개요
기초 프로젝트
- 벌써 부트캠프 시작 5주차..
한 달 동안 학습한 내용들을 활용해 기초 프로젝트를 해보는 시간이 되었다.
- "ON AIR 분석 절차를 기반으로한 프로젝트"
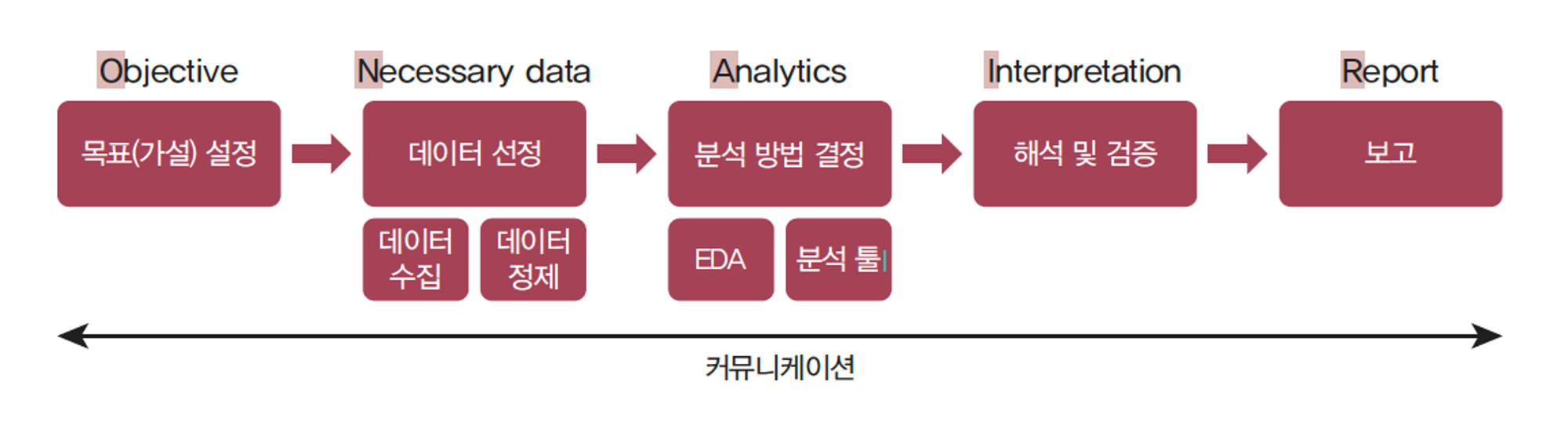
Objective (목표)- 프로젝트 목표 : 프로젝트의 주요 목표를 명확히 기술,
어떤 문제를 해결하고자 하는지, 어떤 비즈니스 목표를 달성하려는지 설명 - 예상 결과물 : 프로젝트를 통해 기대되는 결과물과 도출하고자 하는 인사이트 명시
- 프로젝트 목표 : 프로젝트의 주요 목표를 명확히 기술,
Necessary Data (데이터)- 데이터 소스 : 사용할 데이터의 출처를 설명하고, 필요한 데이터 유형과 범위 명시
- 데이터 수집 계획 : 데이터를 수집하기 위한 계획과 방법 기술,
데이터 수집의 정확성과 완전성을 보장하기 위한 조치 고려
Analytics (분석)- 분석 방법 : 사용할 데이터 분석 기법과 모델을 선정하고 분석을 위한 절차 설명
- 데이터 처리 : 데이터를 정제하고 전처리하는 방법 기술, 분석에 필요한 데이터의 품질 확인
- 시각화 계획 : 데이터를 시각적으로 표현하여 인사이트를 도출하는 계획 제시
Interpretation (해석)- 분석 결과 해석 : 분석 결과를 해석하고, 비즈니스에 어떻게 적용할 수 있는지를 설명
- 인사이트 도출: 데이터에서 도출된 인사이트와 향후 전략 수립을 위한 제언을 제시
Report (보고)- 보고서 구조: 보고서의 구조와 형식을 정의하고, 어떤 정보를 포함할 것인지를 설명
- 시각화 활용: 보고서에 사용할 시각화 도구 및 방법을 결정하고, 강조할 요소를 구체화
- 보고서 작성 일정: 보고서 작성 및 발표 일정을 계획하고, 이를 관리할 방법을 기술
-
What to do: SQL과 Python을 활용한 데이터 분석 실전 연습 단계
정말 다양한 주제와 데이터들을 준비해주셔서 갬동..
-
열심히 해보자!
- “문제에 부딪히며 해결해나가는 과정을 회고할 수 있어야 한다”
- “크고 작음과 상관없이 팀이 목표한 바를 이루어냈는가”
- “그 목표를 이루기 위해 나는 스스로 어떤 노력을 했는가”
📌 1일차
📌 주제 선정
나의 의견
프로젝트 중점 > 어떤 데이터 분석가로 성장할 것인가
-
해보고 싶은 주제
-
GA4 데이터를 활용한 프로덕트 분석 :
실무에서 가장 많이 접할 법한 상황인 것 같고,
코호트, 리텐션, 퍼널 등 지표 분석을 직접 해볼 수 있는 프로젝트인 것 같아서 -
음악 플랫폼 유저 행동 데이터 분석 :
행동 데이터(행동패턴) 분석은 모든 도메인에서 중요한 의미를 가지고 있기 때문에 -
제주 특산물 가격 예측 AI 경진대회 :
머신러닝 모델을 활용한 다양한 분석(회귀분석을 통한 예측 등)을
해볼 수 있는 프로젝트인 것 같아서
-
팀원들과 회의 결과, 다양한 주제를 선호하는 경향이 있어
선호하는 주제 +1, 불호하는 주제 -1로 스코어링을 한 결과,
음악 플랫폼 유저 행동 데이터 분석 주제로 진행하게 되었다.

- 주제: 음악플랫폼 데이터에 대한 EDA 진행, 서비스 현황 확인 및 개선점 제시 - 내용: - 서비스의 현 상태 확인 - 이슈사항 확인 - 고객 세그먼트화(특정 기준에 따라 유저 나누기) - 사용자의 연령과 성별, 고객 행동 패턴에 따라 코호트를 나누어 분석하여 다양한 인사이트 도출 - 변수 간의 상관관계 확인, Heatmap 등으로 시각화, 분포 확인 등 진행 - 다양한 지표 설계 - Action Item 등 인사이트 제공 - 목표 : 유저 행동 데이터 분석을 통한 매출 증대 방안 제시 - 프로젝트 핵심 내용: 다양한 관점에서 EDA를 수행하여 변수 간 상관관계 분석 및 시각화
📌 데이터 살펴보기
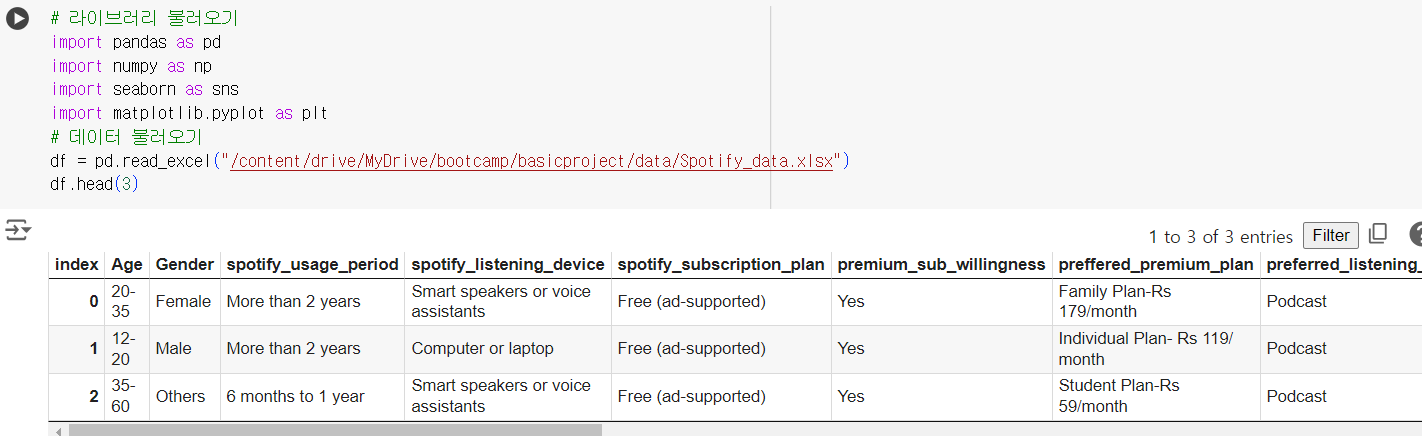
- 먼저 데이터를 불러오고 전체적으로 살펴봤다.
# 라이브러리 불러오기 import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt # 데이터 불러오기 df = pd.read_excel("/content/drive/MyDrive/bootcamp/basicproject/data/Spotify_data.xlsx") df.head(3)
# 시각화 관련 폰트 깨짐 문제 해결 !sudo apt-get install -y fonts-nanum !sudo fc-cache -fv !rm ~/.cache/matplotlib -rf # 폰트 설치 import matplotlib.pyplot as plt plt.rc('font', family='NanumBarunGothic') plt.rcParams['axes.unicode_minus'] =False # 기본 폰트 설정

- 데이터 확인
# 데이터 크기 확인 df.shape

# 컬럼 확인 # df.columns # 데이터 정보 확인 df.info() # 오브젝트 타입의 데이터가 대부분
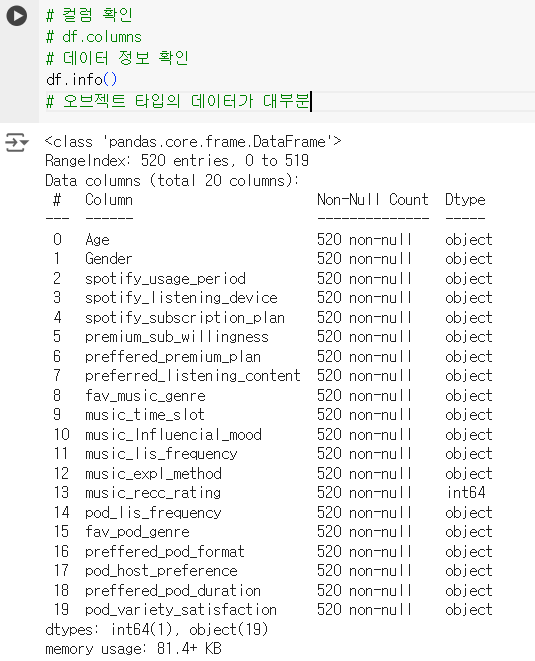
# 결측치 확인 print(df.isnull().sum())
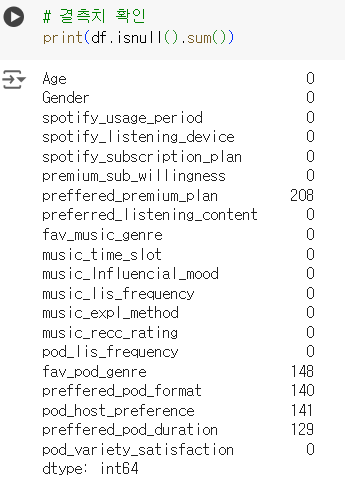
# 결측치 처리 어떻게..? # NaN 값은 실제로는 None 의 값을 가짐 # 설문에 응답하지 않은 데이터로 "N" 으로 대치 df = df.fillna(str("N")) print(df.isnull().sum()) df

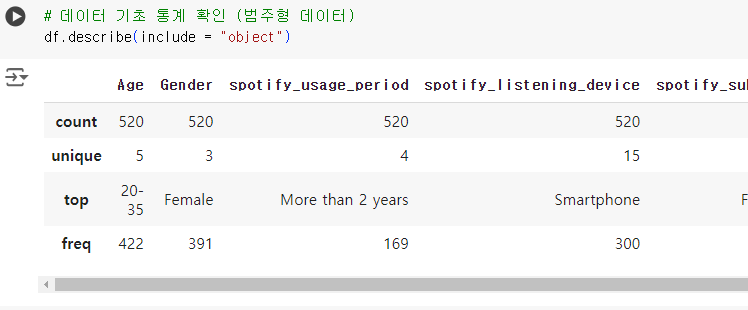
# 데이터 기초 통계 확인 (범주형 데이터) df.describe(include = "object")
📌 EDA (탐색적 데이터 분석)
-
각 컬럼별
value_counts()를 조회하고 데이터의 특징을 파악EDA 역할분담
결측치 공통적으로 처리 후 EDA탐색 시작
- 팀원들이 각자 컬럼을 하나씩 잡고 각 컬럼 기준 특징을 파악하는 시간을 가졌다.
주로 확인하고자 했던 컬럼들은 spotify_usage_period(사용기간) 기준music_time_slot기준Gender, Age기준music_recc_rating기준spotify_subscription_plan(Free vs Premium) 기준- 각 기준에 따른 이용자 현황분석으로 인사이트 도출이 목표 !
- 팀원들이 각자 컬럼을 하나씩 잡고 각 컬럼 기준 특징을 파악하는 시간을 가졌다.
-
오늘은 괄목할만한 인사이트 도출에는 실패..
다음주에는 기준에 따른 특징의 데이터와 다른 변수들과의 관계나 특징을 위주로 파악해볼 예정!
- 1일차 정리
각 컬럼별value_counts()를 조회하고 데이터의 특징을 파악
- DONE
- 사용기간을 기준한 분석으로는 유의미한 인사이트나 결론 도출이 어려웠다.
- 데이터의 분포가 편향이 크다.
(music과 podcast 의 사용 비율, 성별 비율(female 이 압도적), 무료 플랜 사용자 비율(무료가 압도적) 등)
- PLAN
범주형 - 범주형데이터를 분석하기 위해 교차검증 사용 후 히트맵으로 시각화- 추천을 통해 음악을 처음 접하는 사람이 가장 많다.
추천시스템에 대한 만족도, 음악장르, podcast 사용 등에 대한 관련성이나 특징을 종합적으로 살펴보자.
📌 2일차
📌 EDA (탐색적 데이터 분석)
- 범주형 - 범주형 데이터를 분석하기 위해 교차검증 사용 후 히트맵으로 시각화
# 한 컬럼을 기준하여 그 컬럼이 아닌 다른 컬럼들과 교차 분석 반복 실행 for column in df.columns: if column != 'preferred_listening_content': crosstab_result = pd.crosstab(df['preferred_listening_content'], df[column]) print(f"교차 분석 - {column} 칼럼:") print(crosstab_result) print("\n")
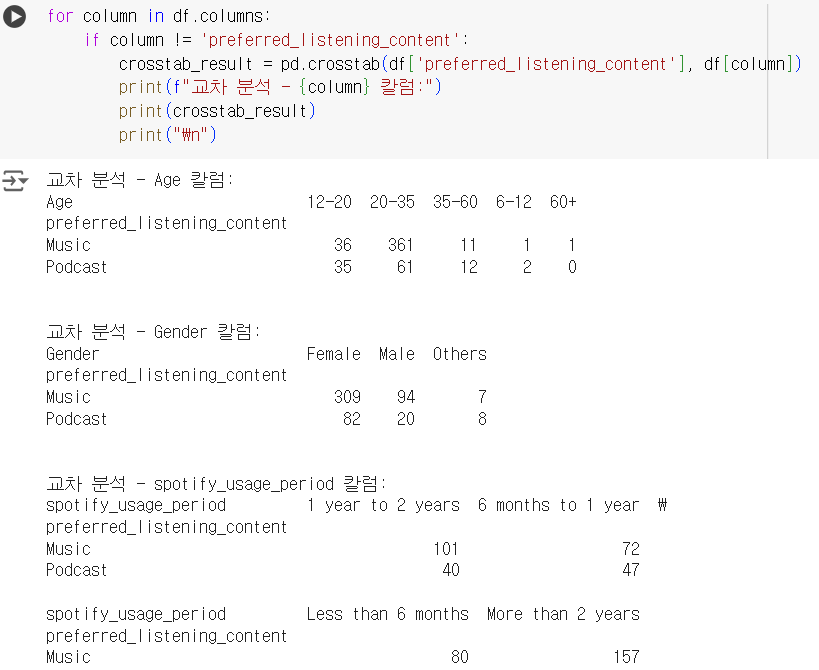
# 교차 분석 결과를 히트맵으로 시각화하는 함수 def visualize_crosstab(crosstab_result): plt.figure(figsize=(6, 4)) sns.heatmap(crosstab_result, annot=True, fmt="d", cmap = "Blues") plt.show() # df의 모든 컬럼에 대해 교차 분석을 수행하고 시각화 for column in df.columns: if column != 'preferred_listening_content': crosstab_result = pd.crosstab(df['preferred_listening_content'], df[column]) print(f"교차 분석 - {column} 칼럼:") visualize_crosstab(crosstab_result)

- 데이터를 살피던 중 데이터 내 중복 선택으로 인한 선택지들이 뭉쳐 있는 컬럼을 발견했다.
- 중복 컬럼 예)
columns_to_encode = ['spotify_listening_device', 'music_Influencial_mood', 'music_lis_frequency', 'music_expl_method'] dup = [df[i].unique() for i in columns_to_encode] # 딕셔너리 생성 unique_values_dict = dict(zip(columns_to_encode, dup)) # 딕셔너리를 데이터프레임으로 변환 unique_values_df = pd.DataFrame(dict([(k, pd.Series(v)) for k, v in unique_values_dict.items()])) # 데이터프레임 출력 unique_values_df # 데이터프레임 정렬 (열 별로 개별 정렬) sorted_df = unique_values_df.apply(lambda x: x.sort_values().reset_index(drop=True)) # 데이터프레임 출력 sorted_df
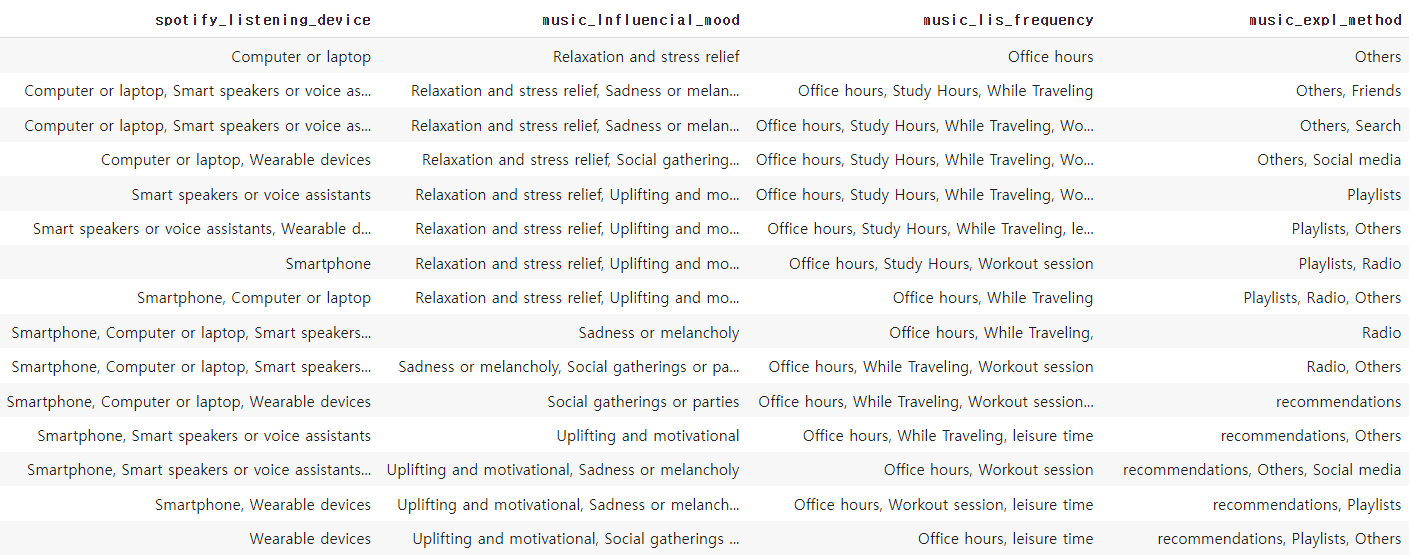
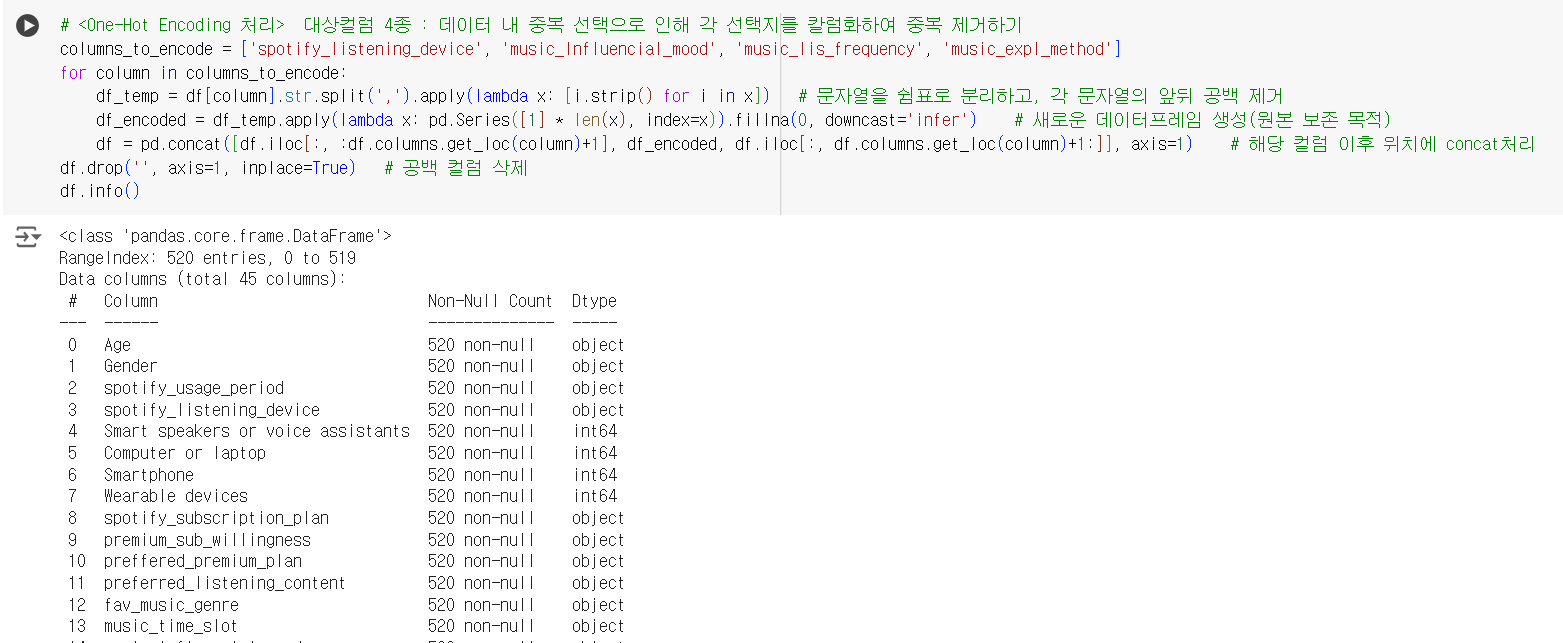
- 따라서 해당 데이터들을 원-핫 인코딩을 통해 컬럼 내 중복값을 제거하는 것을 시도했다.
# <One-Hot Encoding 처리> 대상컬럼 4종 : 데이터 내 중복 선택으로 인해 각 선택지를 칼럼화하여 중복 제거하기 columns_to_encode = ['spotify_listening_device', 'music_Influencial_mood', 'music_lis_frequency', 'music_expl_method'] for column in columns_to_encode: df_temp = df[column].str.split(',').apply(lambda x: [i.strip() for i in x]) # 문자열을 쉼표로 분리하고, 각 문자열의 앞뒤 공백 제거 df_encoded = df_temp.apply(lambda x: pd.Series([1] * len(x), index=x)).fillna(0, downcast='infer') # 새로운 데이터프레임 생성(원본 보존 목적) df = pd.concat([df.iloc[:, :df.columns.get_loc(column)+1], df_encoded, df.iloc[:, df.columns.get_loc(column)+1:]], axis=1) # 해당 컬럼 이후 위치에 concat처리 df.drop('', axis=1, inplace=True) # 공백 컬럼 삭제 df.info()
- 반복문으로 여러 시각화 도표들을 살펴보다가 팀원의 의견으로
무료 이용자와 유료 이용자를 구분할 필요성에 대해 인식했고,
무료 이용자와 유료 이용자를 따로 구분하여 각 그룹의 사용 패턴을 분석하고
관계가 있는 데이터를 뽑아보는 것으로 방향성을 잡았다!
📌 3일차
📌 EDA (탐색적 데이터 분석)
- 유료 이용자와 무료 이용자 구분하기 (필터링)
- 무료 이용자 중 유료 구독의사가 있고 추천 시스템 만족도가 높은 이용자 (교차분석)
# 필터링 (유료 구독의사가 있고 음악 추천 시스템 만족도가 높은(4점 이상) 이용자) filtered = df[(df['music_recc_rating'] > 3) & (df['premium_sub_willingness'] == 'Yes')] # 무료 플랜 이용자 중 구독 의사가 있는 사람 # filtered = df[(df['spotify_subscription_plan'] == 'Free (ad-supported)') & (df['premium_sub_willingness'] == 'Yes')] crosstab = pd.crosstab(filtered['music_recc_rating'], filtered["preferred_listening_content"]) sns.heatmap(crosstab, annot=True, fmt="d", cmap = "Blues") plt.show()
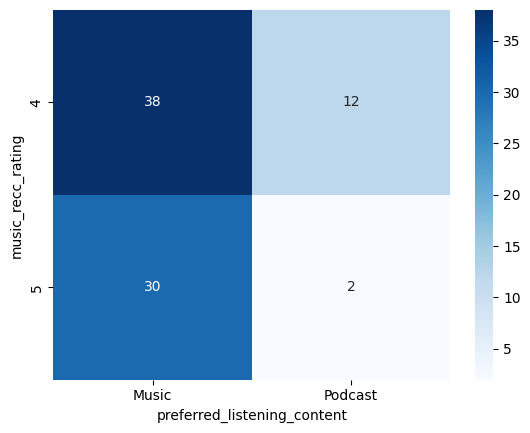
- 추천 시스템에 대한 만족도가 높고 구독 의향이 있는 고객의 행동패턴 분석
(반복문 활용한 교차분석결과 히트맵 시각화)
# 교차 분석 결과를 히트맵으로 시각화하는 함수 생성
def visualize_crosstab(crosstab_result):
plt.figure(figsize=(6, 4))
sns.heatmap(crosstab_result, annot=True, fmt="d", cmap = "Blues")
plt.show()
# 탐색 목적 : 추천 시스템에 대한 만족도가 높고 구독 의향이 있는 고객의 행동패턴 분석
# 필터링
filtered = df[(df['music_recc_rating'] > 3) & (df['premium_sub_willingness'] == 'Yes')]
# df의 모든 컬럼에 대해 교차 분석을 수행하고 시각화
for column in df.columns:
if column != 'music_recc_rating':
crosstab_result = pd.crosstab(filtered['music_recc_rating'], filtered[column])
print(f"교차 분석 - {column} 칼럼:")
visualize_crosstab(crosstab_result)- 여러가지 조건을 계속 변경해가며, 교차분석을 시도하고
해당 분석들을 히트맵으로 표현했다.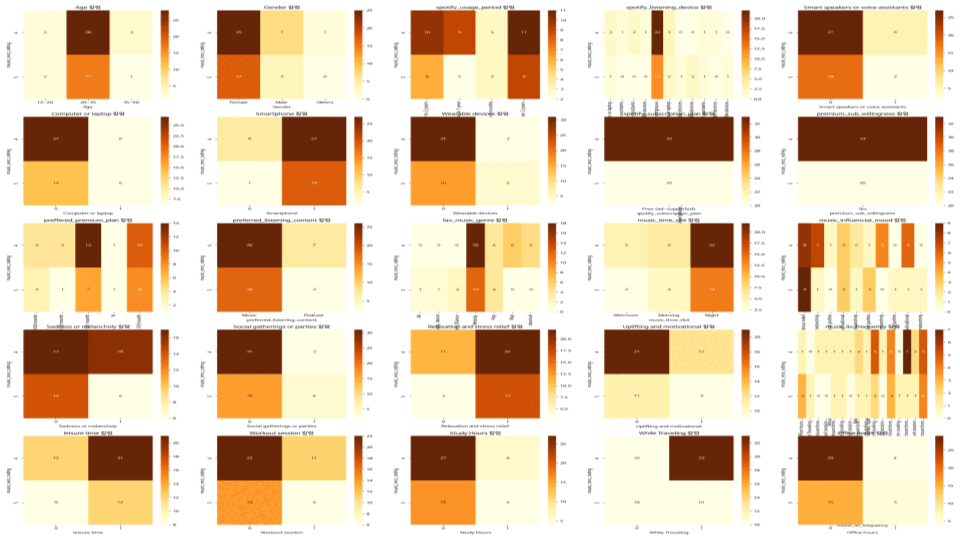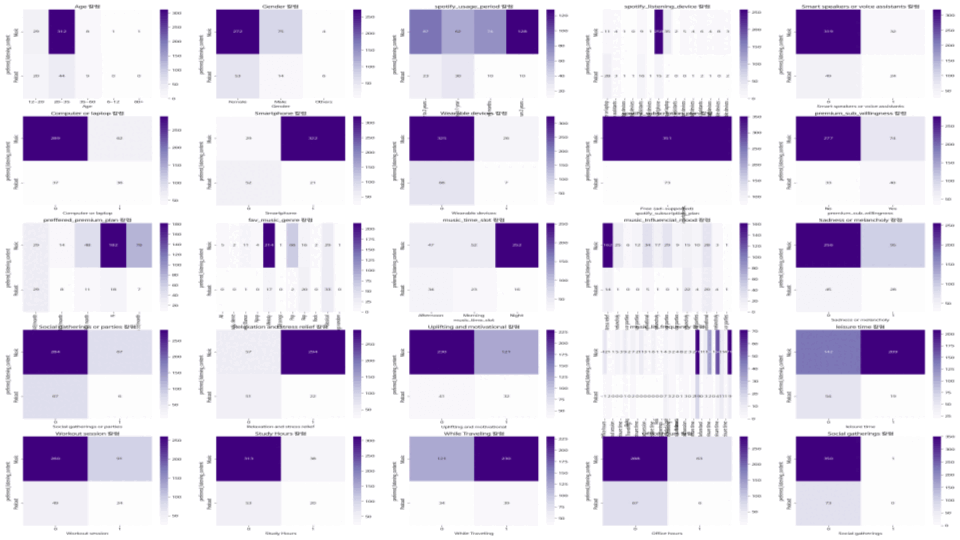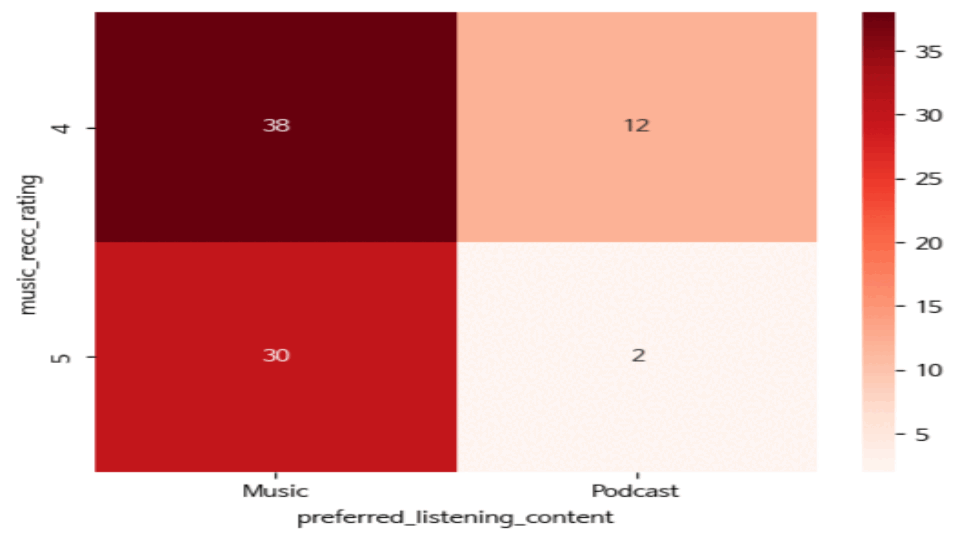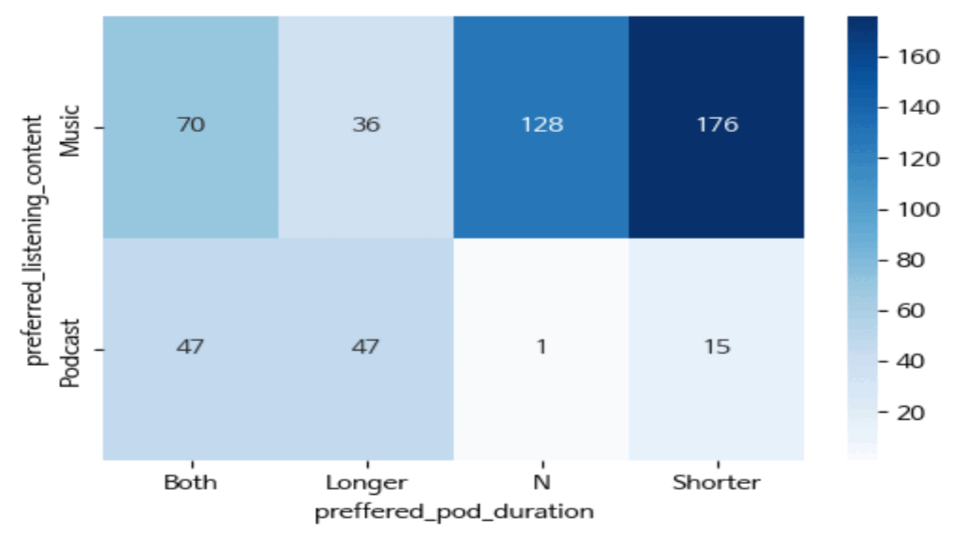
# 코드 정리 예정📌 분석 기획 및 결과
나의 의견
목적: 팟캐스트 유료 이용자를 늘리기 위함 !?
- 무료 segment: 디바이스, 장르 선호도, 팟캐스트 장르
- 유료 segment: 팟캐스트 청취 빈도와 장르
선호하는 음악 장르 이용자 대상 맞춤형 추천 시스템
스마트폰 알림, 프로모션 진행
팟캐스트 청취 유도 이벤트: 일정기간 들으면 무료 구독권 지급
개인화된 팟캐스트 추천 시스템 강화
팀 회의 결과
EDA 후 2가지 action plan 도출
- 팟캐스트 논리 흐름
- 유료 구독자들이 팟캐스트 청취 비율이 높음.
→ 팟캐스트 콘텐츠 강화를 통해 무료 이용자들이 팟캐스트 청취를 하도록 유도하자.
→ 무료 이용자들이 팟캐스트 청취에 만족하면 프리미엄 구독을 할 확률이 높을 것이다. - 무료 이용자가 원하는 콘텐츠 1)코미디, 2)헬스 및 운동 (시간을 추가할 것이라면 short 콘텐츠)
- 유료 구독자들이 팟캐스트 청취 비율이 높음.
- 여행 관련 타겟 마케팅
- 유료, 무료 모두 여행 중에 음악을 듣는 경우가 많음.
- 무료 = 여행 관련(검색 등 추적 분석?) 구독자에게 프리미엄 체험권 지급.
📌 4일차
📌 데이터 시각화
데이터 분석 기획과 목적에 맞는 시각화 정리
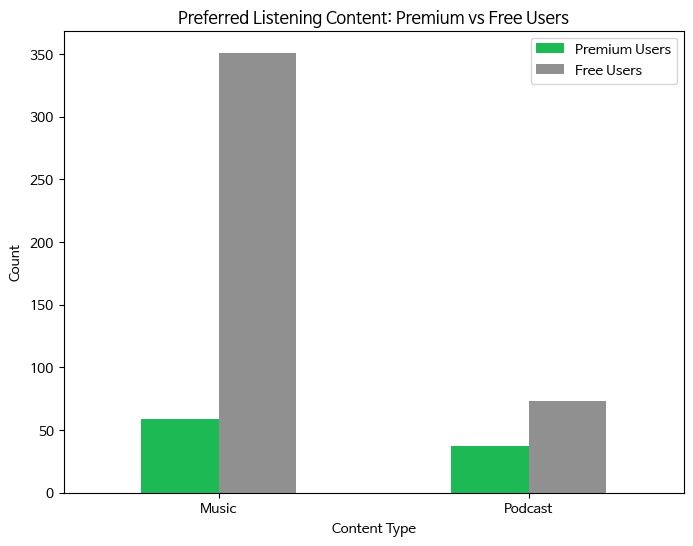
- 유료, 무료 이용자의 선호하는 청취 콘텐츠 (카운트 비교)
# 유료 이용자와 무료 이용자로 데이터 분리 premium = df[df['spotify_subscription_plan'] == 'Premium (paid subscription)'] free = df[df['spotify_subscription_plan'] == 'Free (ad-supported)'] # 유료 이용자와 무료 이용자의 선호 청취 컨텐츠 카운트 변수 생성 premium_content_counts = premium['preferred_listening_content'].value_counts() free_content_counts = free['preferred_listening_content'].value_counts() # 시각화를 위한 데이터 프레임 생성 comp = pd.DataFrame({ 'Premium Users': premium_content_counts, 'Free Users': free_content_counts }).fillna(0) # 데이터 크기 내림차순으로 컬럼 정렬 comp_sorted = comp.loc[comp.sum(axis=1).sort_values(ascending=False).index] # 색상 정하기 colors = ['#1DB954', '#909090'] # 바그래프 시각화 comp_sorted.plot(kind='bar', figsize=(8, 6), color = colors) plt.title('Preferred Listening Content: Premium vs Free Users') plt.xlabel('Content Type') plt.ylabel('Count') plt.xticks(rotation=0) plt.legend() plt.show()
- 유료, 무료 이용자의 선호하는 청취 콘텐츠 (가로 그래프 + 총 비율 비교)
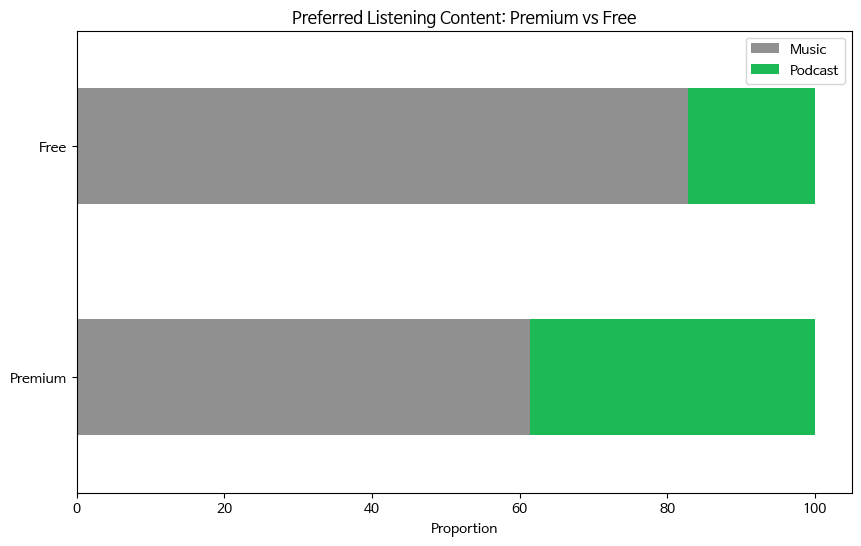
# 유료 이용자와 무료 이용자로 데이터 분리 premium = df[df['spotify_subscription_plan'] == 'Premium (paid subscription)'] free = df[df['spotify_subscription_plan'] == 'Free (ad-supported)'] # 유료 이용자와 무료 이용자의 선호 청취 콘텐츠 비율 변수 생성 (normalize : 정규화) premium_content_counts_pro = premium['preferred_listening_content'].value_counts(normalize=True) free_content_counts_pro = free['preferred_listening_content'].value_counts(normalize=True) # 시각화를 위한 데이터 프레임 생성 comp = pd.DataFrame({ 'Premium': premium_content_counts_pro * 100, 'Free': free_content_counts_pro * 100 }).fillna(0) # 색상 정하기 # colors1 = ['#77DFA9' if (x < max(premium_content_counts_pro)) else '#1DB954' for x in premium_content_counts_pro] # colors2 = ['#909090' if (x < max(free_content_counts_pro)) else '#000000' for x in free_content_counts_pro] colors = ['#909090','#1DB954'] # 바그래프 시각화 gragh = comp.T.plot(kind='barh', stacked=True, figsize=(10, 6), color=colors) plt.title('Preferred Listening Content: Premium vs Free') plt.xlabel('Proportion') plt.ylabel('') plt.legend(['Music', 'Podcast']) # for i in gragh.containers: # gragh.bar_label(i, fmt='%.f', label_type='center', color = 'Black') plt.show()
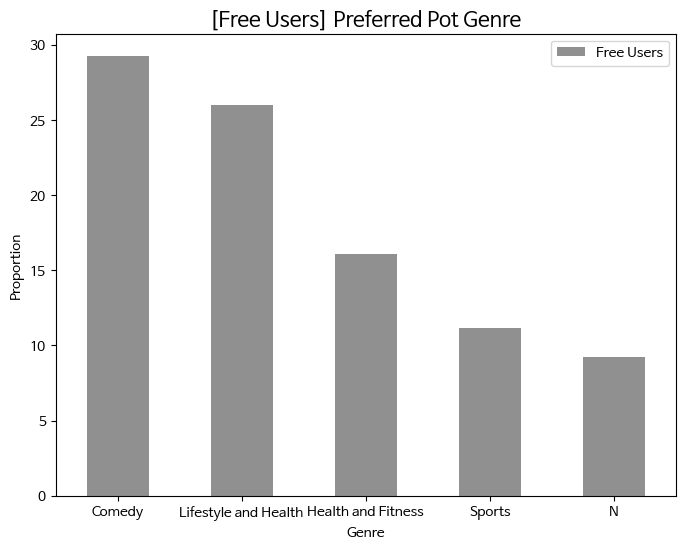
- 무료 이용자의 선호하는 팟캐스트 장르 (총 비율 비교)
# 유료 이용자와 무료 이용자로 데이터 분리 # premium = df[(df['spotify_subscription_plan'] == 'Premium (paid subscription)') & (df['pod_lis_frequency'] != "Never")] free = df[(df['spotify_subscription_plan'] == 'Free (ad-supported)') & (df['pod_lis_frequency'] != "Never")] # 유료 이용자와 무료 이용자의 선호 청취 팟캐스트 장르 비율 변수 생성 (normalize : 정규화) # premium_pod_counts = premium['fav_pod_genre'].value_counts(normalize=True).head(5) free_pod_counts = free['fav_pod_genre'].value_counts(normalize=True).head(5) # 시각화를 위한 데이터 프레임 생성 comp = pd.DataFrame({ # 'Premium Users': premium_pod_counts * 100, 'Free Users': free_pod_counts * 100 }).fillna(0) # 데이터 크기 내림차순으로 컬럼 정렬 comp_sorted = comp.loc[comp.sum(axis=1).sort_values(ascending=False).index] # 색상 정하기 colors = ['#909090'] # 바그래프 시각화 comp_sorted.plot(kind='bar', figsize=(8, 6), color = colors) plt.title('[Free Users] Preferred Pod Genre', size = 15) plt.xlabel('Genre') plt.ylabel('Proportion') plt.xticks(rotation=0) plt.legend() plt.show()
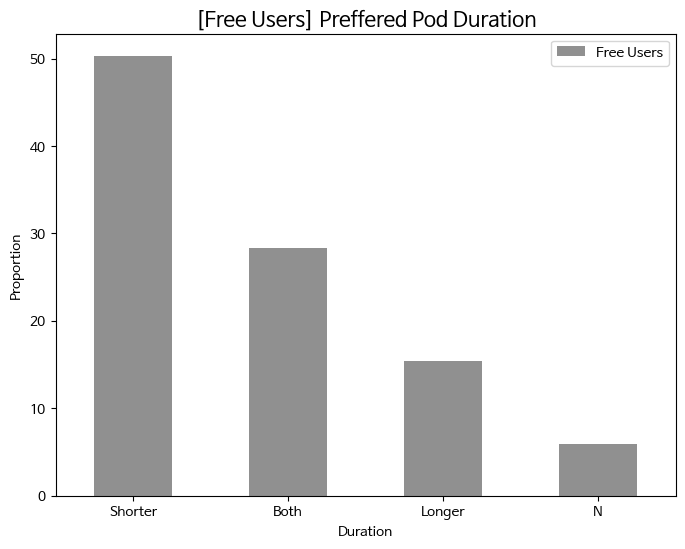
- 무료 이용자의 선호하는 팟캐스트 컨텐츠 길이 (비율 비교)
# 유료 이용자와 무료 이용자로 데이터 분리 # premium = df[(df['spotify_subscription_plan'] == 'Premium (paid subscription)') & (df['pod_lis_frequency'] != "Never")] free = df[(df['spotify_subscription_plan'] == 'Free (ad-supported)') & (df['pod_lis_frequency'] != "Never")] # 유료 이용자와 무료 이용자의 선호 청취 팟캐스트 컨텐츠 길이 비율 변수 생성 (normalize : 정규화) # premium_pod_counts = premium['fav_pod_genre'].value_counts(normalize=True).head(5) free_pod_counts = free['preffered_pod_duration'].value_counts(normalize=True).head(5) # 시각화를 위한 데이터 프레임 생성 comp = pd.DataFrame({ # 'Premium Users': premium_pod_counts * 100, 'Free Users': free_pod_counts * 100 }).fillna(0) # 데이터 크기 내림차순으로 컬럼 정렬 comp_sorted = comp.loc[comp.sum(axis=1).sort_values(ascending=False).index] # 색상 정하기 colors = ['#909090'] # 바그래프 시각화 comp_sorted.plot(kind='bar', figsize=(8, 6), color = colors) plt.title('[Free Users] Preffered Pod Duration', size = 15) plt.xlabel('Duration') plt.ylabel('Proportion') plt.xticks(rotation=0) plt.legend() plt.show()
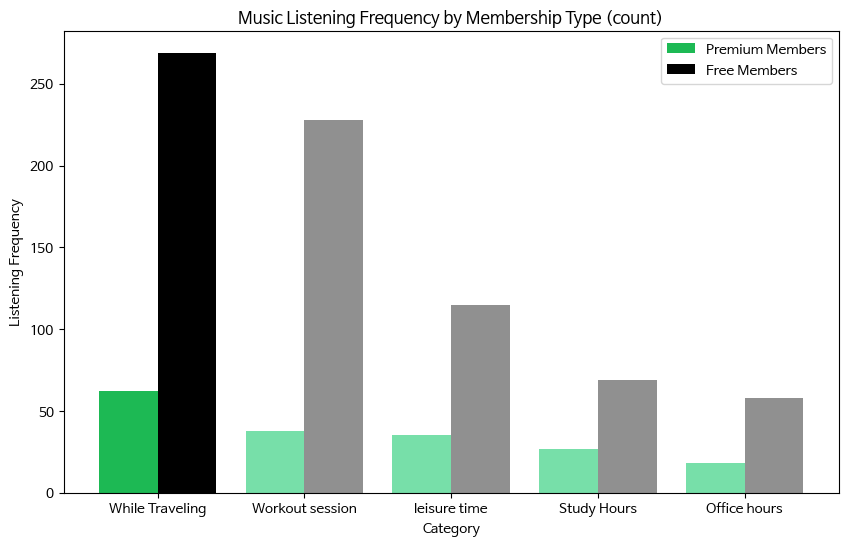
- 유료, 무료 이용자의 음악 청취 환경 (카운트 비교)
# 여행 count # 'spotify_subscription_plan' 열의 값이 'FREE'인 행을 df_free에 저장 df_free = df[df['spotify_subscription_plan'] == 'Free (ad-supported)'] # 'spotify_subscription_plan' 열의 값이 'premium'인 행을 df_premium에 저장 df_premium = df[df['spotify_subscription_plan'] == 'Premium (paid subscription)'] data1=df_premium #premium맴버쉽 사용중music_lis_frequency 칼럼의 합 music_lis_frequency_premium = data1[['While Traveling','Study Hours' ,'leisure time','Office hours','Workout session']].sum() music_lis_frequency_premium data2=df_free #free맴버쉽 사용중music_lis_frequency 칼럼의 합 music_lis_frequency_free = data2[['While Traveling','Study Hours' ,'leisure time','Office hours','Workout session']].sum() music_lis_frequency_free data=df_premium #premium맴버쉽 사용중feel칼럼의합 feel_premium = data[['Sadness or melancholy','Social gatherings or parties' ,'Relaxation and stress relief','Uplifting and motivational']].sum() feel_premium data=df_free #free맴버쉽 사용중feel칼럼의합 feel_free = data[['Sadness or melancholy','Social gatherings or parties' ,'Relaxation and stress relief','Uplifting and motivational']].sum() feel_free #백분위로 계산하기 total_premium = music_lis_frequency_premium.sum() total_free = music_lis_frequency_free.sum() music_lis_frequency_premium_pct = music_lis_frequency_premium music_lis_frequency_free_pct = music_lis_frequency_free import matplotlib.pyplot as plt import numpy as np # 데이터프레임 'music_lis_frequency_free'와 'music_lis_frequency_premium' 백분위 비교 차트 생성 # 데이터 정렬 ★ music_lis_frequency_premium_pct = music_lis_frequency_premium_pct.sort_values(ascending=False) music_lis_frequency_free_pct = music_lis_frequency_free_pct.sort_values(ascending=False) x = np.arange(len(music_lis_frequency_premium_pct)) # 막대 그래프의 x축 좌표 width = 0.4 # 막대 그래프의 너비 fig, ax = plt.subplots(figsize=(10, 6)) # 프리미엄 회원 데이터 그리기 (색상 변경) ★ # ax.bar(x - width/2, music_lis_frequency_premium_pct, width, label='Premium Members', color='#23D950') colors = ['#77DFA9' if (x < max(music_lis_frequency_premium_pct)) else '#1DB954' for x in music_lis_frequency_premium_pct] # #1DB954: 스포티파이 컬러 ax.bar(x - width/2, music_lis_frequency_premium_pct, width, label='Premium Members', color=colors) # 무료 회원 데이터 그리기 (색상 변경) ★ # ax.bar(x + width/2, music_lis_frequency_free_pct, width, label='Free Members', color='#F2F2F2') colors = ['#909090' if (x < max(music_lis_frequency_free_pct)) else '#000000' for x in music_lis_frequency_free_pct] ax.bar(x + width/2, music_lis_frequency_free_pct, width, label='Free Members', color=colors) # 그래프 제목 및 축 라벨 설정 ax.set_title('Music Listening Frequency by Membership Type (count)') ax.set_xlabel('Category') ax.set_ylabel('Listening Frequency') ax.set_xticks(x) # ax.set_xticklabels(['While Traveling', 'Study Hours', 'Leisure Time', 'Office Hours', 'Workout Session']) ax.set_xticklabels(music_lis_frequency_premium_pct.index) # x축 라벨을 정렬된 순서로 변경 ★ # 범례 표시 ax.legend() # 그래프 출력 plt.show()
📌 5일차
📌 프로젝트 정리, 발표 자료 제작
- 공식적인 회의만 13회차..


📌 6일차 (최종)
📌 프로젝트 발표
- 발표 후
전 튜터님 피드백
스포티파이 서비스 설명한 부분
주요 수익모델 설명한 부분
- 분석 기획을 할 때, 논리적인 접근을 하게끔 연결고리가 되었다.
이상치 결측치 처리 부분
- 인코딩 기법에 대한 이해를 잘 한 것 같다.
시각화 관련
- 방향성에 알맞게 시각화가 잘 되었다.
- 그래프에 값이 표시됐다면 더 좋았겠다.
고생의 흔적이 보였다. 고생 많이 하셨다.
시각화 관련해서 색깔에 대한 피드백은 거르자!
(일단 디자인보다는 분석에 집중하자는 의미)정 튜터님 피드백
좋았던 점
- kaggle 데이터 외 스포티파이 수익구조 확인(분기별 재무제표 etc) 탐색
- 비지니스 측면의 과정
- 데이터전처리 과정과 자세한 분석 설명, 구체적인 분석 플로우
- 구체적인 마케팅 전략 소개
개선하면 좋을 점
- 음악 감상의 경우, '빈도'(count)보다 '비율'(rate)이 더 의미 있지 않을지?
- 수익구조 개선을 위한 컨텐츠 강화 외 솔루션 부재SELECT 1 (1조)
다들 고생 많으셨습니다!
