
WHAT IS KATA?
KATA는 기술과 기술 향상에 초점을 맞춘 코드 챌린지입니다.
일부는 프로그래밍 기본 사항을 교육하는 반면 다른 일부는 복잡한 문제 해결에 중점을 둡니다.
이 용어는 The Pragmatic Programmer 라는 책의 공동 저자인 Dave Thomas 가
무술에서 일본의 카타 개념을 인정하면서 처음 만들어졌습니다.
Dave의 개념 버전은 코드 카타를 프로그래머가
연습과 반복을 통해 기술을 연마하는 데 도움이 되는 프로그래밍 연습으로 정의합니다.
- SQL
✔️ 문제 #1: Top Earners

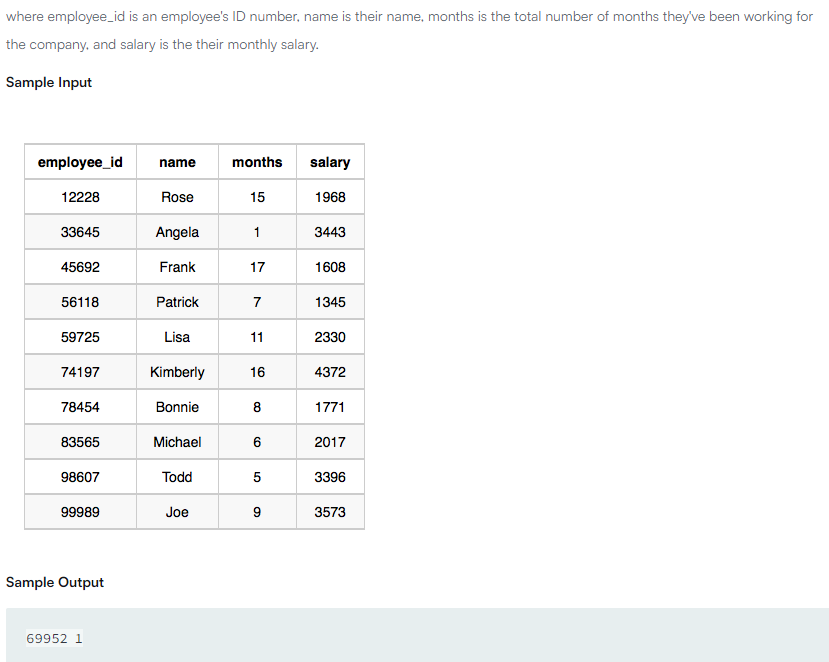
✔️ 제출 쿼리
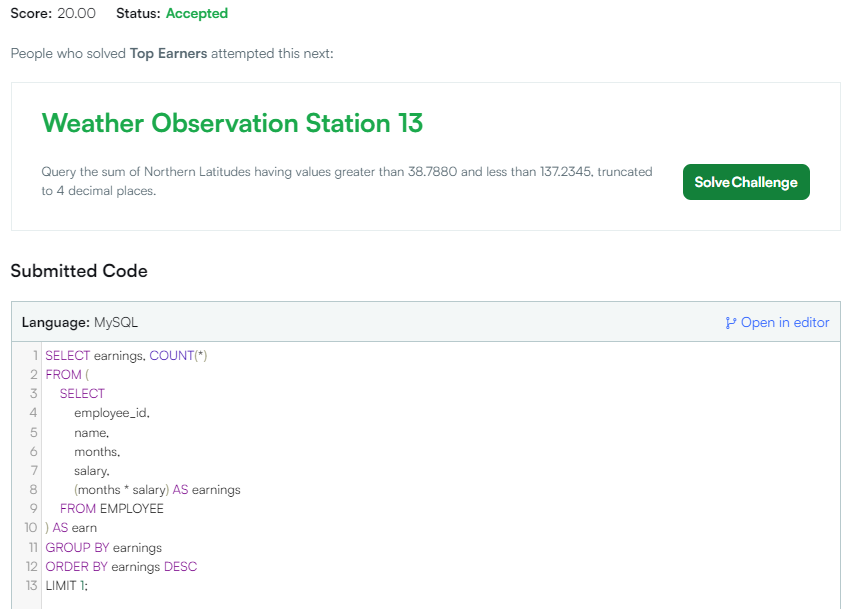
✔️ 쿼리 분석
SELECT earnings, COUNT(*)
FROM (
SELECT employee_id
, name
, months
, salary
, (months * salary) earnings
FROM EMPLOYEE
) AS earn
GROUP BY earnings
ORDER BY earnings DESC
LIMIT 1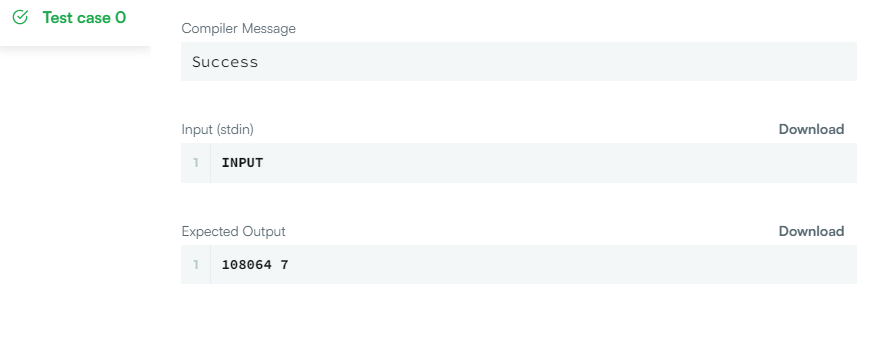
- PYTHON
✔️ 문제 #1: 타겟 넘버
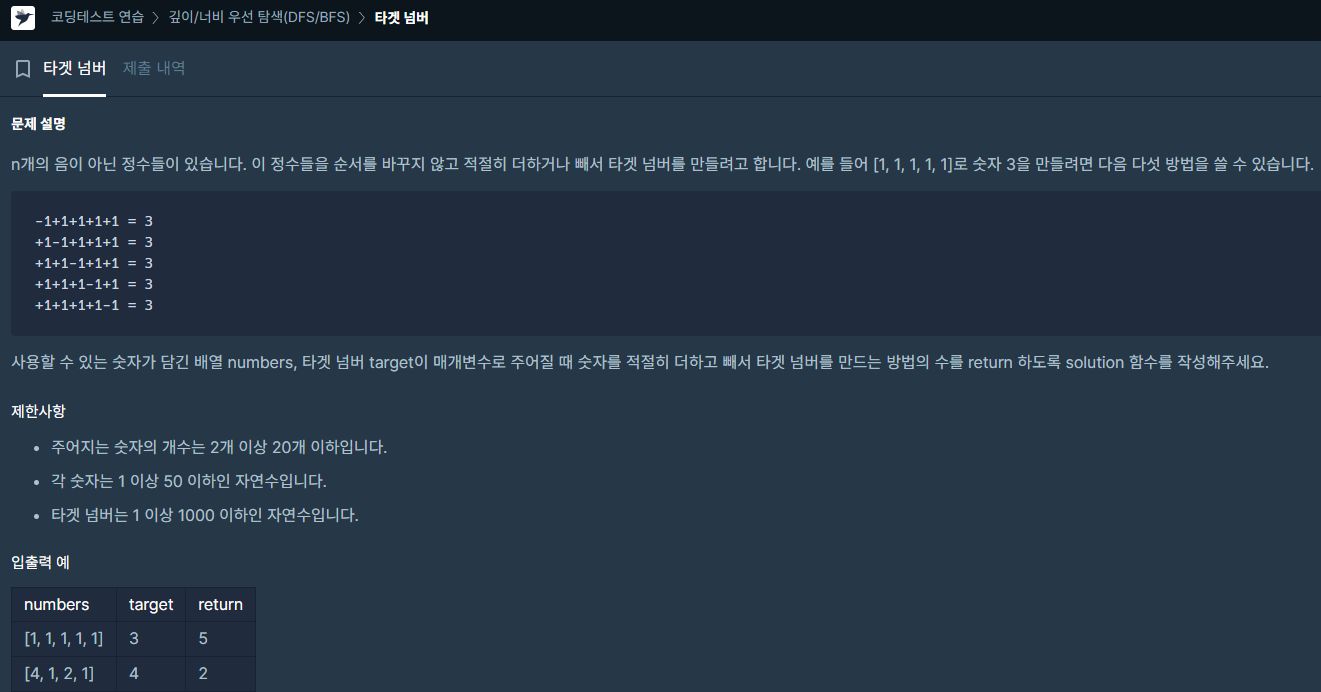
✔️ 제출 코드
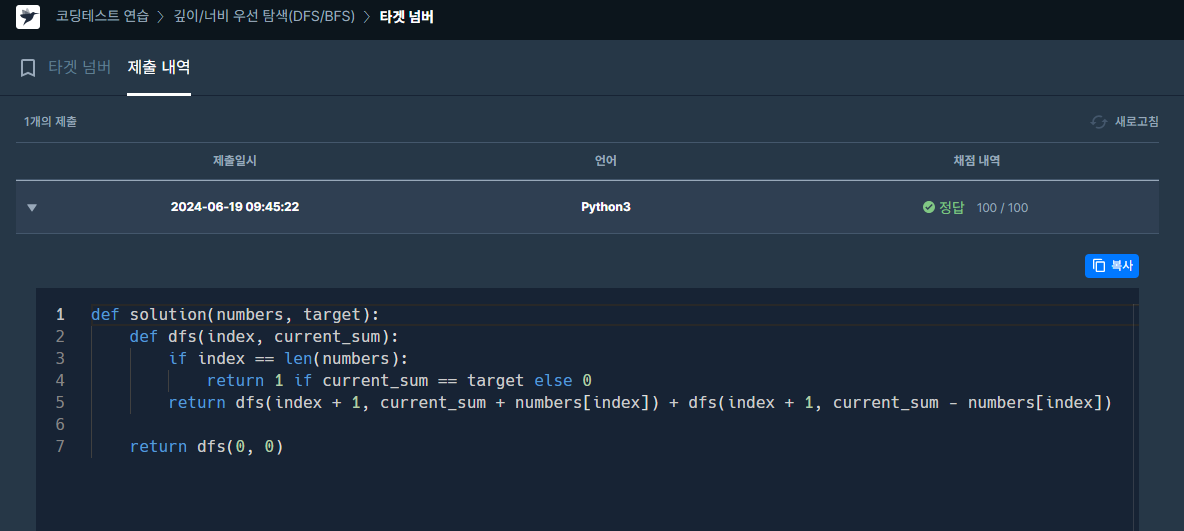
✔️ 코드 분석
def solution(numbers, target):
# dfs 함수 정의
def dfs(index, current_sum):
# 모든 숫자를 다 사용했을 때
if index == len(numbers):
# 현재 합이 타겟 넘버와 일치하면 1을 반환하고, 그렇지 않으면 0을 반환
return 1 if current_sum == target else 0
# 현재 숫자를 더하거나 빼는 두 가지 경우를 재귀적으로 탐색
# index + 1은 다음 숫자로 이동, current_sum + numbers[index]는 현재 숫자를 더하는 경우
# current_sum - numbers[index]는 현재 숫자를 빼는 경우
return dfs(index + 1, current_sum + numbers[index]) + dfs(index + 1, current_sum - numbers[index])
# dfs 탐색 시작: 인덱스 0부터 시작하고 초기 합은 0
return dfs(0, 0)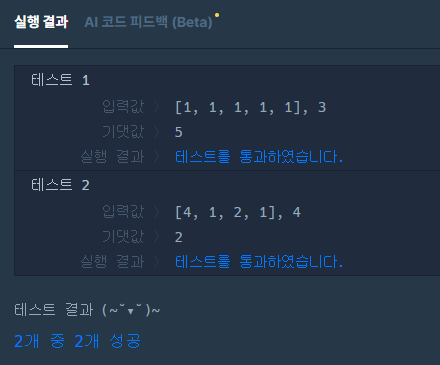
+)
예제 : solution([1, 1, 1, 1, 1], 3)
시작: index=0, current_sum=0
첫 번째 숫자 1을 더하거나 빼는 두 가지 경우:
dfs(1, 1) (더하는 경우)
dfs(1, -1) (빼는 경우)
각각의 경우에 대해 두 번째 숫자 1을 더하거나 빼는 두 가지 경우:
dfs(2, 2), dfs(2, 0) (더하는 경우의 결과)
dfs(2, 0), dfs(2, -2) (빼는 경우의 결과)
이 과정을 계속해서 모든 숫자에 대해 반복
최종적으로, current_sum이 3이 되는 모든 경우의 수를 세어 반환합니다.✔️ CHECK POINT
-
SQL
- MySQL의 8.0 이하 버전에서는 WITH 절을 활용한 CTE 생성이 불가능하다..
WITH 절로 가독성 있고 간단하게 쿼리 작성이 가능한 것을
인라인 뷰(서브쿼리)로 작성하려니 헷갈렸었다.SELECT earnings, COUNT(*) FROM ( SELECT employee_id , name , months , salary , (months * salary) earnings FROM EMPLOYEE ) AS earn GROUP BY earnings ORDER BY earnings DESC LIMIT 1
- MySQL의 8.0 이하 버전에서는 WITH 절을 활용한 CTE 생성이 불가능하다..
-
PYTHON
-
DFS (Depth-First Search) : 깊이 우선 탐색
가능한 깊이까지 탐색한 후에 다시 돌아와서 다음 경로를 탐색한다.
깊이 있는 부분을 먼저 탐색하는 함수 -
특징
-
재귀적 구현:
스택 자료 구조 사용 -
메모리 사용량:
방문한 정점과 경로를 저장하기 위해 최대 O(V)의 공간이 필요 (V ; 정점의 수) -
완전성:
모든 경로를 탐색할 수 있다. -
적용:
미로 찾기, 퍼즐 풀이, 경로 찾기 등.
-
def solution(numbers, target):
# dfs 함수 정의
def dfs(index, current_sum):
# 모든 숫자를 다 사용했을 때
if index == len(numbers):
# 현재 합이 타겟 넘버와 일치하면 1을 반환하고, 그렇지 않으면 0을 반환
return 1 if current_sum == target else 0
# 현재 숫자를 더하거나 빼는 두 가지 경우를 재귀적으로 탐색
# index + 1은 다음 숫자로 이동, current_sum + numbers[index]는 현재 숫자를 더하는 경우
# current_sum - numbers[index]는 현재 숫자를 빼는 경우
return dfs(index + 1, current_sum + numbers[index]) + dfs(index + 1, current_sum - numbers[index])
# dfs 탐색 시작: 인덱스 0부터 시작하고 초기 합은 0
return dfs(0, 0)
커피 좋아하는 데이터 꿈나무