
개요
개인 과제 해설 요약
+) 문제 6 : 딥러닝 코드를 자세하게 설명해주셔서 이해가 잘 되었다.
📌 문제 1
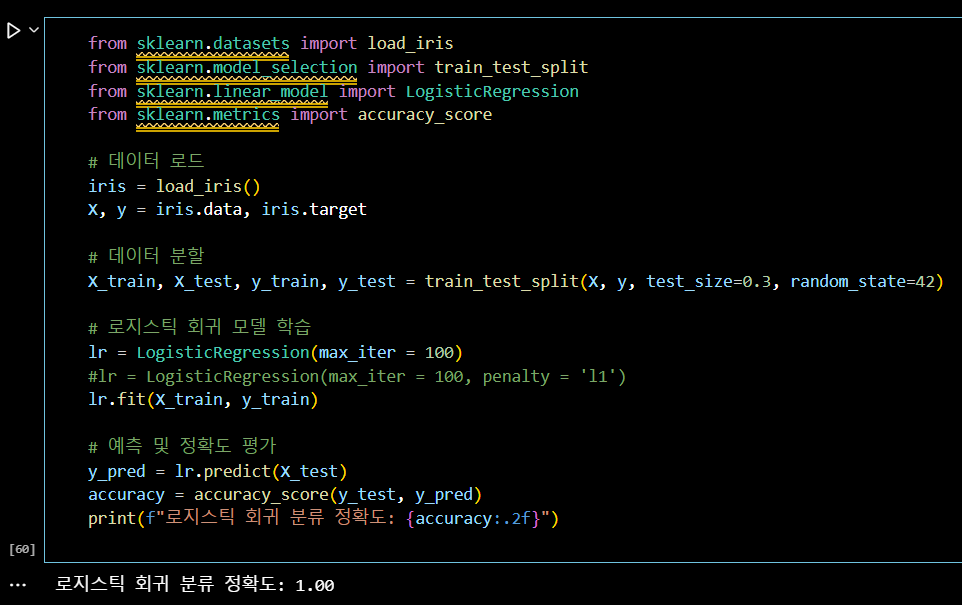
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 로지스틱 회귀 모델 학습
lr = LogisticRegression(max_iter = 100)
#lr = LogisticRegression(max_iter = 100, penalty = 'l1')
lr.fit(X_train, y_train)
# 예측 및 정확도 평가
y_pred = lr.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"로지스틱 회귀 분류 정확도: {accuracy:.2f}")+)
로지스틱 회귀 모델은 확률을 구하는 과정까지는 회귀이지만,
최종적으로 (0, 1) 등의 분류를 하기 때문에 분류기로 정의된다.
원래 Logistic Regression은 이진분류 수행
기존에는 다중분류 수행 시
전략적인 측면 : OVR(= OVA), OVO
loss function 바꾸기 : cross entropy
사이킷런 최신 버전 업데이트부터 자동으로 다중분류가 가능해짐 !📌 문제 2
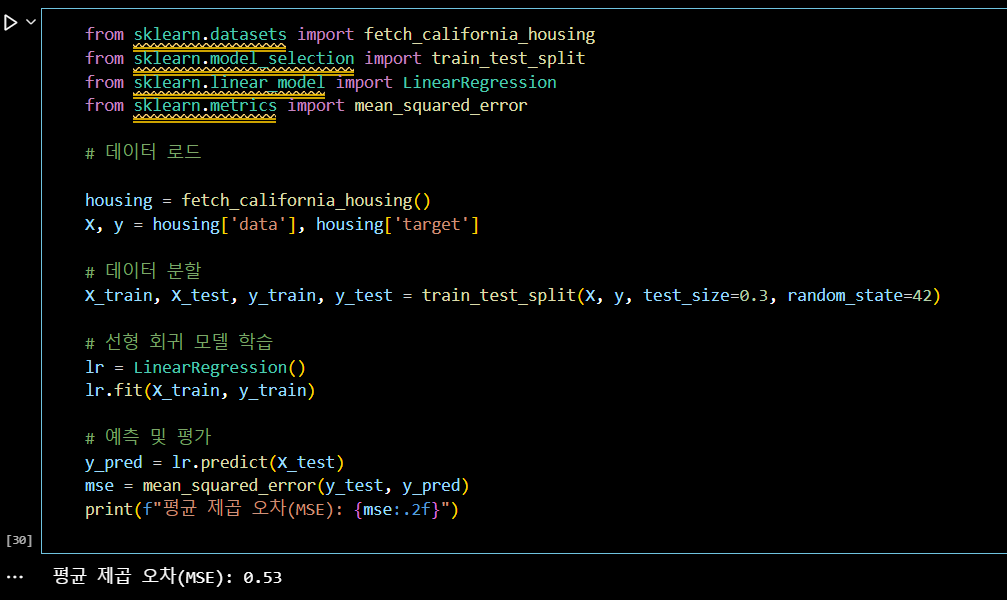
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 데이터 로드
housing = fetch_california_housing()
X, y = housing['data'], housing['target']
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 선형 회귀 모델 학습
lr = LinearRegression()
lr.fit(X_train, y_train)
# 예측 및 평가
y_pred = lr.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"평균 제곱 오차(MSE): {mse:.2f}")📌 문제 3
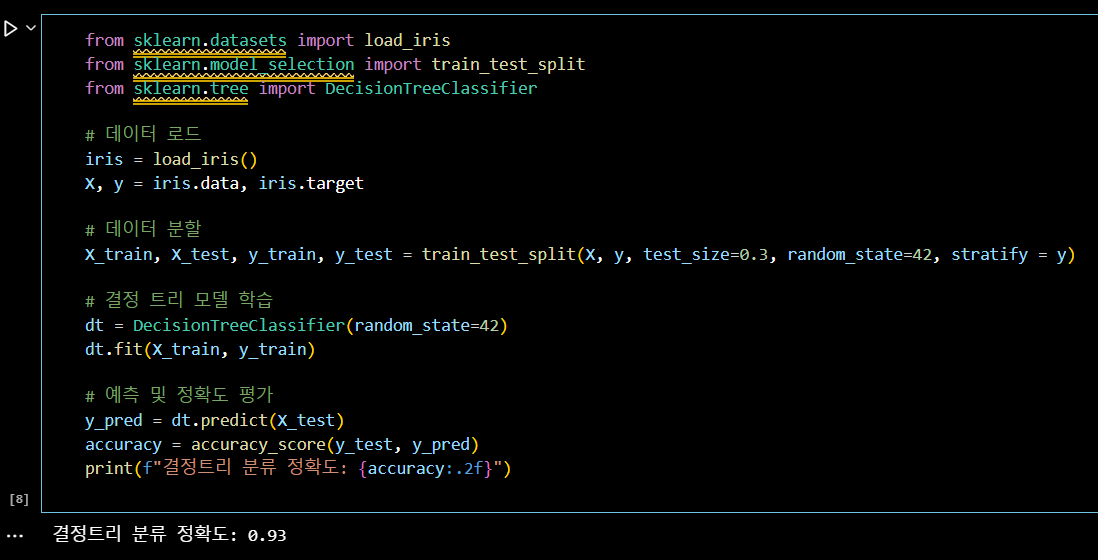
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify = y)
# 결정 트리 모델 학습
dt = DecisionTreeClassifier(random_state=42)
dt.fit(X_train, y_train)
# 예측 및 정확도 평가
y_pred = dt.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"결정트리 분류 정확도: {accuracy:.2f}")📌 문제 4
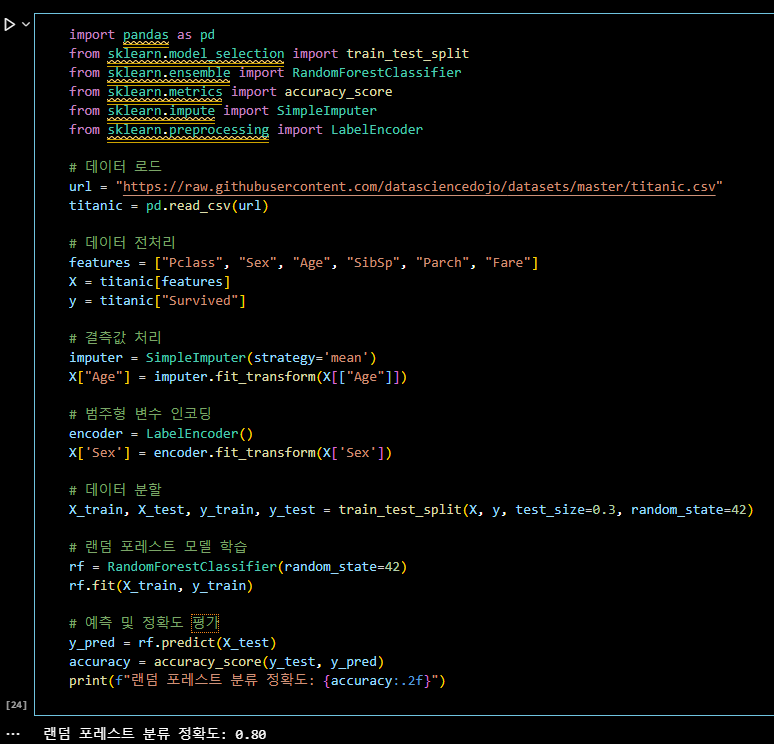
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import LabelEncoder
# 데이터 로드
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
titanic = pd.read_csv(url)
# 데이터 전처리
features = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare"]
X = titanic[features]
y = titanic["Survived"]
# 결측값 처리
imputer = SimpleImputer(strategy='mean')
X["Age"] = imputer.fit_transform(X[["Age"]])
# 범주형 변수 인코딩
encoder = LabelEncoder()
X['Sex'] = encoder.fit_transform(X['Sex'])
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 랜덤 포레스트 모델 학습
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train, y_train)
# 예측 및 정확도 평가
y_pred = rf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"랜덤 포레스트 분류 정확도: {accuracy:.2f}")📌 문제 5
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# K-means 클러스터링 수행
kmeans = KMeans(n_clusters=3, random_state=42)
y_kmeans = kmeans.fit_predict(X)
# 클러스터 중심 출력
print("클러스터 중심 좌표:")
print(kmeans.cluster_centers_)
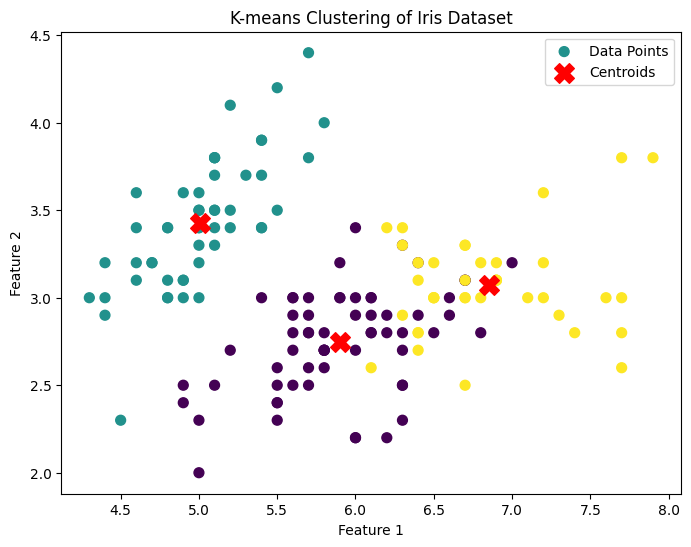
# 클러스터 할당 결과를 주요 피처에 따라 2차원 산점도로 시각화
plt.figure(figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, cmap='viridis', s=50, label='Data Points')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1],
s=200, c='red', marker='X', label='Centroids')
plt.title('K-means Clustering of Iris Dataset')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()+)
- c : marker 색깔
- cmap : 색깔 스타일
- s : marker 크기
- marker : marker 모양, 스타일📌 문제 6

import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
# 데이터 로드 및 전처리
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train, X_test = X_train / 255.0, X_test / 255.0
y_train, y_test = to_categorical(y_train), to_categorical(y_test)
# 신경망 모델 구성
model = Sequential([Flatten(input_shape=(28,28),
Dense(128, activation='relu'),
Dense(64, activation = 'relu'),
Dense(10, activation='softmax')
])
# 모델 컴파일 및 학습
model.compile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=5, validation_data=(X_test, y_test))
# 테스트 데이터에 대한 평가
loss, accuracy = model.evaluate(X_test, y_test)
print(f"신경망 분류 정확도: {accuracy:.2f}")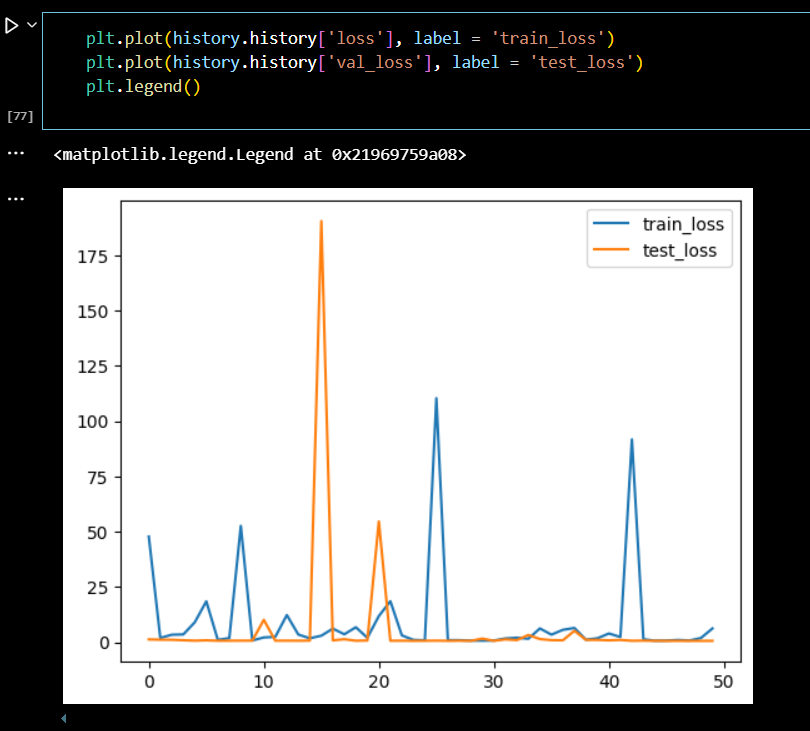
plt.plot(history.history['loss'], label = 'train_loss')
plt.plot(history.history['val_loss'], label = 'test_loss')
plt.legend().
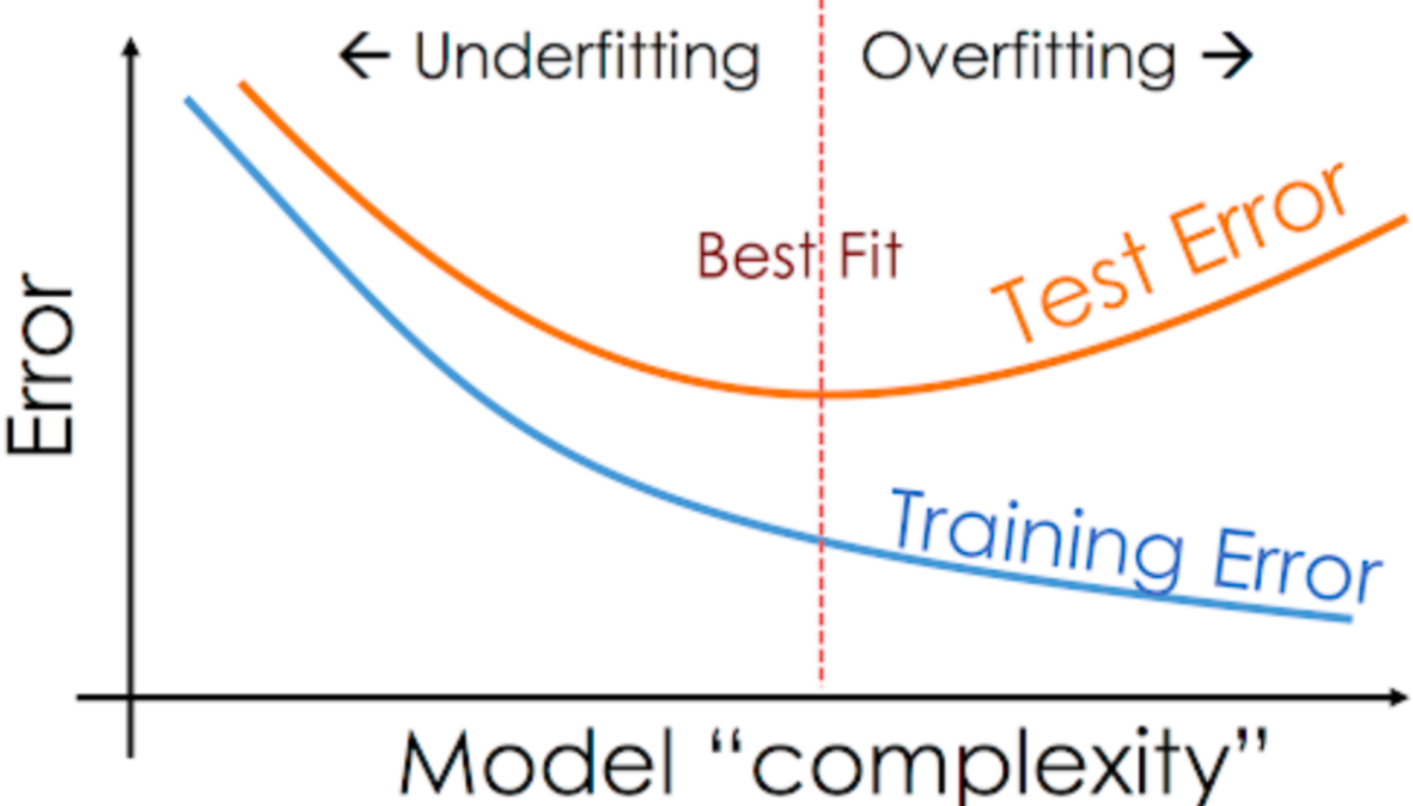
loss의 변화를 보고 오버피팅(과대적합)인지 언더피팅(과소적합)인지 확인이 가능하다.
# 과대적합 : train 데이터는 loss가 잘 낮아지고 있는데,
언제부턴가 test_loss가 더 낮아지지 않는 경우
# 과소적합 : train, test_loss 둘 다 잘 낮아지지 않는 경우
- 과소적합 해결법 -> 모델을 복잡하게 만들어 준다.
- 과대적합 해결법 -> 많은 방법이 있지만 그 중 대표적인 방법 ;
early stopping (일찍 멈추기)+)
# 손글씨 데이터셋 MNIST
# 원래는 정답값 0~9 (예시, 첫 번째 데이터는 2 입니다.)
# categorical (one - hot encoding) : 0, 1, 1, 1, 0, ..., 1
# Dense() ; 가장 기본적인 신경망 층
# Dense() 의 갯수 ; 신경망 층의 갯수
# Dense(숫자) ; 괄호 안 숫자 ; node (동그라미) 수
# 몇 층? 몇 개의 노드? ; 정답이 없고, 노드나 층이 많을수록 복잡한 모델
# 더 복잡한 데이터에서 사용 가능하지만 시간이 오래 걸리고 과대적합 위험이 있다.
# 신경망 층의 갯수는 2개 이상부터 딥러닝이 가능하고
# 2의 제곱수 : 2, 4, 8, 16, ... 가 컴퓨터가 읽어내기 좋다.
# 맨 마지막 층의 노드 수는 신경을 써야 한다.
# 분류 : 클래스(분류해야하는 값)의 갯수
(MNIST 데이터는 9개의 손글씨를 분류해야하기 때문에 10개의 노드가 필요)
# 회귀 : 1개 (집값 예측 > 1개가 맨 마지막에 출력되어야 한다.)
# Flatten : 납작하게 만들어주는 함수 > 이미지 데이터는 (가로 픽셀 X 세로 픽셀)의 2차원 형태
# 벡터로 1차원 형태로 만들기 위해 Flatten 사용
# input_shape : 맨 처음 층에서 반드시 사용해줘야 한다. 데이터의 shape 를 지정하는 부분
# activation function 이 중간중간 들어가야 복잡한 데이터를 처리할 수 있는 딥러닝이 될 수 있다.
# relu, 가장 많이 사용하는 activation function, 계산이 편하고 빠르고, 생물학적으로 뇌의 뉴런과 비슷
# softmax, 마지막에 분류인 경우에 사용 (A에 대해 몇 %, B에 대해 몇 % 인지 계산) / 회귀의 경우 넣지 않는다.
# optimizer : 경사하강법을 어떤 전략으로 수행할 것인지?
(SGD, Mini-batch 등 있지만, Adam이 가장 무난하고 많이 사용)
# loss : 분류는 cross entropy 를 사용하면 되는데 정답값이 원-핫 인코딩이면 'categorical_crossentropy',
# 아니면 'sparse_categorical_crossentropy'
# loss : 회귀는 MSE (MAE, RMAE 등)
# metrics : 성능지표를 넣어주는 곳, (옵션사항) 넣어도 되고 생략해도 된다.
# epochs : 몇 번 학습할 지 정하는 곳, 많을수록 좋은 성능을 기대해볼 수 있으나, 오버피팅의 위험이 있다.
# validation data : 평가용 데이터를 튜플 형태로 넣어주면 된다..
# 딥러닝을 수행하기 위해 필요한 하드웨어
# GPU (그래픽카드) ; 작업관리자에서 쉽게 확인 가능
# 딥러닝을 수행하기 위해 필요한 소프트웨어
# CUDA ; 내 그래픽 카드랑 맞는 버전 설치
# Cudnn ; CUDA 버전에 맞게 설치
# Tensorflow or Pytorch (패키지) ; CUDA, Cudnn 버전에 맞게끔 설치
# 버전이 맞아야 한다.
# 위 세팅이 힘들다면 코랩 사용
# 코랩 > 런타임 > 런타임 유형변경 > GPU
커피 좋아하는 데이터 꿈나무