4.2 소트 머지 조인
옵티마이저는 아래 상황에서 NL 조인 대신 소트 머지 조인이나 해시 조인을 선택한다.
- 조인 컬럼에 인덱스가 없을 때
- 대량 데이터 조인이어서 인덱스가 효과적이지 않을 때
해시 조인이 생기고 소트 머지 조인의 쓰임새가 예전만 못하지만, 대량 데이털르 조인할 때는 유용하다.
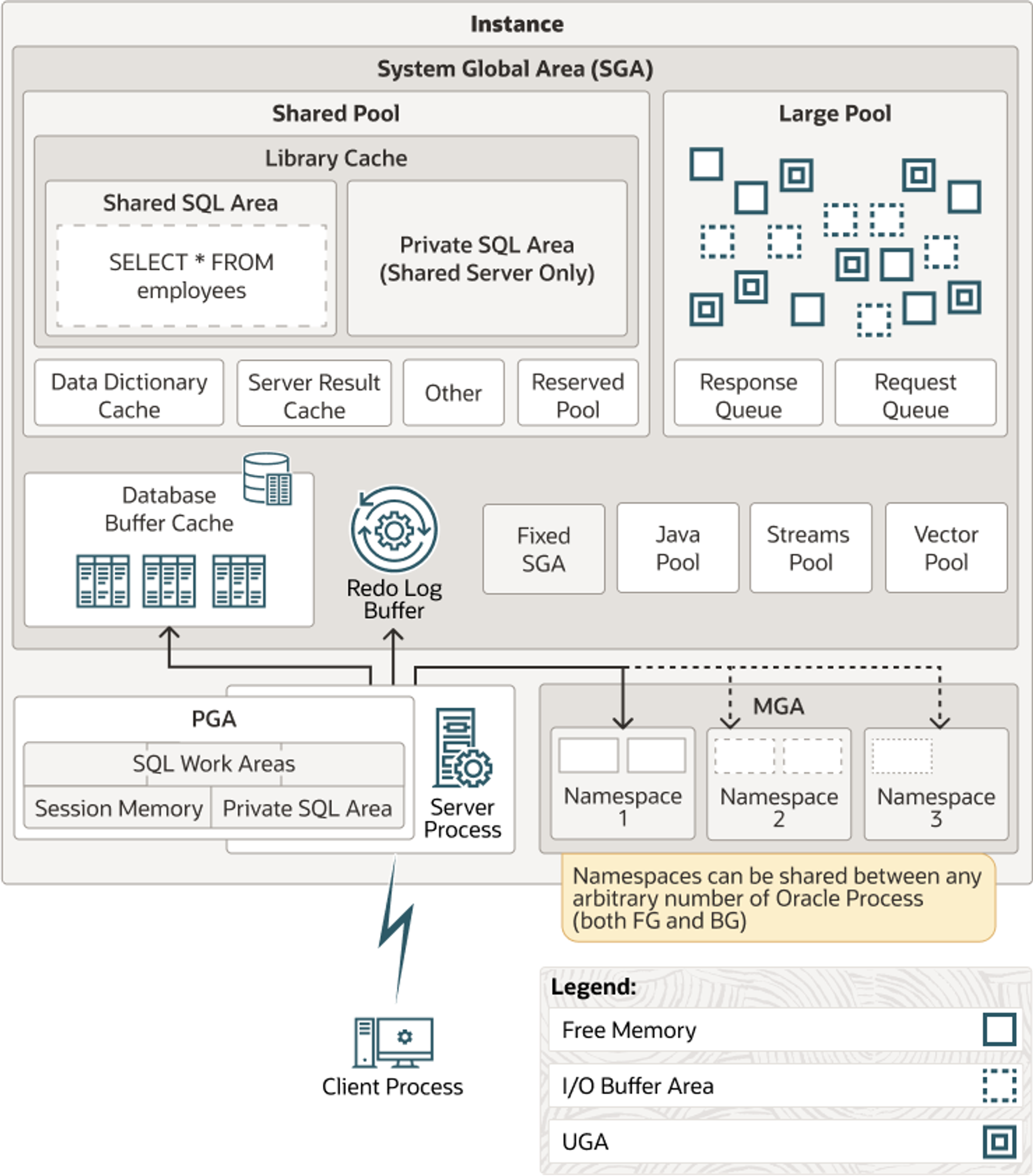
4.2.1 SGA & PGA
SGA (System Global Area, Shared Global Area)
PGA (Process/Program/Private Global Area)
- SGA
- SGA에 캐시된 데이터는 여러 프로세스가 공유 ⭕
- 동시에 액세스 ❌ : 프로세스 간 액세스 직렬화를 위한 Lock 메커니즘인 Latch가 있음.
- 데이터 블록과 인덱스 블록을 캐싱하는 DB 버퍼캐시는 SGA의 가장 핵심적인 구성요소로, 블록을 읽으려면 버퍼 Lock도 얻어야 한다.
- PGA
- 오라클 서버 프로세스는 SGA에 공유된 데이터를 읽고 쓰면서, 동시에 자신만의 고유한 메모리 영역 PGA를 갖는다.
- 프로세스에 종속적인 고유 데이터를 저장하는 용도로 사용
- PGA는 다른 프로세스와 공유하지 않으므로 래치 메커니즘이 필요 ❌ → 같은 양의 데이터를 읽더라도 SGA 버퍼캐시에서 읽을 때보다 훨씬 빠르다.
4.2.2 기본 메커니즘
- 소트 단계 : 양쪽 집합을 조인 컬럼 기준으로 정렬
- 머지 단계 : 정렬한 양쪽 집합을 서로 머지
select /*+ ordered use_merge(c)*/
e.사원번호, e.사원명, e.입사일자,
c.고객번호, c.고객명, c.전화번호, c.최종주문번호
from 사원 e, 고객 c
where c.관리사원번호 = e.사원번호
and e.입사일자 >= '19960101'
and e.부서코드 = 'Z123'
and c.최종주문금액 >= 20000-
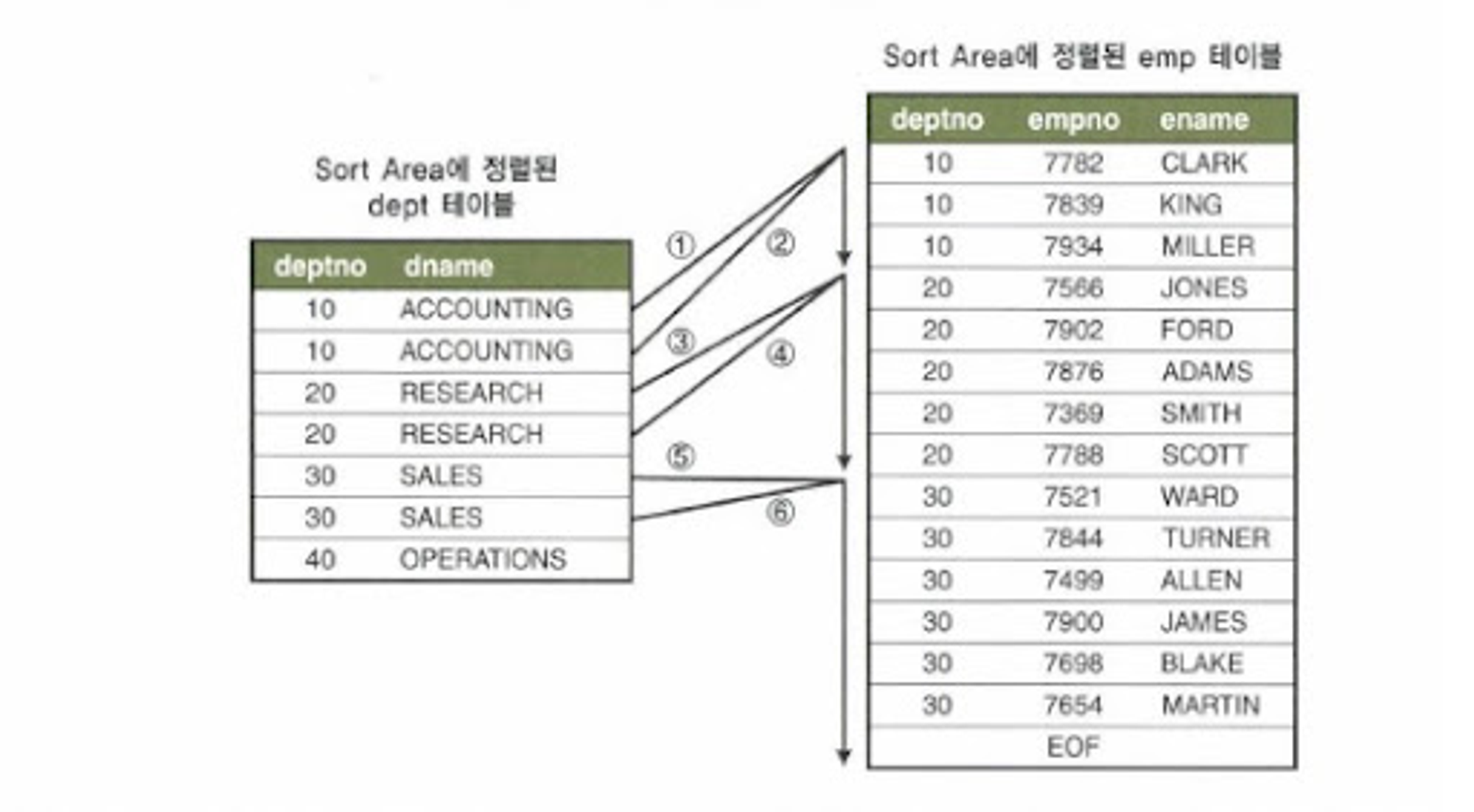
sort) 사원 데이터를 읽어 조인 컬럼인 사원번호 순으로 정렬한다. 정렬한 결과집합은 PGA 내의 Sort Area에 저장한다.
select 사원번호, 사원명, 입사일자 from 사원 where 입사일자 >='19960101' and 부서코드 = 'Z123' order by 사원번호 -
sort) 고객 데이터를 읽어 조인컬럼인 관리사원번호 순으로 정렬한다. 정렬한 결과집합은 PGA 내의 Sort Area에 저장한다.
select 고객번호, 고객명, 전화번호, 최종주문번호 from 고객 c where 최종주문금액 >=20000 order by 관리사원번호 -
merge) PGA에 저장한 사원 데이터를 스캔하면서 PGA에 저장한 고객 데이터와 조인한다.
실제 조인 오퍼레이션은 NL 조인과 비슷하다.
사원 데이터를 기준으로 고객 데이터를 매번 Full scan하지 않는다. 고객 데이터가 정렬되어 있으므로 조인 대상 레코드가 시작되는 지점을 알고 아닌 지점에서 바로 멈출 수 있기 때문이다.
4.2.3 소트 머지 조인이 빠른 이유
NL 조인의 치명적인 단점은 대량 데이터 조인에서 성능이 매우 느리다는 것이다.
→ 인덱스를 이용한 조인 방식으로 조인 과정에서 액세스하는 모든 블록을 랜덤 액세스 방식으로 ‘건건이’ DB 버퍼캐시를 경유해서 읽는다.
→ 즉, 읽는 모든 블록에 래치 획득 및 캐시버퍼 체인 스캔 과정을 거친다.
소트 머지 조인은 양쪽 테이블로부터 조인 대상 집합 (조인 조건 이외 필터 조건을 만족하는 집합)을 ‘일괄적으로’ 읽어 PGA에 저장한 후 조인한다.
→ PGA는 데이터를 읽을 때 래치 획득 과정이 없어 대량 데이터 조인에 유리하다.
소트 머지 조인도 양쪽 테이블로부터 조인 대상 집합을 읽을 때는 DB 버퍼캐시를 경유한다. 이때 인덱스를 이용하기도 하며, 이 때 버퍼캐시 탐색 비용과 랜덤 액세스 부하는 발생할 수 있다.
4.2.4 소트 머지 조인의 주용도
한때 NL 조인의 한계를 보완하였지만 대부분 해시 조인이 더 빠르다.
하지만 해시 조인은 조인 조건식이 등치 (=) 조건이 아닐 때 사용할 수 없다는 단점이 있다.
- 조인 조건식이 등치(=) 조건이 아닌 대량 데이터 조인
- 조인 조건식이 아예 없는 조인(Cross Join, 카다시안 곱)
에서 주로 사용하게 된다.
4.2.5 소트 머지 조인 제어하기
소트 머지 조인 실행계획 : 양쪽 테이블을 각각 소트한 후, 위쪽 사원 테이블 기준으로 아래쪽 고객 테이블과 머지 조인한다.
MERGE JOIN
SORT (JOIN)
TABLE ACCESS (BY INDEX ROWID) OF '사원' TABLE
INDEX (RAGNE SCAN) OF '사원_X1' (INDEX)
SORT (JOIN)
TABLE ACCESS (BY INDEX ROWID) OF '고객' TABLE
INDEX (RAGNE SCAN) OF '고객_X1' (INDEX)4.2.6 소트 머지 조인 특징 요약
- 소트 머지 조인은 실시간으로 인덱스를 생성하는 것과 다름없다. 소트 부하만 감수하면 건건이 버퍼캐시를 경유하는 NL 조인보다 빠르다.
- 소트 머지 조인은 인덱스에 영향을 받지 않는다. 따라서 조인 컬럼에 인덱스가 없는 상황에서 조인 대상 집합을 줄일 수 있어 유용하다.
- 스캔 위주의 액세스 방식을 사용한다. 조인 대상 레코드를 찾을 때는 인덱스를 이용할 수 있고, 그때는 랜덤 액세스가 일어난다.
