭐️ score 값은 double 타입이기 때문에 값이 정확하지 않을 수 있다.
-
Hash
- key-value 밑에 sub key가 존재한다.
Hmset <key> <subkey1> <value1> <subkey2> <value2>Hgetall <key>: 해당 key의 모든 subkey와 value를 가져온다.Hget <key> <subkey>Hmget <key> <subkey1> <subkey2> .. <subkeyN>
✅ 야무지게 사용하기
Counting
- Strings
- 단순 증감 연산 :
INCR명령어로 value를 증가시킬 수 있다
- 단순 증감 연산 :
- Bits
- 데이터 저장공간 절약할 수 있다.
- sequential한 정수로 된 데이터만 카운팅 가능하다.
- Hyperloglogs
- 대용량 데이터를 카운팅할 때 적절하다. (오차 0.81%)
- set과 비슷하지만 저장되는 용량은 매우 작다 (12KB 고정)
- 저장된 데이터는 다시 확인할 수 없다. : 데이터 보호 목적으로도 사용가능
Messaging
- List
- 자체적인 Blocking 기능을 이용해 event queue로 사용 가능하다.
- 불필요한 polling process를 막을 수 있다.
- 트위터에서 타임라인을 구성하기 위해
RPUSHX를 사용한다. → 자주 접속하는 유저는 캐싱을 하고, 사용하지 않으면 삭제되어 key값이 없어진다.RPUSHX를 사용하면 키가 있을 때만 데이터 저장이 가능하다.
- Streams
- 로그를 저장하기 가장 적절한 자료구조
- append-only 방식
- 시간 범위로 검색 / 신규 추가 데이터 수신 / 소비자별 다른 데이터 수신 (소비자 그룹)
- kafka를 간단히 대체할 수 있다고 함
🚫 주의 사항
- 하나의 컬렉션에 아이템이 너무 많으면 좋지 않다.
- 10000개 이하 몇 천개 수준으로 유지하는게 좋다.
- Expire (TTL)는 collection의 item 개별로 걸리지 않고 전체 collection에 대해서만 걸린다
- 하나의 key가 만료되면 안에 있는 collection 전체가 삭제된다.
데이터 분산
- 데이터의 특성에 따라서 선택할 수 있는 방법이 달라진다
📌 Appliation 레벨
1️⃣ Consistent Hashing
- twemproxy를 사용하는 방법으로 쉽게 사용 가능하다
- 서버가 추가되거나 빠지더라도 해당 서버에 있는 데이터들만 리밸런싱이 일어난다.
2️⃣ Sharding
- 데이터를 어떻게 나누고 찾을 것인가?
- 상황마다 샤딩 방법이 달라진다
- Range
- 특정 range를 정의하고 해당 range에 속하면 거기에 저장한다.
- 확장은 편하지만, 당시 서버 상황에 따라 놀고 있는 서버와 열일하는 서버가 나뉜다.
- Modular
- 균등하게 분배되지만, 서버 한대가 추가될 때 재분배 양이 많아진다.
- Indexed
- 해당 key가 저장되어야할 관리 서버가 따로 존재한다.
- 서버가 2배로 늘어나면 반 나눠서 옮긴다.
- 인덱스 서버가 죽으면 분배가 안 된다.
📌 Redis cluster
-
Hash 기반으로 slot 16384로 구분한다.
-
hash 알고리즘은 CRC16을 사용한다.
-
slot = crc16(key) % 16384
실제 클러스터가 16384개를 넘을 수 없다.
-
key가
key{hashkey}패턴이면 실제 crc16에 hashkey가 사용된다.key{hashkey}: 원하는 서버로 보낼 수 있다.
-
특정 redis 서버는 이
slot range를 가지고 있고, 데이터 migration은 이 slot 단위의 데이터를 다른 서버로 전달하게 된다. (migrateCommand 이용)
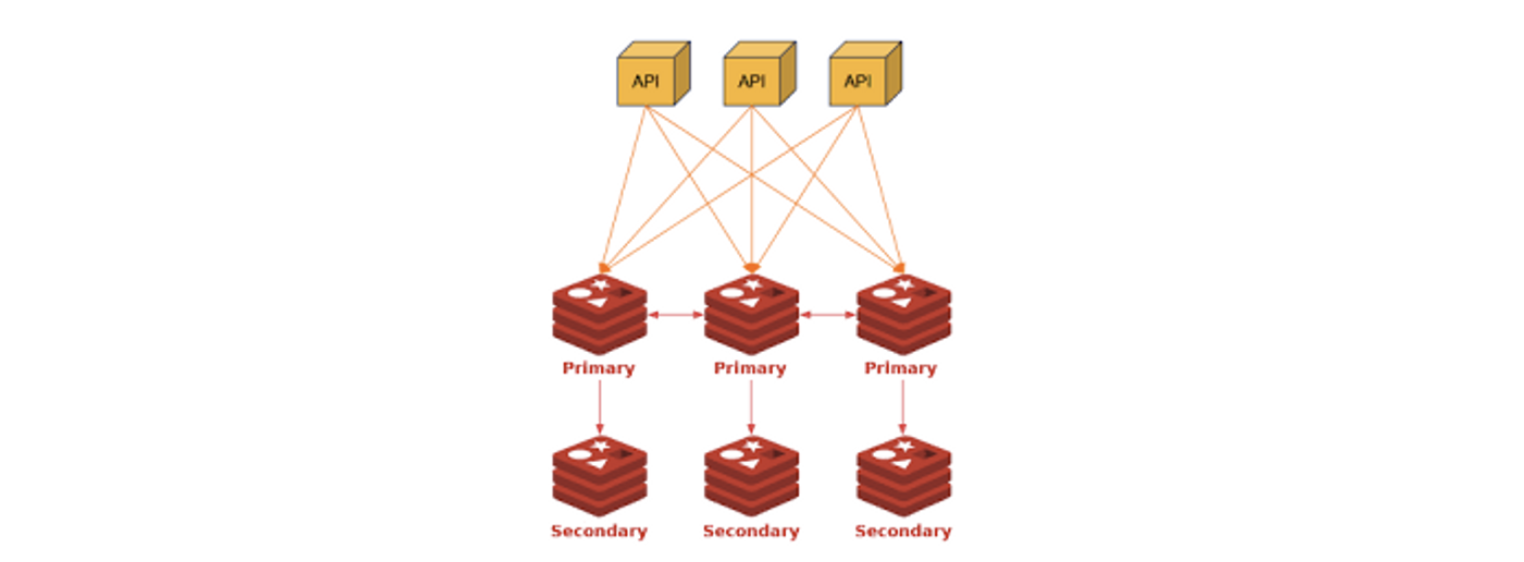
-
primary 서버가 죽으면 seconary가 primary가 된다
- primary와 secondary는 replication으로 연결이 되어 있다.
-
primary마다 slot range가 정해져있다.
slot이 잘못오면-MOVED <primary>응답을 하고 이에 따라서 클라이언트가 요청을 다시 맞는 primary에 보낸다
→ 이러한 처리는 보통 라이브러리에 구현이 되어있고, 직접 쓰려고 하면 구현을 해줘야 한다.
→ 레디스 클러스터는 라이브러리 의존적이다.
✅ 장점
- 자체적으로 헬스체크를 하고 primary, secondary failover를 한다.
- slot 단위의 데이터처리를 할 수 있다.
✅ 단점
- 슬롯 관리 등으로 메모리 사용량이 더 많따.
- migration 자체는 관리자가 시점을 결정해야 한다.
- Library 구현이 필요하다.
Redis Failoveer
📌 Coordinator 기반
- Zookeeper, etcd, consul 등의 Coordinator 사용
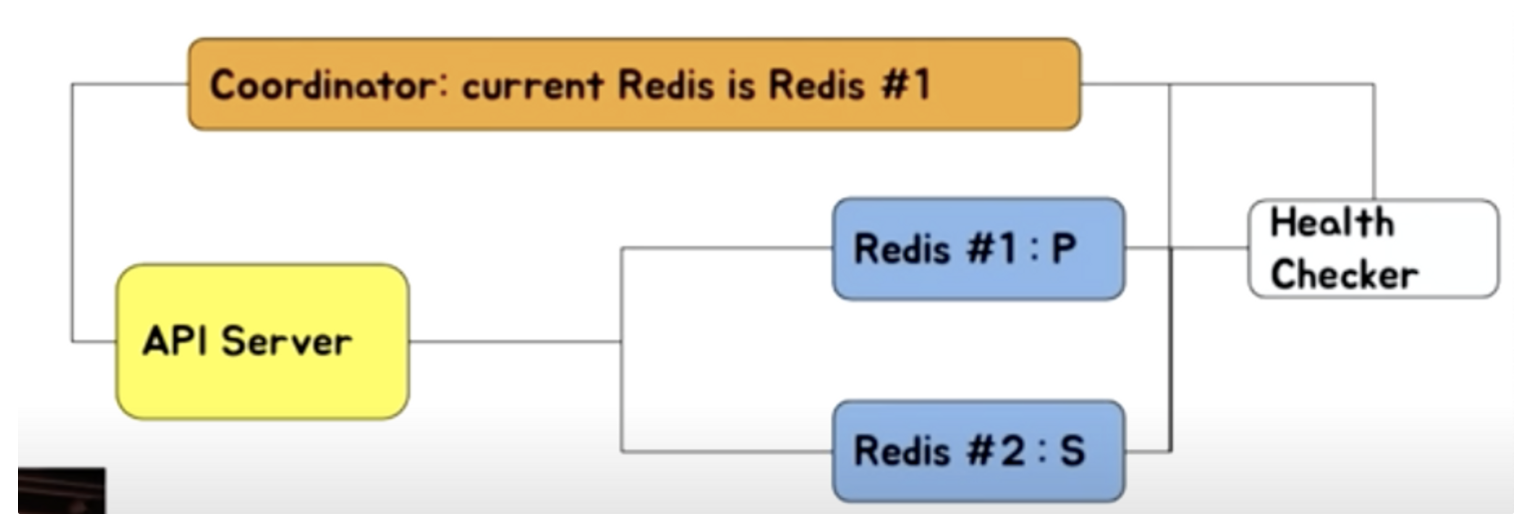
- Redis #1이 죽으면 health checker가 Redis #2를 primary로 승격시킨다.
- Health checker는 Coordinator에 current redis가 Redis #2라고 업데이트한다.
- Coordinator가 API 서버에 primary notify를 해준다.
- Coordinator 기반으로 설정을 관리한다면 동일한 방식으로 관리가 가능하다.
- 해당 기능을 이용하도록 개발이 필요하다.
📌 VIP (Virtual IP) 기반
- 가상 IP를 할당한다.
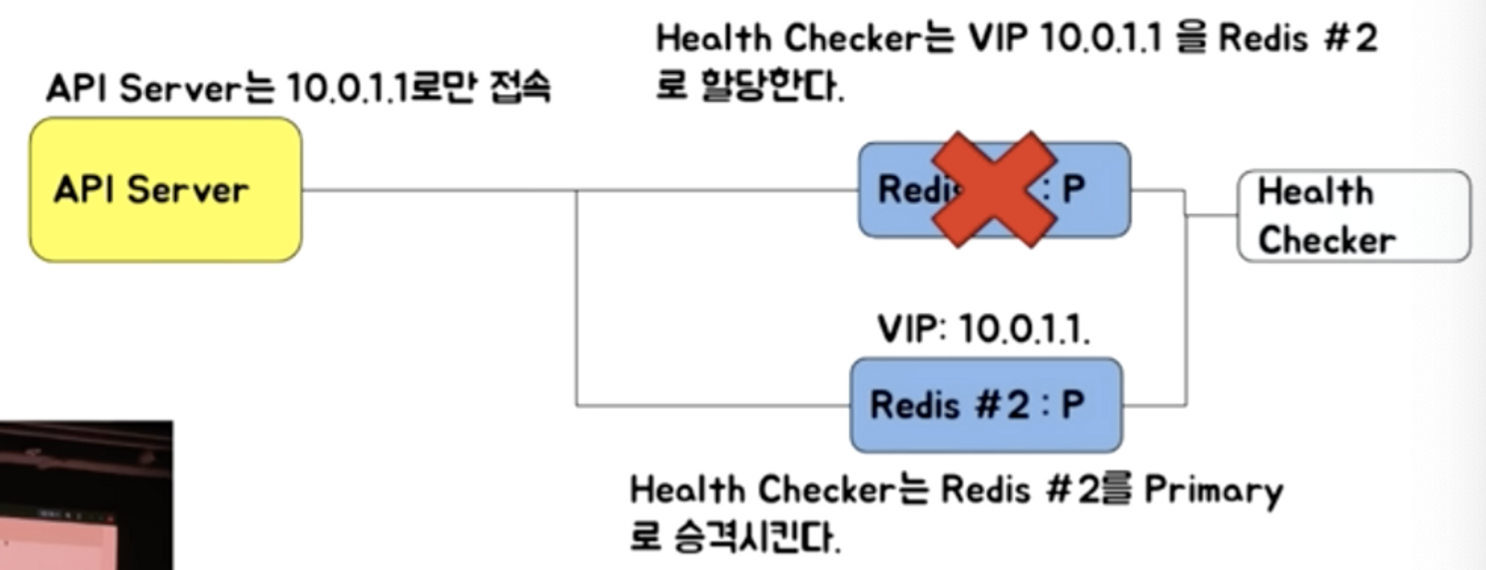
- API server는 10.0.1.1로만 접속한다.
- Redis #1이 죽으면 Redis #2를 primary로 승격시키고, health checker가 VIP 10.0.1.1을 Redis #2로 할당한다.
- health checker는 redis #1에 있던 기존 연결을 모두 끊어준다. (클라이언트의 재접속 유도)
📌 DNS 기반
VIP 방법과 유사하다.
- API server는 redis-primary.svc.io로만 접속한다.
- Redis #1이 죽으면 Redis #2를 primary로 승격시키고, health checker가 Redis #2로 도메인을 할당한다.
- health checker는 redis #1에 있던 기존 연결을 모두 끊어준다. (클라이언트의 재접속 유도)
✔︎ VIP 기반 vs DNS 기반
- 코드를 바꾸는 것이 아니다. 잠시 끊어지긴 하지만 자동복구가 된다.
- VIP 기반은 외부로 서비스를 제공해야 하는 서비스 업자에 유리하다. (클라우드 업체 등)
- DNS 기반은 DNS cache TTL을 관리해야 한다.
- 사용하는 언어에 따라서 DNS 캐싱 정책을 잘 알아야 한다. (자바는 30초)
- 툴에 따라서 한번 가져온 DNS 정보를 다시 호출하지 않는 경우도 존재한다.
Monitoring
Redis info를 통한 정보
- RSS : physical memory를 얼마나 쓰고 있느냐 (used memory rss)
- Used memory : reids가 생각하는 본인이 사용하고 있는 메모리
→ 이 차이가 크면 fragmentation이 증가하였다고 한다.
- 삭제되는 키가 많으면 fragmentaion이 증가한다.
- 특정 시점에 피크를 찍고 다시 삭제되는 경우
- TTL로 인해 eviction이 많이 발생하는 경우
CONFIG SET activedefrag yes커맨드를 사용하면 도움이 된다.- connection 수 : 클라이언트에서 접속할 때 connection을 맺었다 끊었다 하면 레디스 성능이 떨어진다. 보통 레디스 connection 수가 치솟았다가 떨어지는 거는 문제가 생긴 경우가 많다.
- 초당 처리 요청 수 : 기본적으로 짧은 명령일 때 CPU의 영향을 받는다.
System
- CPU
- disk : fork 등
- Network rx/tx : 너무 많은 데이터가 들어오면 switch에서 패킷 드랍을 해버린다.
✅ CPU 100%를 칠 경우
- 처리량이 매우 많다면?
- CPU 성능 좋은 서버로 이전
- 실제 CPU 성능에 영향을 받음
- 그러나 단순 get/set은 초당 10만 이상 처리 가능
- O(N) 계열의 특정 명령이 많은 경우
- Monitor 명령을 통해 (짧게 쓰기) 특정 패턴을 파악하는 것이 필요
Monitor: 현재 쓰는 명령어들이 나온다.
- Monitor 잘못쓰면 부하로 해당 서버에 더 큰 문제를 일이킬 수도 있음(짧게 쓰는게 중요함)
- Monitor 명령을 통해 (짧게 쓰기) 특정 패턴을 파악하는 것이 필요
영구 저장 (Redis persistence)
redis를 캐시 이외의 상황에 적용한다면 적절한 백업이 필요하다.
1️⃣ AOF (Append Only File)
: 데이터 변경하는 커맨드를 모두 저장
- 파일이 점점 커지기 때문에 압축해서 다시 저장해야 한다.
- 자동 : redis.conf 파일에서 auto-aof-rewrite-percentage 옵션 (크기 기준)
- 수동 :
BGREWRITEAOF커맨드를 이용해 cli 창에서 수동으로 AOF 파일 생성
2️⃣ RDB (snapshot)
: 저장 당시 파일을 저장한다.
- 자동 : redis.conf 파일에서 SAVE 옵션 (시간 기준)
- 수동 :
BGSAVE커맨드를 이용해 cli 창에서 수동으로 RDB 파일 저장 가능- SAVE 커맨드는 절대 사용 X
선택 기준
- 백업은 필요하지만 어느 정도의 데이터 손실이 발생해도 괜찮은 경우
- RDB 단독 사용
- redis.conf 파일에서 SAVE 옵션을 적절히 사용
- 장애 상황 직전까지의 모든 데이터가 보장되어야할 경우
- AOF 사용 (appendonly yes)
- APPENDFSYNC 옵션이 everysec인 경우 최대 1초 사이의 데이터 유실 가능 (기본 설정)
- 제일 강력한 내구성이 필요한 경우
- RDB & AOF 동시 사용
아키텍쳐 선택
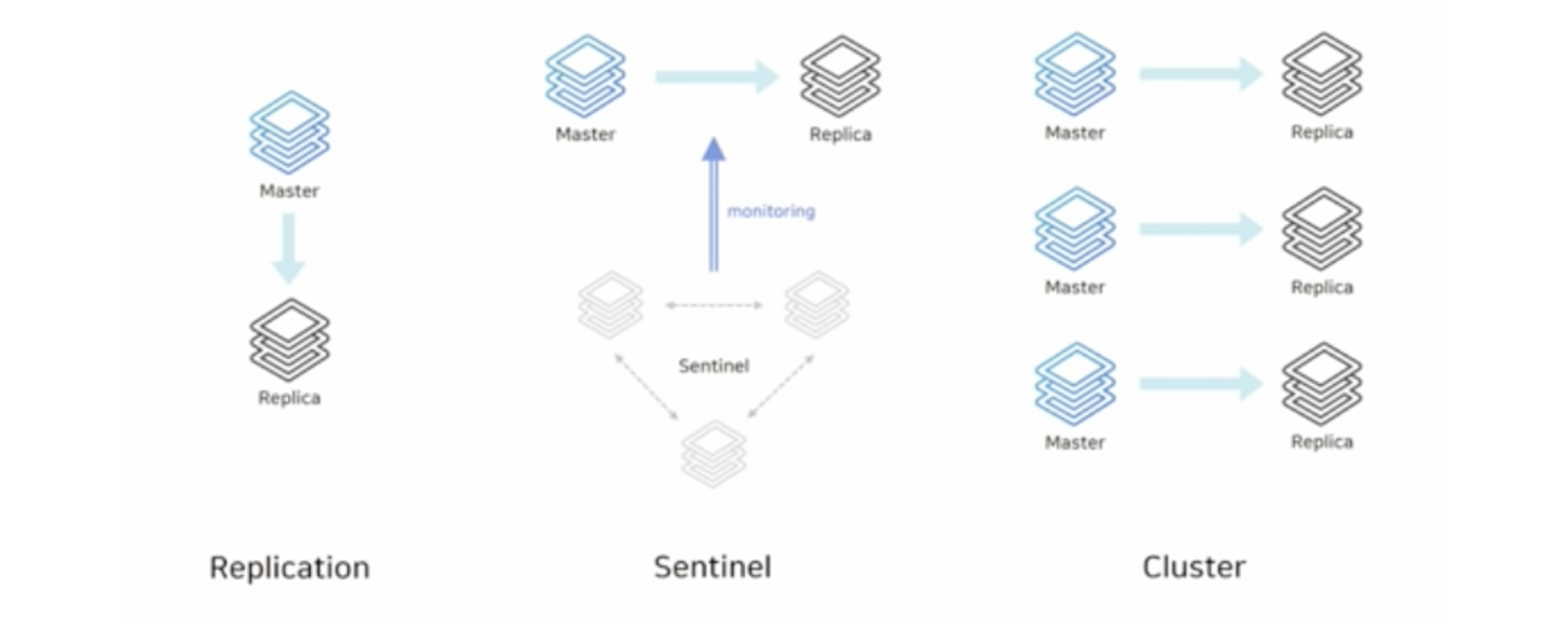
1️⃣ Replication 구성
replicaof커맨드를 이용해서 간단하게 복제 연결- 비동기식 복제
- HA 기능이 없으므로 장애 상황 시 수동 복구
replicaof no one으로 수동으로 연결을 끊는다.- 애플리케이션에서 연결 정보 변경
2️⃣ Sentinel
- 자동 failover 가능한 HA 구성 (High Availability)
- sentinel 노드가 다른 노드를 감시한다.
- 마스터가 비정상 상태일 때 자동으로 failover → replica가 마스터가 된다.
- 연결 정보 변경 필요 없음 - sentinel 정보만 알면 마스터로 바로 연결시켜 준다.
- sentinel 노드는 항상 3대 이상의 홀수로 존재해야 한다.
- 과반수 이상의 sentinel이 동의해야 failover 진행 가능하다.
- 마스터와 replica 노드에 sentinel을 같이 띄울 수 있다.
3️⃣ Cluster
- 스케일 아웃과 HA 구성 (High Availability)
- 키를 여러 노드에 자동으로 분할해서 저장 (sharidng)
- 모든 노드가 서로를 감시하며, 마스터가 비정상일 때 failover
- 최소 3대의 마스터 노드가 필요하다.
Redis 운영
✅ 메모리 관리를 잘하자
✅ O(N) 관련 명령어는 주의하자
✅ Replication
✅ 권장 설정
✅ 메모리 관리를 잘하자
-
Redis는 In-memory data store
-
physical memory 이상을 사용하면 문제가 발생한다
swap: 메모리 페이지를 디스크에 저장하고 다른 업무를 처리한다. 한 번 swap된 페이지는 계속 swap된다.- swap이 있다면 swap 사용으로 해당 메모리 page 접근시마다 늦어진다.
- 갑자기 속도가 00ms ~ 000ms로 느려진다면 이를 의심해보자.
- swap이 없다면 OOM 등으로 죽을 수 있다
-
Maxmemory를 설정하더라도 이보다 더 사용할 가능성이 크다.- 설정된 메모리보다 크면 키를 랜덤하게 지우거나 만료된 것을 지우고 메모리를 확보하고 사용하게 된다.
- Memory allocator에 의존하기 때문에 redis는 자신이 사용하는 메모리가 얼마인지 정확하게 알 수 없다.
- 메모리는 페이지 단위로 할당한다. 메모리 파편화가 생길 수 있어서 메모리 관리를 잘 해야한다.
RSS 값을 모니터링해야한다.
-
큰 메모리를 사용하는 instance 하나보다는 작은 메모리를 사용하는 instance 여러개가 안전하다.(예, 24 GB < 8GB * 3개)
- master-slave 구조를 사용하면 fork를 많이 하게 된다. read를 많이 하는 것은 상관없는데, write가 무거우면 최대 메모리를 2배까지 쓸 수 있다. ← 처음에 fork를 하게 되면, copy on write로 메모리 write에서는 메모리를 복사해서 더 써야한다.
- master-slave 구조를 사용하면 fork를 많이 하게 된다. read를 많이 하는 것은 상관없는데, write가 무거우면 최대 메모리를 2배까지 쓸 수 있다. ← 처음에 fork를 하게 되면, copy on write로 메모리 write에서는 메모리를 복사해서 더 써야한다.
-
Redis는 메모리 파편화가 발생할 수 있다. 4.x대부터 메모리 파편화를 줄이도록 jemalloc에 힌트를 주는 기능이 들어갔으나, jemalloc 버전에 따라서 다르게 동작할 수 있다.
-
3.x대 버전의 경우 실제 used memory는 2GB로 보고가 되지만 11GB의 RSS를 사용하는 경우가 자주 발생한다.
-
다양한 사이즈를 가지는 데이터보다는 유사한 크기의 데이터를 가지는 경우가 유리하다.
○ 메모리가 부족할 때는
- Cache is Cash
- 좀 더 메모리 많은 장비로 migration
- 메모리가 빡빡하면 migration 중에 문제가 발생할 수 있다..
- 있는 데이터 줄이기
- 데이터를 일정 수준에서만 사용하도록 특정 데이터를 줄인다.
- 다만 이미 swap을 사용 중이라면, 프로세스를 재시작해야 한다.
○ 메모리를 줄이기 위한 설정
Collection들은 아래와 같은 자료구조를 사용한다.
- Hash → Hash Table을 하나 더 사용
- Sorted set → Skiplist와 HashTable을 이용
- Set → Hash Table 상용
해당 자료구조들은 메모리를 많이 사용한다.
→ Ziplist를 사용하면 속도는 좀 느리지만 메모리는 적게 사용한다. 설정으로 바꿀 수 있다.
📌 Ziplist 구조
- In-memory 특성 상, 적은 개수라면 선형 탐색을 하더라도 빠르다.
- List, hash, sorted set 등을 작은 개수에서는 ziplist로 대체해서 처리하는 설정이 존재한다.
✅ O(N) 관련 명령어는 주의하자
- Redis는 single thread
- 동시에 하나의 명령만 처리할 수 있다.
- 단순한 get, set의 경우, 초당 10만 TPS 이상 가능
- packet으로 하나의 command가 완성되면 processCommand에서 실제로 실행된다.
→ 오래걸리는 명령을 실행하면 뒤에는 다 기다리게되고, 타임아웃이라도 설정됭어 있으면 터지게된다.
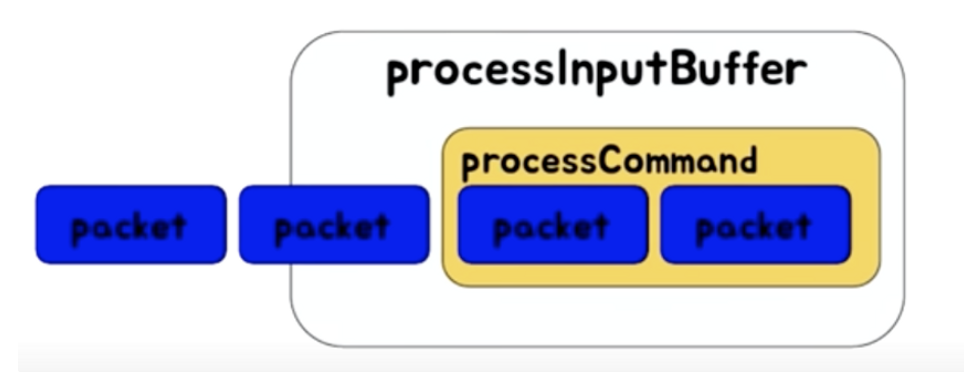
📌 오래걸리는 명령어 - O(N)
-KEYS
-FLUSHALL,FLUSHDB: 다 지우는 것
-Delete Collections
-Get all collections
대표적인 실수 사례
- key가 백만개 이상인데 확인을 위해
KEYS명령어를 사용하는 경우scan: 하나의 긴 명령을 짧은 여러번의 명령으로 바꿀 수 있다.- 텀 사이에 시간이 짧은 명령들이 실행될 수 있다
- 아이템이 몇 만개든 hash, sorted set, set에서 모든 데이터를 가져오는 경우
- collection의 일부만 가져온다
- 큰 collection을 작은 여러 개 (최대 100만개)로 나눠서 저장한다.
hgetail→hscandel→unlink(키를 백그라운드로 지워준다)
- 예전의 spring security oauth RedisTokenStore : 최신은 개선 되었다
- Access Token을 저장할 때 List(O(N)) 자료구조를 통해서 이루어진다. → 검색, 삭제 시 모든 item을 매번 찾아야 한다.
- 현재는 set(O(1))로 변경되었다.
- Access Token을 저장할 때 List(O(N)) 자료구조를 통해서 이루어진다. → 검색, 삭제 시 모든 item을 매번 찾아야 한다.
✅ Redis Replication
-
Async Replication
- replication lag이 발생할 수 있다.
- A에서 변경이 있어서 B로 전파하는 사이에 데이터의 차이가 생길 수 있다.
- 중간에 lag이 심하게 발생하면 연결을 아예 끊었다가 다시 연결하는 경우도 있는데 이 때 부하가 많이 걸린다.
-
Replicaof(≥ 5.0.0) orslaveof명령으로 설정 가능- Replicaof hostname port
-
DBMS로 보면 statement replication가 유사
- 쿼리로 실행된다. Lua script를 쓰면 now 같은 경우는 다른 값이 나올 수 있다.
-
Replication 설정 과정
- Secondary에 replicaof 또는 slaveof 명령을 전달
- Secondary는 primary에 sync 명령 전달
- Primary는 현재 메모리 상태를 저장하기 위해
fork→ 메모리 부족이 발생할 수 있다
- fork한 프로세서는 현재 메모리 정보를 disk에 dump (디스크도 많이 쓰고)
- 해당 정보를 secondary에 전달
- fork 이후의 데이터를 secondary에 계속 전달
- Redis-cli —rdb 명령 (dump) 은 현재 상태의 메모리 스냅샷을 가져오므로 같은 문제를 발생시킨다.
- AWS (ElastiCache)나 클라우드의 Redis는 좀 다르게 구현되어서 해당 부분이 비교적 안정적이다
→ fork 없이 replication을 하는데 느리다.
-
많은 대수의 redis 서버가 replica를 두고 있다면
- 네트워크 이슈나 사람의 작업을 동시에 replication이 재시도 되도록 하면 문제가 발생할 수 있다.
→ 같은 네트워크안에서 30GB를 쓰는 Redis Master 100대 정도가 리플리케이션을 동시에 재시작하면?
- 네트워크 이슈나 사람의 작업을 동시에 replication이 재시도 되도록 하면 문제가 발생할 수 있다.
✅ 권장 설정
-
Maxclient: 50000 (높게 주는 것이 좋다) -
RDB/AOF : off, 또는 replica만 켠다 (성능 상으로도 안정성도 높다)
-
특정 commands disable
Keys- AWS의 ElastiCache는 이미 설정되어 있음
-
전체 장애의 90% 이상이 KEYS와 SAVE 설정을 사용해서 발생
SAVE: 디폴트로 몇 건 이상의 변경이 있으면 저장하는 건데 실제 서비스에서 흔히 생길 수 있어서 끄는 것이 좋음
-
ziplist 사용
-
STOP-WRITES-ON-BGSAVE-ERROR = NO- yes (default)
- RDB 파일 저장 실패 시 redis로의 모든 write 불가능하게 하는 기능
-
MAXMEMORY-POLICY = ALLKEYS-LRU- redis를 캐시로 사용할 때 expire time 설정 권장
- 메모리가 가득 찼을 때 MAXMEMORY-POLICY 정책에 의해 키 관리
- noeviction (default) : 삭제 안 함, 메모리가 가득차면 새로운 키를 저장 안 함 → 장애
- volatile-lru : expire time 설정이 있는 키값만 사용. 다 expire time이 없으면 위와 같아진다.
- allkeys-lru
📌 Cache Stampede
TTL 값을 너무 작게 설정한 경우, 키가 만료되면 해당 키를 바라보던 모든 어플리케이션들이 DB에 요청해서 저장하는 Duplicated read & write가 발생한다. 몹시 비효율적이라 장애로까지 이어질 수 있다.
📎 결론
-
레디스는 기본적으로 매우 좋은 툴이다
-
그러나 메모리를 빡빡하게 쓸 경우 관리가 어렵다.
- 32기가 장비면 24기가 이상 사용하면 장비 증설을 고려하는 것이 좋음
- Write가 Heavy할 경우 마이그레이션도 주의해야 함.
-
client-output-buffer-limit: 메모리가 클 수록 크게 잡아야 한다. 이 값을 넘어가면 connection을 끊어버린다. -
레디스를 Cache로 쓰는 경우 - 문제가 적게 발생
- 레디스가 문제가 있을 때 DB등의 부하가 어느정도 증가하는지 확인 필요함 → DB가 못 버틸 정도면 문제가 있지만, 아니면 캐시는 다시 만들어주면 된다.
- Consistent Hashing도 부하를 아주 균등하게 나누지는 않음 → adaptive consistent hashing 같은 방법도 있다.
- 레디스가 문제가 있을 때 DB등의 부하가 어느정도 증가하는지 확인 필요함 → DB가 못 버틸 정도면 문제가 있지만, 아니면 캐시는 다시 만들어주면 된다.
-
레디스를 Persistent Store로 쓰는 경우
- 무조건 Primary/Secondary 구조로 구성이 필요함
- 메모리를 절대로 빡빡하게 사용하면 안됨 - 넉넉하게
- 정기적인 마이그레이션 필요
- 가능하면 자동화 툴 만들어 사용
- 정기적으로 백업할 때도 secondary에서 백업
- RDB/AOF가 필요하다면 Secondary에서만 구동
- RDB보다는 AOF가 IO가 균등하게 여러번 발생하기 때문에 안정적이다.
참고 :
https://redis.io/
https://www.youtube.com/watch?v=mPB2CZiAkKM
https://www.youtube.com/watch?v=jgpVdJB2sKQ
