
#INTRO
목표했던 자격증들 모두 취득 완료 !

#최종 프로젝트 진행
- 기획 재정리
- 목적이 있는 분석 & 결과 도출하기
- 도메인 : 패션 커머스
- 데이터 : H&M 고객, 제품, 거래(2년) 정보가 담긴 3개의 데이터셋
- 분석 방향 : H&M 매출 향상 및 충성 고객 유지
- 예상 결과물 : BI 현황 대시보드 & 제품 추천 대시보드<프로젝트 주제>
H&M 데이터 분석을 통한 매출 및 고객 구매 경험 개선 전략
<주제 선정 이유>
실제 기업에서 제공한 데이터(고객, 거래, 제품 등)를 활용하여 실무와 유사한 분석을 수행할 수 있을 것으로 기대
<프로젝트 명>
H&M 매출 증대 및 고객 만족도 향상 프로젝트
<프로젝트 목표>
H&M 고객의 구매 패턴을 분석하여 맞춤형 마케팅 전략 수립으로 매출 및 고객 만족도를 향상,
개인 맞춤형 제품 추천 시스템 개발
<프로젝트 핵심 내용>
- 데이터 분석
- 고객 분석: 고객의 특성, 구매 빈도, 평균 구매 금액 등을 분석하여 주요 고객 세그먼트 파악
- 제품 분석: 제품 판매 트렌드, 인기 제품, 시즌별 판매 추이 등을 분석하여 상품 기획 및 판매 전략 수립
- 거래 분석: 거래 데이터를 분석하여 구매 패턴, 재구매율, 고객 라이프사이클 등을 파악하여 마케팅 전략 수립
- 예상 결과물
- BI 현황 대시보드:
- 매출 현황: 주별, 월별, 분기별 매출 추이, 매출 비율 상위 제품, 고객 세그먼트별 매출 분석
- 고객 현황: 신규 고객, 재구매 고객, VIP 고객 분석, 고객 유지율 및 이탈율 분석
- 제품 현황: 인기 제품, 분류별 매출 비율 등 분석
- 제품 추천 대시보드:
- 개인 맞춤 추천: 고객의 과거 구매 이력과 선호도를 기반으로 한 개인 맞춤형 추천 제품 리스트
- 연관 제품 추천: 특정 제품을 구매한 고객이 함께 구매한 다른 제품 추천 리스트- 다시 처음으로 돌아가서, 분석에 필요한 상태로 데이터를 정리했다.
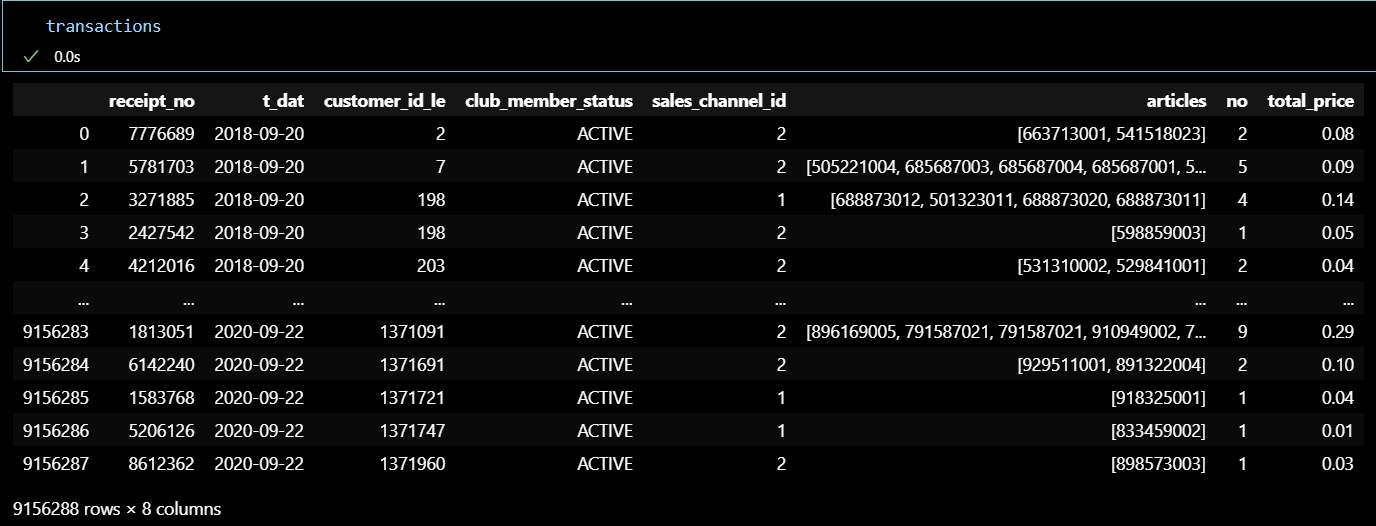
TRANSACTIONS 테이블 정리
-
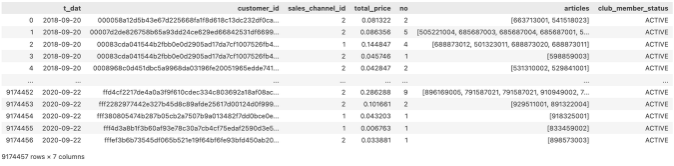
구매일, 고객 id, 판매 채널이 같은 거래 건들을 모아서 하나의 거래 기록으로 정의 (1번)

-
고객이 구매한 상품들을 모두 list로 그룹화 →
articles컬럼 생성

-
고객 테이블에 있는
club_member_status구분 붙이기 (2번)

-
1번, 2번 데이터 합치기
-
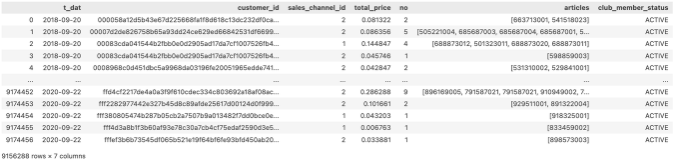
club_member_status의 결측치 제거
-
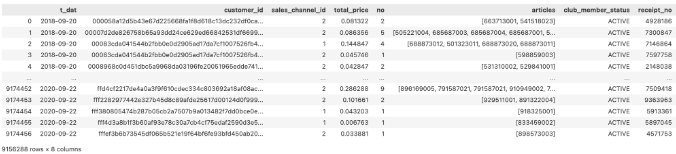
난수 생성으로
영수증 번호(receipt_no)컬럼 생성
-
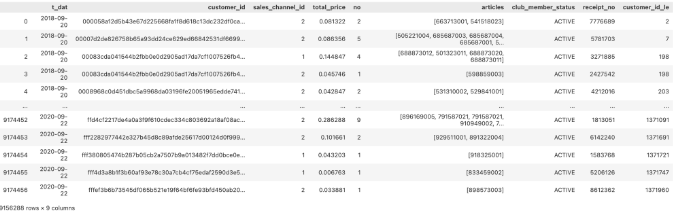
분석 효율을 위한 용량 축소 목적의
customer_id레이블 인코딩
-
필요 컬럼 추출, TRANSACTIONS 데이터 정리 완료
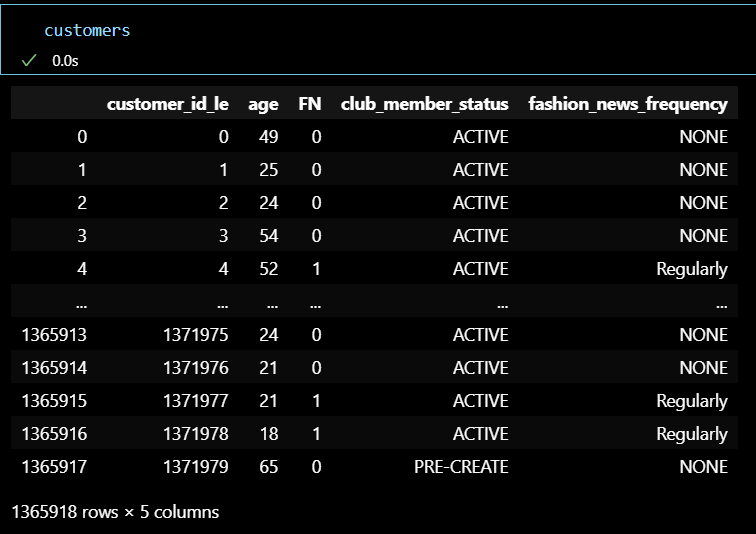
CUSTOMERS 테이블 정리
CUSTOMERS테이블 : Fashion News 관련 컬럼 데이터 논리 구조 맞추기
- FN 1, 0 (구독, 구독 X)
- FN == 1 , fashion_news_frequency == [’Monthly’, ‘Regularly’, ‘None’]
- FN == 0, fashion_news_frequency == [’None’]
CUSTOMERS테이블 : customer_id 데이터 레이블 인코딩
(TRANSACTIONS 테이블과 일치화)
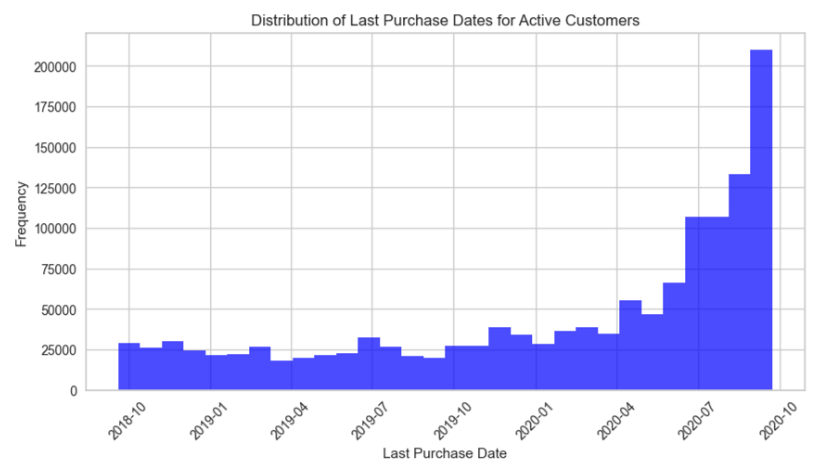
- 고객 특성 분석
- 정상 고객과 이탈 고객으로 분류하여 구매 시점 분포 확인
(정상 고객의 기준 ; club_member_status ==ACTIVE,PRE-CREATE,
이탈 고객의 기준 ; club_member_status ==LEFT CLUB)
- 정상 고객과 이탈 고객으로 분류하여 구매 시점 분포 확인
정상 고객 마지막 구매 시점 분포
(최근 구매 건수 多)
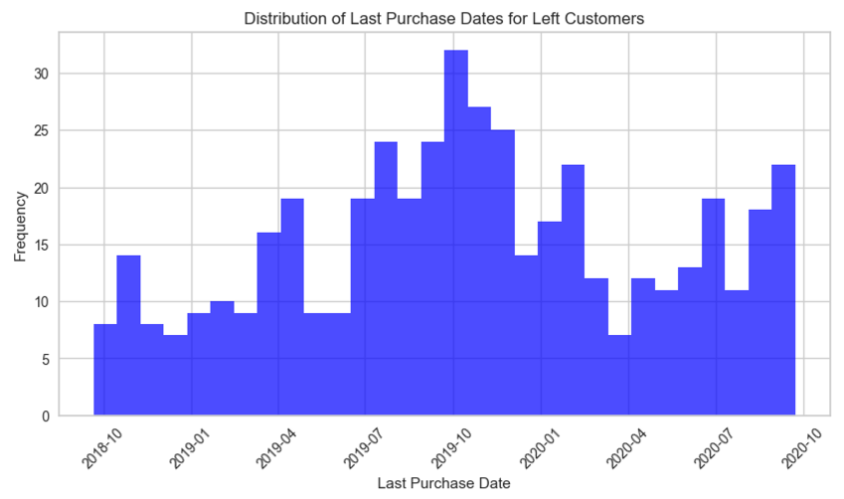
이탈 고객 마지막 구매 시점 분포
(현재일 기준 1년 전 고객 이탈이 가장 많음)
- 고객 분류 분석 (RFM)
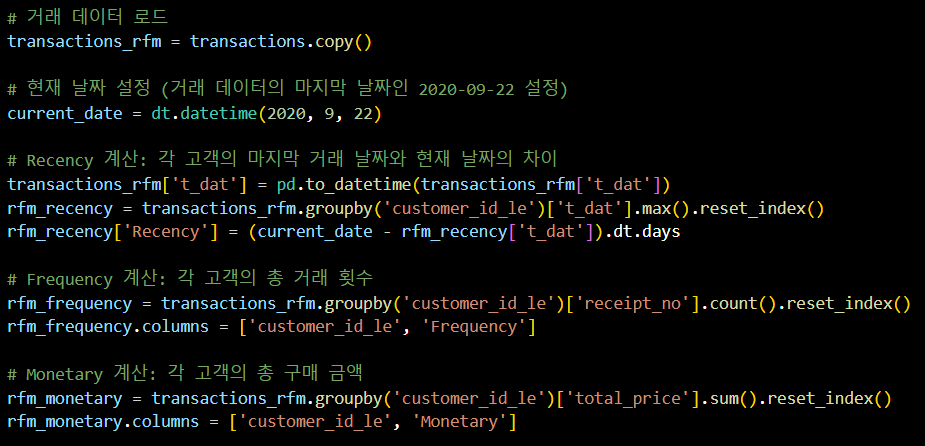
# 거래 데이터 로드
transactions_rfm = transactions.copy()
# 현재 날짜 설정 (거래 데이터의 마지막 날짜인 2020-09-22 설정)
current_date = dt.datetime(2020, 9, 22)
# Recency 계산: 각 고객의 마지막 거래 날짜와 현재 날짜의 차이
transactions_rfm['t_dat'] = pd.to_datetime(transactions_rfm['t_dat'])
rfm_recency = transactions_rfm.groupby('customer_id_le')['t_dat'].max().reset_index()
rfm_recency['Recency'] = (current_date - rfm_recency['t_dat']).dt.days
# Frequency 계산: 각 고객의 총 거래 횟수
rfm_frequency = transactions_rfm.groupby('customer_id_le')['receipt_no'].count().reset_index()
rfm_frequency.columns = ['customer_id_le', 'Frequency']
# Monetary 계산: 각 고객의 총 구매 금액
rfm_monetary = transactions_rfm.groupby('customer_id_le')['total_price'].sum().reset_index()
rfm_monetary.columns = ['customer_id_le', 'Monetary']# RFM 데이터 통합
rfm = rfm_recency.merge(rfm_frequency, on='customer_id_le')
rfm = rfm.merge(rfm_monetary, on='customer_id_le')
# RFM 점수화
rfm['R_Score'] = pd.qcut(rfm['Recency'], 5, labels=False, duplicates='drop') + 1
rfm['F_Score'] = pd.qcut(rfm['Frequency'].rank(method='first'), 5, labels=False, duplicates='drop') + 1
rfm['M_Score'] = pd.qcut(rfm['Monetary'], 5, labels=False, duplicates='drop') + 1
# RFM 점수 통합
rfm['RFM_Score'] = rfm['R_Score'].astype(str) + rfm['F_Score'].astype(str) + rfm['M_Score'].astype(str)# RFM 데이터 통합
rfm = rfm_recency.merge(rfm_frequency, on='customer_id_le')
rfm = rfm.merge(rfm_monetary, on='customer_id_le')
# RFM 점수화
rfm['R_Score'] = pd.qcut(rfm['Recency'], 5, labels=False, duplicates='drop') + 1
rfm['F_Score'] = pd.qcut(rfm['Frequency'].rank(method='first'), 5, labels=False, duplicates='drop') + 1
rfm['M_Score'] = pd.qcut(rfm['Monetary'], 5, labels=False, duplicates='drop') + 1
# RFM 점수 통합
rfm['RFM_Score'] = rfm['R_Score'].astype(str) + rfm['F_Score'].astype(str) + rfm['M_Score'].astype(str)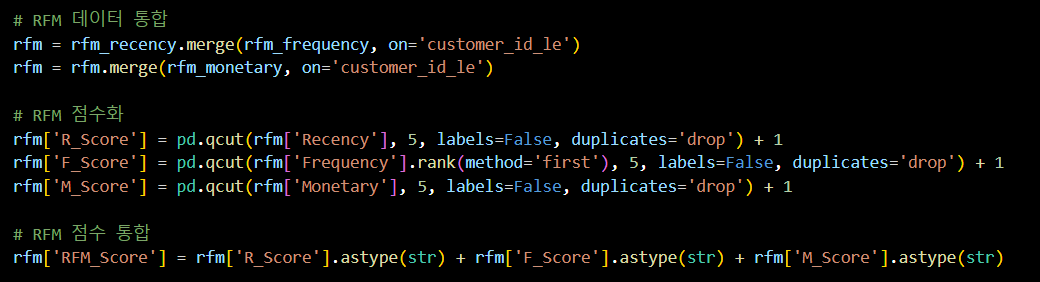
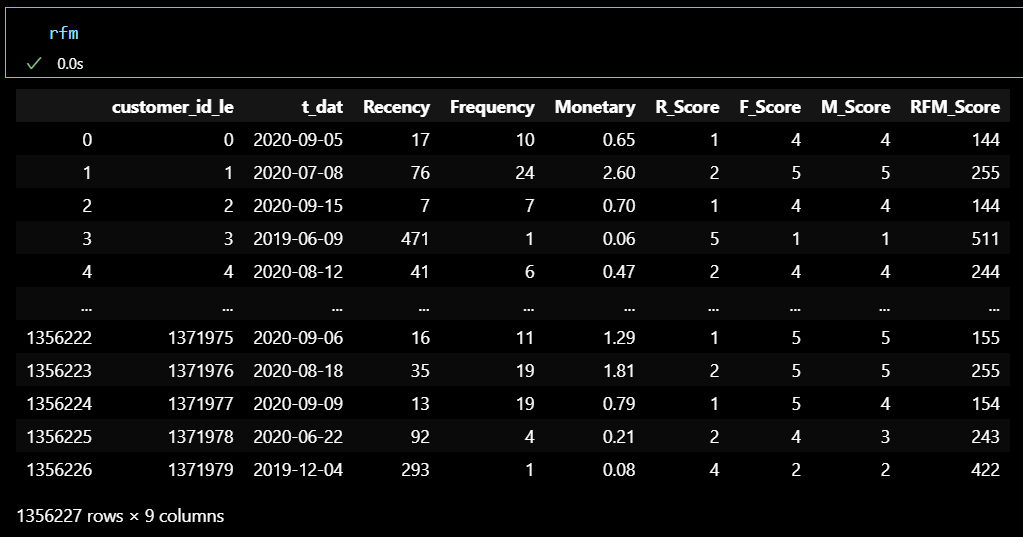
# RFM_Score의 빈도 계산
rfm_counts = rfm['RFM_Score'].value_counts().reset_index()
rfm_counts.columns = ['RFM_Score', 'Count']
# 막대 그래프 시각화
plt.figure(figsize=(20, 8))
sns.barplot(x='RFM_Score', y='Count', data=rfm_counts)
plt.title('Frequency of RFM Scores')
plt.xlabel('RFM Score')
plt.ylabel('Count')
plt.xticks(rotation=90)
plt.show()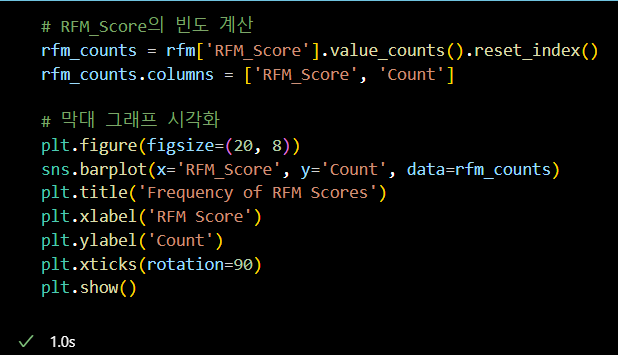
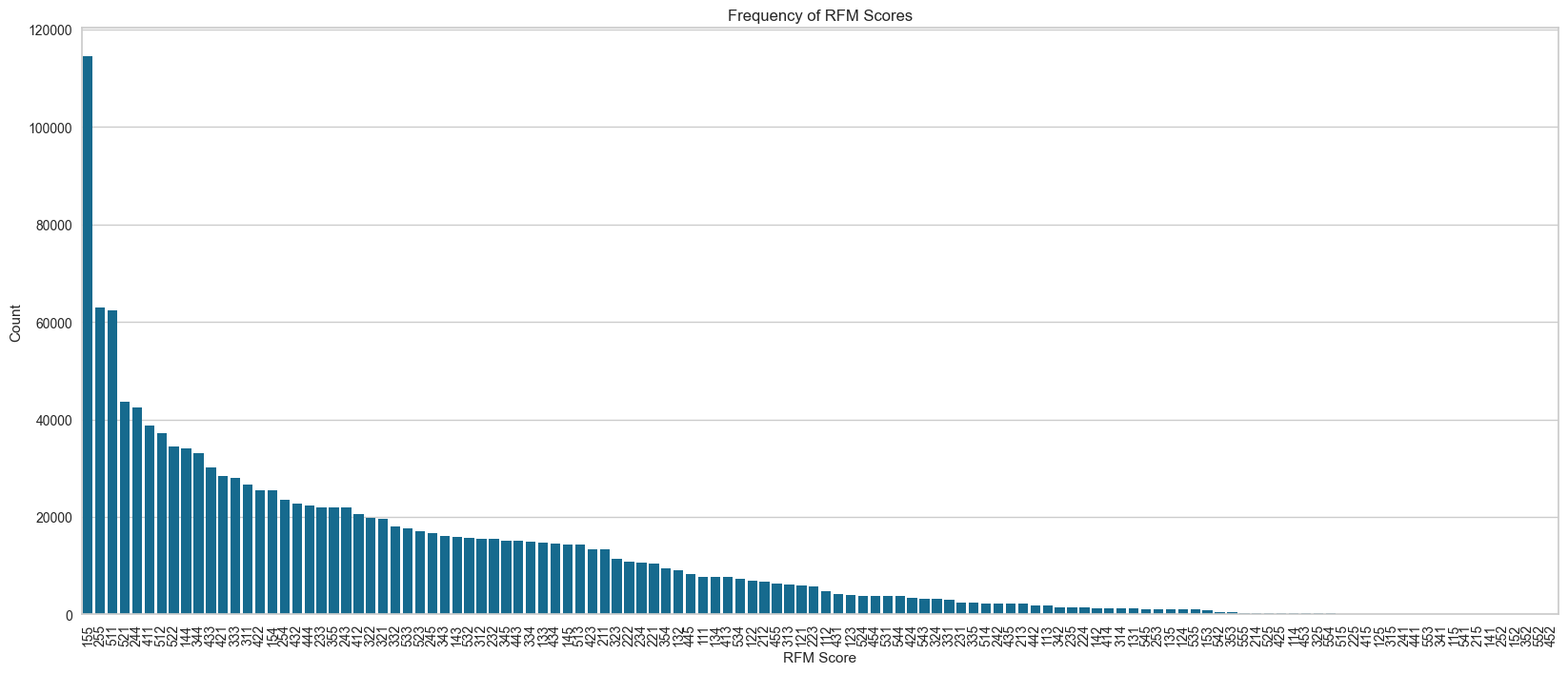
RFM 분석 결과 공유 후 확인한 문제점
-
Recency 점수
(마지막 구매일과 현재 일자와의 차이가 작을수록
높은 점수를 부여해야하는데, 숫자대로 점수를 주다보니 반대가 되었다.) -
Frequency 점수
(구매 횟수에 대한 기간 기준 애매함과
구매 주기에 대한 정의를 고민할 필요가 있다.)
정리
- 분석 방향성 정리
- 고객 분류를 먼저 진행하자.
- 분류된 고객의 특성을 파악하자. (집중해야 하는 고객 세그먼트 선정)
- 선택한 고객 분류의 특성을 확인할 수 있는 지표를 설정하자.
(재구매, 이탈율, 평균 매출 등) - ...
#OUTRO
오늘의 한 줄.
주말이다!!!!!!!!!!!!!!!!!!!!!!!!!!!

커피 좋아하는 데이터 꿈나무
크 자격증 므찌다👍🏻🏅