
#INTRO
맛있는 거 먹기

화이팅..
#코드카타
-
SQL
- CTE 생성 (WITH RECURSIVE 절)
첫 번째 세대 선택SELECT ID , PARENT_ID , 1 AS Gen FROM ECOLI_DATA WHERE PARENT_ID IS NULL
- PARENT_ID가 NULL인 개체들을 선택하여 첫 번째 세대로 설정
- Gen 컬럼을 1로 설정하여 첫 번째 세대를 표시
재귀적으로 다음 세대 찾기
- UNION ALL을 사용하여 첫 번째 세대의 자식 개체들을 재귀적으로 찾고,
INNER JOIN Generation G ON E.PARENT_ID = G.ID를 사용하여
현재 세대의 ID를 부모 ID로 가지는 개체들을 찾기SELECT E.ID , E.PARENT_ID , G.Gen + 1 AS Gen FROM ECOLI_DATA E INNER JOIN Generation G ON E.PARENT_ID = G.ID
- 부모 ID가 이전 세대의 ID인 개체들을 찾아 세대를 하나씩 증가시키기
최종 결과 선택
- 3세대 개체의 ID 선택
SELECT ID FROM Generation WHERE Gen = 3 ORDER BY ID
- Gen 값이 3인 개체들을 선택하여 3세대 개체들 식별
- 결과를 ID 오름차순으로 정렬하여 출력
+)
재귀 쿼리에 대한 설명
- WITH RECURSIVE 절
- SQL에서 재귀적으로 데이터를 처리하기 위해
WITH RECURSIVE 절을 사용한다.
- CTE의 한 형태로, 자기 자신을 참조하여
반복적인 처리를 수행할 수 있게 한다.
- 초기 조건
- 첫 번째 세대와 같이 재귀 처리를 시작하는 초기 조건을 정의.
이번 쿼리에서는 PARENT_ID가 NULL인 개체들을 첫 번째 세대로 선택
- 재귀 부분
- UNION ALL을 사용하여 초기 조건에서 시작하여
다음 세대를 찾는 재귀적 구조를 맞춘다.
- INNER JOIN을 통해 부모 ID가
이전 세대의 ID인 개체들을 찾아 세대 증가시키기.
- 종료 조건
- 재귀 쿼리는 암묵적으로 종료 조건을 가진다.
이 쿼리에서는 더 이상 매칭되는 개체가 없을 때 재귀 종료
- 결과 선택
- 마지막으로 원하는 세대의 데이터를 선택하여 조회
이 쿼리에서는 3세대 개체들의 ID를 선택하고 정렬#커머스 데이터 분석 실무 (라이브 세션)
#협업 필터링
추천 시스템 고민 중 협업 필터링에 대한 내용 정리
-
협업 필터링 ?
- 협업 필터링은 사람들이 좋아하는 것들에 대한 데이터를 사용해서,
어떤 사람에게 어떤 것을 추천할지 예측하는 방법이다. - 예를 들어, 영화 추천 시스템에서 협업 필터링을 사용하면,
고객이 이전에 좋아했던 영화와 비슷한 영화를 좋아하는
다른 고객들의 취향을 분석하여,
해당 고객이 좋아할 만한 영화를 추천할 수 있다.

- 협업 필터링은 사람들이 좋아하는 것들에 대한 데이터를 사용해서,
-
주요 개념
- 유사도 계산
코사인 유사도, 피어슨 상관계수 등을 사용하여 유사도를 계산 - 평점 행렬
사용자 - 아이템 평점을 행렬 형태로 저장하여 분석에 활용.
- 유사도 계산
-
유형
-
사용자 기반 협업 필터링 (User-Based Collaborative Filtering)
- 비슷한 취향의 고객들이 좋아한 아이템을 추천하는 방식
- 예시
A 고객과 비슷한 영화를 좋아하는 B 고객이
X 영화를 좋아하면, A 고객에게 X 영화를 추천
-
아이템 기반 협업 필터링 (Item-Based Collaborative Filtering)
- 비슷한 아이템들을 찾아 추천하는 방식
- 예시
고객이 좋아하는 X 영화와 비슷한 Y 영화 추천
-
-
협업 필터링의 예시
- Netflix 영화 추천 : 사용자의 시청 기록을 분석하여
비슷한 취향의 사용자가 좋아하는 영화를 추천 - Amazon 상품 추천 : 고객이 구매한 상품과 비슷한 상품을
다른 고객들이 구매한 데이터를 바탕으로 추천
- Netflix 영화 추천 : 사용자의 시청 기록을 분석하여
+) 유사도 계산
유사도 계산은 협업 필터링에서 중요한 단계 중 하나로,
사용자들 간 또는 아이템들 간의 유사성을 측정하는 방법이다.
대표적인 방법으로 코사인 유사도와 피어슨 상관계수가 있다.
-
코사인 유사도 (Cosine Similarity)- 코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여 유사도를 계산한다. 주로 벡터화된 사용자 또는 아이템의 속성을 비교할 때 사용된다.
-
계산 방법
- 벡터화: 각 사용자나 아이템을 n차원 벡터로 표현한다. 예를 들어, 각 사용자에 대해 아이템에 대한 평가 점수를 벡터로 만든다.
- 코사인 각도: 두 벡터 간의 코사인 각도를 계산하여 유사도를 측정한다. 코사인 값은 -1에서 1 사이의 값을 가지며, 1에 가까울수록 두 벡터가 유사함을 의미한다.
-
피어슨 상관계수 (Pearson Correlation Coefficient)- 피어슨 상관계수는 두 변수 간의 선형 상관관계를 측정한다.
주로 사용자 간의 평가 패턴의 유사성을 비교할 때 사용된다.
- 피어슨 상관계수는 두 변수 간의 선형 상관관계를 측정한다.
-
계산 방법
- 평균 중심화: 각 사용자나 아이템의 평가 점수에서 평균을 뺀다.
- 공분산: 두 변수의 공분산을 계산한다.
- 표준 편차: 각 변수의 표준 편차를 계산한다.
- 상관계수: 공분산을 표준 편차의 곱으로 나누어 상관계수를 구한다.
#최종 프로젝트 진행
-
데이터 전처리 (2)
- 조인한 데이터 테이블로 분석을 진행할 경우,
데이터 증폭과 중복에 대한 문제가 발생 - 각 테이블에서 팀 회의 결과로 결정된 전처리 후 csv 변환

- 조인한 데이터 테이블로 분석을 진행할 경우,
- L2 (유클리드) 거리 기반 유사도 계산
협업 필터링에서 유사도 계산하는 코사인 유사도는 아니지만,
Faiss를 이용한 인덱스 생성으로 L2 거리 기반 유사도 검색 시도
import pandas as pd
import re
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
articles_df = articles.copy()
# 필요한 특성 선택 및 전처리
selected_columns = [
'article_id', 'prod_name', 'product_type_name', 'product_group_name',
'graphical_appearance_name', 'colour_group_name', 'perceived_colour_value_name',
'perceived_colour_master_name', 'department_name', 'index_name',
'section_name', 'garment_group_name'
]
articles_df = articles_df[selected_columns]
articles_df['combined_features'] = articles_df.apply(lambda row: ' '.join([
str(row['prod_name']),
str(row['product_type_name']),
str(row['product_group_name']),
str(row['graphical_appearance_name']),
str(row['colour_group_name']),
str(row['perceived_colour_value_name']),
str(row['perceived_colour_master_name']),
str(row['department_name']),
str(row['index_name']),
str(row['section_name']),
str(row['garment_group_name'])
]), axis=1)
# 소문자 변환 및 불용어 제거 함수
def preprocess_text(text):
text = text.lower()
text = re.sub(r'\b(?:{})\b'.format('|'.join(ENGLISH_STOP_WORDS)), '', text)
text = re.sub(r'\s+', ' ', text)
return text
# 텍스트 데이터 전처리 적용
articles_df['combined_features'] = articles_df['combined_features'].apply(preprocess_text)
# TF-IDF Vectorizer를 사용하여 텍스트 벡터화
tfidf = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf.fit_transform(articles_df['combined_features'])
# Sparse matrix를 numpy array로 변환
tfidf_matrix = tfidf_matrix.toarray().astype('float32')
import faiss
# faiss 인덱스 생성
d = tfidf_matrix.shape[1]
index = faiss.IndexFlatL2(d)
faiss.normalize_L2(tfidf_matrix)
# 인덱스에 벡터 추가
index.add(tfidf_matrix)
def recommend_products(product_id, index, df=articles_df, top_n=10):
# 제품 인덱스 찾기
idx = df[df['article_id'] == product_id].index[0]
# 제품 벡터 가져오기
product_vector = tfidf_matrix[idx].reshape(1, -1).astype('float32')
# 유사한 제품 검색
D, I = index.search(product_vector, top_n + 1) # +1 to exclude the product itself
# 추천 제품의 인덱스 받기
recommended_indices = I[0][1:]
# 추천 제품의 세부 정보 반환
return df.iloc[recommended_indices]
# 특정 제품에 대한 추천 예시
product_id = 108775015
recommended_products = recommend_products(product_id, index)
print(recommended_products[['article_id', 'prod_name', 'product_type_name', 'product_group_name']])
1. 텍스트 전처리 및 TF-IDF 벡터화:
TfidfVectorizer를 사용하여 텍스트 데이터를 벡터화.
tfidf_matrix는 각 제품의 특징을 TF-IDF 방식으로 변환한 벡터들로 구성.
2. Faiss를 이용한 인덱스 생성:
faiss.IndexFlatL2를 사용하여 L2 거리 기반의 인덱스를 생성.
faiss.normalize_L2(tfidf_matrix)를 사용하여 벡터를 L2 정규화.
index.add(tfidf_matrix)로 인덱스에 벡터 추가.
3. 제품 추천 함수:
recommend_products 함수는 주어진 product_id에 대해 유사한 제품을 찾음.
유사도를 계산할 때 L2 거리(유클리드 거리)를 사용.
index.search를 통해 가장 유사한 제품들을 찾음.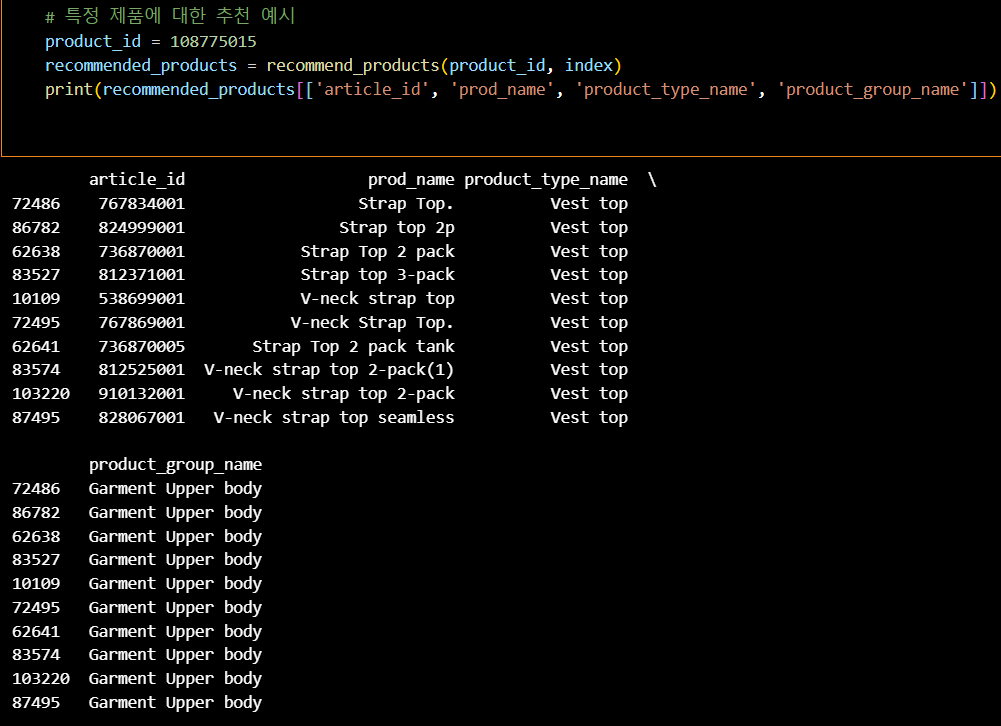
#OUTRO
오늘의 한 줄.
집중하자!

커피 좋아하는 데이터 꿈나무