
WHAT IS KATA?
KATA는 기술과 기술 향상에 초점을 맞춘 코드 챌린지입니다.
일부는 프로그래밍 기본 사항을 교육하는 반면 다른 일부는 복잡한 문제 해결에 중점을 둡니다.
이 용어는 The Pragmatic Programmer 라는 책의 공동 저자인 Dave Thomas 가
무술에서 일본의 카타 개념을 인정하면서 처음 만들어졌습니다.
Dave의 개념 버전은 코드 카타를 프로그래머가
연습과 반복을 통해 기술을 연마하는 데 도움이 되는 프로그래밍 연습으로 정의합니다.
- SQL
✔️ 문제 #1: Customer Who Visited but Did Not Make Any Transactions
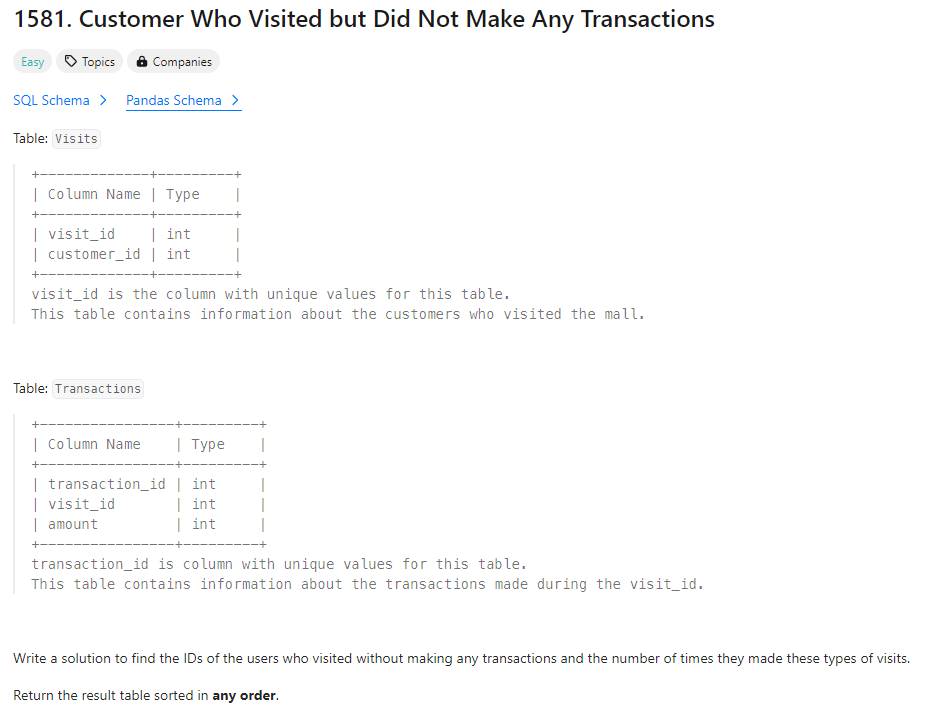
✔️ 제출 쿼리
✔️ 쿼리 분석
SELECT v.customer_id,
COUNT(*) count_no_trans
FROM Visits v LEFT JOIN Transactions t
ON v.visit_id = t.visit_id
WHERE t.transaction_id IS NULL
GROUP BY v.customer_id
✔️ 문제 #2: Rising Temperature
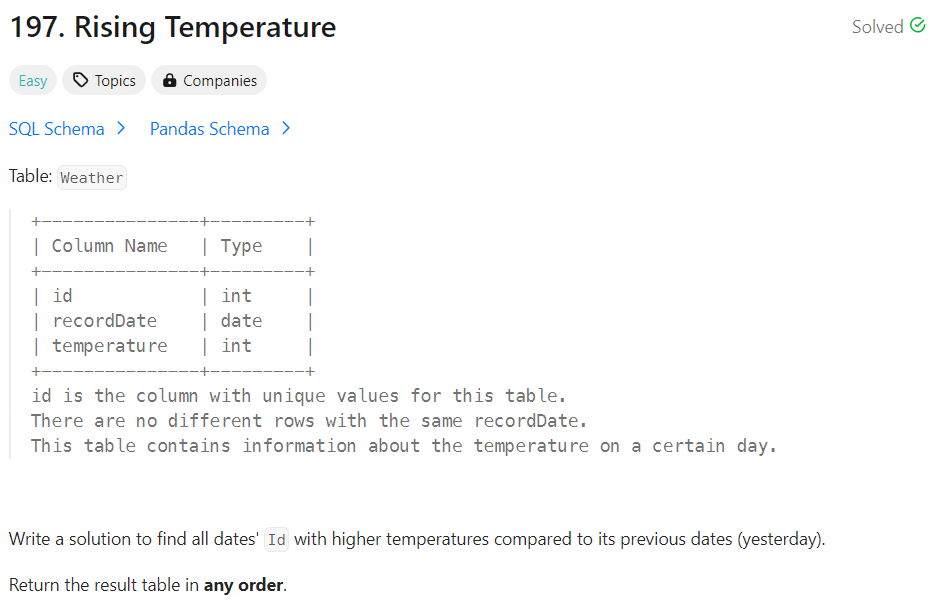
✔️ 제출 쿼리
✔️ 쿼리 분석
#1 (Self-Join) :
같은 테이블을 두 번 참조하여 서로 다른 레코드를 비교하는 쿼리
Weather 테이블을 w1과 w2로 두 번 불러와 조인 후 데이터 비교
#2 (DATEDIFF, 시작값(큰 날짜), 끝값(작은 날짜)) :
WHERE절에 DATEDIFF 함수로 날짜의 차이가 1이고,
다음날이 전날보다 온도가 높은 경우의 값만 조회
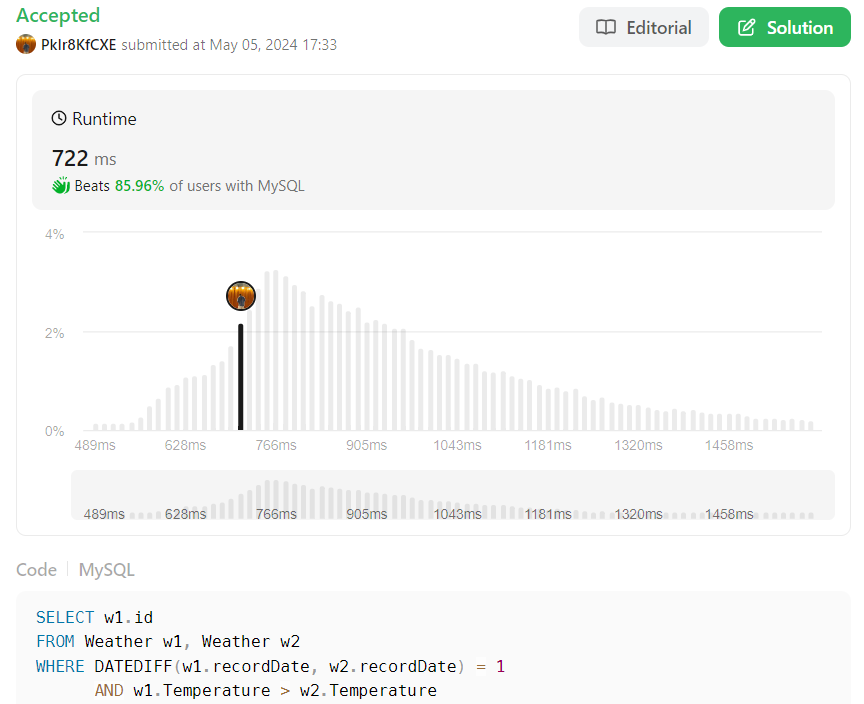
SELECT w1.id
FROM Weather w1, Weather w2 - #1
WHERE DATEDIFF(w1.recordDate, w2.recordDate) = 1 - #2
AND w1.Temperature > w2.Temperature
✔️ 문제 #3: Average Time of Process per Machine
✔️ 제출 쿼리
✔️ 쿼리 분석
#1 ROUND(AVG(큰값 - 작은값),3) :
a2 테이블 timestamp는 activity_type이 end인 경우로 큰값 조회,
a1 테이블 timestamp는 activity_type이 start인 경우로 작은값 조회
값들의 차이의 평균을 소수점 3번째 자리까지만 표현하는 쿼리
#2 (Self-Join) :
Activity 테이블을 a1과 a2로 두 번 불러와 조인 후 데이터 비교
#3 :
WHERE 절을 통해 두 테이블의 machine_id와 process_id 가 같고,
a1 테이블의 activity_type이 start이며,
a2 테이블의 activity_type이 end 인 경우의 값들만 조회
#4 :
모든 데이터를 machine_id 기준으로 그룹화
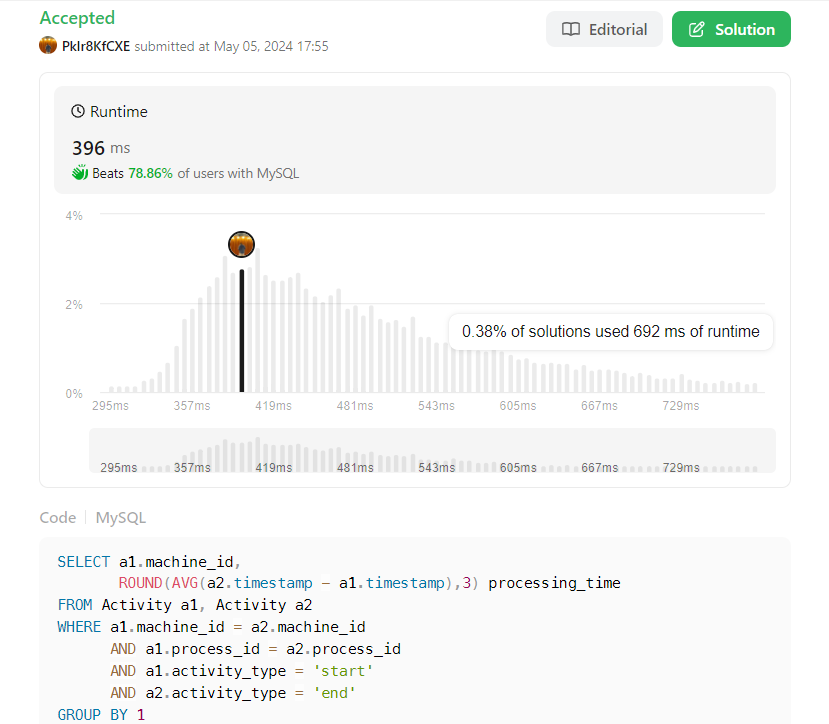
SELECT a1.machine_id,
ROUND(AVG(a2.timestamp - a1.timestamp),3) processing_time - #1
FROM Activity a1, Activity a2 - #2
WHERE a1.machine_id = a2.machine_id - #3
AND a1.process_id = a2.process_id
AND a1.activity_type = 'start'
AND a2.activity_type = 'end'
GROUP BY 1 - #4
- PYTHON
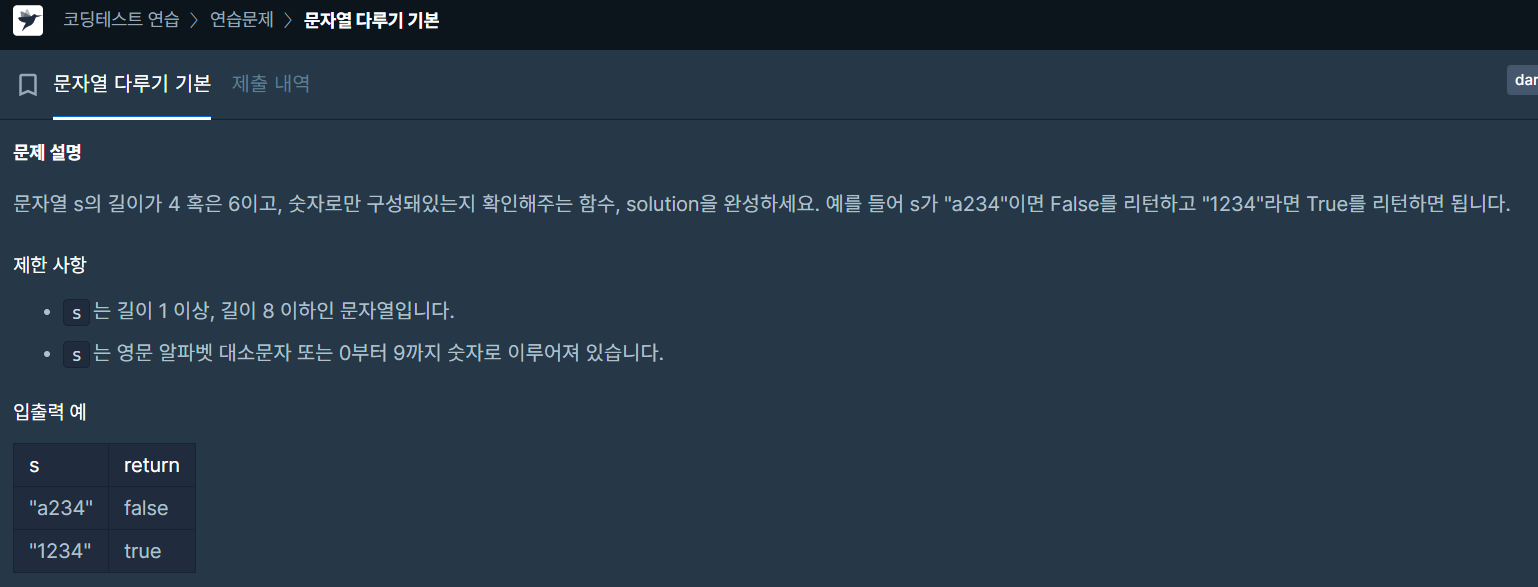
✔️ 문제 #1: 문자열 다루기 기본
✔️ 제출 코드
✔️ 코드 분석
def solution(s):
if (len(s) == 4 and s.isdigit()) :
return True
elif (len(s) == 6 and s.isdigit()) :
return True
return False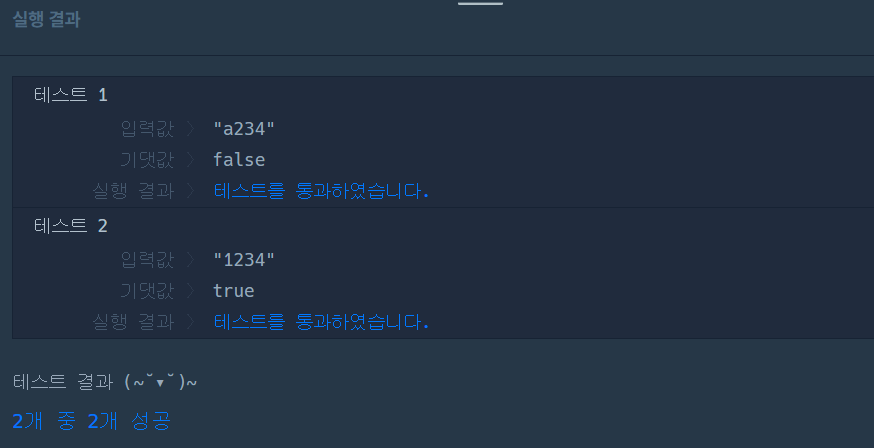
✔️ 문제 #2: 행렬의 덧셈
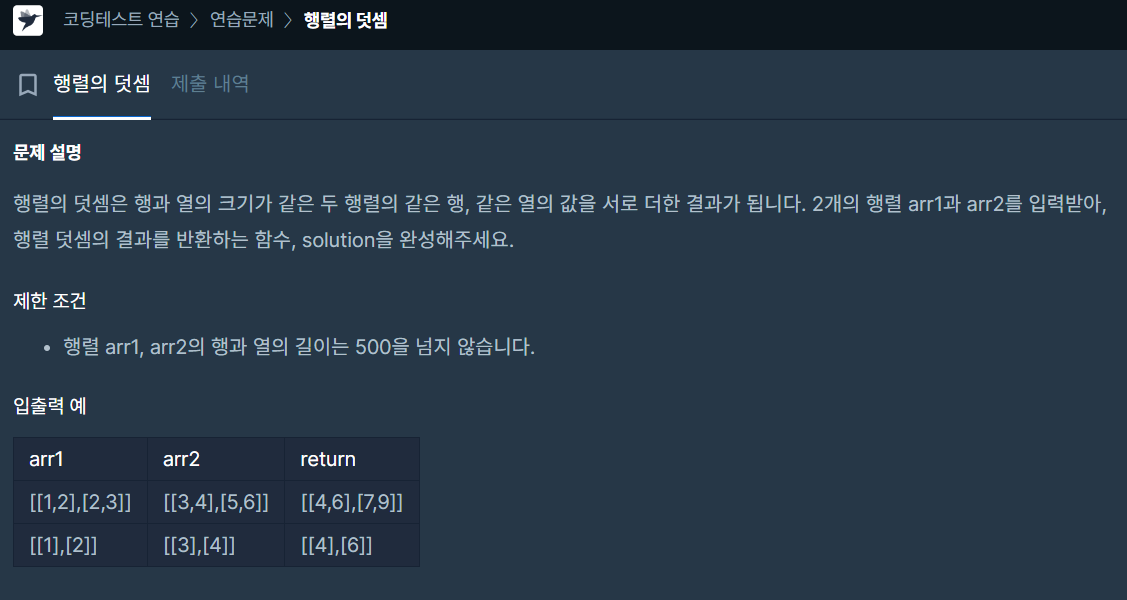
✔️ 제출 코드
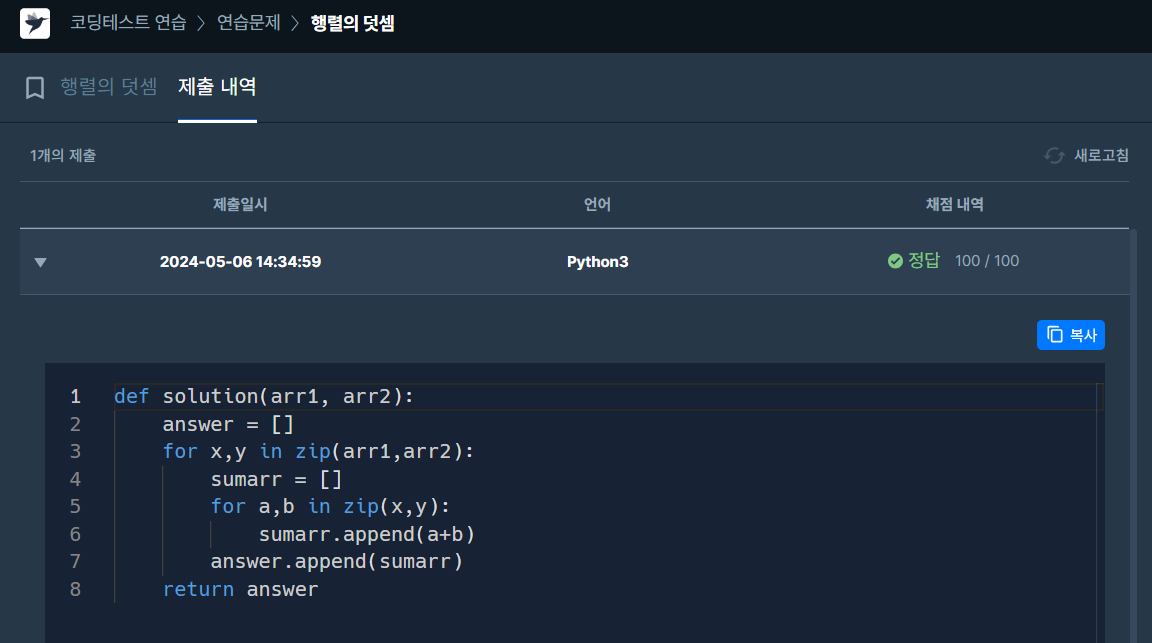
✔️ 코드 분석
def solution(arr1, arr2):
answer = [] # 최종 결과 리스트
for x,y in zip(arr1,arr2):
# arr1, arr2 같은 위치의 원소들을 더하기 위해 zip() 함수 사용
# x = [1,2], y = [3,4] / x = [2,3], y = [5,6]
sumarr = [] # 현재 행 리스트
for a,b in zip(x,y):
sumarr.append(a+b)
# 현재 행 같은 위치의 원소들을 더해서 sumarr 리스트에 추가
# a = 1, b = 3 / a = 2, b = 4 //
a = 2, b = 5 / a = 3, b = 6
answer.append(sumarr)
# 현재 행의 sumarr 리스트를 answer 리스트에 추가
# [4,6], [7,9]
return answer 
✔️ CHECK POINT
-
SQL
- SELF JOIN
1개의 테이블(A)에 가상으로 A1, A2라는 별칭을 부여하여
2개의 테이블인 것처럼 간주한 뒤 JOIN하는 것.
1개의 컬럼 내에 섞여있는 여러 레코드들을 다른 컬럼을 통해서 위계 또는 관계를 알 수 있는 모습으로 조회할 수 있다. - 표현식
SELECT A1.컬럼1, A1.컬럼2, A2.컬럼3, ... FROM 테이블A A1, 테이블A A2 WHERE A1.컬럼1 = A2.컬럼1 ;
- SELF JOIN
-
PYTHON
- 문자열이 숫자인지 문자인지 판별하는 메서드
문자열이 숫자인지 ?str.isdigit()
문자열이 숫자를 나타내는 문자인지 ?str.isnumeric()
문자열이 알파벳인지 ?str.isalpha()
문자열이 영숫자인지 ?str.isalnum()
. - STRING METHODS 참고

- 문자열이 숫자인지 문자인지 판별하는 메서드

커피 좋아하는 데이터 꿈나무