Index

Index가 중요한 이유
Index가 없다면
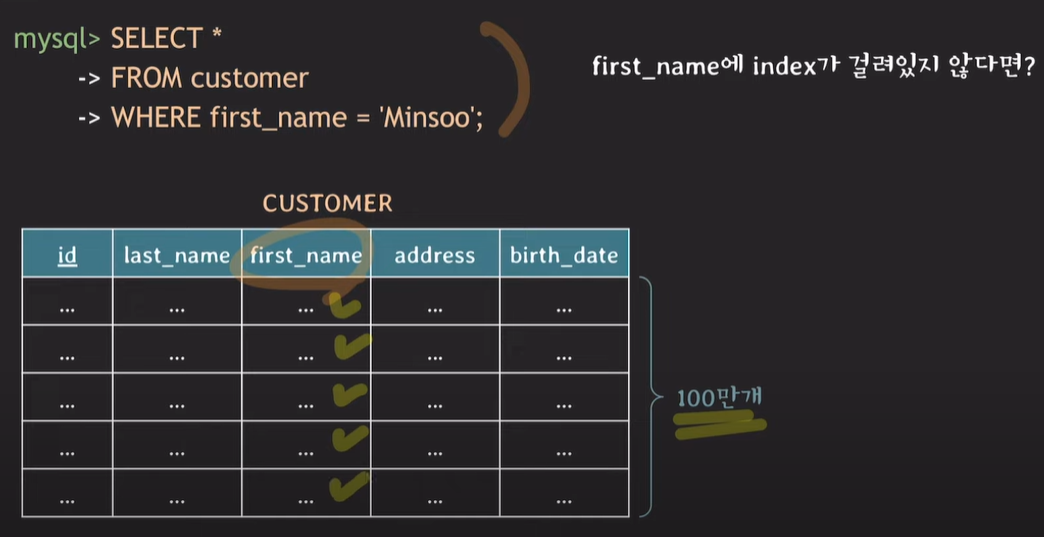
데이터베이스에서 select 쿼리 조회시 where절에 column에 index가 설정되어있지 않다면, 데이터베이스는 tuple을 처음부터 끝까지 전부 하나씩 읽는다.
이러한 행위를 full scan(=table)이라 하며 시간복잡도는 O(N)
Index가 있다면

where절에 작성한 column에 인덱스가 설정되어 있다면 시간 복잡도 O(logN), full scan보다 더 빨리 찾을 수 있다.
Index를 사용하는 이유

- 조건을 만족하는 튜플(들)을 빠르게 조회하기 위해
- 빠르게 정렬(order by)하거나 그룹핑(group by) 하기 위해
Index 생성
테이블 생성 후 인덱스 설정
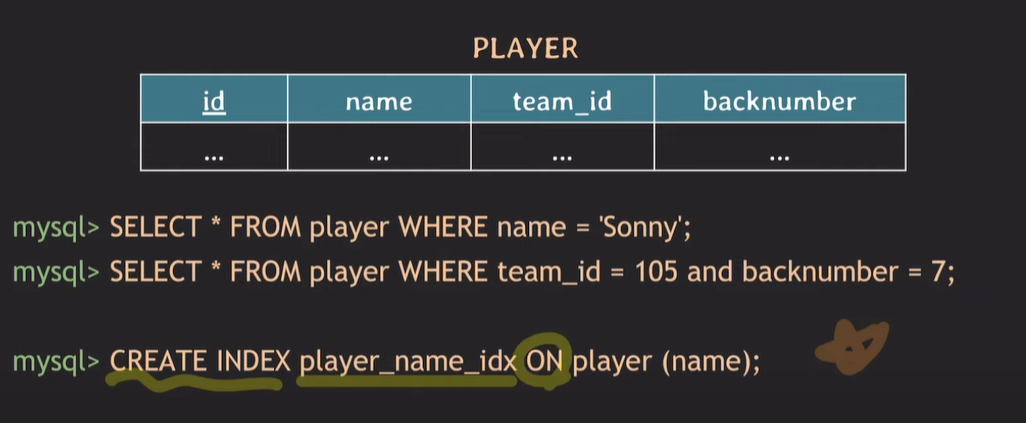
CREATE INDEX 인덱스명 ON 테이블명 (attribute 명)
-> CREATE INDEX player_name_idx ON player (name)
-> CREATE UNIQUE INDEX player_id_backnumber_idx ON player (team_id, backnumber)
UNIQUE INDEX : 인덱스로 설정한 attribute에 의해 tuple이 고유하게 존재한다. unique하게 식별할 수 있다.
name은 동명이인이 존재하여 Unique index가 불가능하지만, (team_id, backnumber)는 tuple이 unique하게 존재한다.
테이블 생성 시 인덱스 설정
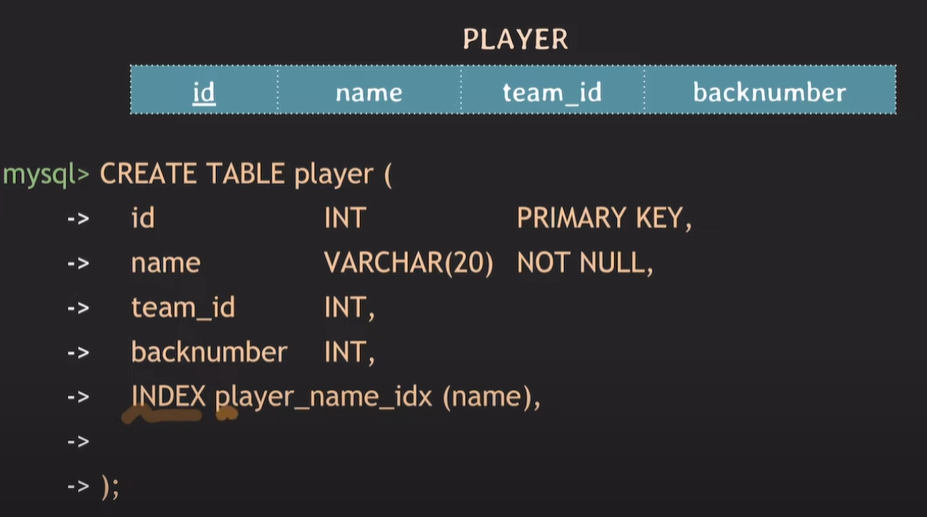
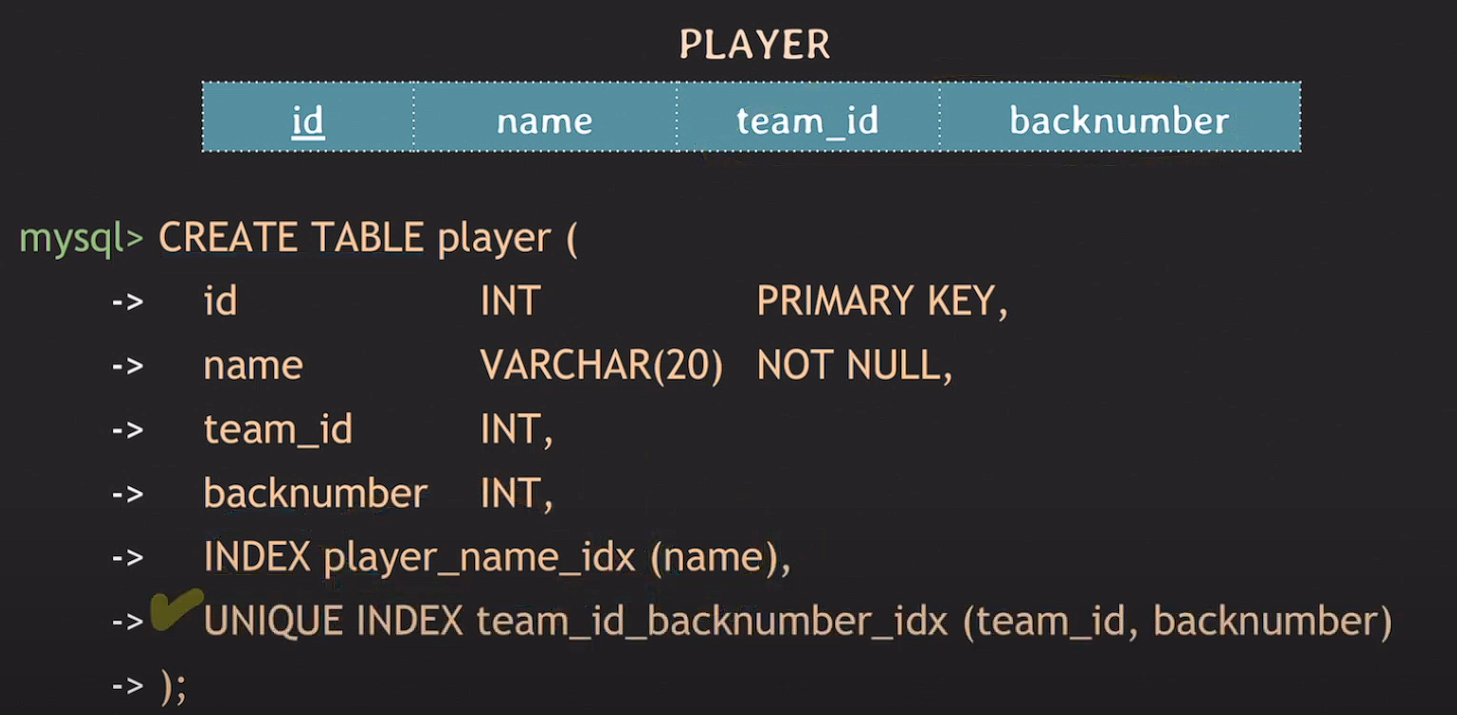
CREATE TABLE 테이블명 (
...
INDEX 인덱스명 (attribute),
UNIQUE INDEX 인덱스명 (id, backnumber) -- composite index, multicolumn index라 한다.
);
대부분의 RDBMS에서는 primary key를 생성할 경우 index가 자동 생성된다.
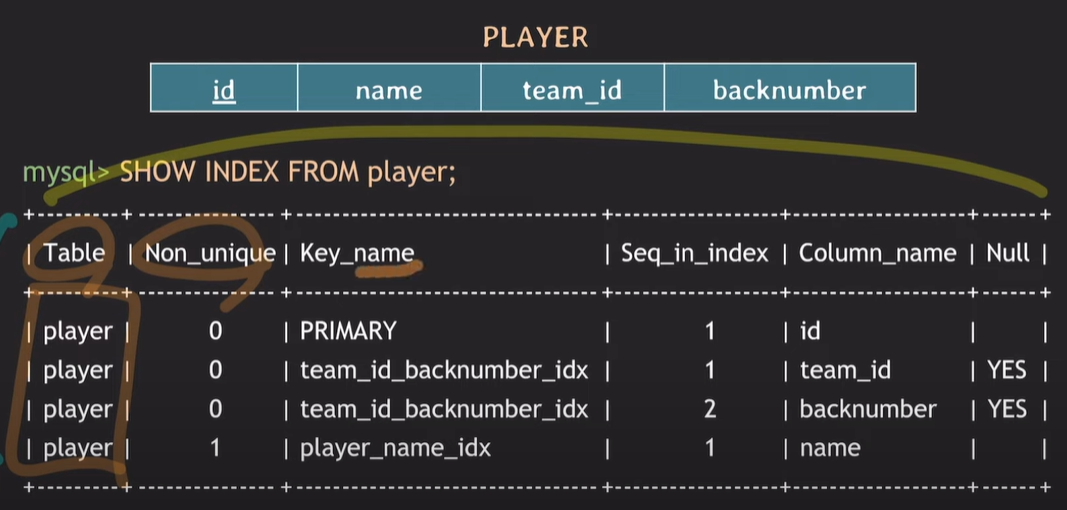
SHOW INDEX FROM 테이블명;
-- 테이블에 설정된 INDEX를 파악할 수 있다.INDEX 동작 방식(B-tree)

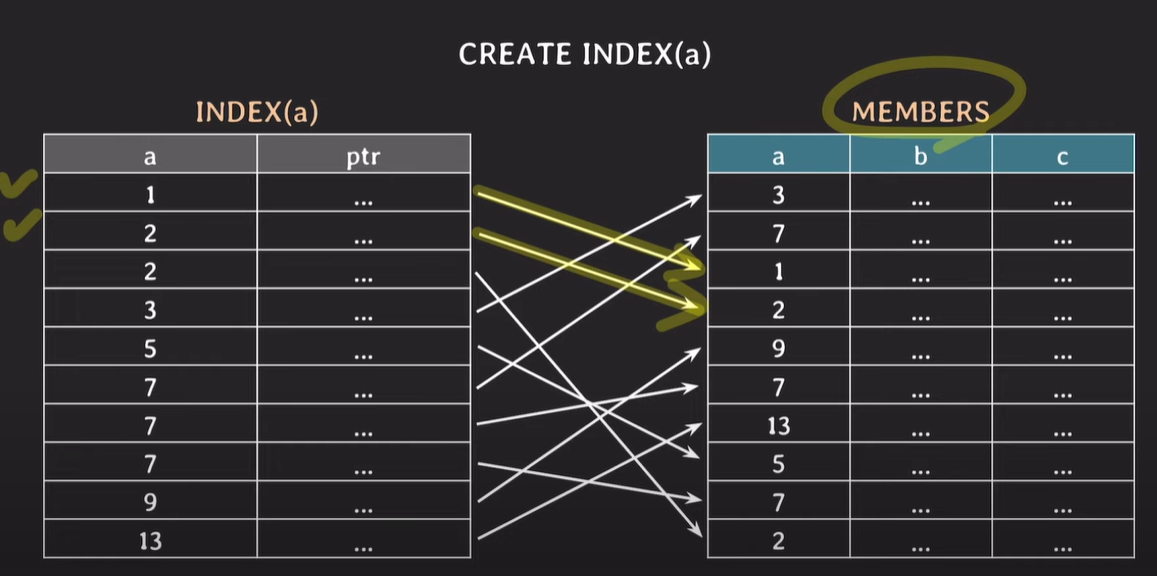
index로 설정된 값들이 B-tree 구조로 정렬되어 있으며, 값과 Member 테이블의 튜플에 대한 포인터를 가지고 있다.
binary search (예제)
예제1
where 조건에 해당하는 값이 1개인 경우
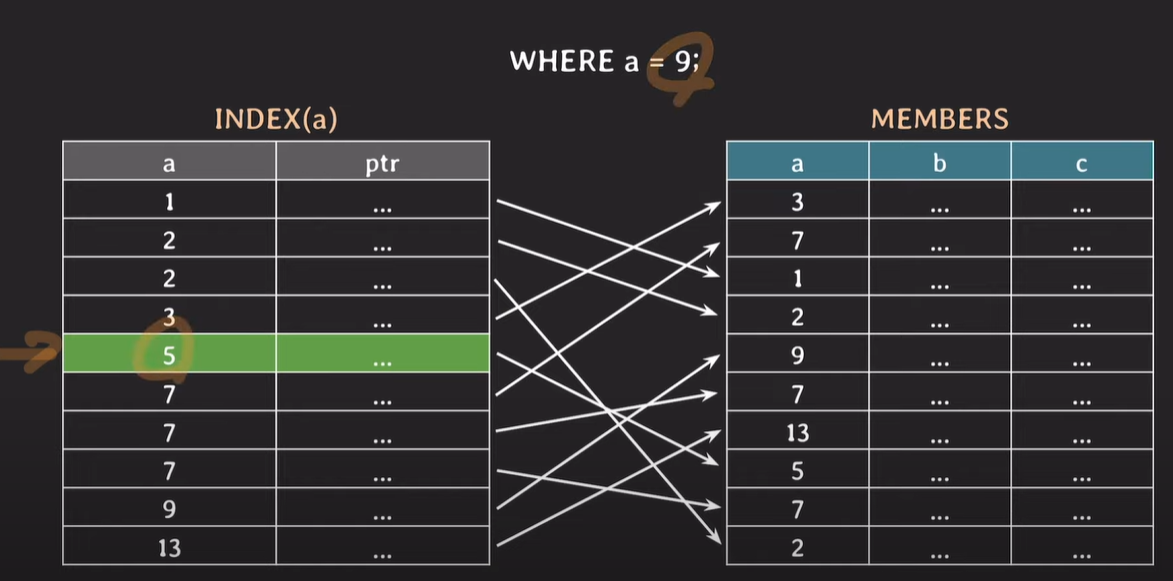
Index로 설정되어있는 attribute는 정렬되어있기 때문에 binary search(이진탐색)으로 index를 확인한다.
조건을 만족하는 index를 찾았다 해서 끝이나는게 아닌, 이진탐색을 계속 실행하여 조건을 만족하는 값을 찾고, 조건에 만족하는 값이 없으면 이진탐색을 멈춘다.
예제2
where 조건에 해당하는 값이 여러개인 경우
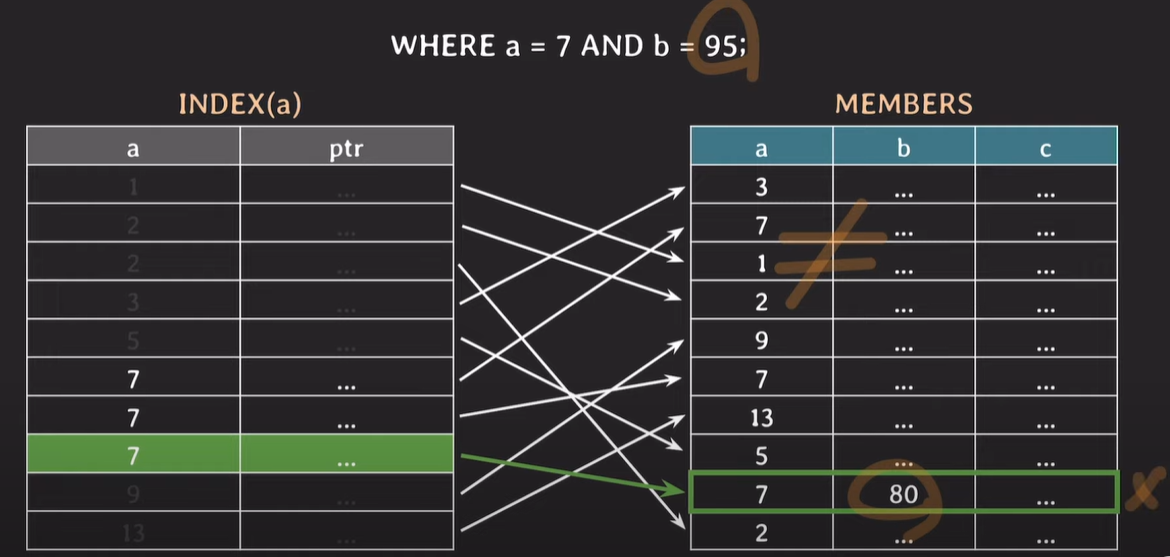
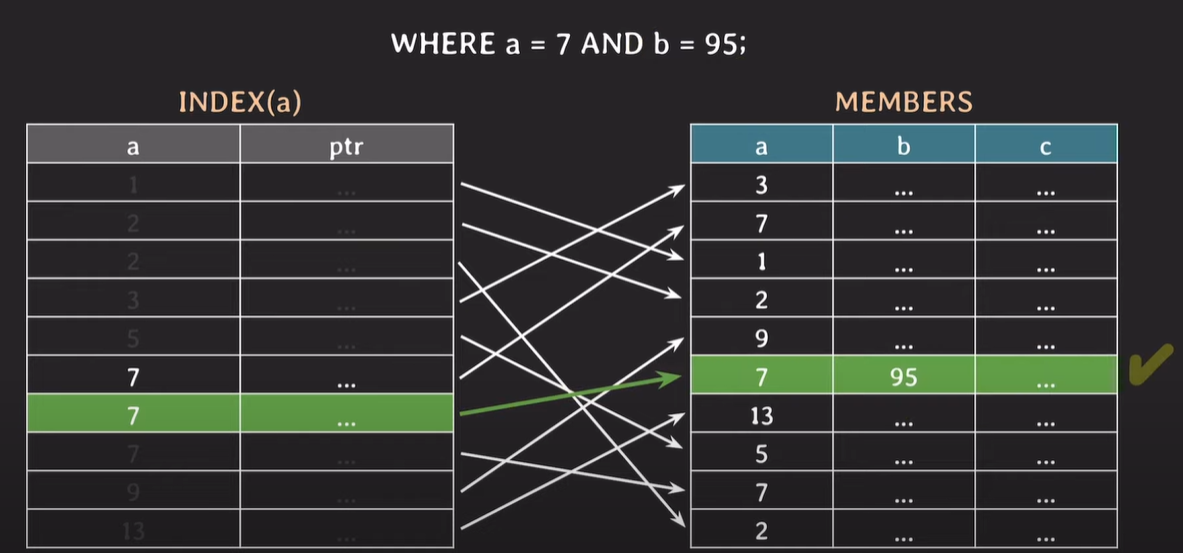
index로 설정된(a) attribute에서 조건을 만족하는값을 찾은 후 pointer를 이용하여 b의 값을 확인하고, 이진탐색으로 a의 값을 만족하는것이 있는지 계속해서 확인한다.
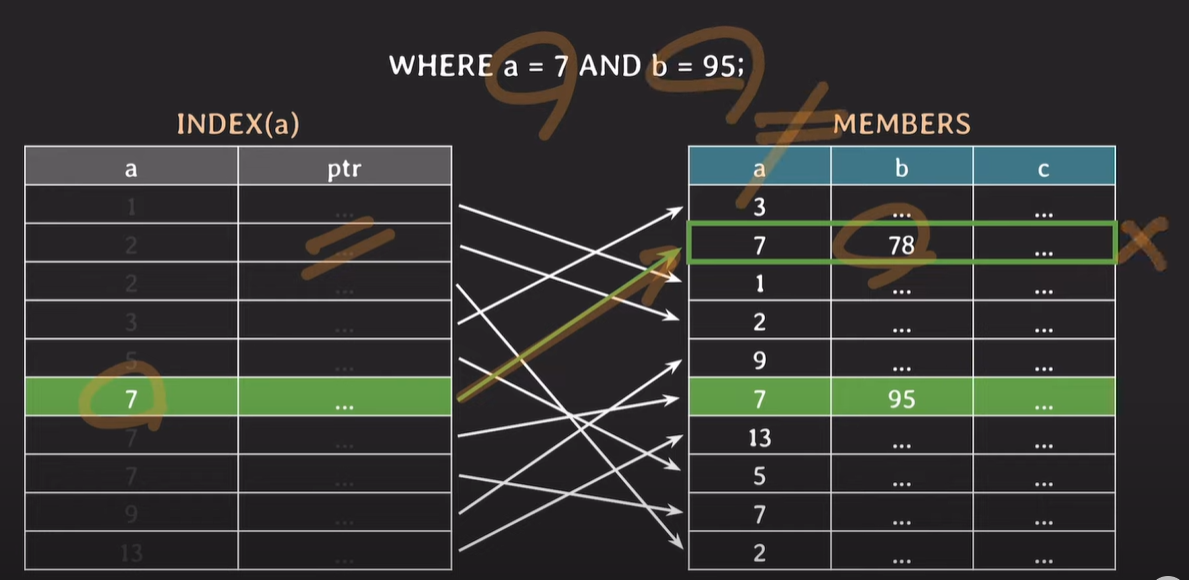
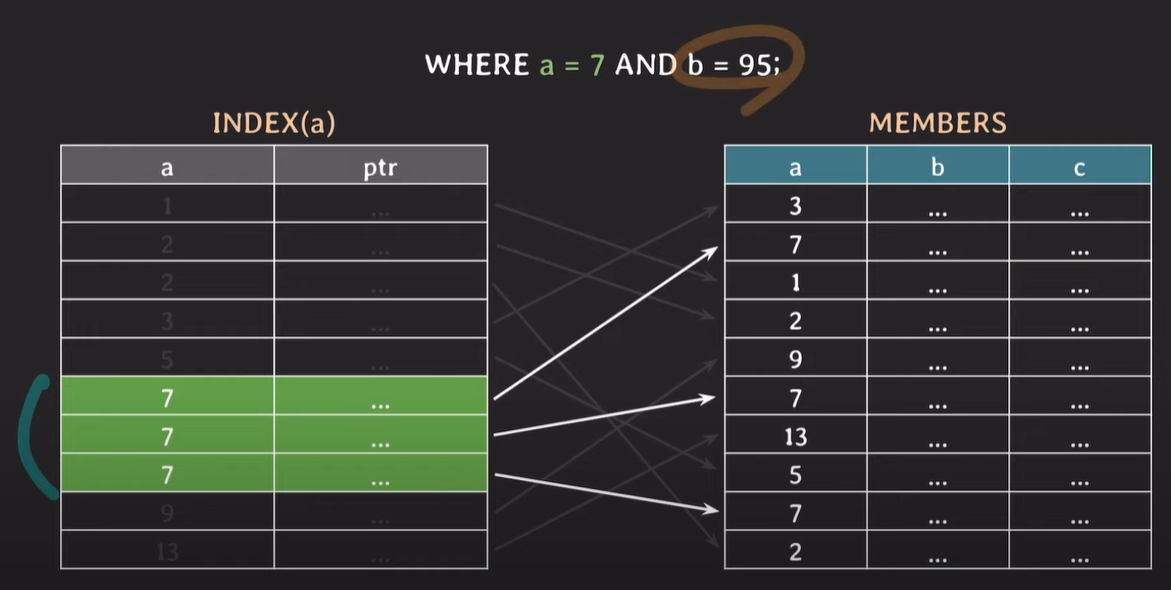
a에만 index 설정되어있기 때문에 조건을 만족하는 a는 빠르게 찾을 수 있지만, b는 정렬 및 index가 설정 되어있지 않기 때문에 b의값을 조회 하는것이 오래걸린다. 즉, b의 값을 찾을때 full scan이 발생한다.
예제3
Index로 a,b를 동시에 사용하는 경우

a의 값이 정렬된 후 b의 값이 정렬된다. (두 INDEX 모두 정렬되어있다.)
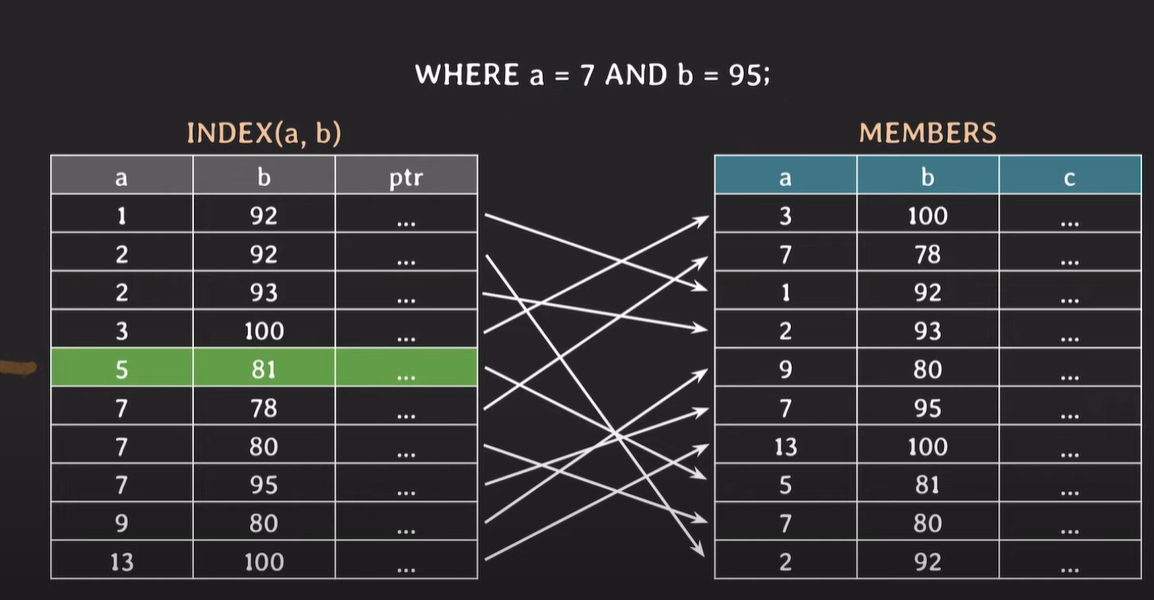
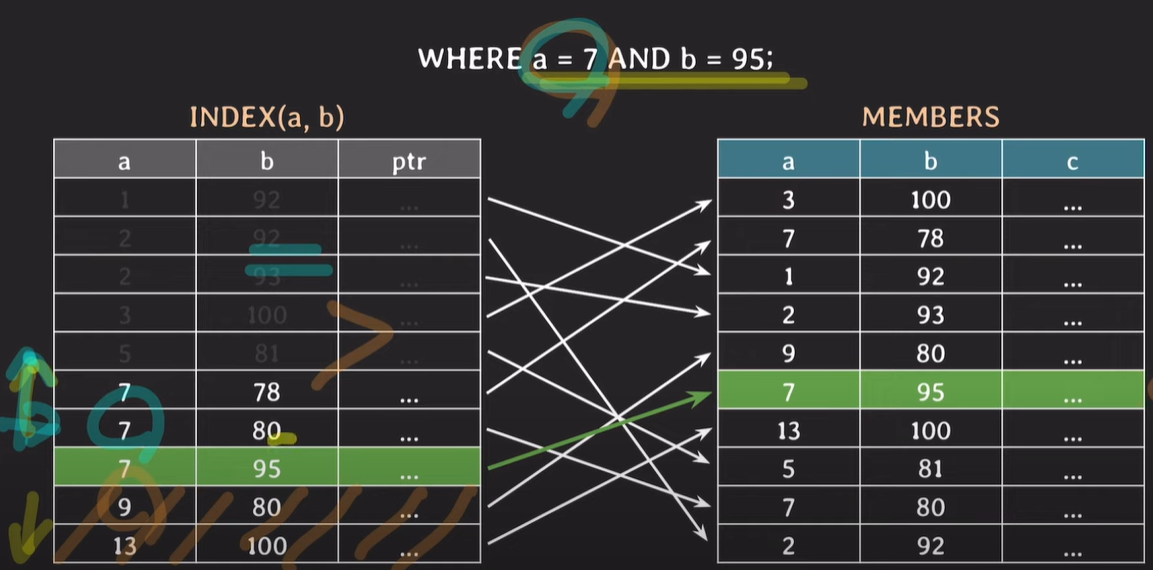
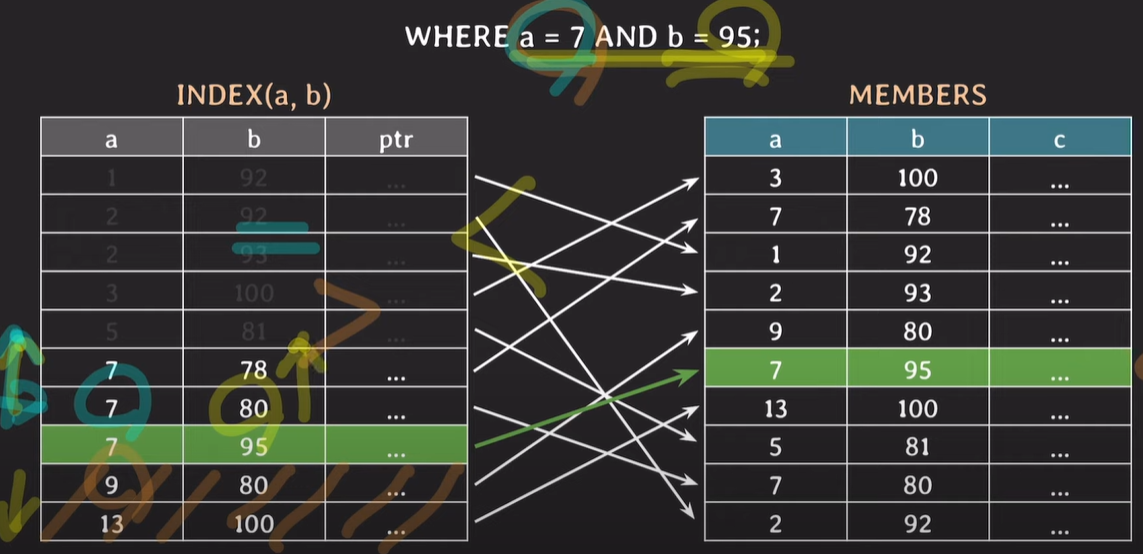
a를 이진탐색한 후, b에 대해 이진탐색을 실행한다. a와 b를 둘다 모두 이진탐색하기 때문에 조회 성능이 향상된다. a,b 모두 정렬이 되어있기 때문에 a에 대해 조건을 검색하는 과정에서 이진탐색을 하여 불필요한 부분은 조회하지 않고, b에 대해서도 이진탐색하여 불필요한 부분은 조회하지 않는다.
★★★★★ 예제4
Index로 a,b가 설정되어있지만, b로 검색하는경우
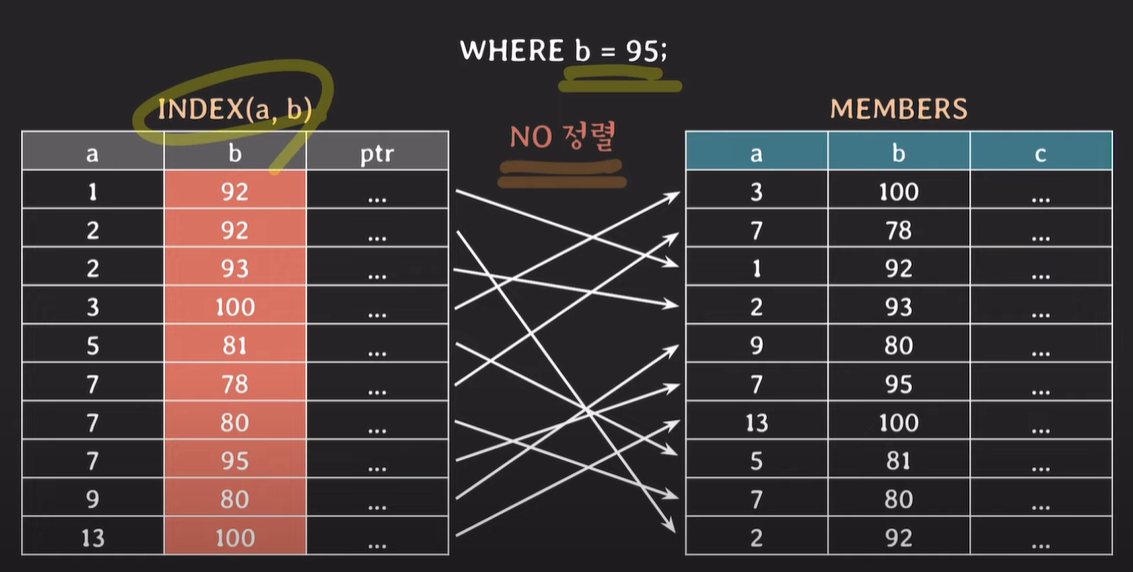
우선, 성능이 마음에 들게 나오지 않는다.
a에 대해 우선정렬이 되어있기 때문에, b에 대해서는 정확하게 정렬이 되어있지 않다. 때문에 인덱스를 사용하지 않거나 성능이 보장되지 않는다.
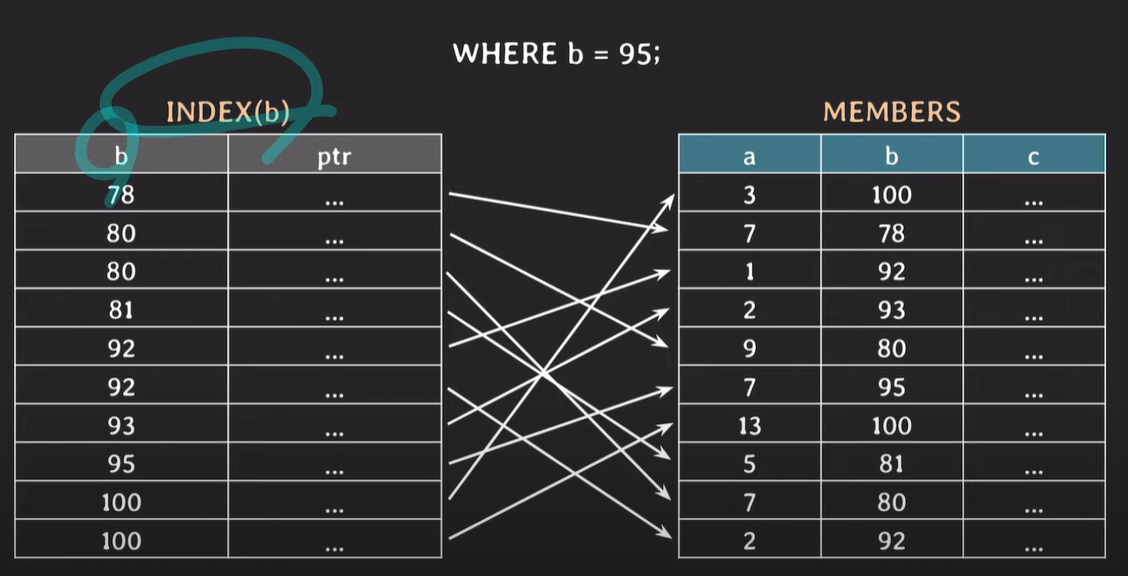
b에 대해서만 따로 index를 설정하여 두는것이 좋다.
★★★★★ 예제5
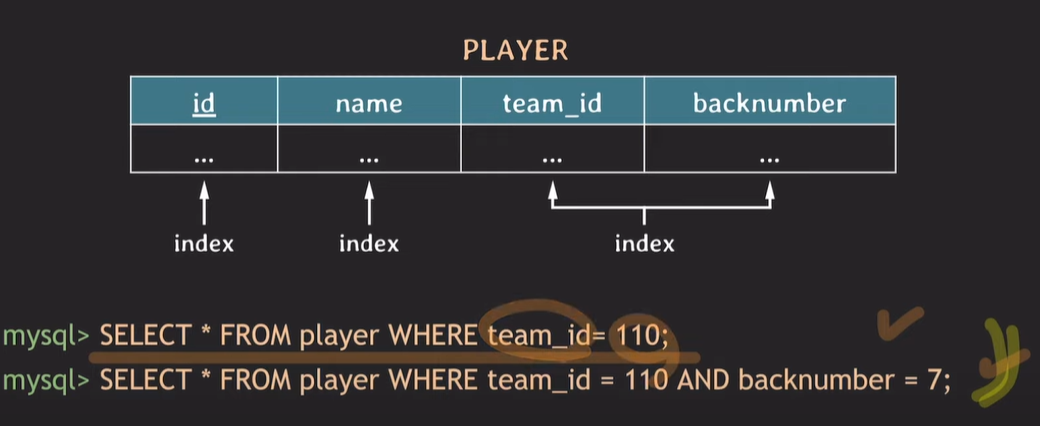
1번 쿼리, 2번 쿼리 모두 team_id가 우선 정렬되어있기 때문에 조회성능이 높다.
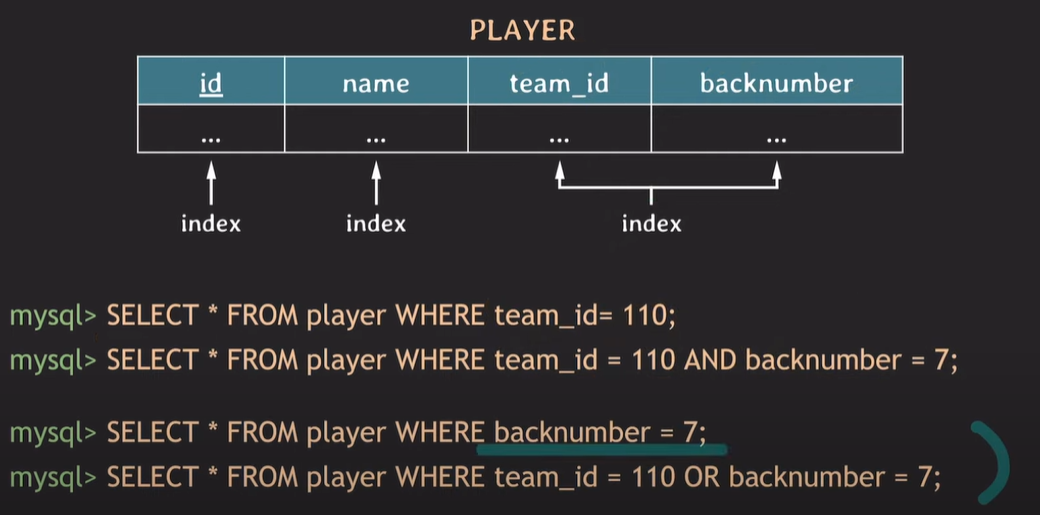
하지만, 3번 쿼리 같은 경우 backnumber에 대해서는 후 순위로 정렬되어있기 때문에 성능이 보장되지 않는다.
4번 쿼리의 경우 조건에 OR가 존재하기 때문에, team_id에 대해서는 binary search를 하지만, backnumber의 경우 모든 경우의 수를 생각한다 때문에 결국 full scan을 한다. 이럴 경우 backnumber에 대해서만 따로 INDEX를 설정해주는것이 좋다.
예제 정리
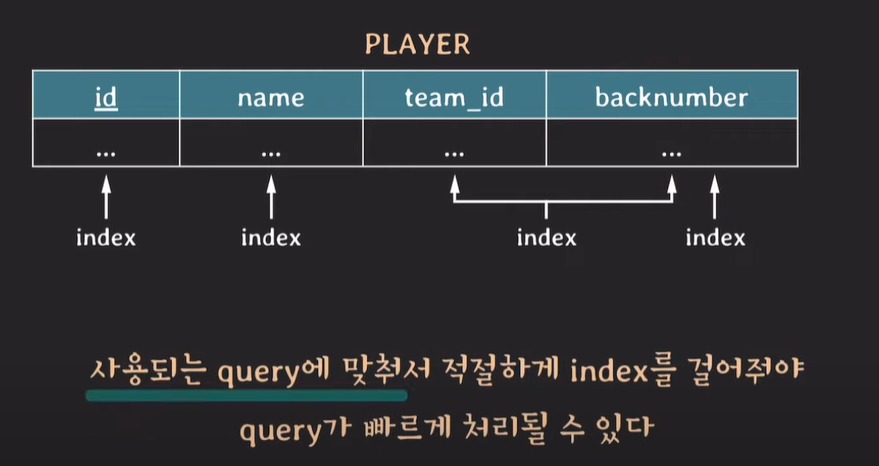
★사용되는 query에 맞게 적절한 index를 걸어줘야 빠른 조회성능을 갖출 수 있다.
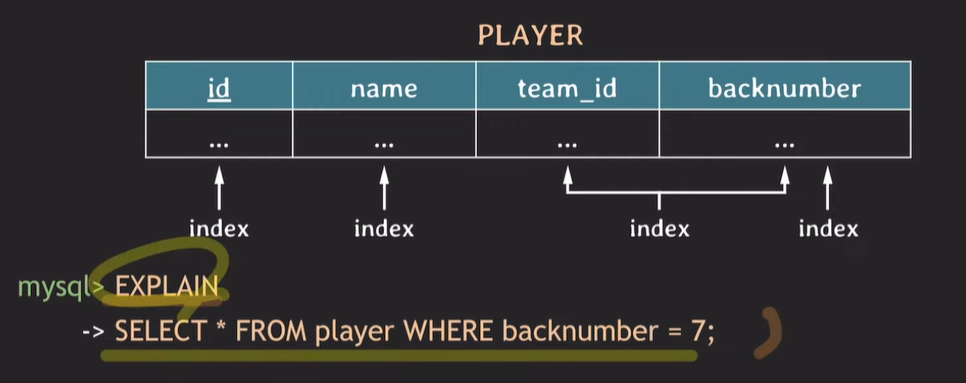
내가 작성한 쿼리가 어떻게 동작하는지 알고 싶은 경우
EXPLAIN (ANALYZE) select * from player where ...;RDBMS에서 해당 쿼리가 어떻게 동작하는지 보여준다. key에 작성된 내용이 해당 쿼리가 사용하는 인덱스를 실질적으로 보여준다.
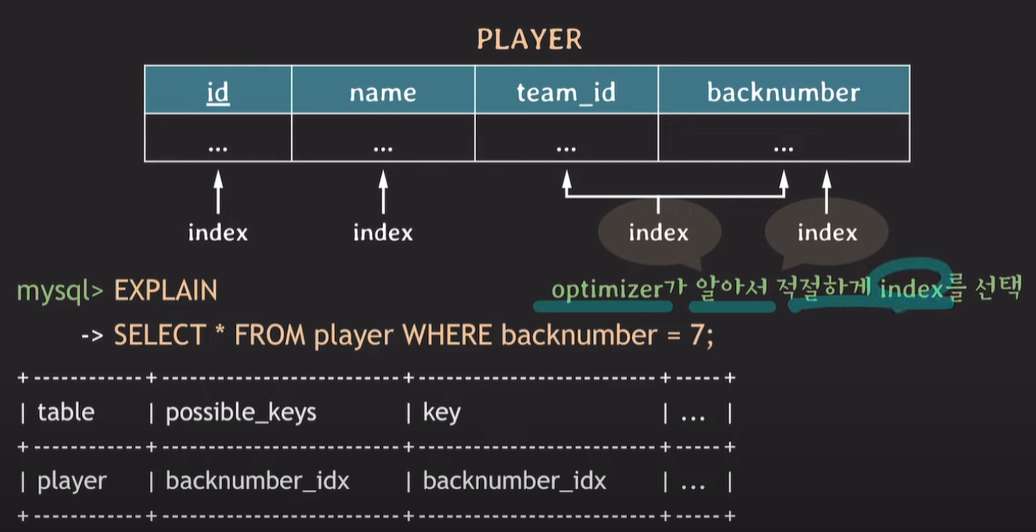
INDEX는 DBMS의 optimizer가 적절한 INDEX를 선택하여 조호한다.
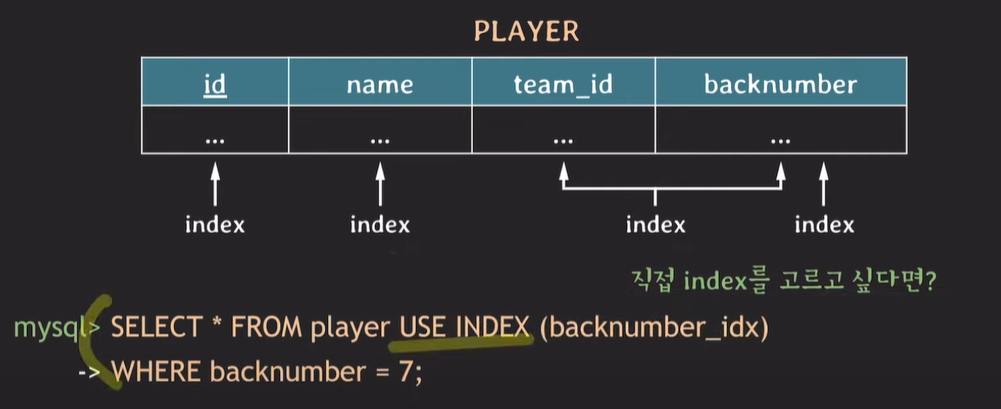
만약 EXPLAIN 후 optimizer가 적절한 index를 사용하지 않는경우 개발자가 직접 사용할 INDEX를 선택하는 방법
select * from player USE INDEX (인덱스명) where ...;
-- 권장사항느낌. 해당 인덱스를 사용해주세요
-- optimizer가 해당 인덱스를 사용하지 않을 수 도있다.
select * from player FORCE INDEX (인덱스명) where ...;
-- 무조건 해당 인덱스를 사용해라.주의사항
데이터 추가 변경
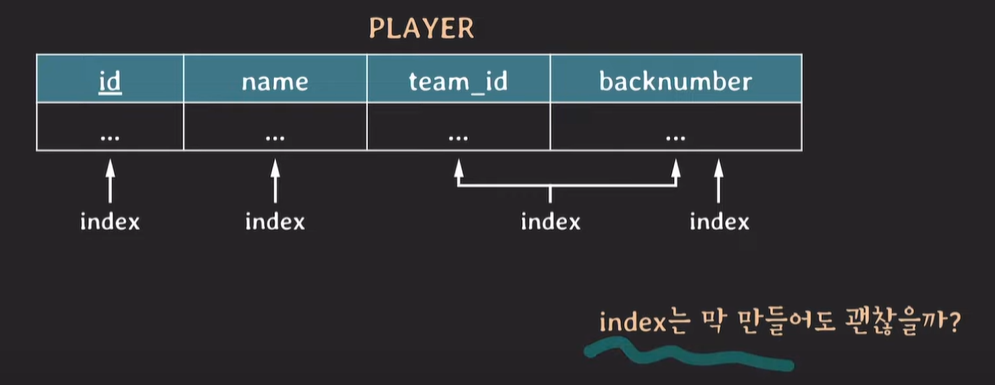
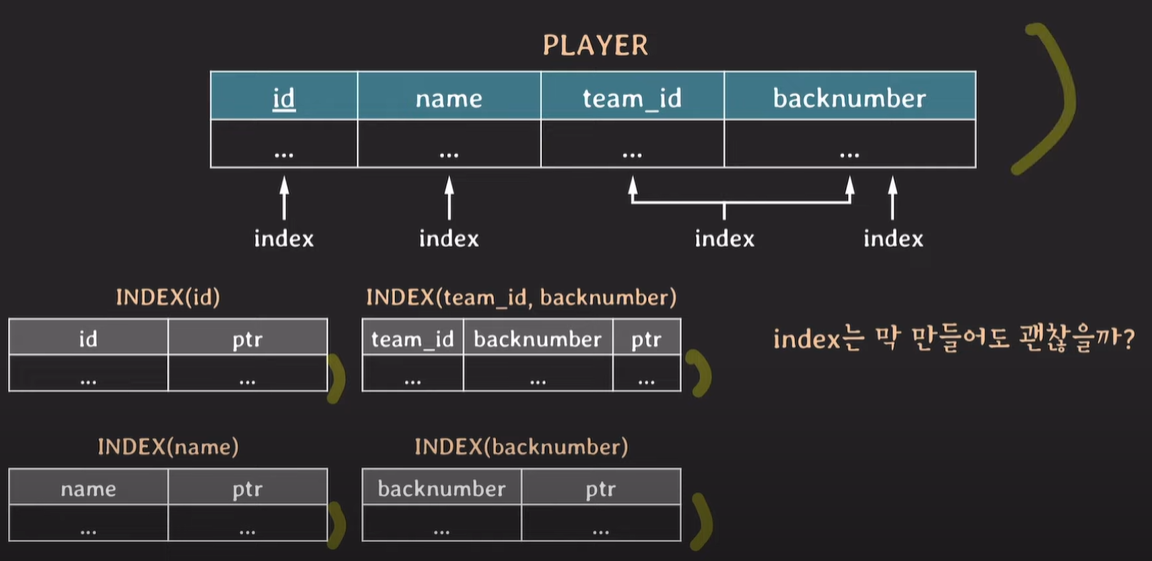
index가 4개 존재하는 경우 table에 데이터는 1개 이지만, 각각의 인덱스가 table의 데이터들을 가지고 있다.

데이터 write (insert, delete, update)가 발생하면 index에 변경이 발생한다.
추가적인 데이터 저장 공간이 필요하다.
full scan이 더 좋은 경우

- table에 데이터가 별로 존재하지 않는 경우
- 만약 tuple 100만개중 99만개가 해당 조건에 만족하는경우. 대부분의 데이터가 조건에 만족하는경우 full scan이 더 좋을 것이다.
그 외

MySQL의 경우 테이블을 생성할 때 foreign key를 설정하면 index가 설정되지만, 다른 RDBMS는 확인이 필요하다.
JOIN으로 사용되는 column에 대해 INDEX 확인 및 필요할 경우 INDEX를 설정하여 성능을 높일 수 있다.
이미 데이터가 수백만건인 테이블에 인덱스를 설정하면, 인덱스 생성과정에서 시간이 오래 걸릴 수 있다.

Covering INDEX
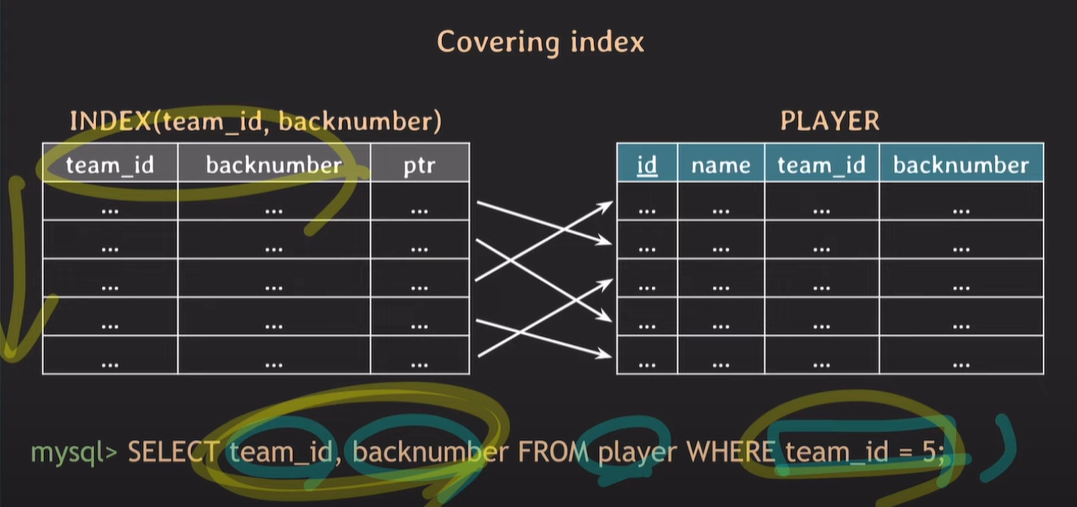
index로 설정되어있는 data가 select문에 의해 조회가 일어날 때, index에 존재하는 data만 사용하면되고, 굳이 포인터를 이용하여 table에 존재하는 data를 read하지 않아도 된다.
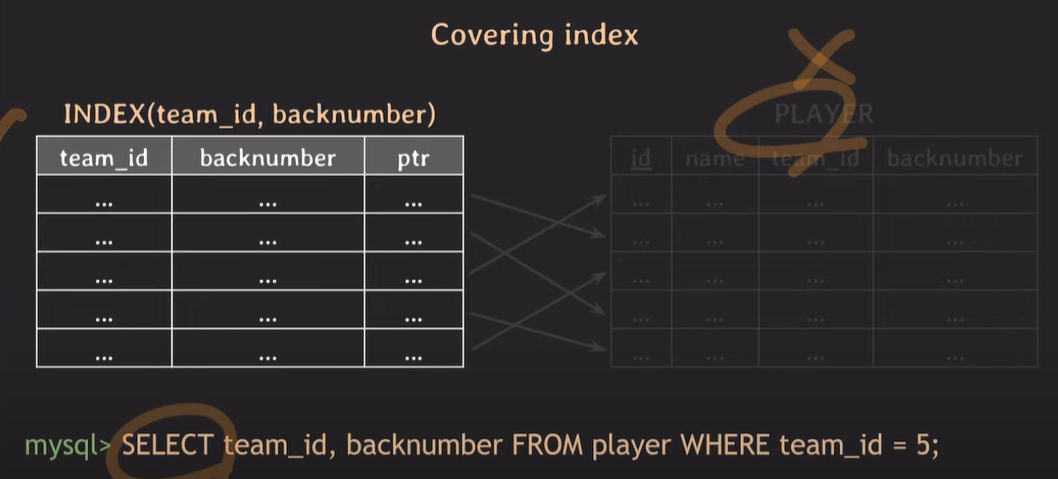

조회하는 attribute를 index가 모두 cover할 때 covering index라 하며 조회 성능이 더 빠르다.
