
#INTRO
꿀주말!

# 데이터 수집 - 웹 크롤링 시도
내가 항상 원두를 구매하는 29CM 의 원두 판매 페이지에서
판매량이 많은 상위 제품들의 리뷰를 크롤링해보고 싶어졌다.
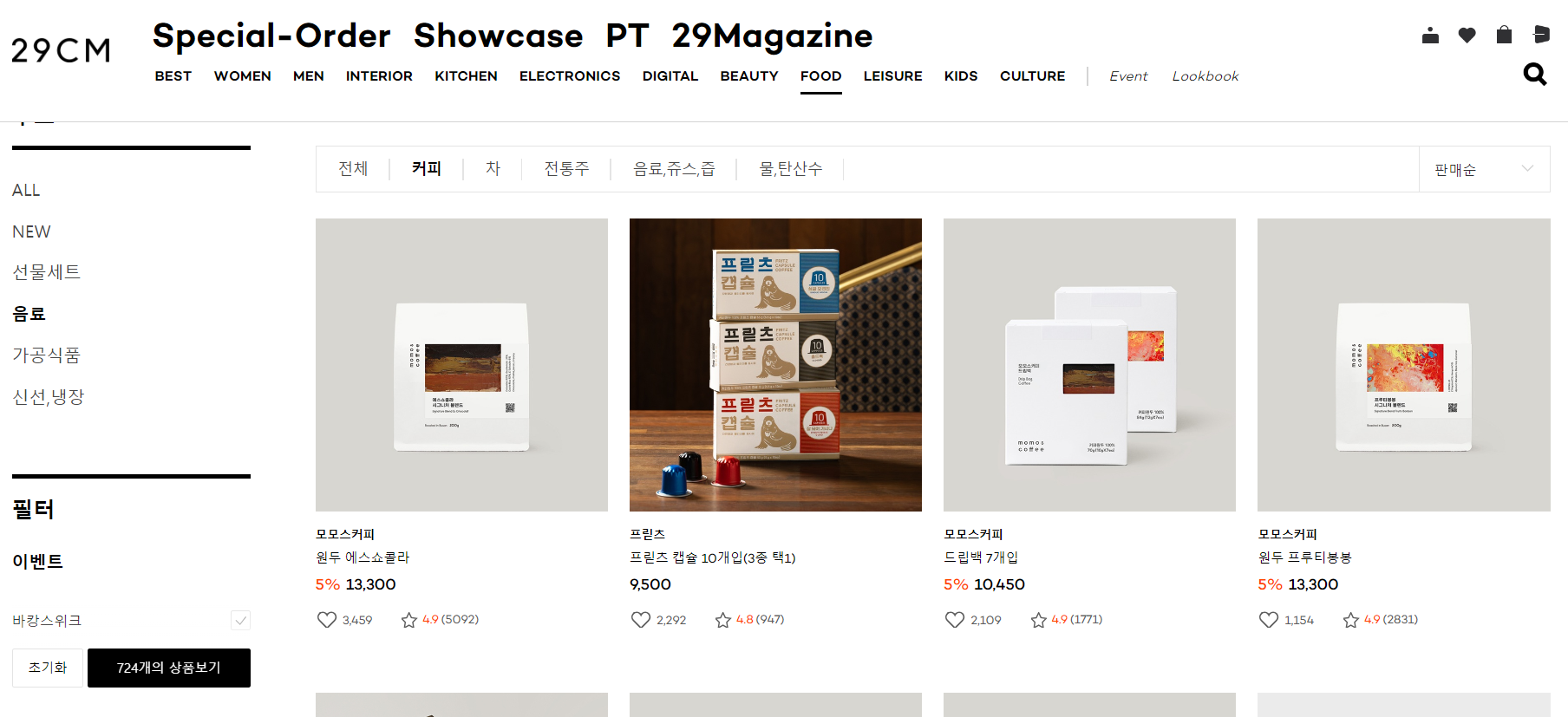
크롤링하기 전 로봇 배제 표준 확인
판매량이 제일 많은 원두의 리뷰 페이지 확인
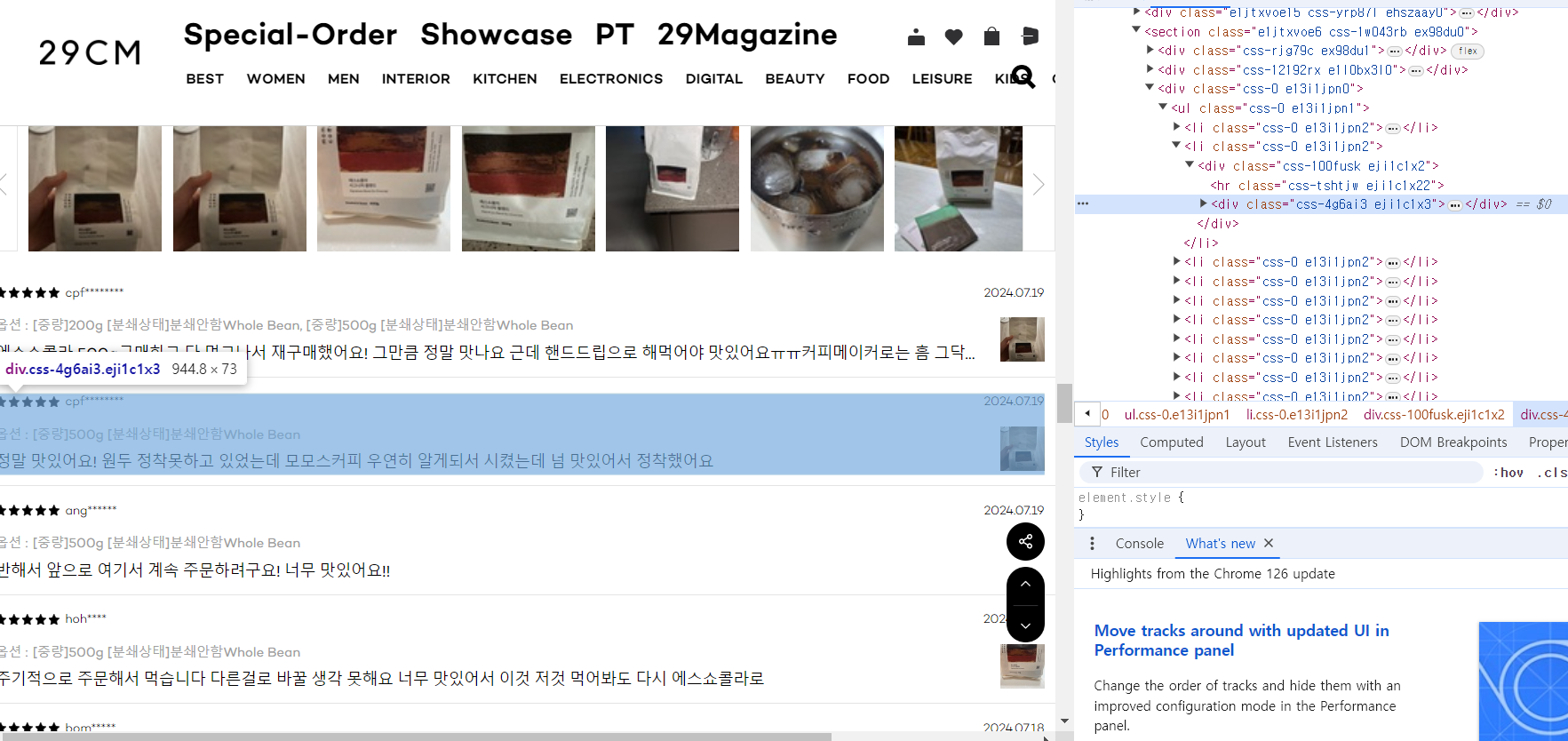
별점은 이미지 파일로 되어 있어서 크롤링하기 쉽지 않아 보였다.
검은 별 이미지의 갯수를 세서 숫자로 변환하는 게 가능할까?

일단, 클래스를 바로 적용해서 크롤링이 가능해보이는
작성자 아이디, 옵션, 리뷰, 날짜 4가지 항목을 가져와보기로 했다.
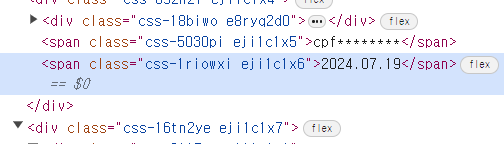
작성자 아이디 클래스
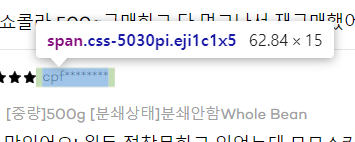
옵션 클래스
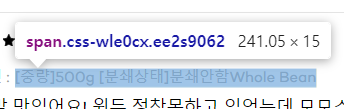
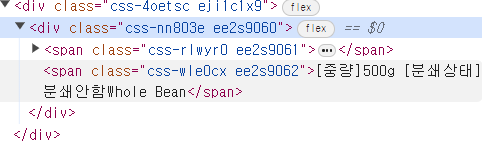
리뷰 클래스
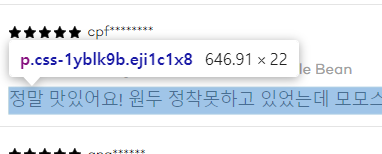
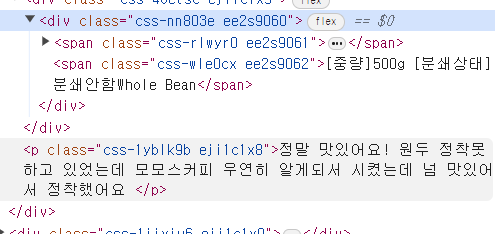
날짜 클래스

세션에서 배웠던 코드를 변형해서 진행
- 라이브러리 가져오기
import time
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.common.exceptions import NoSuchElementException
from webdriver_manager.chrome import ChromeDriverManager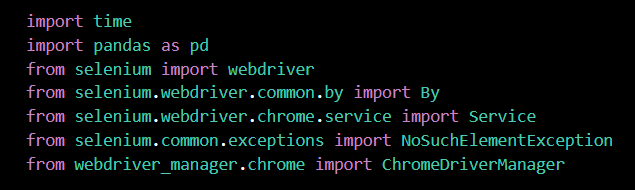
- 함수 만들기 (1)
def get_coffee_reviews(url, page_num=20):
# Service 객체를 사용하여 Chrome 드라이버 초기화
service = Service(ChromeDriverManager().install())
wd = webdriver.Chrome(service=service)
wd.get(url)
# 빈 리스트 생성하기
writer_list = []
option_list = []
review_list = []
date_list = []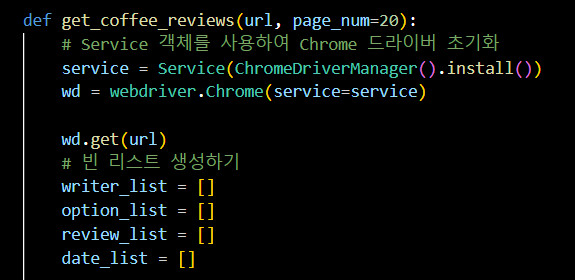
- 함수 만들기 (2)
for page_no in range(1, page_num + 1): # 1페이지에서 page_num까지의 리뷰 추출
try:
# 페이지 넘버를 찾아 클릭하는 로직
page_ul = wd.find_element(By.CLASS_NAME, 'css-16vmvyd')
page_lis = page_ul.find_elements(By.TAG_NAME, 'li')
for li in page_lis:
if li.text == str(page_no):
li.click()
time.sleep(3) # 페이지 로딩까지의 시간 두기
break
# 리뷰 작성자
writers = wd.find_elements(By.CLASS_NAME, 'css-5030pi')
writer_list += [writer.text for writer in writers]
# 옵션 정보
options = wd.find_elements(By.CLASS_NAME, 'css-wle0cx')
option_list += [option.text for option in options]
# 리뷰 내용
reviews = wd.find_elements(By.CLASS_NAME, 'css-1yblk9b')
review_list += [review.text for review in reviews]
# 작성 날짜
dates = wd.find_elements(By.CLASS_NAME, 'css-1riowxi')
date_list += [date.text for date in dates]
except NoSuchElementException:
break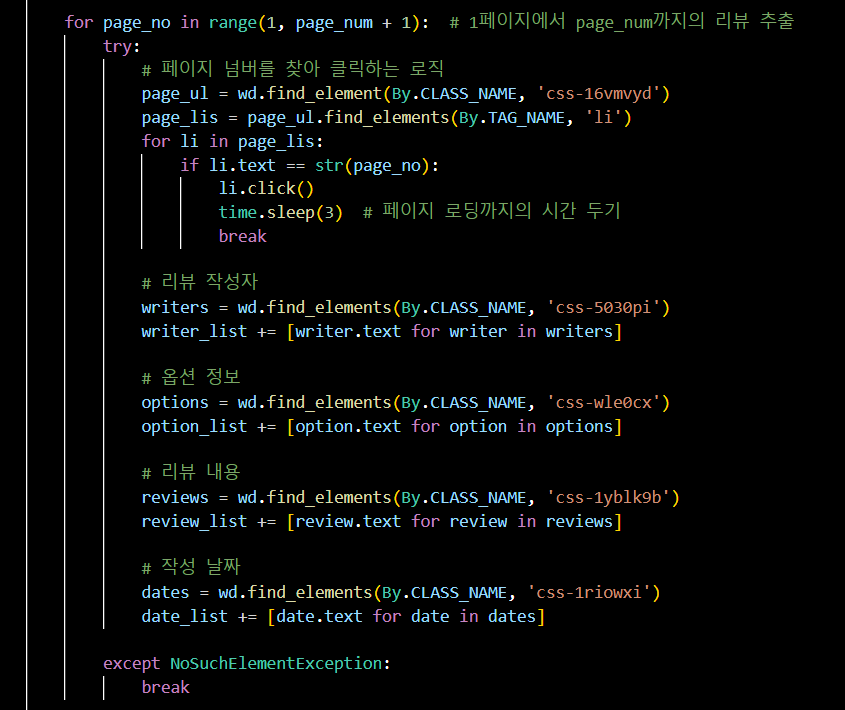
-
페이지 넘버 클래스 확인 (
css-16vmvyd)


-
리뷰 작성자 클래스 확인 (
css-5030pi)

-
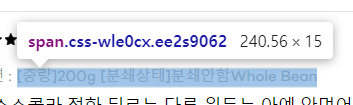
옵션 정보 클래스 확인 (
css-wle0cx)
-
리뷰 내용 클래스 확인 (
css-1yblk9b)

-
작성 날짜 클래스 확인 (
css-1riowxi)

- 함수 만들기 (3)
# 데이터 프레임 생성
coffee_review_df = pd.DataFrame({"Writer": writer_list,
"Option": option_list,
"Review": review_list,
"Date": date_list})
wd.close()
return coffee_review_df
- 함수 실행 후 데이터 프레임으로 반환
# URL과 page_num을 입력하여 작성자, 리뷰내용, 작성날짜 요청 및 데이터프레임 반환
url = "https://product.29cm.co.kr/catalog/400817?"
coffee_review_df = get_coffee_reviews(url, page_num=20)
# 데이터프레임 저장
coffee_review_df.to_csv('에스쇼콜라리뷰크롤링.csv', index=False, encoding="utf-8-sig")
-
실행 결과
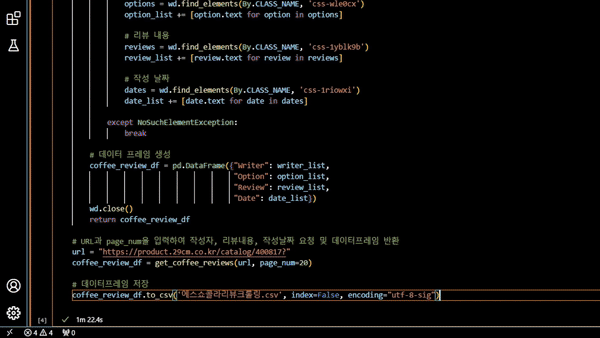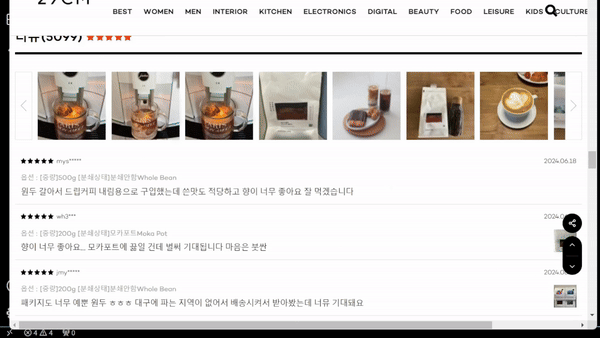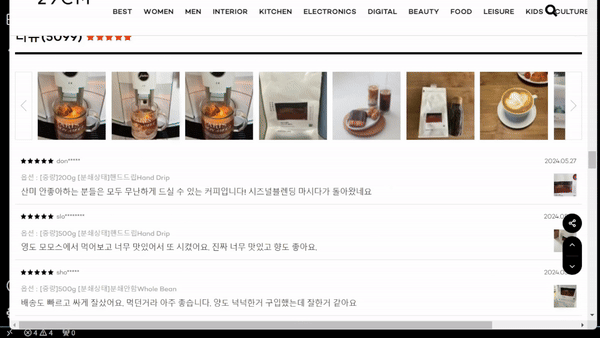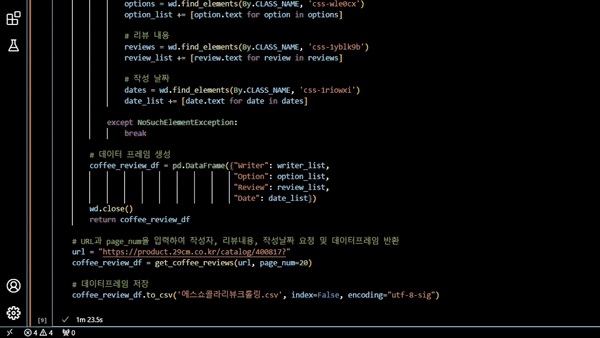
-
리뷰데이터.csv
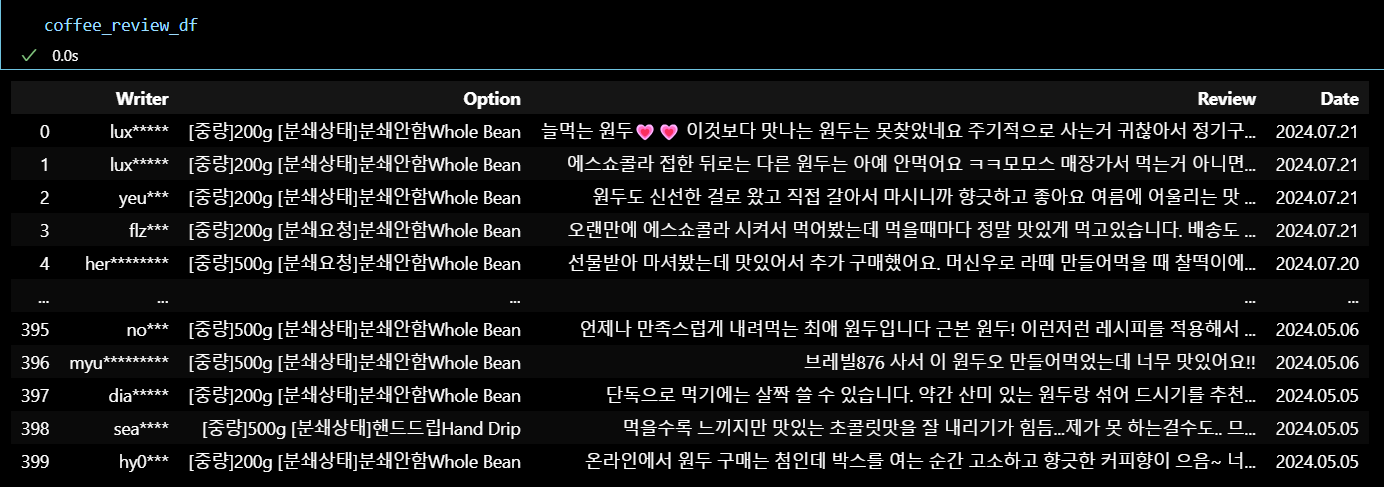
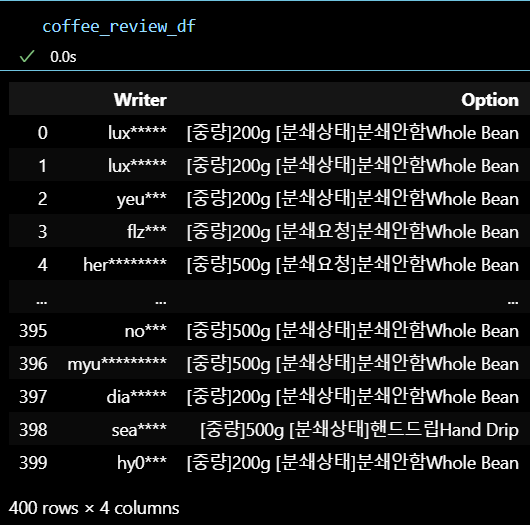

리뷰 데이터 가져오기 성공 !
#OUTRO
오늘의 한 줄.
주말 끝 !

커피 좋아하는 데이터 꿈나무