정규화 (Normalization)
의미

데이터 중복과 insertion, update, deletion anomaly를 최소화 하기 위해 일련의 normal forms(NF)에 따라 relational DB를 구성하는 과정
* anomaly : 변칙, 이상
normal form

정규화 되기 위해 준수해야할 몇가지 규칙
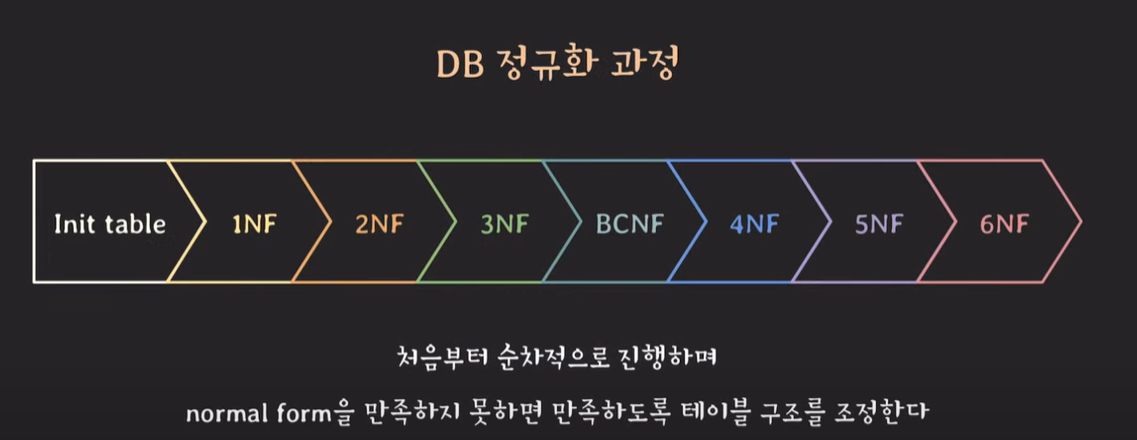
앞 단계를 만족해야 다음 단계로 진행할 수 있다.
3NF를 만족할 경우 1NF, 2NF를 만족한 상태이다.
1NF -> 2NF -> 3NF -> BCNF
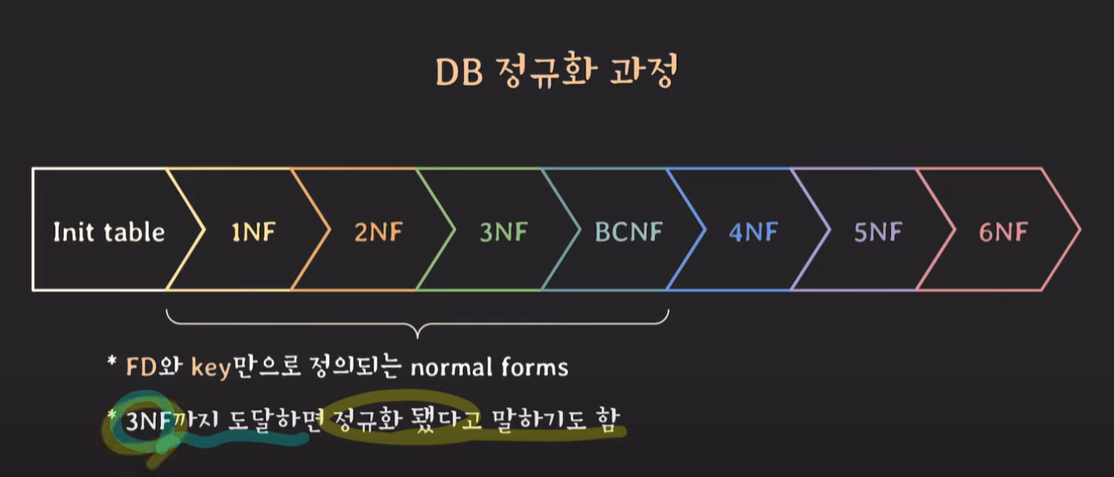
실무에서는 주로 3NF 혹은 BCNF까지 진행(많이 해도 4NF 정도 까지만 진행)
BCNF까지는 FD(funtional dependency)와 key만으로 정의되는 normal forms이다.
예제 Table Schema

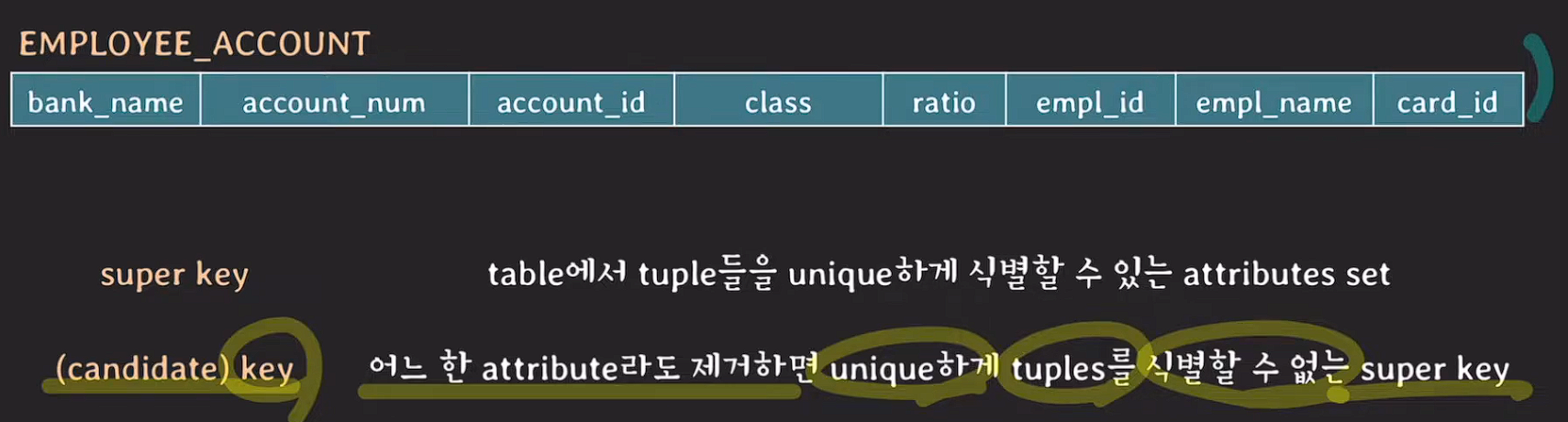
super key : table에서 tuple들을 unique하게 식별할 수 있는 attributes set
(candidate) key : 어느 한 attribute라도 제거하면 unique하게 tuple들을 식별할 수 없는 super key
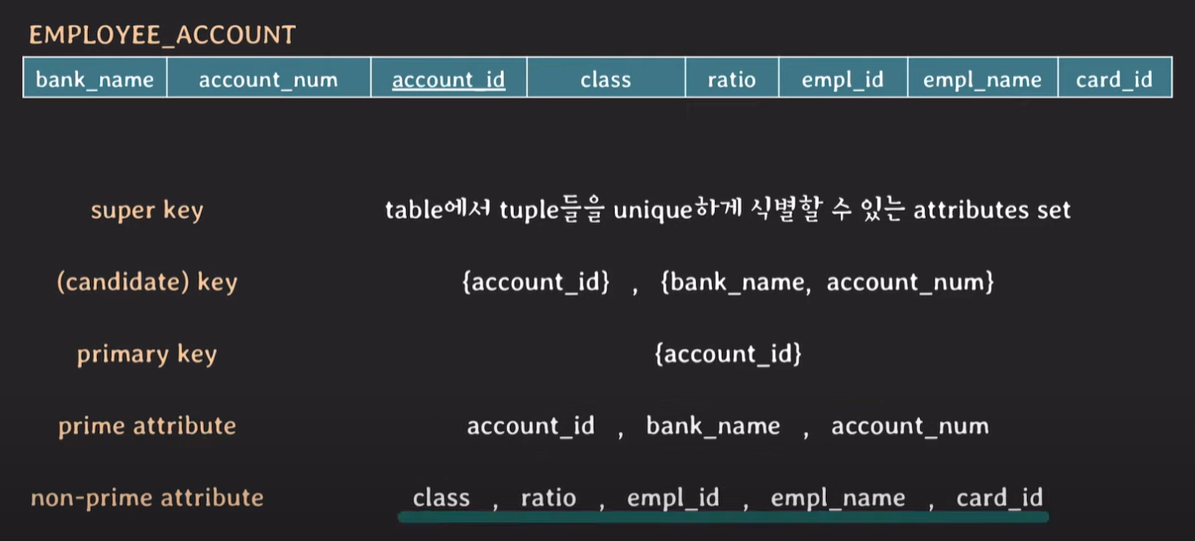
primary key : table에서 tuple들을 unique하게 식별하도록 선택한 키
candidate key중 tuple을 unique하게 식별하기 위해 선택된 key, primary key는 attibute의 수가 적을수록 관리하기 쉽다.
prime attribute : 임의의 (candidate)key에 속하는 attribute
non-prime attribute : 어떠한 key에도 속하지 않는 attribute
예제 FD
account_id

account_id가 같다면 나머지 attribute들의 데이터가 같다.
bank_name, account_num
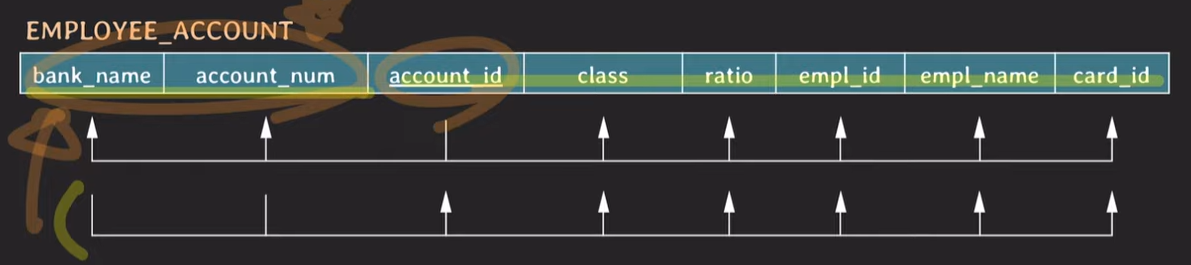
class
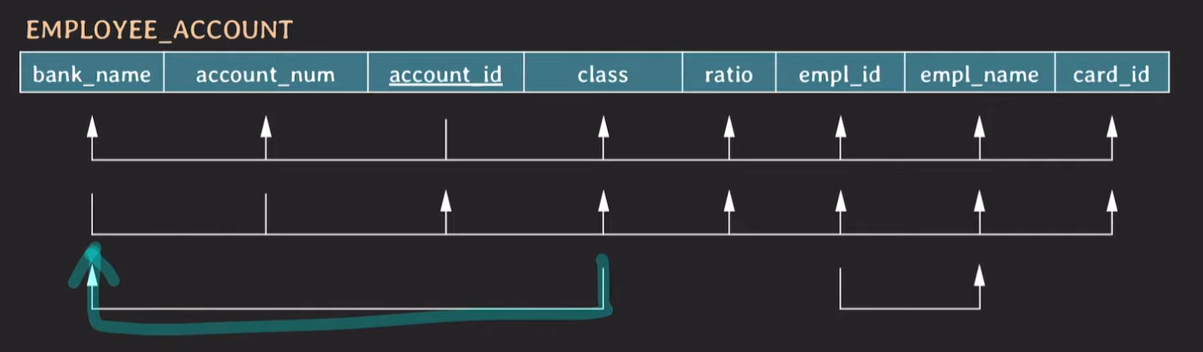
각은행별 class의 이름이 다르다.
해당 회원이 어떤 class를 가지고 있는지 파악하면 어떤 은행인지 파악이 가능하다. 즉 class가 같으면 bank_name이 같을 수 밖에 없다.
예제 data
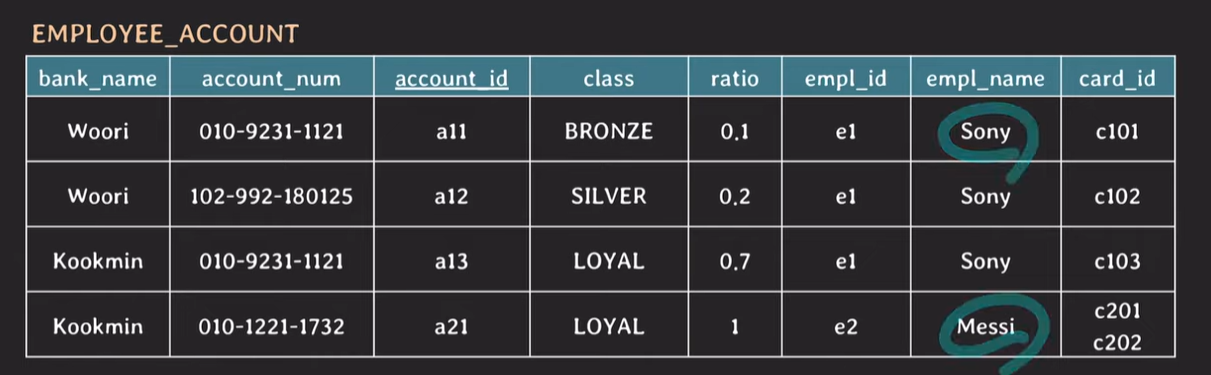
1NF
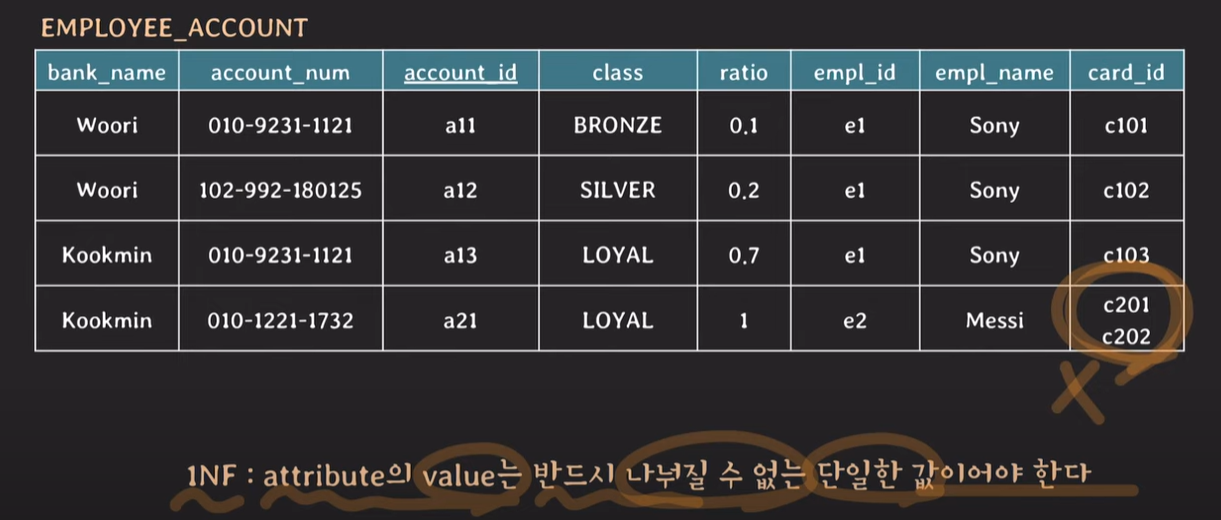
attribute의 value는 반드시 나눠질 수 없는 단일한 값이어야한다.

Messi의 tuple에 card_id는 나눠질 수 있다. 따라서 card_id를 나눠서 하나의 tuple을 더 생성하지만, card_id를 제외한 나머지 attribute의 값들은 같다.
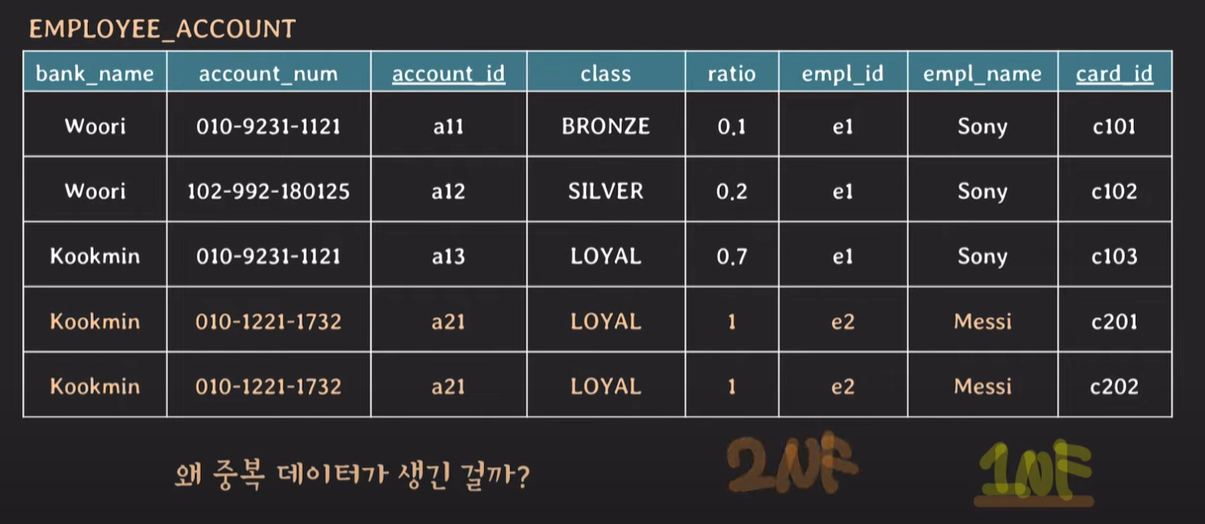
1NF 후 발생된 문제 : card_id를 나누고, ratio의 합은 1이여야하는데 1이 초과하고, primary key (account_id)가 더이상 tuple을 unique하게 식별할 수 없다. primary key를 변경해주어야한다. {account_id, card_id}를 primary key로 설정한다.

1NF를 마치고 key attribute set에 card_id가 각각 추가된다.
key에 해당하지 않는 non-prime attribute = class, ratio, empl_id, empl_name
2NF

card_id가 존재하지 않아도 non-prime attribute가 unique하게 결정될 수 있다.


non-prime attribute들이 부분적으로 {account_id, card_id}에 의존하는 상태이다.
Messi의 card_id가 분리되었기 때문에 중복된 데이터가 생성되었다. 근데 이때 새로 생긴 tuple을 제외하고, card_id가 없어도 account_id만으로 non-prime attribute들을 결정할 수 있다. 2NF 필요
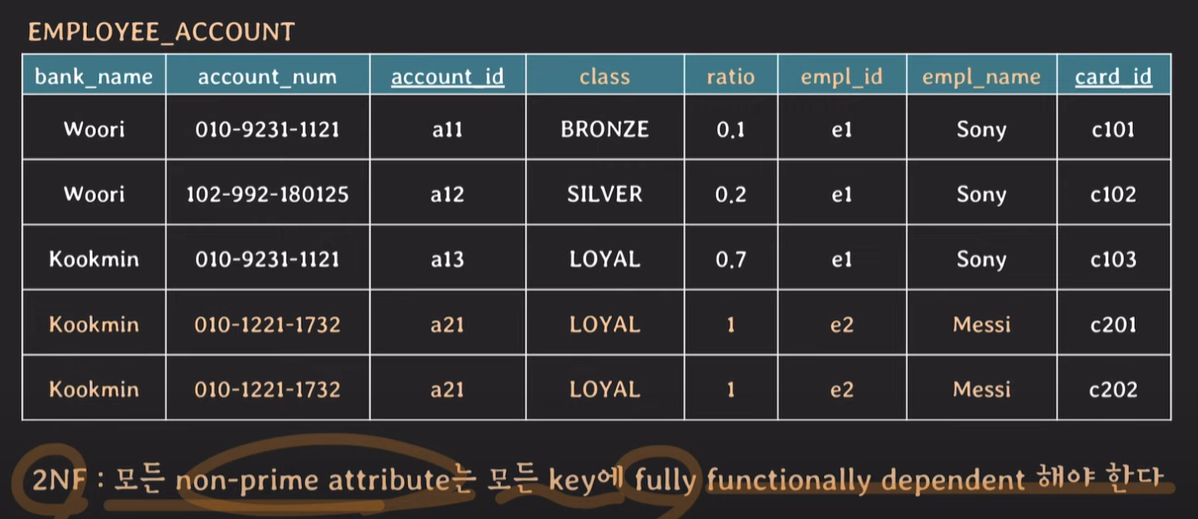
2NF : 모든 non-prime attribute는 모든 key에 fully functionally dependent 해야 한다.
class, ratio, empl_id, empl_name은 (candidate) key {account_id, card_id}, {bank_name, account_num, card_id}에 대해 전체적으로 의존적이어야한다.
* fully funtional dependency : X의 부분집합이 아닌, X의 집합 전부가 Y를 결정짓는 유효한 상황인 경우
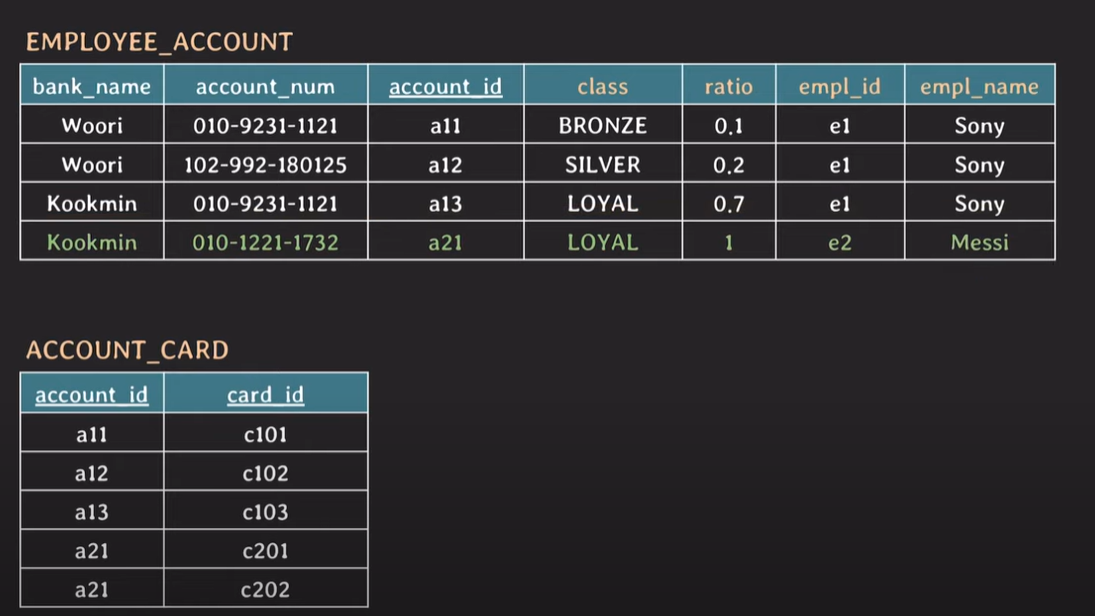
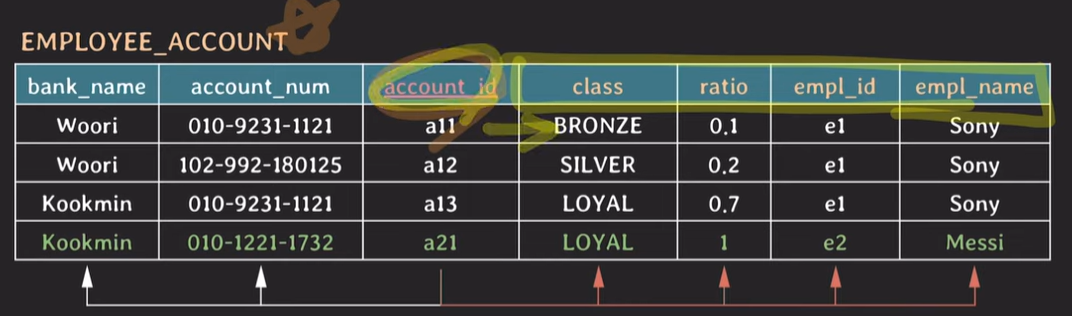
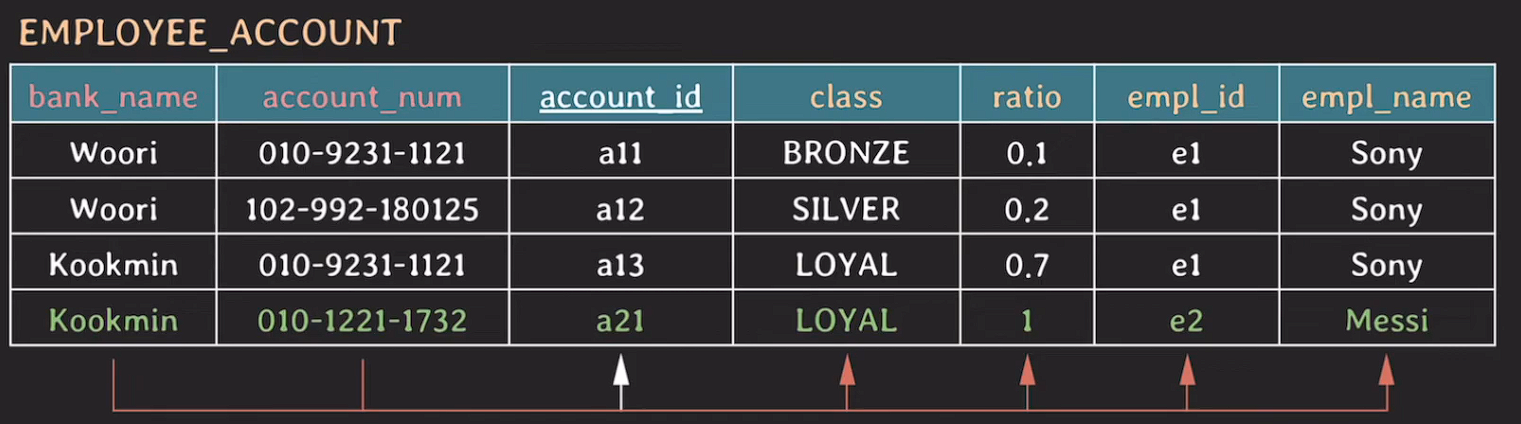
non-prime attribute들이 {account_id} , {bank_name, account_num}에의해 unique하게 결정된다.
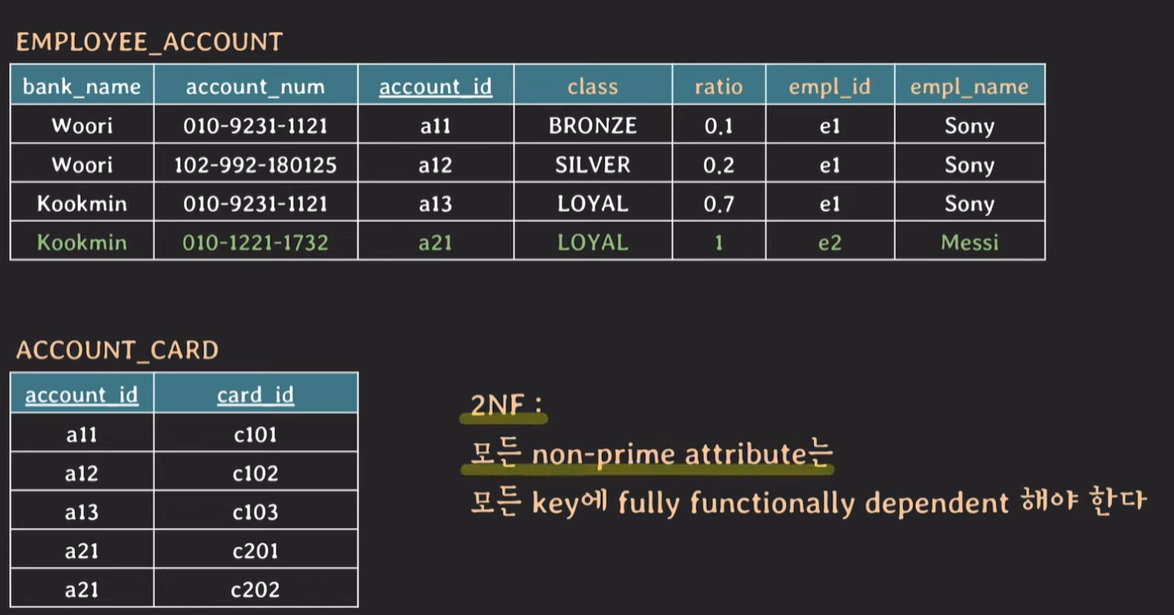
2NF : 모든 non-prime attribute는 모든 key에 fully functionally dependent 해야한다.
3NF
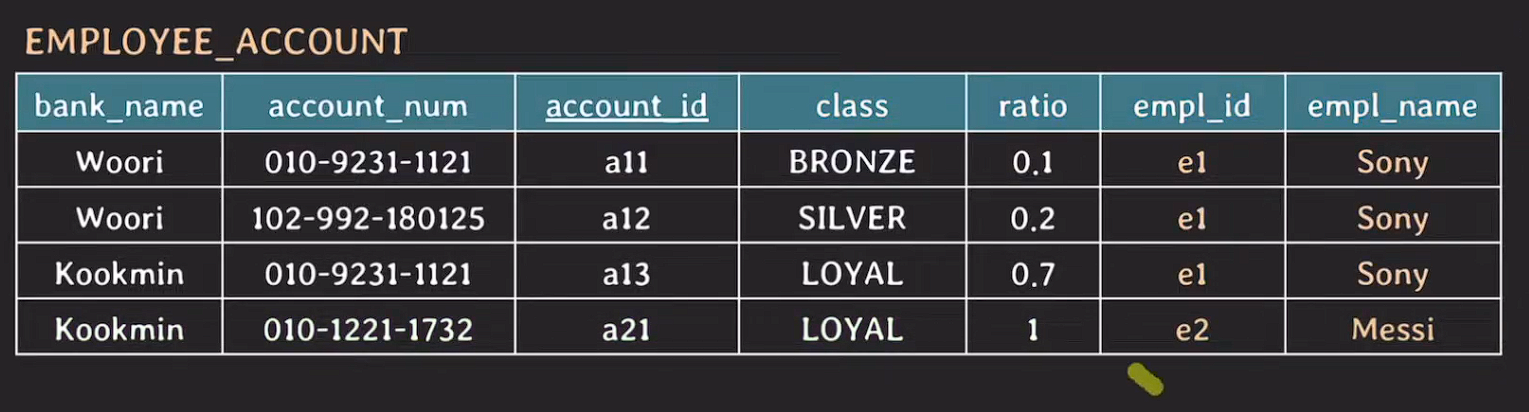
empl_id와 empl_name의 데이터 중복이 많은 상황 Sony에 대한 tuple이 3개 존재한다.

account_id도 empl_id을 결정할 수 있으며 empl_id가 empl_name을 결정할 수 있다.
{account_id} -> {empl_id}, {empl_id} -> {empl_name}
=> {account_id} -> {empl_name}

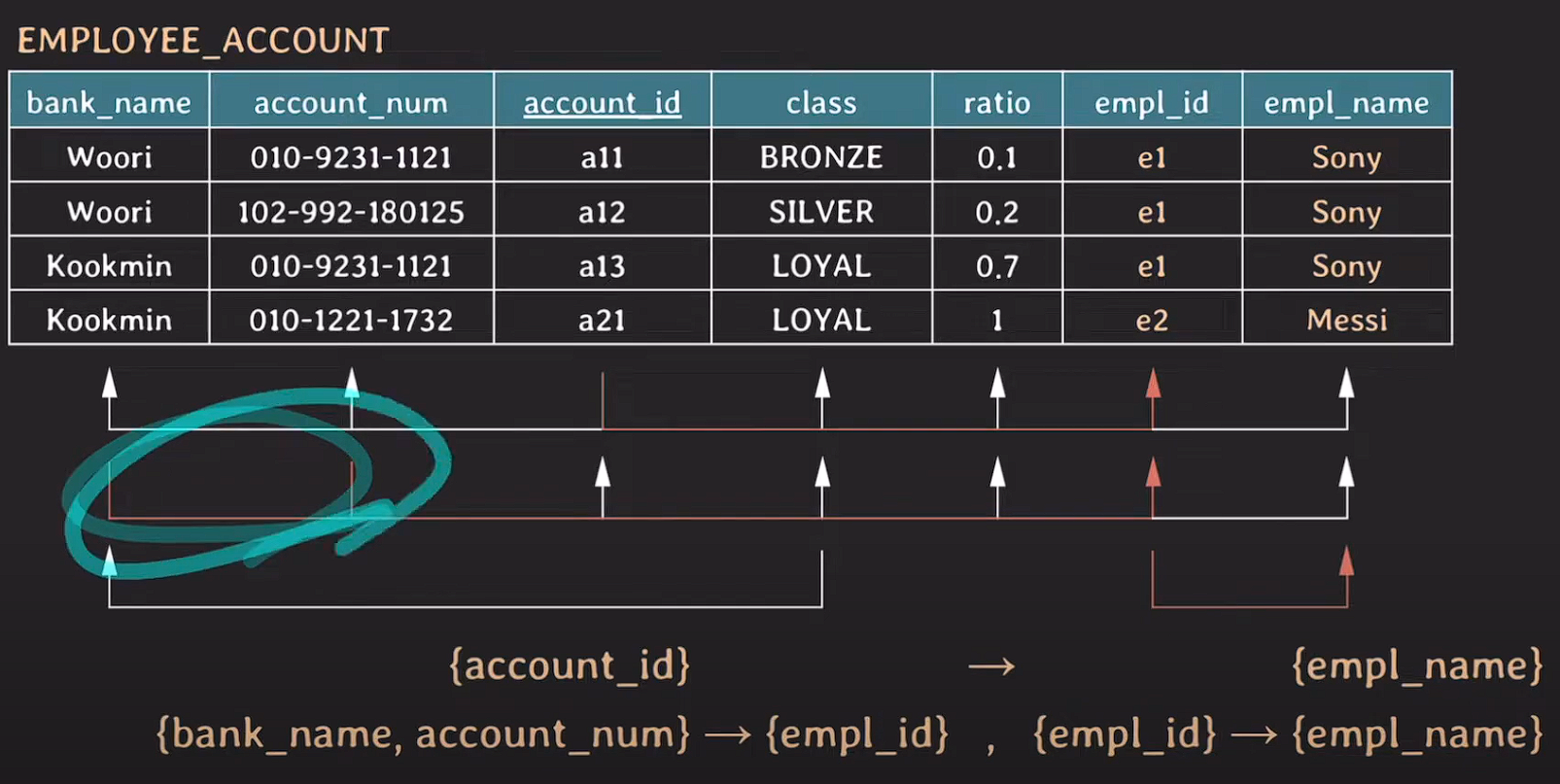
{bank_name, account_num} -> {empl_id}, {empl_id} -> {empl_name}

{account_id} -> {empl_name} // {bank_name, account_num} -> {empl_name}
transitive FD관계이다.

3NF : 모든 non-prime attribute는 어떤 key에도 transitively dependent 하면 안된다.
즉, transitive funtional dependency가 존재해서는 안된다.
non-prime attribute 들 사이에 FD가 존재해서는 안된다.

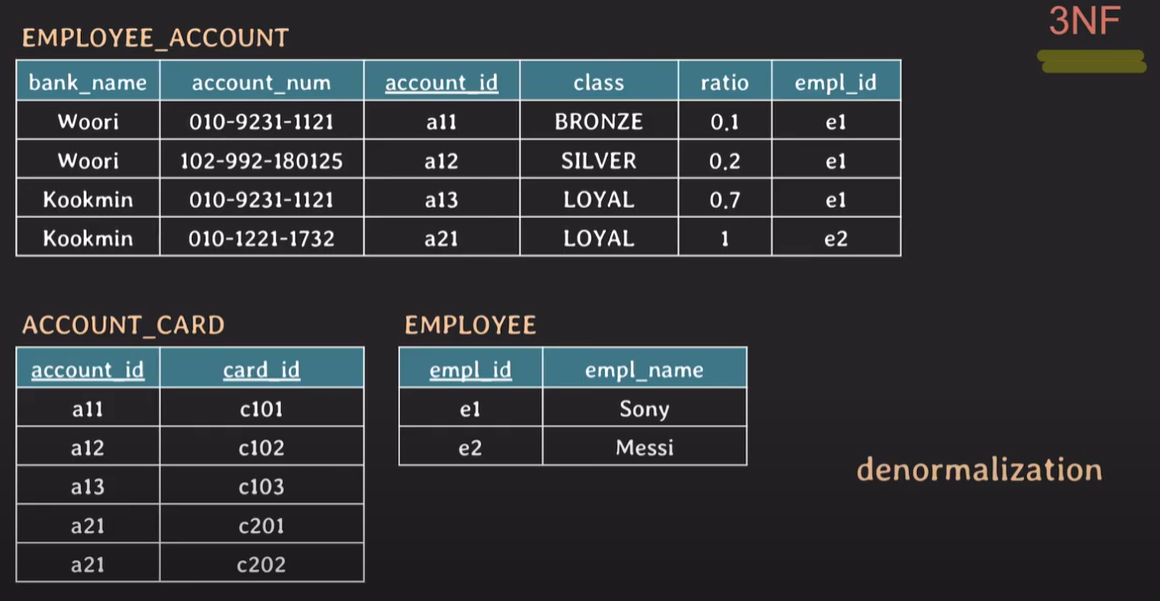
empl_id에 의해 empl_name이 결정되는 상황. non-prime attribute간 FD간 생긴 attribute들을 다른 테이블로 옮겨준다.


EMPLOYEE_ACCOUNT 테이블의 empl_id는 JOIN하기 위해 유지한다.
BCNF
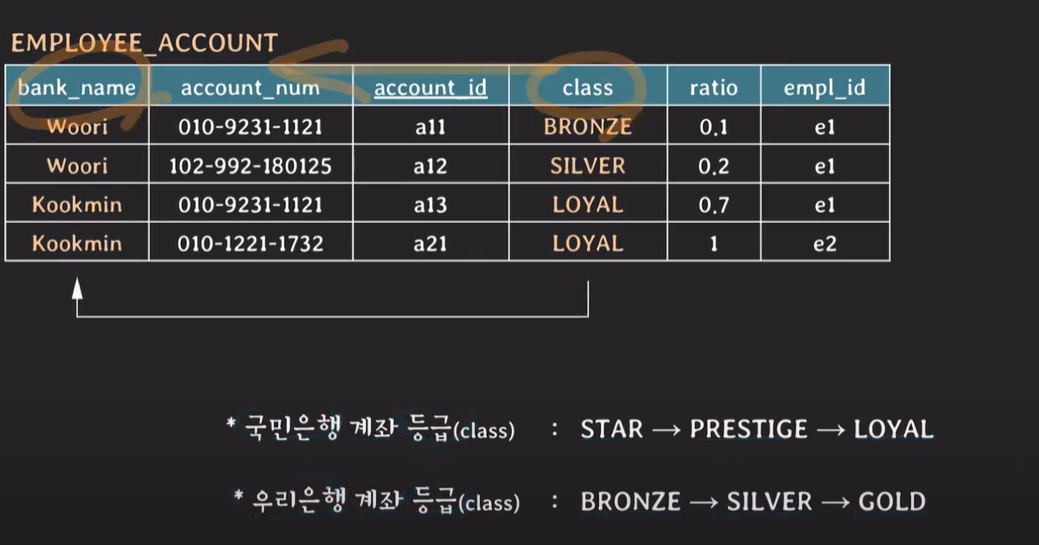
데이터가 계속해서 저장될 수록 bank_name과 class attribute에는 중복된 데이터가 쌓이게 된다.
class가 같으면 bank_name이 같고, class의 value를 파악하면 bank_name이 어떤것인지 파악가능하다.
class는 bank_name을 결정지을 수 있다. (FD) class가 같으면 bank_name이 같다.

BCNF : 모든 유효한 non-trivial FD X -> Y는 X가 super key여야 한다.
bank_name은 class에 의존적이지만, class는 super key가 아니다!
class만으로 tuple을 unique하게 식별할 수 없다.
* non-trivial funtional dependency : X -> Y가 유효하지만, Y는 X의 부분집합이 아닌 경우
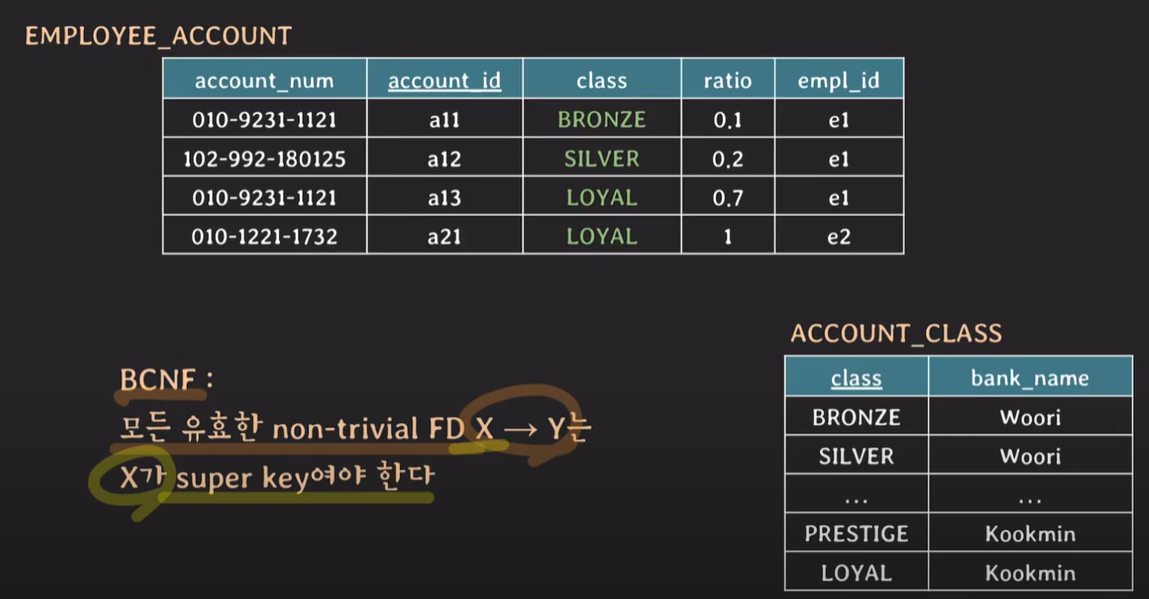

2NF 참고사항

2NF는 key가 composite key가 아니라면 2NF는 자동적으로 만족하는가?
composite key : Primary Key가 2개이상의 attribute로 구성되는 key
대부분 composite key가 아닌경우 2NF를 만족하지만 항상 만족하는것은 아니다.
Denormalization
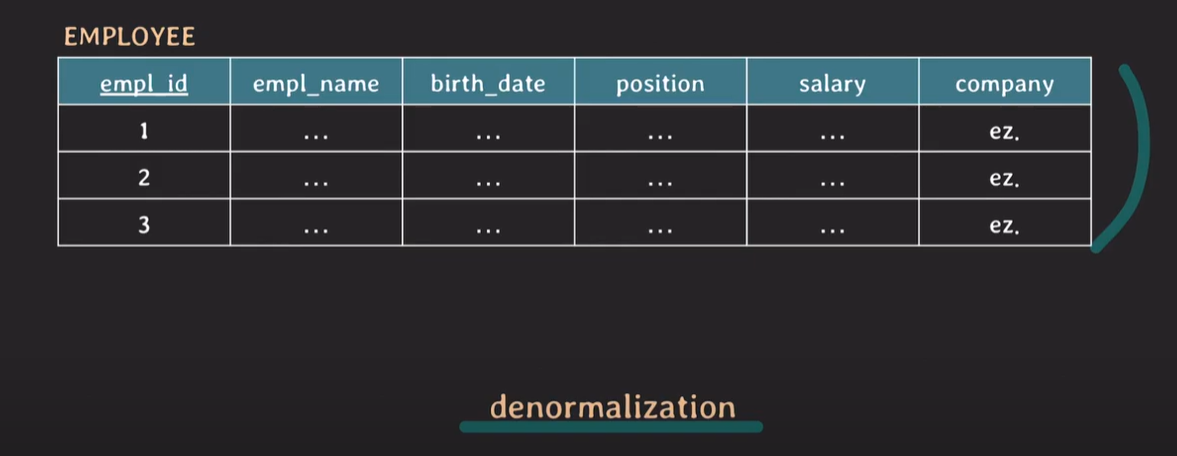
반 정규화, 정규화 과정에서 너무 많은 table로 나뉘게 되면 관리가 어려워지고, table join에서 성능저하이슈가 발생될 가능성이 존재한다.

항상 정규화를 지켜주는것이 최선이 아니다.
정리
1NF : 각 attribute들의 속성값은 더이상 나눌 수 없는 상태여야한다.
2NF : 모든 non-prime attribute는 모든 key에 fully functionally dependent 해야한다.
3NF : 모든 non-prime attribute는 어떤 key에도 transitively dependent 하면 안된다. 즉, transitive funtional dependency가 존재해서는 안된다. non-prime attribute와 non-prime attribute 사이에 FD가 존재해서는 안된다.
BCNF : 모든 유효한 non-trivial FD X -> Y는 X가 super key여야 한다.
