
#개요
- 문자열 심화
📌 데이터 생성
import pandas as pd df = pd.DataFrame({'A': ['블루베리 스무디', '딸기 스무디', '딸기 바나나 스무디'], 'B': [10, 20, 30], 'C': ['추천/신메뉴', '신메뉴/할인', '사이즈업/추천'], 'D': ['ab cd', 'AB CD', 'ab cd'] }) df
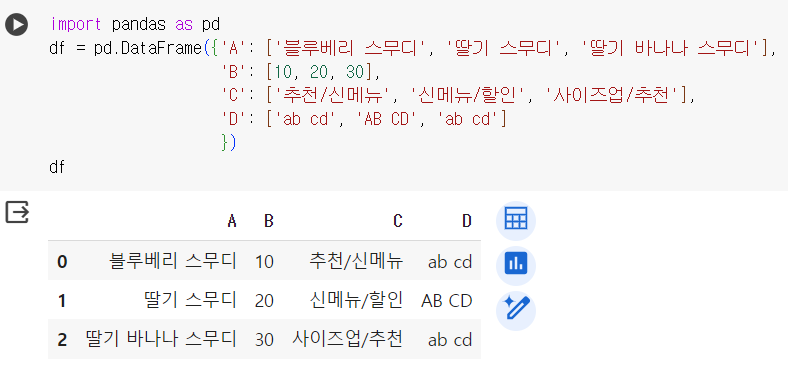
📌 replace 데이터프레임
# replace, 전체 문자가 일치해야 변경 df['A'] = df['A'].replace('스무디','에이드') # 변경이 되지 않음! df
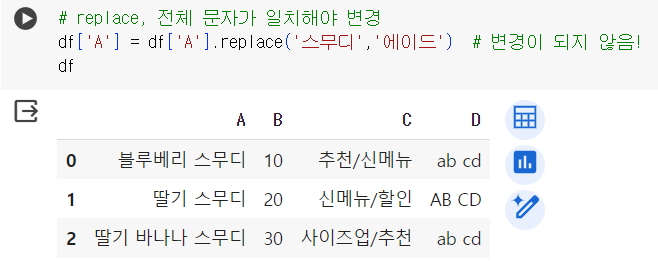
# replace 데이터프레임 df.replace('블루베리 에이드','청포도 에이드')
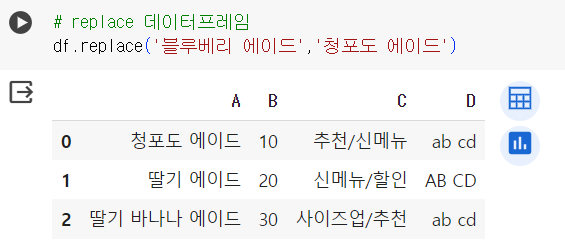
📌 str.replace 일부 문자
# str.replace, 일부 일치하는 문자 변경 # 시리즈 형태의 문자만 변경 가능! df['A'] = df['A'].str.replace('스무디','에이드') df
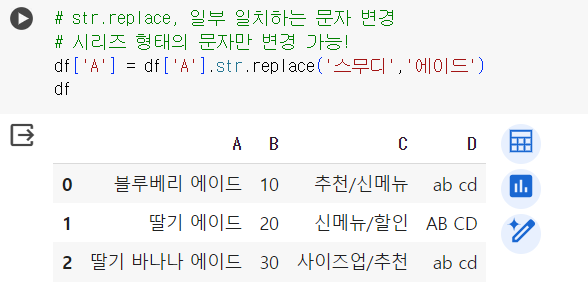
# str.replace, 일부 일치하는 문자 변경 # 시리즈 형태의 문자만 변경 가능! df.str.replace('블루베리 에이드','청포도 에이드') # 시리즈 형태가 아니기 때문에 오류 반환

📌 숫자 변경
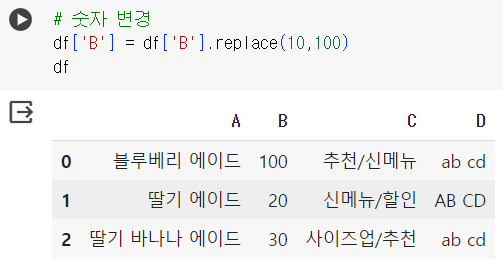
# 숫자 변경 df['B'] = df['B'].replace(10,100) df
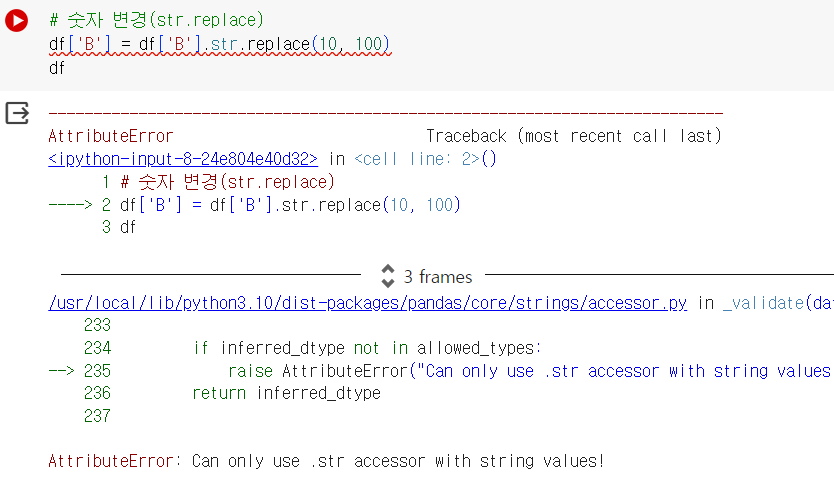
# 숫자 변경(str.replace) # 시리즈에 str 접근자를 사용하면 오류가 반환된다. df['B'] = df['B'].str.replace(10, 100) df
📌 split 어절 나누기
# 어절 나누기 df['A'].str.split()

# 어절 나눈 후 첫 번째 값 df['A'].str.split().str[0]

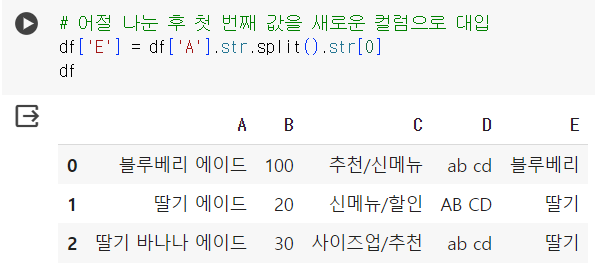
# 어절 나눈 후 첫 번째 값을 새로운 컬럼으로 대입 df['E'] = df['A'].str.split().str[0] df
# 어절 나누기(/) df['C'].str.split('/')

📌 contains 특정 문자 찾기
# 특정 문자 찾기 (contains) df['A'].str.contains('딸기')

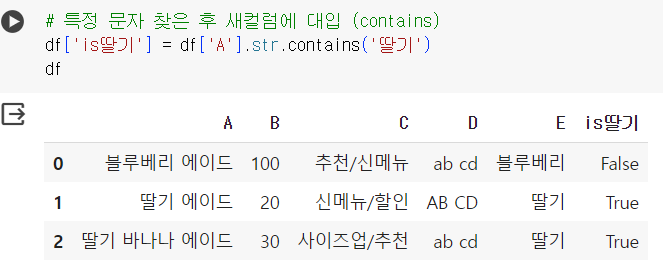
# 특정 문자 찾은 후 새컬럼에 대입 (contains) df['is딸기'] = df['A'].str.contains('딸기') df
📌 isin 특정 값 찾기
# 데이터 menu = pd.Series(['맛난버거 세트', '매운 치킨버거', '더블 치즈버거'])

# 특정 값이 있는지 확인하기 (isin) # 여러 값을 동시에 찾을 수 있음! menu.isin(['맛난버거 세트', '더블 치즈버거'])

# 특정 단어가 있는지 확인하기 (isin) # 전체 값을 다 적지 않고 일부만 적으면 찾아내지 못한다! menu.isin(['세트'])

# 특정 단어가 있는지 확인하기 (contains) # 1개 값만 찾을 수 있음! menu.str.contains('세트')

📌 len 문자 길이
# 문자 길이 # str 접근자를 사용해 len 사용 가능! df['A'].str.len()

📌 대소문자 구분
# 대소문자 구분 # 파이썬은 기본적으로 대소문자를 구분한다! 'AB cd' == 'ab CD'

# 소문자로 변경 df['D'].str.lower()

# 대문자로 변경 df['D'].str.upper()

📌 공백 구분
df2 = pd.DataFrame({'A': ['블루베리 스무디', '딸기 스무디', '딸기 바나나 스무디'], 'B': [10, 20, 30], 'C': ['추천/신메뉴', '신메뉴/할인', '사이즈업/추천'], 'D': ['ab cd', 'AB CD', 'ab cd '] # 3번째 값에 마지막 공백 추가 })

# AB CD와 같은가? # 공백이 있기 때문에 같은 값이 아니라고 반환한다! df2['D'] = df2['D'].str.upper() df2['D'] == 'AB CD'

📌 공백 제거
# 공백 제거 df2['D'] = df2['D'].str.replace(" ","") df2

📌 문자열 슬라이싱
# 슬라이싱(str) df2['D'].str[:2]

# 슬라이싱 # str 접근자를 활용해야 문자열에 접근이 가능하다! # str 접근자가 없으면 해당 인덱스 행이 출력 df2['D'][:2]

📌 원하는 문자 슬라이싱
# 데이터 df = pd.DataFrame({'date':['2024년 3월', '2024년 4월', '2025년 5월']})

# 연도 df['date'].str[:4]
# 월 df['date'].str[6:7]


커피 좋아하는 데이터 꿈나무