
#INTRO
맛있는 고기쌈 :)

#최종 프로젝트 진행
- R, F, M 각 컬럼별로 분류를 하기 위해 각 수치별 통계량을 확인하고,
정량적인 기준을 정해 고객을 분류하기로 했다.- 고객 상태 기준으로 분류
- 거래 데이터에서
club_member_status가ACTIVE또는PRE-CREATE인 고객을 active_customers로 분류하고 해당 고객들에 대한 RFM 분석 시도
- 거래 데이터에서
- 고객 상태 기준으로 분류
.
- Recency 계산
# 각 고객의 마지막 거래 날짜와 현재 날짜의 차이를 계산하여 Recency 값 구하기
active_transactions_rfm['t_dat'] = pd.to_datetime(active_transactions_rfm['t_dat'])
active_rfm_recency = active_transactions_rfm.groupby('customer_id_le')['t_dat'].max().reset_index()
active_rfm_recency['Recency'] = (current_date - active_rfm_recency['t_dat']).dt.days
- Frequency 계산
# 각 고객의 총 거래 횟수를 계산하여 Frequency 값 구하기
active_rfm_frequency = active_transactions_rfm.groupby('customer_id_le')['receipt_no'].count().reset_index()
active_rfm_frequency.columns = ['customer_id_le', 'Frequency']- Monetary 계산
# 각 고객의 총 구매 금액을 계산하여 Monetary 값 구하기
active_rfm_monetary = active_transactions_rfm.groupby('customer_id_le')['total_price'].sum().reset_index()
active_rfm_monetary.columns = ['customer_id_le', 'Monetary']- RFM 데이터 통합
# Recency, Frequency, Monetary 값을 active_rfm으로 통합
active_rfm = active_rfm_recency.merge(active_rfm_frequency, on='customer_id_le')
active_rfm = active_rfm.merge(active_rfm_monetary, on='customer_id_le')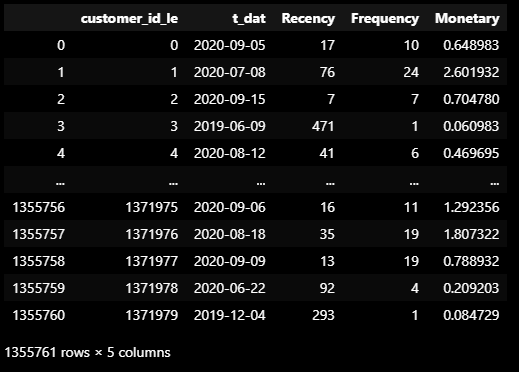
DECILE 분석 (Monetary 기준 고객 그룹 분류)
- Monetary 그룹화 함수 정의 및 적용
# Monetary 값을 기준으로 고객을 10개의 그룹으로 나누는 함수 정의
def Monetary_group(df):
df['Monetary_group'] = 0 # 새로운 컬럼 초기화
df.loc[df['Monetary'] > 1.63, 'Monetary_group'] = 10
df.loc[(df['Monetary'] <= 1.63) & (df['Monetary'] > 0.9), 'Monetary_group'] = 9
df.loc[(df['Monetary'] <= 0.9) & (df['Monetary'] > 0.56), 'Monetary_group'] = 8
df.loc[(df['Monetary'] <= 0.56) & (df['Monetary'] > 0.37), 'Monetary_group'] = 7
df.loc[(df['Monetary'] <= 0.37) & (df['Monetary'] > 0.25), 'Monetary_group'] = 6
df.loc[(df['Monetary'] <= 0.25) & (df['Monetary'] > 0.17), 'Monetary_group'] = 5
df.loc[(df['Monetary'] <= 0.17) & (df['Monetary'] > 0.11), 'Monetary_group'] = 4
df.loc[(df['Monetary'] <= 0.11) & (df['Monetary'] > 0.07), 'Monetary_group'] = 3
df.loc[(df['Monetary'] <= 0.07) & (df['Monetary'] > 0.04), 'Monetary_group'] = 2
df.loc[(df['Monetary'] <= 0.04), 'Monetary_group'] = 1
return df
# 함수 실행해서 df1으로 분석하기
df1 = Monetary_group(df)
- 그룹별 통계량 확인
# Monetary_group을 기준으로 각 그룹의 통계량 계산
df1_agg = df1.groupby('Monetary_group').agg(
고객수 = ('customer_id_le', 'nunique'),
총매출 = ('Monetary', 'sum'),
최소매출 = ('Monetary', 'min'),
최대매출 = ('Monetary', 'max'),
인당평균매출 = ('Monetary', 'mean'),
총구매횟수 = ('Frequency', 'sum'),
최소구매횟수 = ('Frequency', 'min'),
최대구매횟수 = ('Frequency', 'max'),
평균구매횟수 = ('Frequency', 'mean')
)
# 통계량 확인 및 총매출 기준 정렬
df1_agg.sort_values(by='총매출', ascending=False).reset_index(drop=True)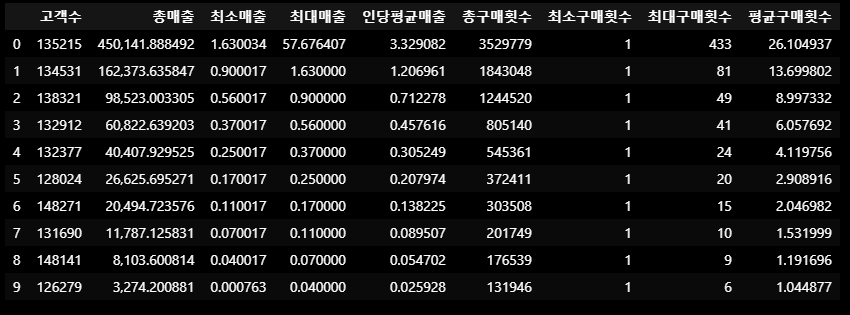
총 매출과 인당 평균매출 등의 통계량을 확인하고, 분포를 확인하면서
10등분의 그룹을 어떤 기준으로 나누어 몇 개의 그룹으로 분류할 것인지 정할 예정.
군집화 결과
-
기준
- 연속형 변수 : rfm 지표 + 평균 방문 주기 (avg_term)
- 범주형 변수 : 나이대(age_bin), club_member_status, fashion_news_frequency
- 결론 : 5개 집단 군집화가 적합한 것으로 보임
-
X_freatures
- 연속형 : ['recency','frequency','monetary','avg_term'] → 스케일링 진행
- 범주형 : ['age_bin',’channel_status_le’] → 스케일링 미진행 (나이대와 구매 경로에 대한 분류를 명확하게 하기 위함)
-
Inertia plot
inertia값이 작을수록 군집 내 데이터 포인트들이 군집 중심에 가까워져 더 응집력이 강한 군집을 의미- 급격하게 꺾여 들어가는 구간으로 군집수 결정 (4~5)
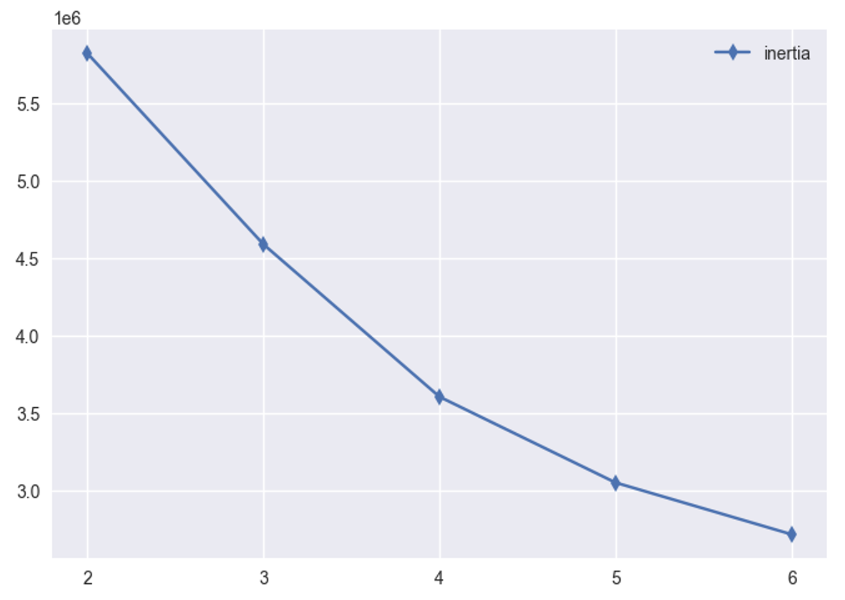
-
X_featrue line plot
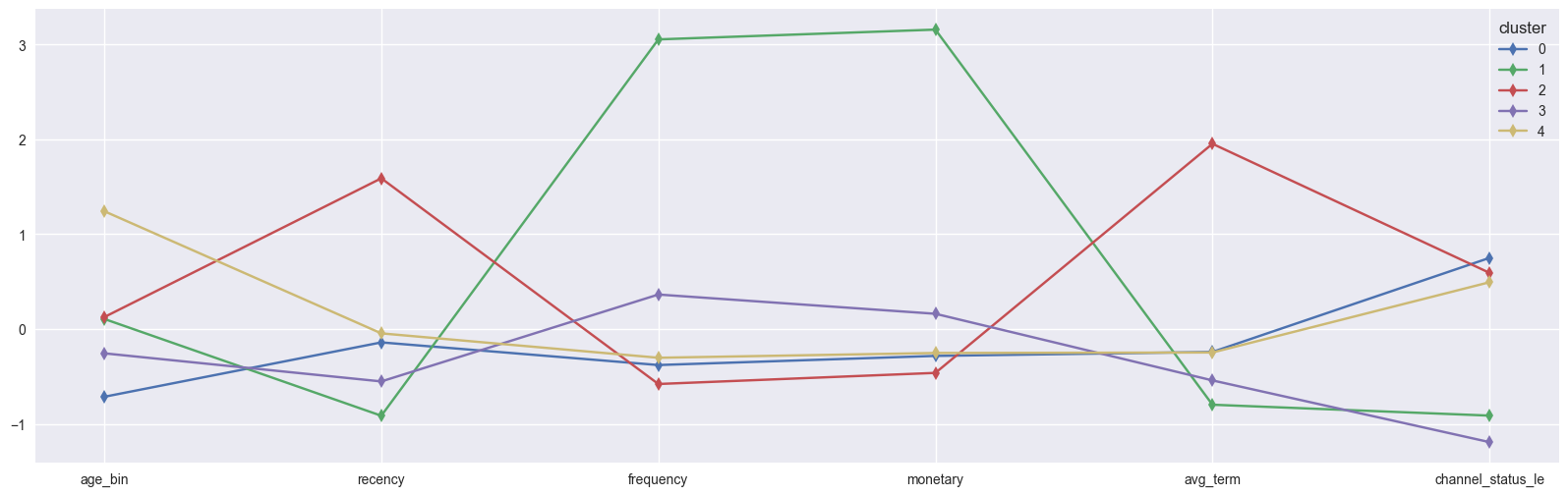
-
PCA plot

정리
군집화 결과와 RFM 세그먼트를 함께 붙여서,
비즈니스 상 집중해야 할 고객들의 특징을 정리하고,
어떤 지표를 주로 확인하면서 비즈니스 전략을 가져가야할 지에 집중해서
분석 결과와 결과물을 도출하자.
#OUTRO
오늘의 한 줄.
오늘도 고생했다.

커피 좋아하는 데이터 꿈나무