
#INTRO
놀러가고 싶구만!

#코드카타
-
PANDAS
-
조건필터가 2개 이상일 때, 각 조건에 소괄호
( )필요# 예시 # 1. 조건필터 2개를 데이터프레임화하여 변수에 저장 world = world[(world['area'] >= 3000000) | (world['population'] >= 25000000)] # 2. 조건필터 2개를 변수에 저장 후 데이터프레임화 cond = (products['low_fats'] == 'Y') & (products['recyclable'] == 'Y') products[cond][['product_id']]
-
#최종 프로젝트 진행
모델링 결과
- 로지스틱 회귀 모델 ( f1_score : 0.7 )
- 랜덤 포레스트 모델 ( f1_score : 0.83 )
라이트 그래디언트 부스트 모델 ( f1_score : 0.85 )
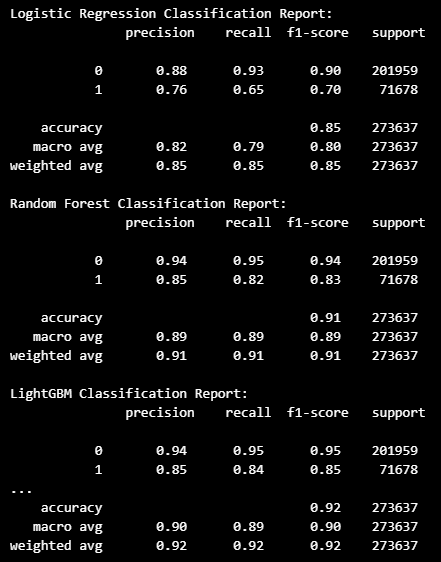
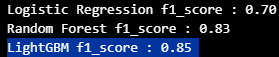
가장 좋은 성능을 보여주는
LGBM 으로 학습한 모델로 예측 확률을 확인하기로 결정.
모델 모듈화
- 전체 코드
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler, LabelEncoder
import lightgbm as lgb
import datetime as dt
import calendar
# 데이터 불러오기
transactions = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/h&m/preprocessed/transactions.csv')
transactions
# transactions 데이터 날짜 기준 필터링 함수
def transactions_filter(df, year, month):
df['t_dat'] = pd.to_datetime(df['t_dat'], yearfirst=True)
df['t_dat_ym'] = df['t_dat'].dt.to_period('M')
df_filtered = df[df['t_dat_ym'] <= str(year) + '-' + str(month)]
last_day_of_month = calendar.monthrange(year, month)[1]
current_date = dt.datetime(year, month, last_day_of_month)
return df_filtered, current_date
# 고객 구매 기록 기준 RFM, 구매주기, 연령대 테이블 생성 함수
def get_rfm(transactions_filtered, customers, current_date):
r = (current_date - transactions_filtered.groupby('customer_id_le')['t_dat'].max()).dt.days.to_frame().rename({'t_dat': 'Recency'}, axis=1)
fm = transactions_filtered.groupby('customer_id_le').agg(
{'receipt_no': 'count',
'price': 'sum'}
).rename({'receipt_no': 'Frequency', 'price': 'Monetary'}, axis=1).reset_index()
customer_min_max_date = transactions_filtered.groupby('customer_id_le')['t_dat'].agg(['min', 'max'])
customer_min_max_date['days'] = (customer_min_max_date['max'] - customer_min_max_date['min']).dt.days
customer_min_max_date = customer_min_max_date.merge(fm[['customer_id_le', 'Frequency']], how='inner', on='customer_id_le')
customer_min_max_date['purchase_cycle'] = customer_min_max_date['days'] / (customer_min_max_date['Frequency'] - 1)
customer_min_max_date['purchase_cycle'].fillna(0, inplace=True)
rfm = pd.merge(r, fm, how='inner', on='customer_id_le')
rfm = pd.merge(rfm, customer_min_max_date[['customer_id_le', 'purchase_cycle']], how='inner', on='customer_id_le')
rfm = pd.merge(rfm, customers[['customer_id_le', 'age']], how='inner', on='customer_id_le')
bin = [10, 20, 30, 40, 50, 60, float('inf')]
label = ['10s', '20s', '30s', '40s', '50s', 'over 60s']
rfm['age_bin'] = pd.cut(rfm['age'], bins=bin, labels=label, right=False)
rfm = rfm.drop(columns=['age'])
return rfm
# 고객 정보 요약 RFM 데이터 전처리 (로그화 및 스케일링)
def get_preprocess(df, sd, le):
df = df[df['purchase_cycle'] != 0].reset_index(drop=True)
df_num_log = pd.DataFrame(np.log10(df[['Monetary', 'purchase_cycle']].replace(0, 1e-10)), columns=['Monetary', 'purchase_cycle'])
df_num = df[['Recency', 'Frequency']]
df_cat = pd.DataFrame(le.transform(df['age_bin']), columns=['age_bin'])
df_concat = pd.concat([df_num_log, df_num, df_cat], axis=1)
df_scaled = pd.DataFrame(sd.transform(df_concat), columns=df_concat.columns)
df = pd.concat([df['customer_id_le'], df_scaled], axis=1)
return df
# LGBM 예측값 생성 함수
def get_proba(df, lgbm):
df_pred = pd.DataFrame(lgbm.predict_proba(df.iloc[:, 1:]), columns=[0, 1])
df = pd.concat([df['customer_id_le'], df_pred], axis=1)
return df
# 날짜 설정 후 고객별 월별 이탈 확률 자동화 및 데이터프레임 생성 반복문
date_range = pd.date_range(start='2019-09-01', end='2020-09-30', freq='MS')
churn_rating = pd.DataFrame(columns=['customer_id_le', 'churn_rate', 'base_ym'])
for date in date_range:
year, month = date.year, date.month
transactions_filtered, current_date = transactions_filter(transactions, year, month)
rfm = get_rfm(transactions_filtered, customers, current_date)
df_scaled = get_preprocess(rfm, sd, le)
df_proba = get_proba(df_scaled, lgbm)
churn_rate = pd.merge(df_proba, rfm[['customer_id_le']], how='right', on='customer_id_le').iloc[:, [0, 2]].fillna(1).rename({1: 'churn_rate'}, axis=1)
churn_rate['churn_rate'] = churn_rate['churn_rate'] * 100
churn_rate['base_ym'] = pd.to_datetime(current_date).to_period('M')
churn_rating = pd.concat([churn_rating, churn_rate], ignore_index=True)
# 최종 결과
churn_rating- 코드별 작동 원리
데이터 로드
- 먼저
transactions데이터프레임을 CSV 파일에서 로드
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler, LabelEncoder
import lightgbm as lgb
import datetime as dt
import calendar
# 데이터 불러오기
transactions = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/h&m/preprocessed/transactions.csv')
transactions거래 데이터 날짜 기준 필터링 함수 생성
- 주어진 연도와 월에 맞춰 현재 날짜를 설정하고 거래 데이터를 필터링하는 함수
def transactions_filter(df, year, month):
df['t_dat'] = pd.to_datetime(df['t_dat'], yearfirst=True) # t_dat 컬럼을 datetime 형식으로 변환
df['t_dat_ym'] = df['t_dat'].dt.to_period('M') # 연도와 월 단위로 변환하여 새로운 컬럼 생성
df_filtered = df[df['t_dat_ym'] <= str(year) + '-' + str(month)] # 주어진 연도와 월 이하의 데이터 필터링
last_day_of_month = calendar.monthrange(year, month)[1] # 주어진 월의 마지막 날 계산
current_date = dt.datetime(year, month, last_day_of_month) # 현재 날짜 설정
return df_filtered, current_date # 필터링된 데이터와 현재 날짜 반환고객 구매 기록 기준 RFM, 구매주기, 연령대 테이블 생성 함수
- 필터링된 거래 데이터와 고객 데이터를 사용하여
RFM 값을 계산하고 구매 주기와 연령대 수치를 포함한 테이블을 생성하는 함수
def get_rfm(transactions_filtered, customers, current_date):
# Recency 계산
r = (current_date - transactions_filtered.groupby('customer_id_le')['t_dat'].max()).dt.days.to_frame().rename({'t_dat': 'Recency'}, axis=1)
# Frequency와 Monetary 계산
fm = transactions_filtered.groupby('customer_id_le').agg(
{'receipt_no': 'count', 'price': 'sum'}
).rename({'receipt_no': 'Frequency', 'price': 'Monetary'}, axis=1).reset_index()
# 고객별 첫 구매일과 마지막 구매일 계산 및 구매주기 계산
customer_min_max_date = transactions_filtered.groupby('customer_id_le')['t_dat'].agg(['min', 'max'])
customer_min_max_date['days'] = (customer_min_max_date['max'] - customer_min_max_date['min']).dt.days
customer_min_max_date = customer_min_max_date.merge(fm[['customer_id_le', 'Frequency']], how='inner', on='customer_id_le')
customer_min_max_date['purchase_cycle'] = customer_min_max_date['days'] / (customer_min_max_date['Frequency'] - 1)
customer_min_max_date['purchase_cycle'].fillna(0, inplace=True)
# RFM 데이터 통합
rfm = pd.merge(r, fm, how='inner', on='customer_id_le')
rfm = pd.merge(rfm, customer_min_max_date[['customer_id_le', 'purchase_cycle']], how='inner', on='customer_id_le')
rfm = pd.merge(rfm, customers[['customer_id_le', 'age']], how='inner', on='customer_id_le')
# 연령대를 나누어 그룹화
bin = [10, 20, 30, 40, 50, 60, float('inf')]
label = ['10s', '20s', '30s', '40s', '50s', 'over 60s']
rfm['age_bin'] = pd.cut(rfm['age'], bins=bin, labels=label, right=False)
# 연령 컬럼 제거
rfm = rfm.drop(columns=['age'])
return rfm # RFM 데이터 반환
고객 정보 요약 RFM 데이터 전처리 (로그화 및 스케일링)
- 분포가 몰린 Monetary, purchase_cycle 컬럼의 로그 변환 및 전체 수치 스케일링하는 함수
def get_preprocess(df, sd, le):
df = df[df['purchase_cycle'] != 0].reset_index(drop=True) # 구매주기가 0이 아닌 데이터만 선택하고 인덱스 재설정
df_num_log = pd.DataFrame(np.log10(df[['Monetary', 'purchase_cycle']].replace(0, 1e-10)), columns=['Monetary', 'purchase_cycle']) # Monetary와 purchase_cycle 로그 변환
df_num = df[['Recency', 'Frequency']] # Recency와 Frequency 선택
df_cat = pd.DataFrame(le.transform(df['age_bin']), columns=['age_bin']) # age_bin 레이블 인코딩
df_concat = pd.concat([df_num_log, df_num, df_cat], axis=1) # 모든 데이터를 하나의 데이터프레임으로 병합
df_scaled = pd.DataFrame(sd.transform(df_concat), columns=df_concat.columns) # 스케일링
df = pd.concat([df['customer_id_le'], df_scaled], axis=1) # 고객 ID와 스케일링된 데이터 병합
return df # 전처리된 데이터 반환LGBM 예측값 생성 함수
- 모델을 사용하여 고객 이탈 확률을 예측하는 함수
def get_proba(df, lgbm):
df_pred = pd.DataFrame(lgbm.predict_proba(df.iloc[:, 1:]), columns=[0, 1]) # 예측 확률 계산
df = pd.concat([df['customer_id_le'], df_pred], axis=1) # 고객 ID와 예측 확률 병합
return df # 예측 확률 데이터 반환
날짜 설정 후 고객별 월별 이탈 확률 자동화 및 데이터프레임 생성 반복문
- 주어진 날짜 범위에 따라 월별로 고객의 이탈 확률을 예측하고
결과를 데이터프레임에 저장하는 반복문
# 날짜 설정 후 고객별 월별 이탈 확률 자동화 및 데이터프레임 생성 반복문
date_range = pd.date_range(start='2019-09-01', end='2020-09-30', freq='MS')
churn_rating = pd.DataFrame(columns=['customer_id_le', 'churn_rate', 'base_ym'])
for date in date_range:
year, month = date.year, date.month
transactions_filtered, current_date = transactions_filter(transactions, year, month)
rfm = get_rfm(transactions_filtered, customers, current_date)
df_scaled = get_preprocess(rfm, sd, le)
df_proba = get_proba(df_scaled, lgbm)
churn_rate = pd.merge(df_proba, rfm[['customer_id_le']], how='right', on='customer_id_le').iloc[:, [0, 2]].fillna(1).rename({1: 'churn_rate'}, axis=1)
churn_rate['churn_rate'] = churn_rate['churn_rate'] * 100
churn_rate['base_ym'] = pd.to_datetime(current_date).to_period('M')
churn_rating = pd.concat([churn_rating, churn_rate], ignore_index=True)
# 최종 결과
churn_rating.head() # 최종 결과 출력
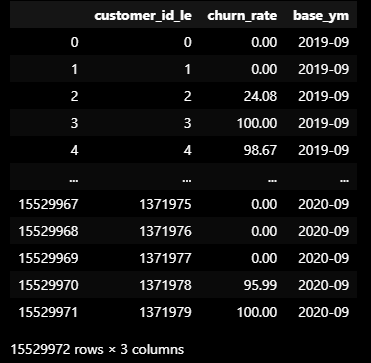
(예시) 2020년 4월 기준 고객 예측 확률 분포
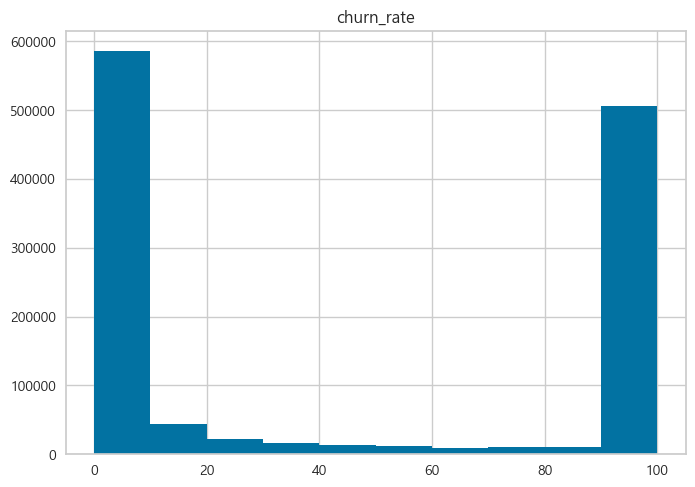
2019년 9월부터 2020년 9월까지 12개월의 기간을 월별로 나누어
각 월별 고객들의 예측된 이탈 확률을 월별 그룹으로 정리된 데이터.
- customer_id_le: 고객 ID
- churn_rate: 해당 월의 고객 이탈 확률 (백분율)
- base_ym: 기준 연월 (예측이 이루어진 월)
결과
예측 모델이 잘 기능을 한다는 것을 확인할 수 있었고,
해당 예측 결과를 태블로에 업로드해 이탈 고객 관리 대시보드를 구성하는 데 활용할 예정.
#OUTRO
오늘의 한 줄.
오늘도 고생했습니다요!

커피 좋아하는 데이터 꿈나무