Partitioning, Sharding, Replication
Partitioning

Partitioning : database table을 더 작은 table들로 나누는것

vertical partitioning : column을 기준으로 table을 나누는 방식
horizontal partitioning : row을 기준으로 table을 나누는 방식
vertical partitioning
정의

column을 기준으로 table을 나눈다. 정규화도 vertical partitioning 중 하나이다.
예시
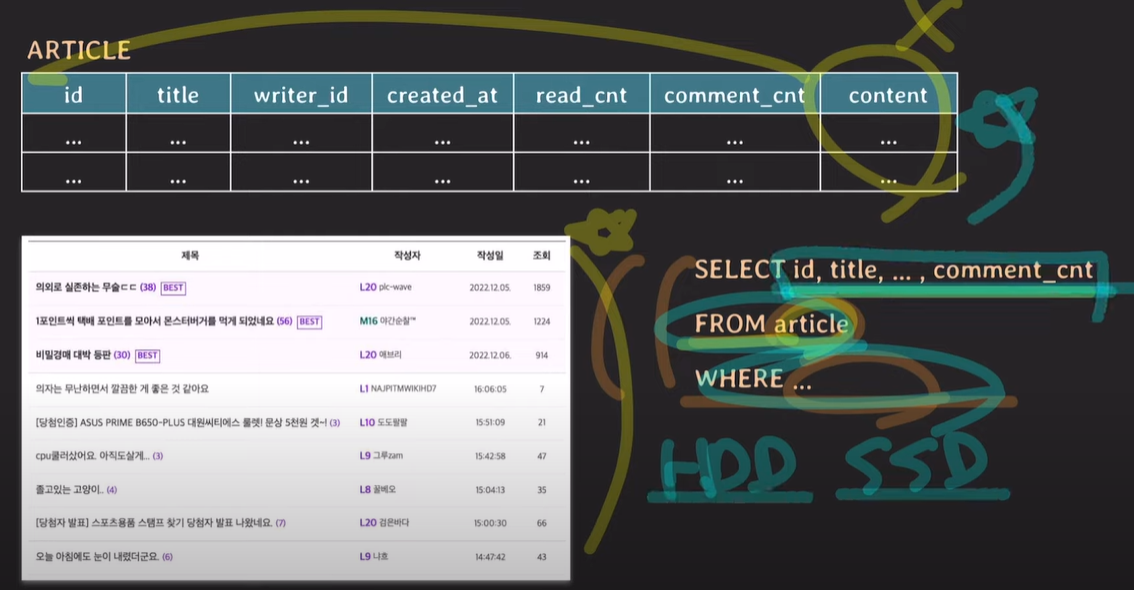
쿼리를 실행하고 where 조건절에 만족하는 데이터들을 read해올 때, HDD 또는 SSD에서 조건에 만족하는 데이터들(row)을 전부 가져온 후 select절에 존재하는 attribute만으로 tuple을 구성하는것이다.
content는 tuple을 구성하지 않지만, 일단은 저장장치에서 tuple들을 전부 가져온 후 제외시킨다. 만약, content의 크기는 대부분 사이즈가 클 수 있다. 사용하지 않지만, 저장장치에서 read후 메모리에 올리고 화면으로 보여준다. (I/O에 대한 부담이 커진다.)
적용
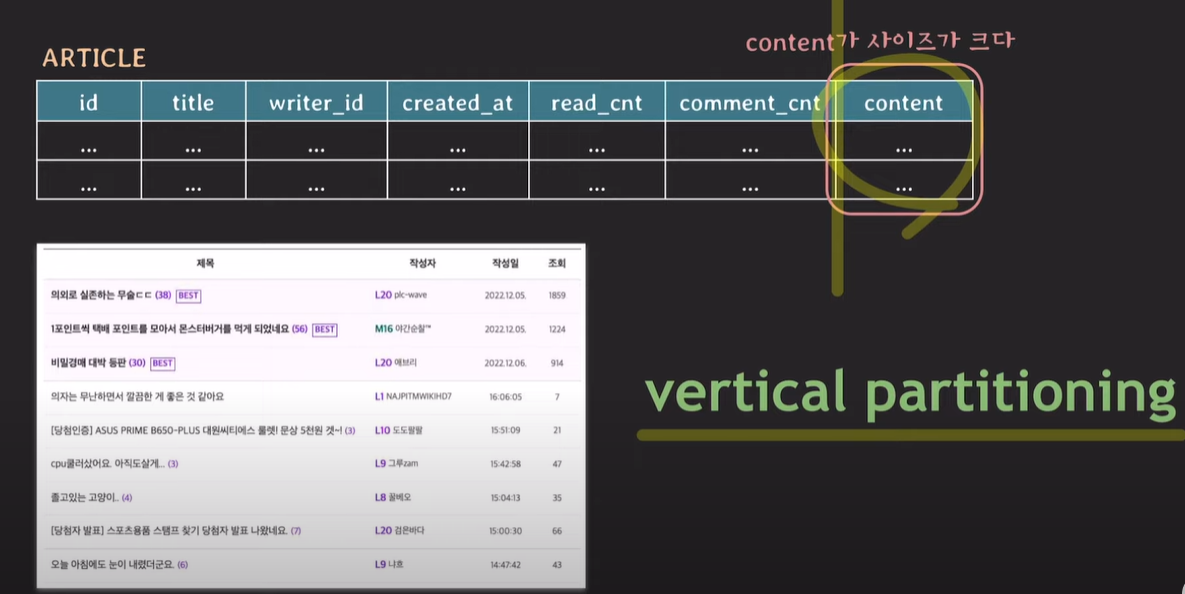
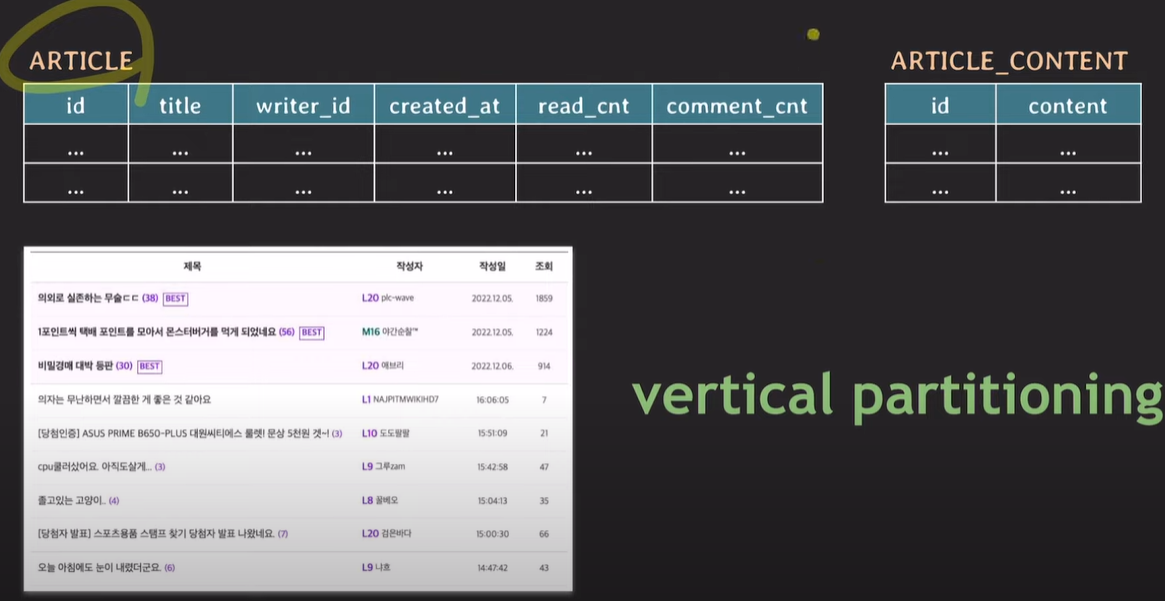
content를 기존 table에서 분리 후 id와 content만 존재하는 table을 새로 생성한다.
글 목록 페이지에서는 Article table만 select하면 되기 때문에 I/O의 부담이 적어지고, 성능도 빨리진다.
이처럼 정규화를 마친 테이블에서도 성능 향상을 위해 vertical partitioning을 수행할 수 있다.
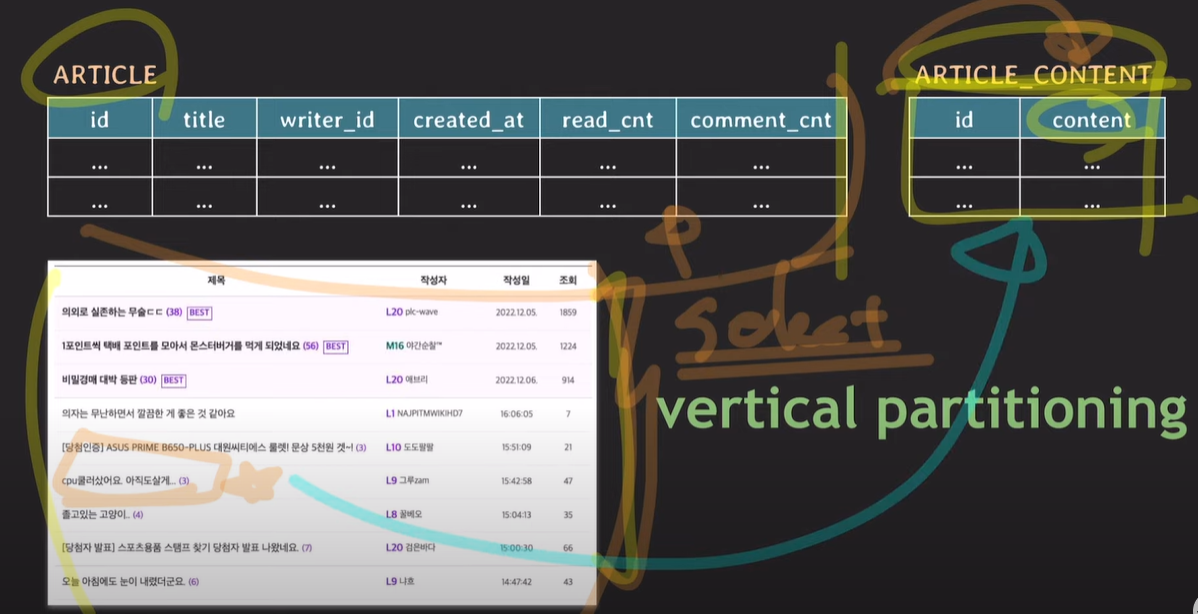
글 목록이 보일 경우 article_content table을 조회하지 않아도 되고, 글 상세보기에 들어가면 join을 통해 글 관련 정보를 한번에 읽어온다.
민감 정보, 자주 사용되는 데이터 - 자주 사용되지 않는 데이터 등 여러가지로 파티셔닝이 될 수 있고, join으로 데이터를 read
horizontal partitioning
정의 및 특징
horizontal partitioning : row를 기준으로 table을 나누는 방식. 특정 데이터, tuple을 기준으로 테이블을 분리한다.
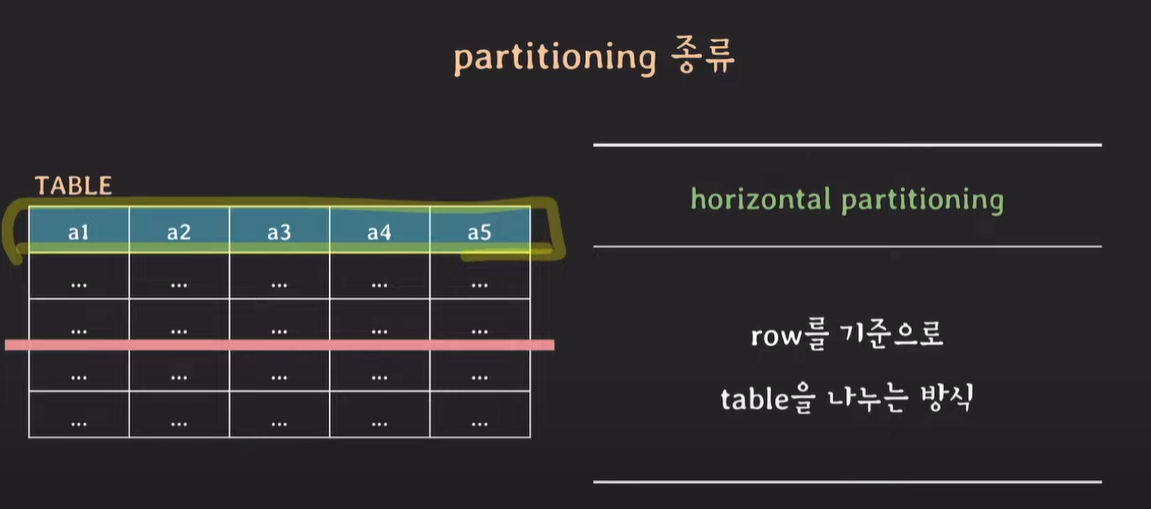
vertical partitioning과는 다르게 table schema는 유지된다.

유튜브 유저가 어떤 채널을 구독하는 경우
유저가 채널을 구독할때마다 tuple들이 생성된다.
즉, 데이터의 최대 갯수 유저 수 * 채널 수가 될 수있다.

테이블의 크기가 커질수록 인덱스의 크기도 커지며, 데이터 변경이 일어날때마다 인덱스도 변경되기 때문에 처리속도가 느려진다. 데이터가 적을 때 보다 데이터가 많은 경우 인덱스 조건을 찾기위해 search를 더 많이해야하고, write하게 될 때마다 인덱스 구조가 재조정된다.
hash-based horizontal partitioning

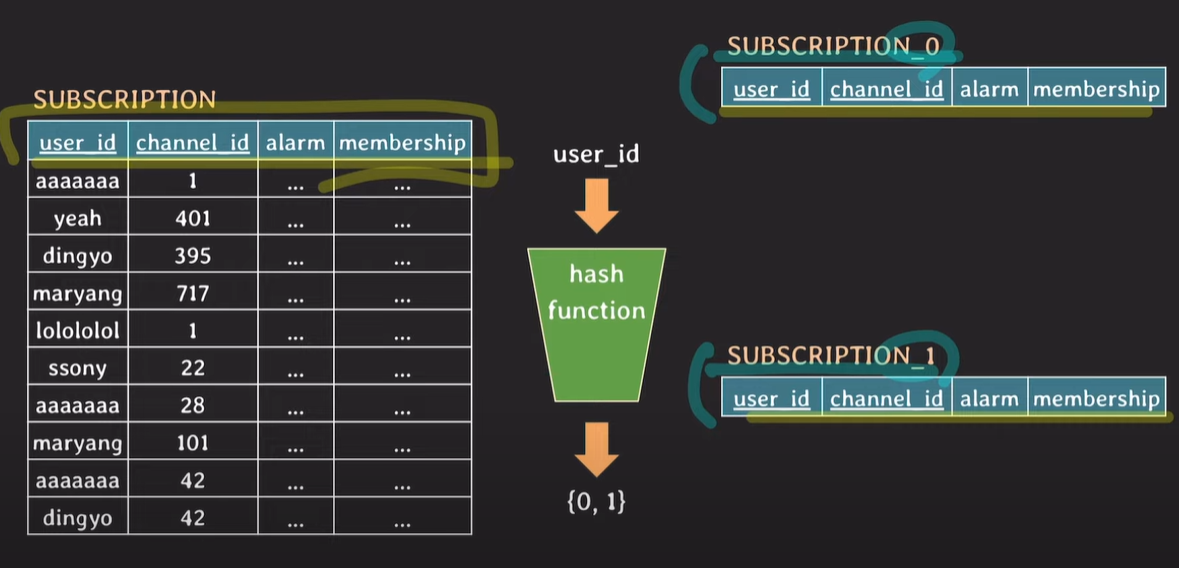
user_id를 hash function을 통해 값을 처리한 후 hash function의 결과값에 따라 저장되는 table이 달라진다.
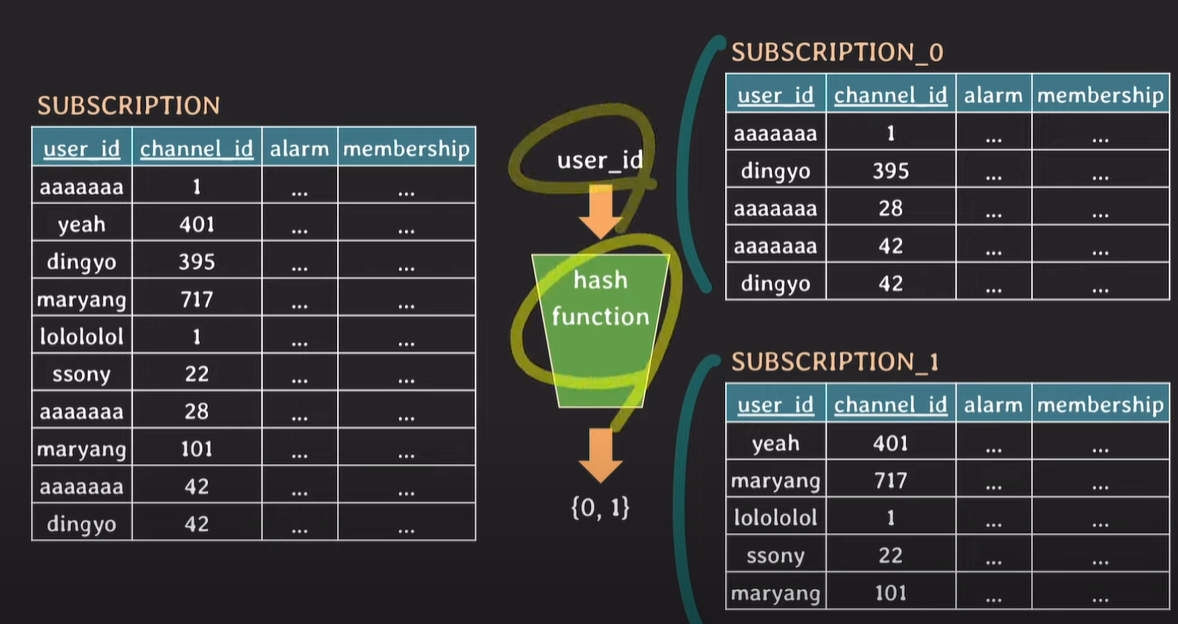

기존 table을 사용하지 않고 hash function을 통해 나눈 파티셔닝 테이블을 사용하며, hash function에 사용된 user_id를 partition key라 부른다.
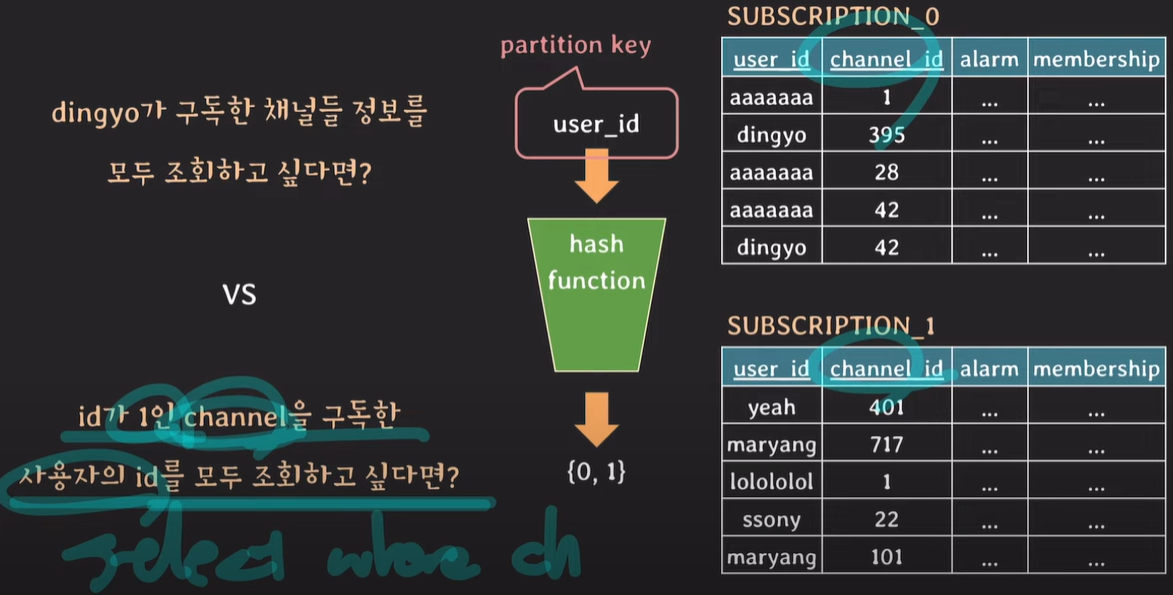
user_id를 partition key로 지정하고 user_id로 테이블을 조회하면 성능이 좋지만, 만약 partition key가 아닌 channel_id로 조회한다면 어떻게 될까?
모든테이블에 대해서 조회를 해야하기 때문에 full scan한다.
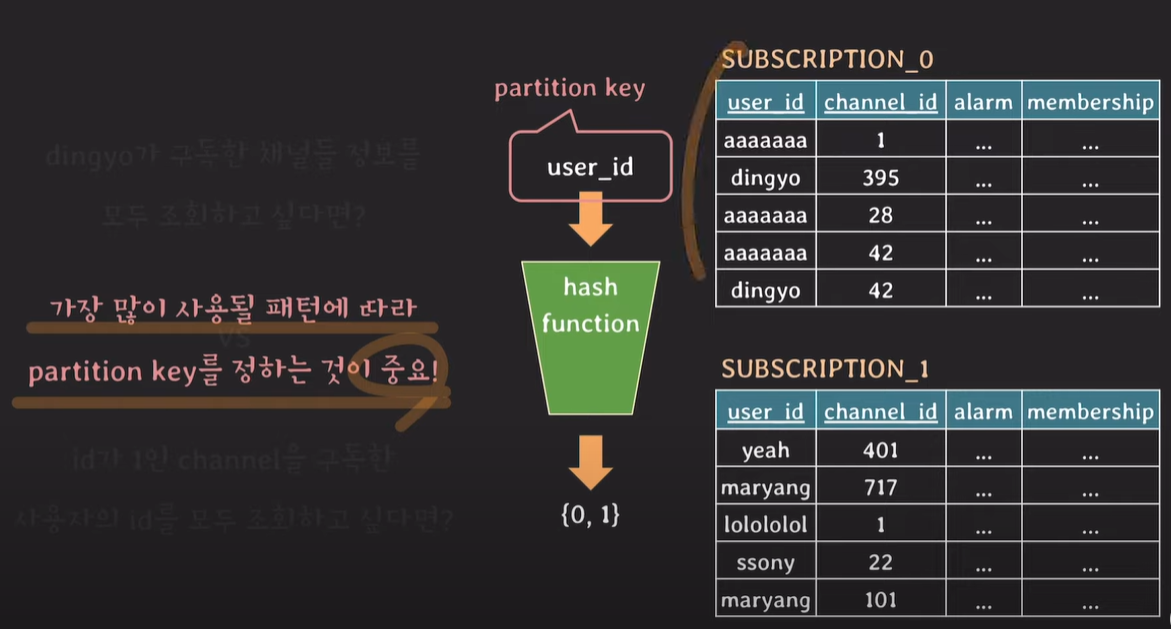

주로 read 조건에 사용되는 attribute를 partition key로 설정하는것이 좋으며, 데이터가 잘 분배되도록 설정한다.
주의

첫 hash-based partitioning 후 추가적으로 partitioning을 하게되면, 새롭게 hash function들을 적용해야하고, 데이터들을 재배치해야하기 때문에 운영 중 재배치하면 위험이 따른다.
Sharding
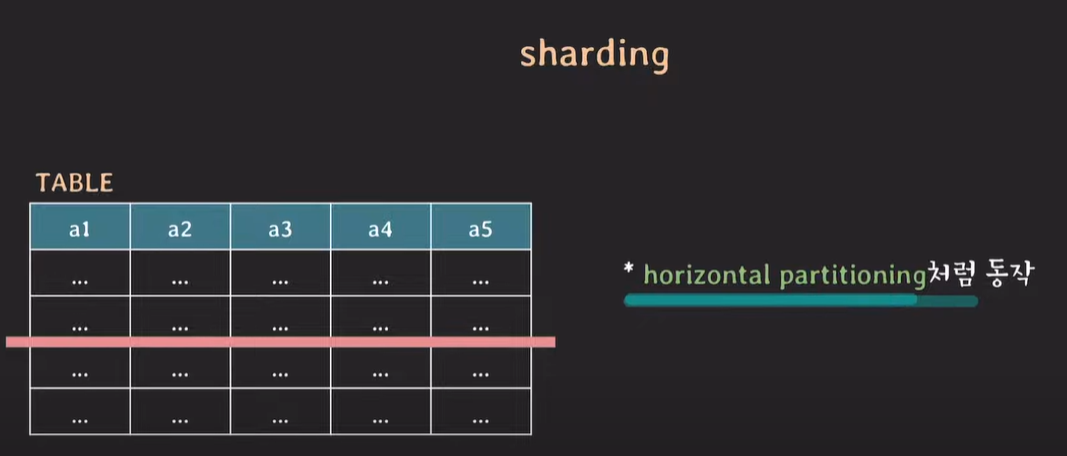
row를 기준으로 동작하는 horizontal partitioning과 유사하다.
하지만, 각 partition은 서로 다른 DB 서버를 사용한다.
horizontal partioning과 차이

horizontal partioning은 파티션 후 나뉘어진 파티션들이 같은 DB서버에 저장된다.
하나의 DB서버로 관리하기 때문에 다수의 요청이 오는 경우 조회시간이 오래 걸릴 수 있다.
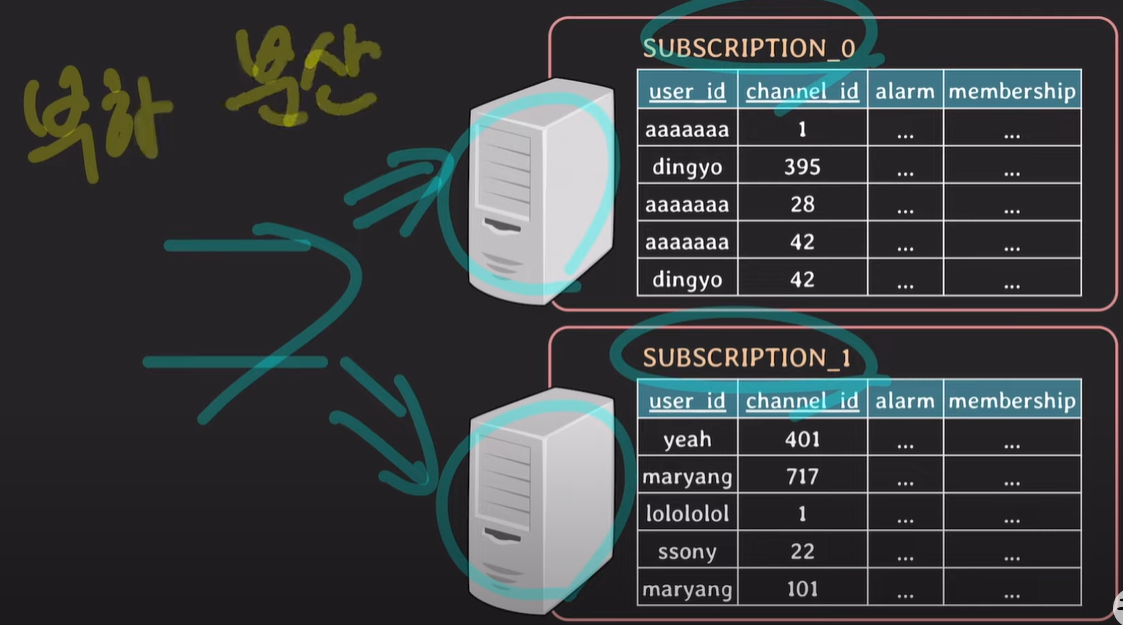
샤딩을 실행하면 파티션된 테이블이 서로 다른 독립된 DB서버에 저장되기 때문에 요청에 맞는 테이블만 조회할 수 있으며, DB 서버에 부하가 적다.
부하를 분산시키는 목적을 가진다.
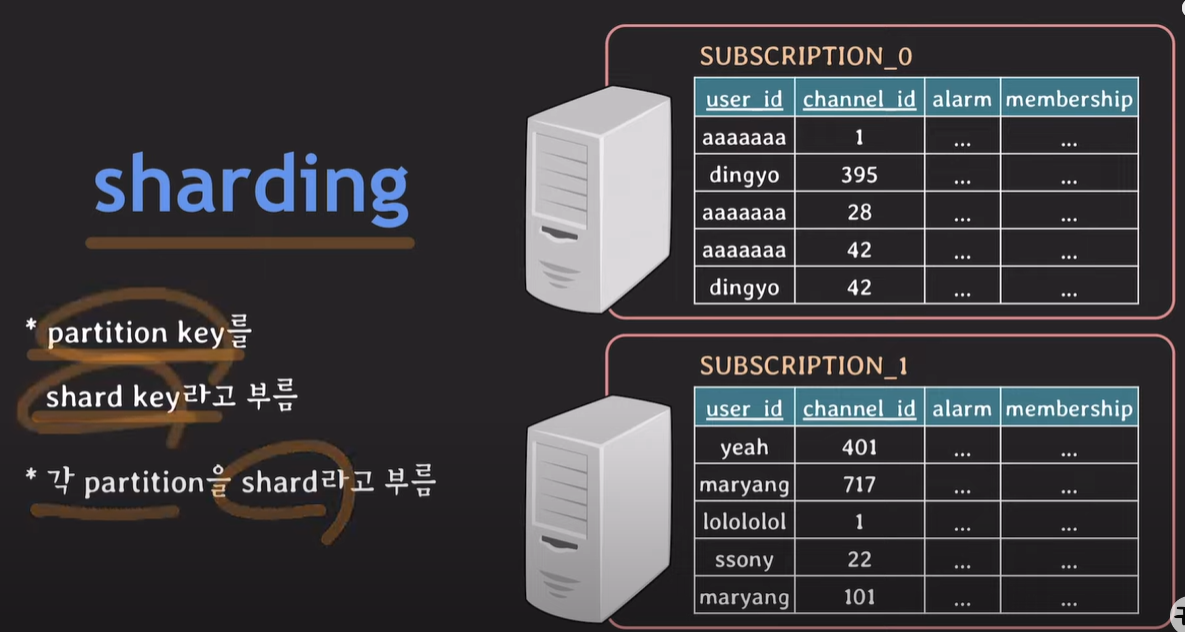
샤딩에 사용되는 attribute를 shard key라 부르며, 각각의 테이블을 shard라 한다.
Replication

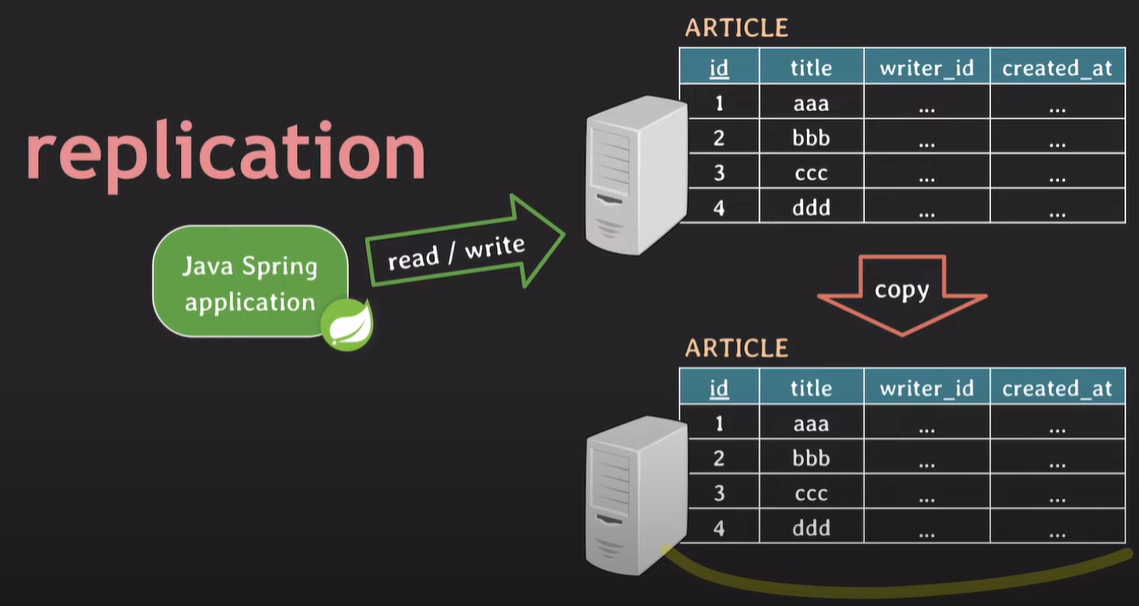
기존에 존재하는 데이터베이스를 그대로 복사해온다. 두 데이터베이스는 항상 같은 스키마를 유지하고, 데이터가 변경되면 다른 데이터베이스에도 동기화시킨다.
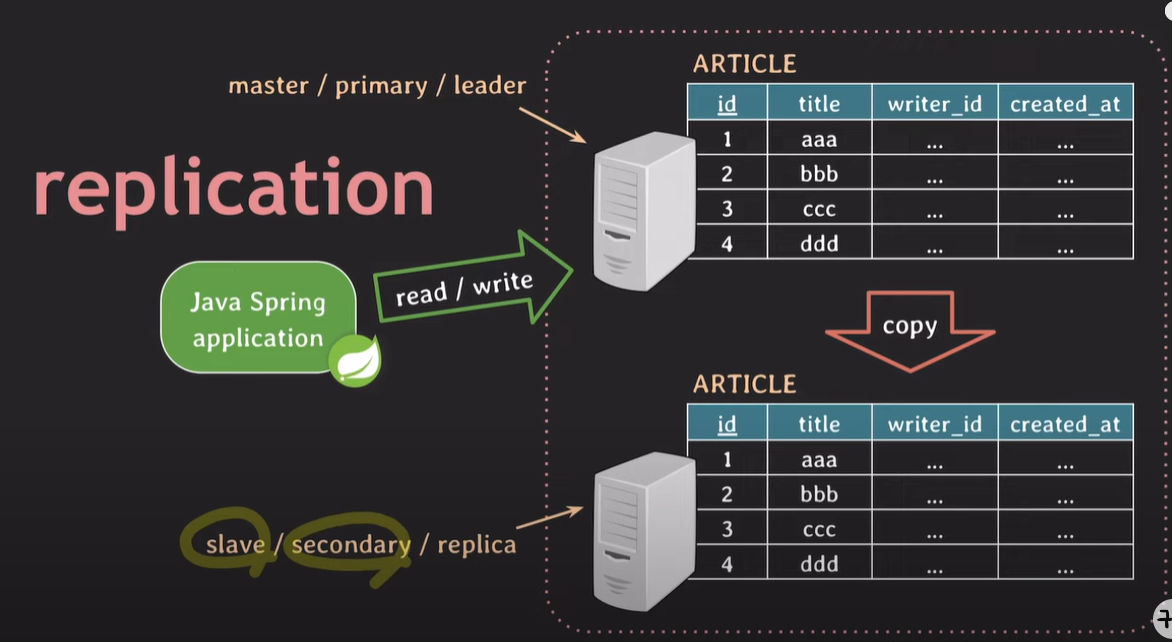
원본 table : 주로 master, primary, leader 라 불린다.
복사 table : 주로 slave, secondary, replica 라 불린다.
secondary server는 1개만 가져야 하는게 아닌, 1개 이상 가질 수 있다. 필요에 따라 증설한다.
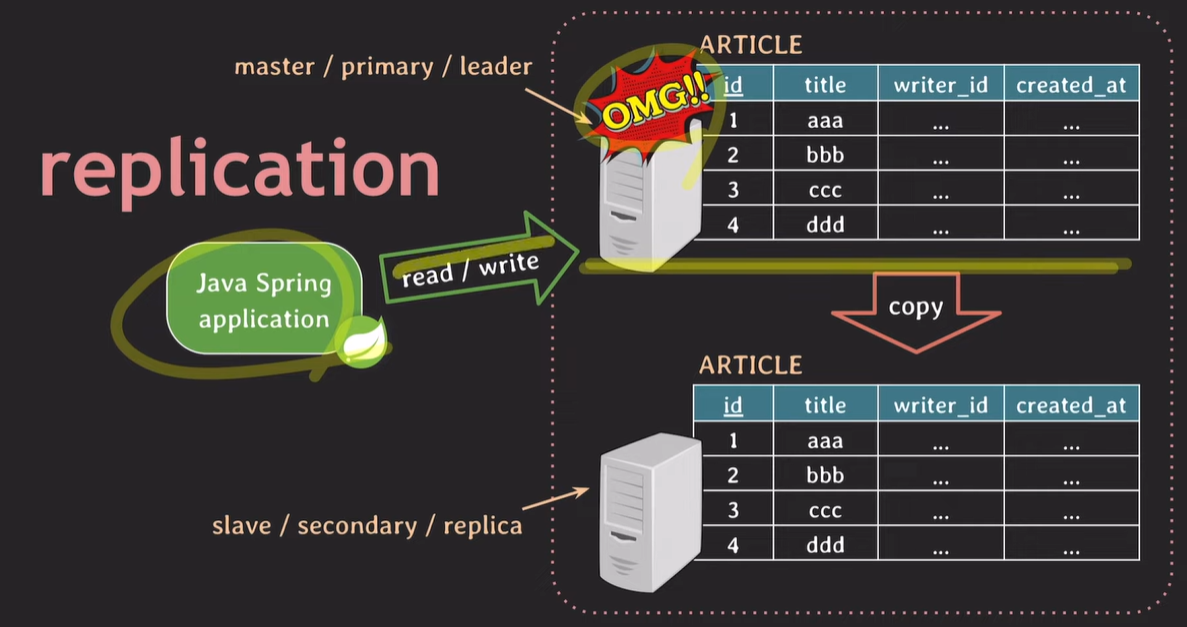
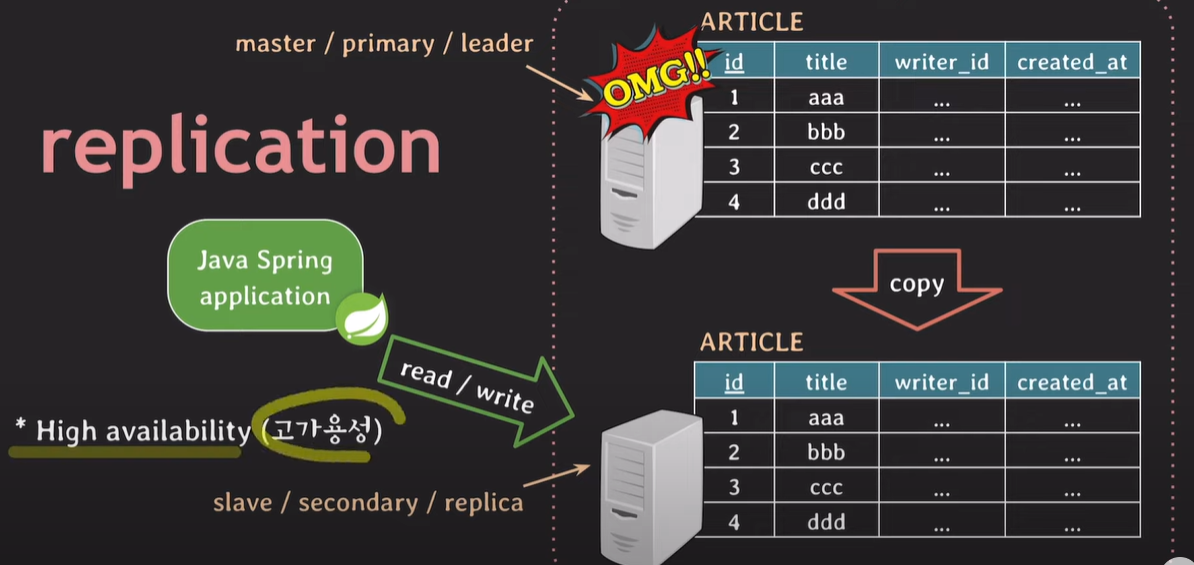
고가용성 (HA, high availability) :
primary 서버에 문제가 생겼을 경우 애플리케이션은 secondary 서버에서 read/write 한다. 장애 상황이 발생해도 빠르게 서비스를 유지할 수 있다.
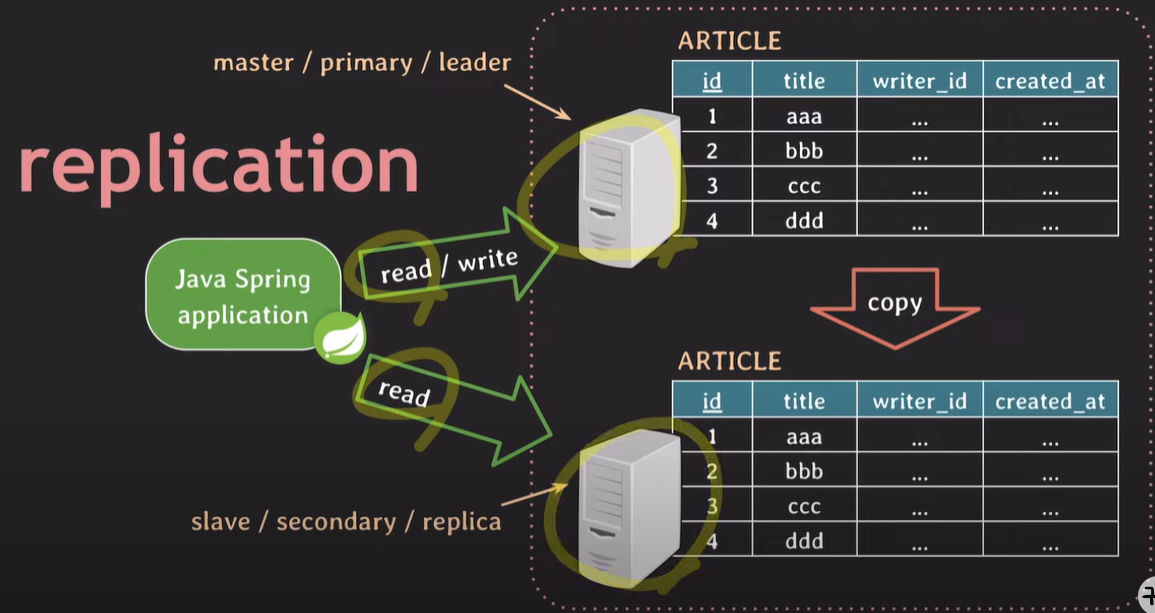
장애 상황이 아닌경우, secondary 서버로 트래픽을 나눌 수 있기 때문에, 성능이 향상되며 서버 부하를 낮춘다. 주로 대부분의 요청인 read 요청 트래픽을 나눠 줄 수 있다.
정리
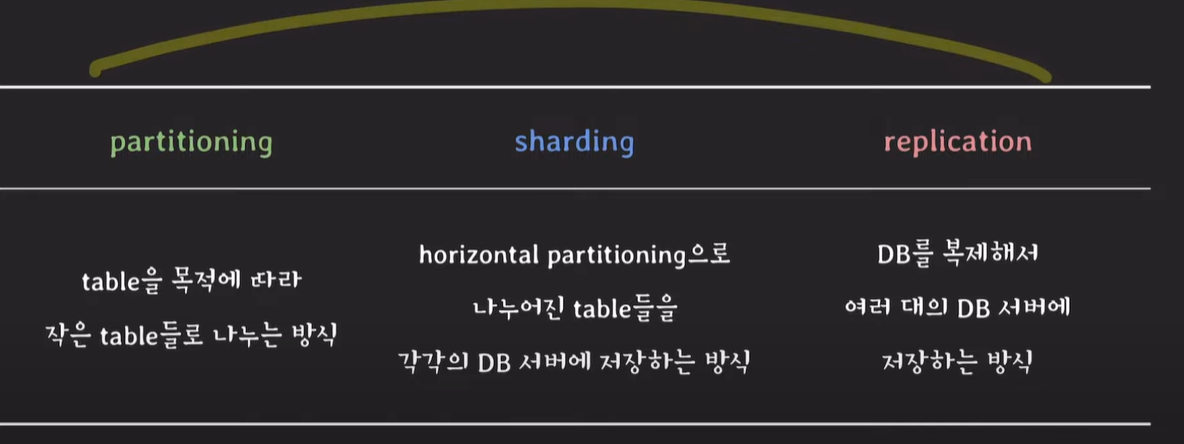

용어에 대한 설명이기 때문에 추가적으로 공부할 것!!!
파티셔닝, 샤딩, ★레플리케이션
