
개요
머신러닝의 이해 + 라이브러리를 정리하고 익히는 것이 목표
📌 문제 공통 사항
- 1 ~ 3번 문제는 basic 문제이며,
특별한 전처리 과정(결측값 처리, 범주형 값 처리, scailing 등)을 필요로 하지 않습니다.
데이터를 불러오고, test 데이터를 분리할 수 있으며,
모델을 가져와서 학습을 하고 예측 및 평가를 진행하는 것을 물어보는 문제입니다.
- 4 ~ 6번 문제는 challenge 문제이며,
특별한 전처리과정이 필요할 수도 있습니다!
필요한 경우 수행하세요!
- train_test split 함수나 모든 머신러닝은 random seed로 인해
성능의 영향을 받을 수 있기 때문에 random_state는 42로 고정하여 사용하세요!
(이외에도 혹시나 본인이 추가적으로 사용하고 싶은 함수 중
random seed와 관련 있는 경우에는 random_state를 42로 고정하세요)
- train 데이터와 test 데이터의 비율을 7:3으로 나누세요.
- 편의를 위해 validation 데이터는 별도로 두지 않겠습니다.
test 데이터로 머신러닝 모델을 평가하세요.
📌 문제 1
Iris 데이터셋에서 Logistic Regression 분류
-
Iris 데이터셋을 사용하여 Logistic Regression 모델을 학습시키고, 정확도(accuracy)를 계산하세요
-
아래와 같이 데이터를 불러오세요
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target-
(Hint!) 데이터를 불러오고, test 데이터를 분리하며, 모델을 학습시키고, 예측 및 정확도를 계산하세요!
-
(Hint!) sklearn의 train_test_split를 이용하면 편하게 데이터를 분리할 수 있습니다.
-
(Hint!) sklearn의 accuracy_score를 이용하면 편하게 accuracy를 계산할 수 있습니다.
# 라이브러리 불러오기 import sklearn import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns

# 데이터 불러오기 from sklearn.datasets import load_iris iris = load_iris() X, y = iris.data, iris.target

# 데이터 확인 print(X.shape, y.shape) # 데이터 프레임 변환 후 확인 iris_df = pd.DataFrame(X, columns = iris.feature_names) iris_df['target'] = y iris_df.head()
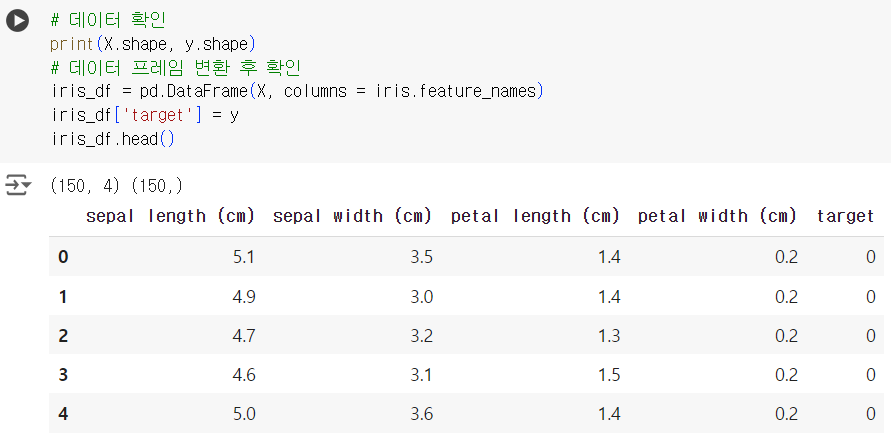
# 데이터 분리하기 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42) # 모델 불러오기 & 학습 (LogisticRegression) from sklearn.linear_model import LogisticRegression lor = LogisticRegression(max_iter = 300) lor.fit(X_train, y_train) # 예측하기 y_pred = lor.predict(X_test) # Accuracy_score 확인 from sklearn.metrics import accuracy_score print(accuracy_score(y_test, y_pred)) # accuracy_score = 1.0
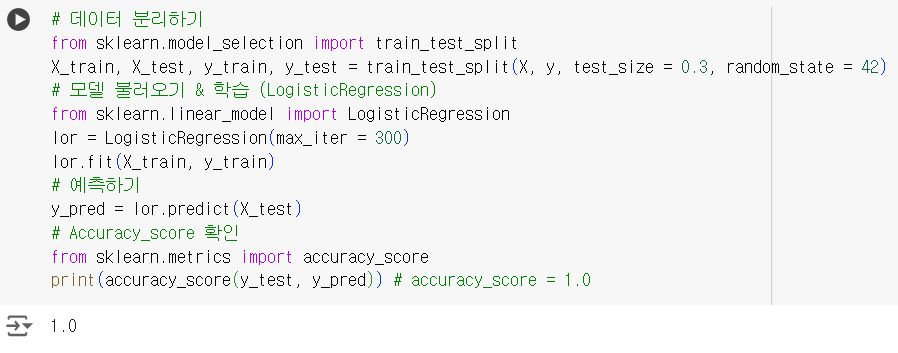
- 제출 코드
# 라이브러리 불러오기
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 불러오기
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target
# 데이터 확인
# print(X.shape, y.shape)
# 데이터 프레임 변환 후 확인
iris_df = pd.DataFrame(X, columns = iris.feature_names)
iris_df['target'] = y
iris_df.head()
# 데이터 분리하기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)
# 모델 불러오기 & 학습 (LogisticRegression)
from sklearn.linear_model import LogisticRegression
lor = LogisticRegression(random_state = 42, max_iter = 300)
lor.fit(X_train, y_train)
# 예측하기
y_pred = lor.predict(X_test)
# Accuracy_score 확인
from sklearn.metrics import accuracy_score
print('\n', '정답! Accuracy_score =', accuracy_score(y_test, y_pred)) # accuracy_score = 1.0📌 문제 2
주택 가격 Linear Regression 예측
-
주택 가격 데이터셋을 사용하여 주택 가격을 예측하는 회귀 모델을 만드세요.
-
Linear Regeression을 사용하세요
-
MSE로 성능을 평가하세요
-
아래와 같이 데이터를 불러오세요
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
X, y = housing['data'], housing['target']-
(Hint!) 데이터를 불러오고, test데이터를 분리하며, 모델을 학습시키고, 예측 및 오차를 계산하세요!
-
(Hint!) sklearn의 train_test_split를 이용하면 편하게 데이터를 분리할 수 있습니다.
-
(Hint!) sklearn의 mean_squared_error를 이용하면 편하게 MSE를 계산할 수 있습니다.
# 라이브러리 불러오기 import sklearn import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns

# 데이터 불러오기 from sklearn.datasets import fetch_california_housing housing = fetch_california_housing() X, y = housing['data'], housing['target']

# 데이터 확인 print(X.shape, y.shape) # 데이터 프레임 변환 후 확인 housing_df = pd.DataFrame(X, columns = housing.feature_names) housing_df['target'] = y housing_df.head()
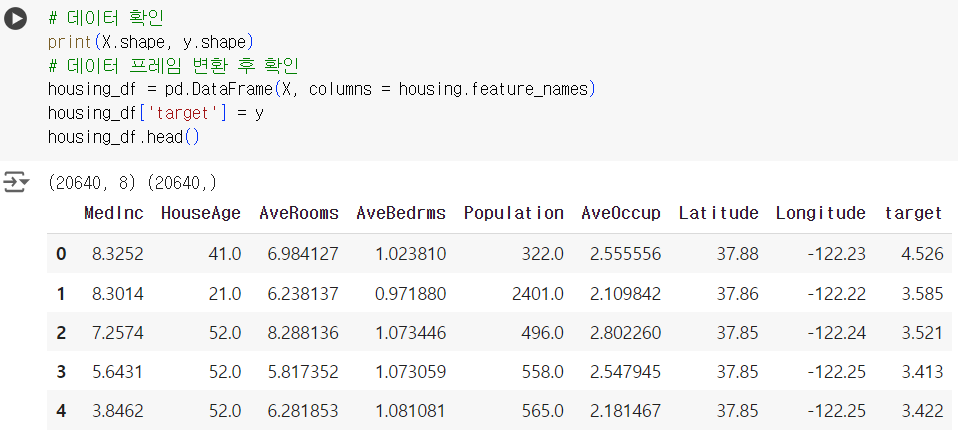
# 데이터 분리 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42) # 모델 불러오기 & 학습 (Linear Regeression) from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(X_train, y_train) # 예측하기 y_pred = lr.predict(X_test) # MSE 평가 from sklearn.metrics import mean_squared_error print(mean_squared_error(y_test, y_pred).round(3)) # MSE = 0.531

- 제출 코드
# 라이브러리 불러오기
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 불러오기
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
X, y = housing['data'], housing['target']
# 데이터 확인
# print(X.shape, y.shape)
# 데이터 프레임 변환 후 확인
housing_df = pd.DataFrame(X, columns = housing.feature_names)
housing_df['target'] = y
housing_df.head()
# 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)
# 모델 불러오기 & 학습 (Linear Regeression)
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
# 예측하기
y_pred = lr.predict(X_test)
# MSE 평가
from sklearn.metrics import mean_squared_error
print('\n', '정답! MSE =', mean_squared_error(y_test, y_pred).round(3)) # MSE = 0.531📌 문제 3
iris 데이터 DecisionTree로 분류
-
Iris 데이터셋을 사용하여 DecisionTree 모델을 학습시키고, 정확도(accuracy)를 계산하세요
-
데이터는 1번문제의 데이터를 활용하세요
# 라이브러리 불러오기 import sklearn import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns

# 데이터 불러오기 from sklearn.datasets import load_iris iris = load_iris() X, y = iris.data, iris.target

# 데이터 확인 print(X.shape, y.shape) # 데이터 프레임 변환 후 확인 iris_df = pd.DataFrame(X, columns = iris.feature_names) iris_df['target'] = y iris_df.head()
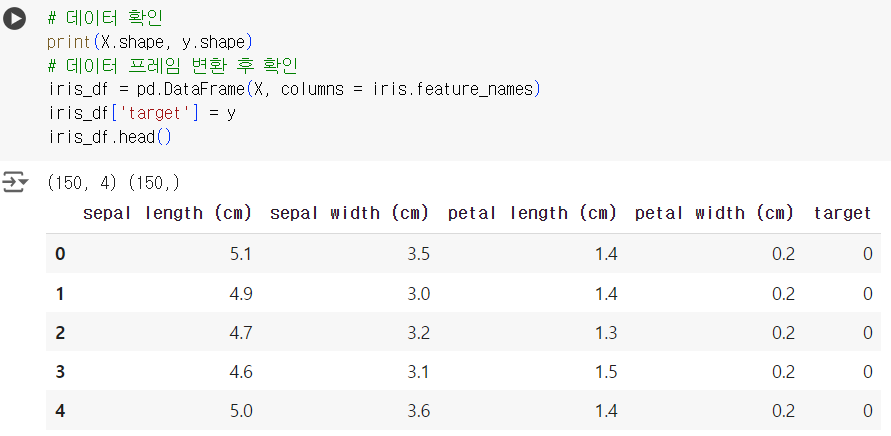
# 데이터 분리하기 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42) # 모델 불러오기 & 학습 (DecisionTreeClassifier) from sklearn.tree import DecisionTreeClassifier dtc = DecisionTreeClassifier(random_state = 42) dtc.fit(X_train, y_train) # 예측하기 y_pred = dtc.predict(X_test) # Accuracy_score 확인 from sklearn.metrics import accuracy_score print(accuracy_score(y_test, y_pred)) # accuracy_score = 1.0

📌 문제 4
타이타닉 데이터 랜덤포레스트 분류기로 생존여부 예측
- 데이터는 아래와 같이 불러오세요
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
titanic = pd.read_csv(url)- 데이터의 특성 중 다음 특성들만 사용하세요
"Pclass", "Sex", "Age", "SibSp", "Parch", "Fare"
- 성능은 accuracy로 평가하세요
# 라이브러리 불러오기 import sklearn import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns

# 데이터 불러오기 url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv" titanic = pd.read_csv(url)

# 특성 골라서 X, y 나누기 cols = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare"] X = titanic[cols] y = titanic['Survived']

# 데이터 확인 print(X.shape, y.shape) print(X.head(3)) print(y.head(3))
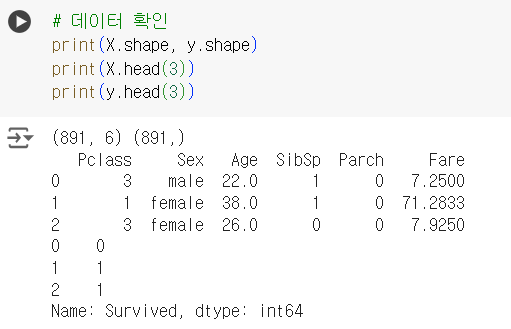
# 결측치 확인 X.info() print('\n') y.info()

# 결측치 평균값 대치 age_mean = X['Age'].mean().round(2) X.loc[:, 'Age'] = X['Age'].fillna(age_mean) X.info()

# 범주형 데이터 인코딩 (LabelEncoder) from sklearn.preprocessing import LabelEncoder le = LabelEncoder() X.loc[:, 'Sex'] = le.fit_transform(X['Sex'])

# 데이터 분리 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42) # 모델 불러오기 & 학습 (RandomForestClassifier) from sklearn.ensemble import RandomForestClassifier rfc = RandomForestClassifier(random_state = 42) rfc.fit(X_train, y_train) # 예측하기 y_pred = rfc.predict(X_test) # Accuracy_score 확인 from sklearn.metrics import accuracy_score print(accuracy_score(y_test, y_pred).round(3)) # Accuracy_score = 0.802

- 제출 코드
# 라이브러리 불러오기
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 불러오기
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
titanic = pd.read_csv(url)
# 특성 골라서 X, y 나누기
cols = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare"]
X = titanic[cols]
y = titanic['Survived']
# 데이터 확인
# print(X.shape, y.shape)
# print(X.head(3))
# print(y.head(3))
# 결측치 확인
# X.info()
# print('\n')
# y.info()
# 결측치 평균값 대치
age_mean = X['Age'].mean().round(2)
X.loc[:, 'Age'] = X['Age'].fillna(age_mean)
# X.info()
# 범주형 데이터 인코딩 (LabelEncoder)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
X.loc[:, 'Sex'] = le.fit_transform(X['Sex'])
# 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)
# 모델 불러오기 & 학습 (RandomForestClassifier)
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier(random_state = 42)
rfc.fit(X_train, y_train)
# 예측하기
y_pred = rfc.predict(X_test)
# Accuracy_score 확인
from sklearn.metrics import accuracy_score
print('\n', '정답! Accuracy_score =', accuracy_score(y_test, y_pred).round(3)) # Accuracy_score = 0.802📌 문제 5
iris 데이터를 이용하여 클러스터링을 수행하고 시각화
-
데이터는 1번 문제 처럼 iris 데이터를 불러오면 됩니다
-
클러스터의 개수는 3개로 설정하세요
-
클러스터의 결과를 시각화 하기 위해 데이터의 첫번째 특성을 X축, 두번째 특성을 Y축으로 하는 산점도(scatter) 그리세요! 이때, 클러스터에 따라 색깔이 구분되게 하세요!
-
(물론, 클러스터를 수행할 때는 모든 특성을 다 사용하세요)
# 라이브러리 불러오기 import sklearn import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns

# 데이터 불러오기 from sklearn.datasets import load_iris iris = load_iris() X, y = iris.data, iris.target

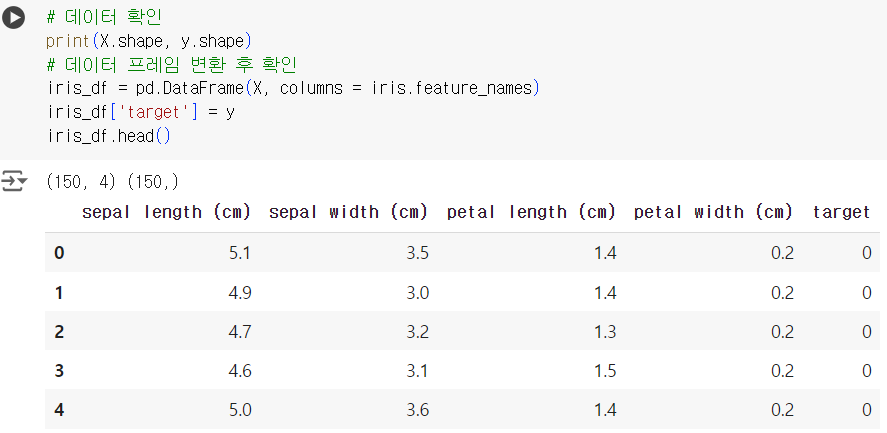
# 데이터 확인 print(X.shape, y.shape) # 데이터 프레임 변환 후 확인 iris_df = pd.DataFrame(X, columns = iris.feature_names) iris_df['target'] = y iris_df.head()
# 결측치 확인 = 없음 iris_df.isnull().sum()

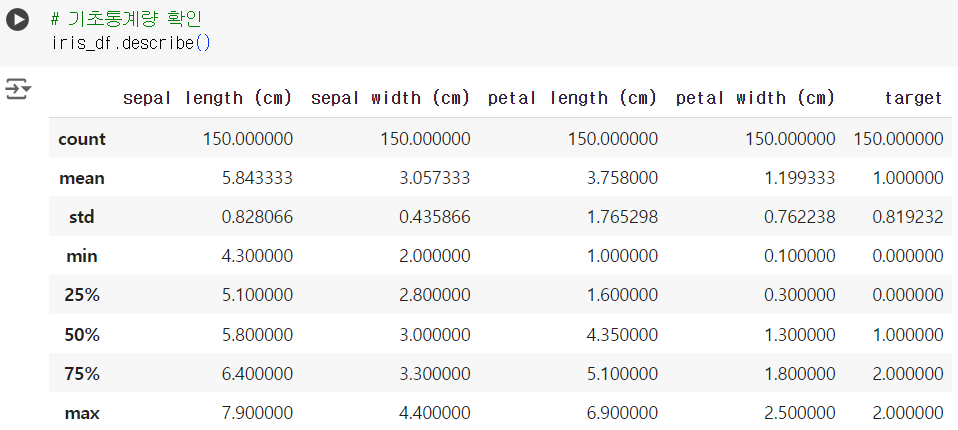
# 기초통계량 확인 iris_df.describe()
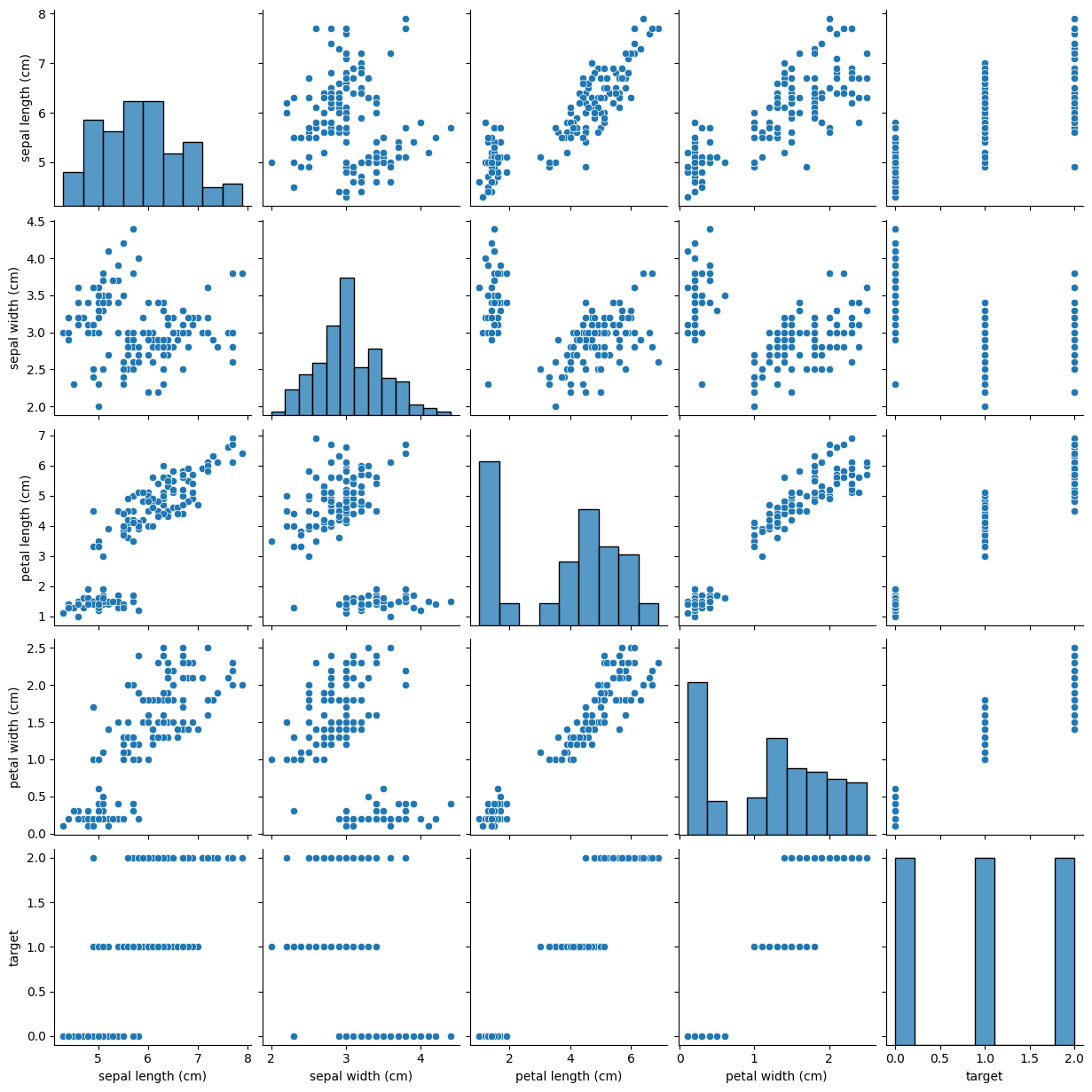
# pairplot 시각화 sns.pairplot(iris_df)

# Z - score 계산 from scipy.stats import zscore z_scores = np.abs(zscore(iris_df)) z_scores
# Z - score 가 3 초과인 데이터(이상치) 확인 outliers = np.where(z_scores > 3) print(outliers) print(len(outliers[0])) # 이상치 제거 iris_df_cleaned = iris_df[(z_scores < 3).all(axis = 1)] iris_df_cleaned

# 표준화 진행 from sklearn.preprocessing import StandardScaler st_sc = StandardScaler() iris_df_2 = st_sc.fit_transform(iris_df_cleaned) iris_df_2
# PCA 적용 from sklearn.decomposition import PCA pca = PCA(n_components = 2) pca1 = pca.fit_transform(iris_df_2) print(pca.explained_variance_ratio_)

# K-Means 수행 (k 값은 3) from sklearn.cluster import KMeans kmeans = KMeans(n_clusters = 3, random_state = 42, n_init = 10) kmeans.fit(iris_df_2) labels = kmeans.labels_ labels

# 군집화 결과를 데이터에 추가 iris_df_cleaned.loc[:, 'pca_1'] = pca1[:, 0] iris_df_cleaned.loc[:, 'pca_2'] = pca1[:, 1] iris_df_cleaned.loc[:, 'cluster'] = labels iris_df_cleaned

# 시각화 sns.scatterplot(x='pca_1', y='pca_2', hue='cluster', data=iris_df_cleaned) plt.xlabel('PCA 1') plt.ylabel('PCA 2') plt.title('KMeans Clustering of Iris Data') plt.show()
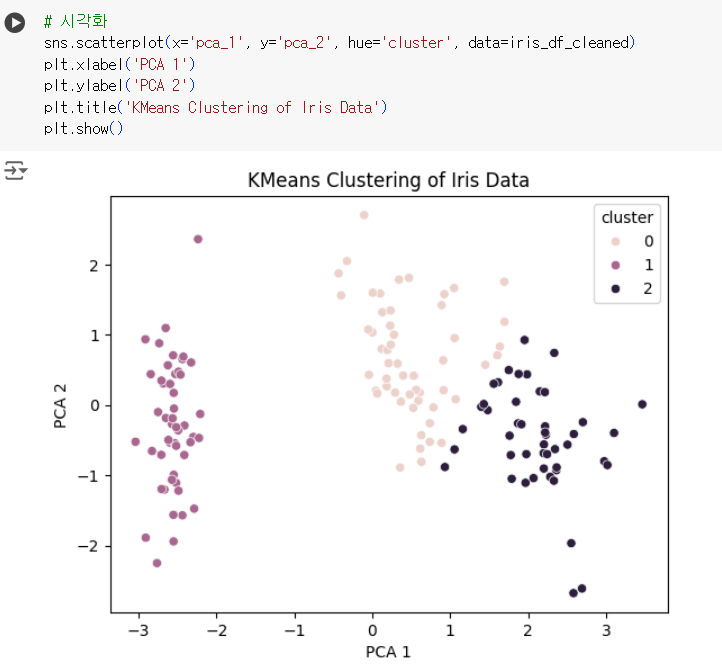
- 제출 코드
# 라이브러리 불러오기
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 불러오기
from sklearn.datasets import load_iris
iris = load_iris()
X, y = iris.data, iris.target
# 데이터 확인
# print(X.shape, y.shape)
# 데이터 프레임 변환 후 확인
iris_df = pd.DataFrame(X, columns = iris.feature_names)
iris_df['target'] = y
iris_df.head()
# 결측치 확인 = 없음
iris_df.isnull().sum()
# 기초통계량 확인
iris_df.describe()
# pairplot 시각화
# sns.pairplot(iris_df)
# Z - score 계산
from scipy.stats import zscore
z_scores = np.abs(zscore(iris_df))
z_scores
# Z - score 가 3 초과인 데이터(이상치) 확인
outliers = np.where(z_scores > 3)
# print(outliers)
# print(len(outliers[0]))
# 이상치 제거
iris_df_cleaned = iris_df[(z_scores < 3).all(axis = 1)].copy()
iris_df_cleaned
# 표준화 진행
from sklearn.preprocessing import StandardScaler
st_sc = StandardScaler()
iris_df_2 = st_sc.fit_transform(iris_df_cleaned)
iris_df_2
# PCA 적용
from sklearn.decomposition import PCA
pca = PCA(n_components = 2)
pca1 = pca.fit_transform(iris_df_2)
# print(pca.explained_variance_ratio_)
# K-Means 수행 (k 값은 3)
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, random_state = 42, n_init = 10)
kmeans.fit(iris_df_2)
labels = kmeans.labels_
labels
# 군집화 결과를 데이터에 추가
iris_df_cleaned.loc[:, 'pca_1'] = pca1[:, 0]
iris_df_cleaned.loc[:, 'pca_2'] = pca1[:, 1]
iris_df_cleaned.loc[:, 'cluster'] = labels
iris_df_cleaned
# 시각화
sns.scatterplot(x='pca_1', y='pca_2', hue='cluster', data=iris_df_cleaned)
plt.xlabel('PCA 1')
plt.ylabel('PCA 2')
plt.title('KMeans Clustering of Iris Data')
plt.show()📌 문제 6
딥러닝을 이용하여 MNIST 데이터 분류
- 데이터는 아래와 같이 불러오세요
from tensorflow.keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()-
본인만의 신경망을 구축하세요 (어떤 신경망이든 상관 없습니다)
-
tensorflow를 사용하든, pytorch를 사용하든 딥러닝 framework는 무엇을 사용하든 상관 없습니다
-
학습하고 정확도(accuracy)를 계산하세요
실패..ㅋㅋ
# 라이브러리 불러오기
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# tensorflow 설치
# !pip install --upgrade pip --user
# !pip install tensorflow
# 데이터 불러오기
from tensorflow.keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()