
#INTRO
이번 달 곳간은 빈브라더스 시즌 원두로 채우기

#최종 프로젝트 진행
SMOTE를 활용한 오버 샘플링
결과
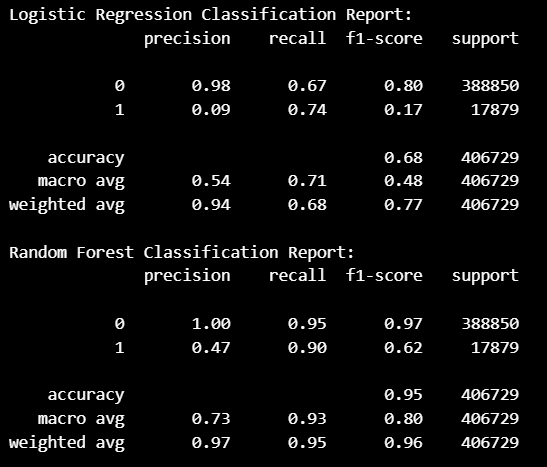
Recall과 F1-score에서 수치가 향상되기는 했지만,
활용할 수 있는 수준의 성능은 아니었다.
이탈 고객 재정의
-
팀원들과 회의를 통해 기존 이탈 고객으로 정의한 데이터의 수가 너무 작으니
이탈 고객의 범위를 다시 확인해서1의 수를 늘리는 방식을 선택했다. -
3번 군집의 코호트 리텐션
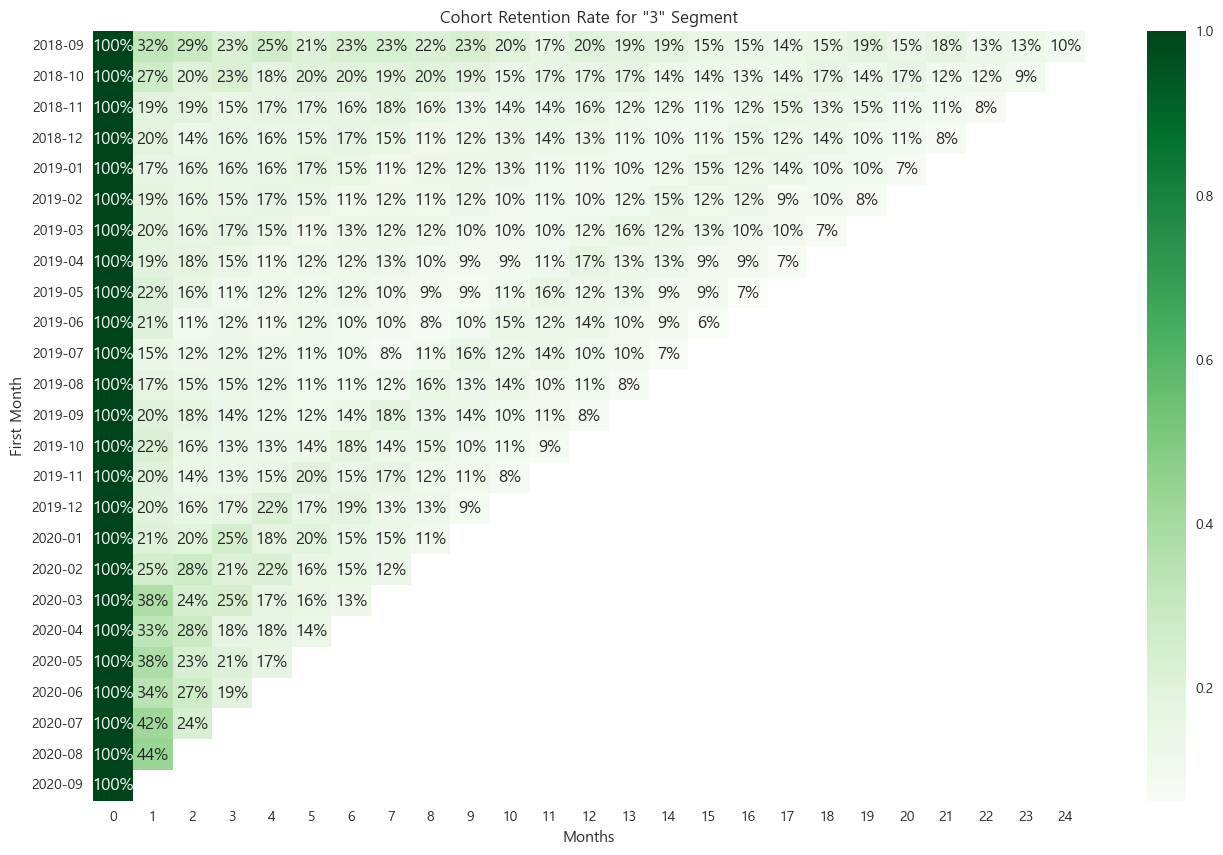
마지막 기간까지 잔존하는 고객이 있으나, 군집 전체적으로 리텐션이 많이 떨어지는 형태를 보여, 3번 군집에서의 RFM 세그멘테이션이이탈, 동면인 고객들을 함께 포함하기로 했다. -
3, 4번 군집의 이탈, 동면 고객각 교차점 고객들의 코호트 리텐션
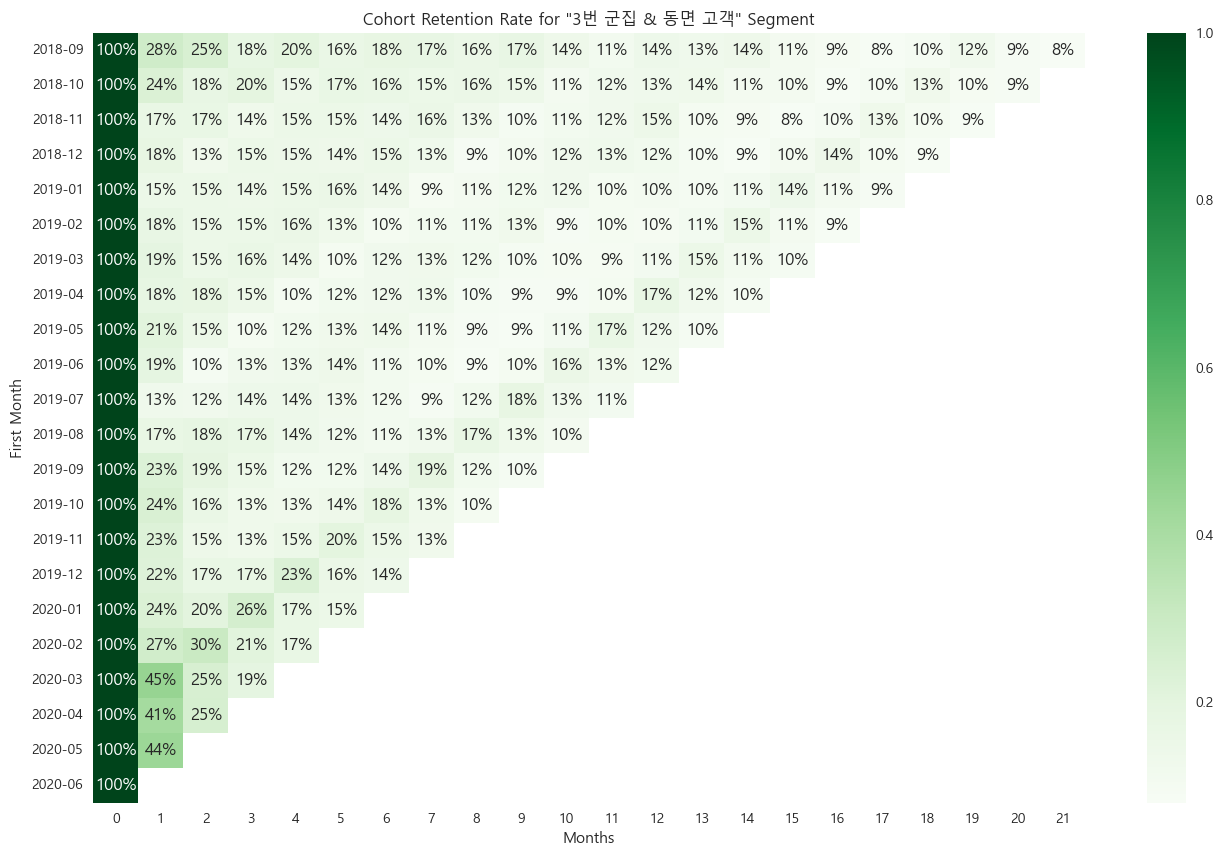
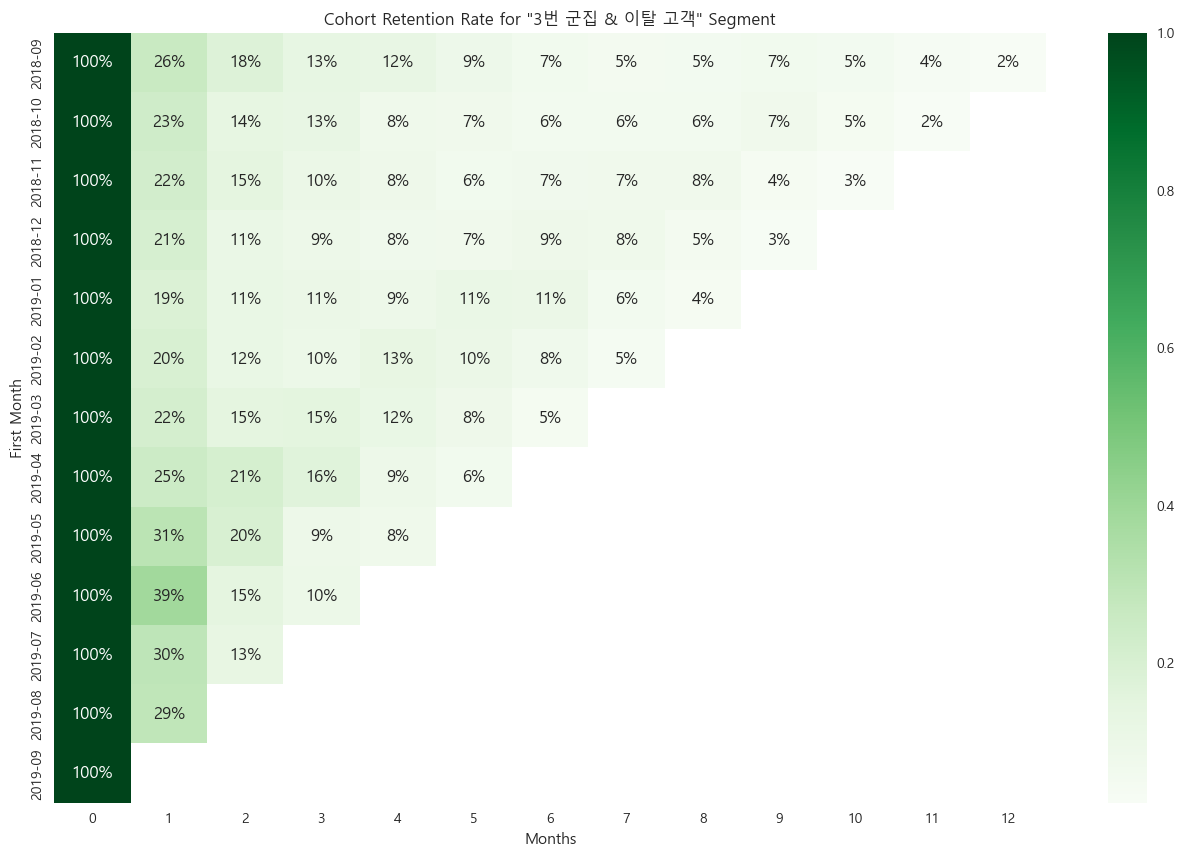
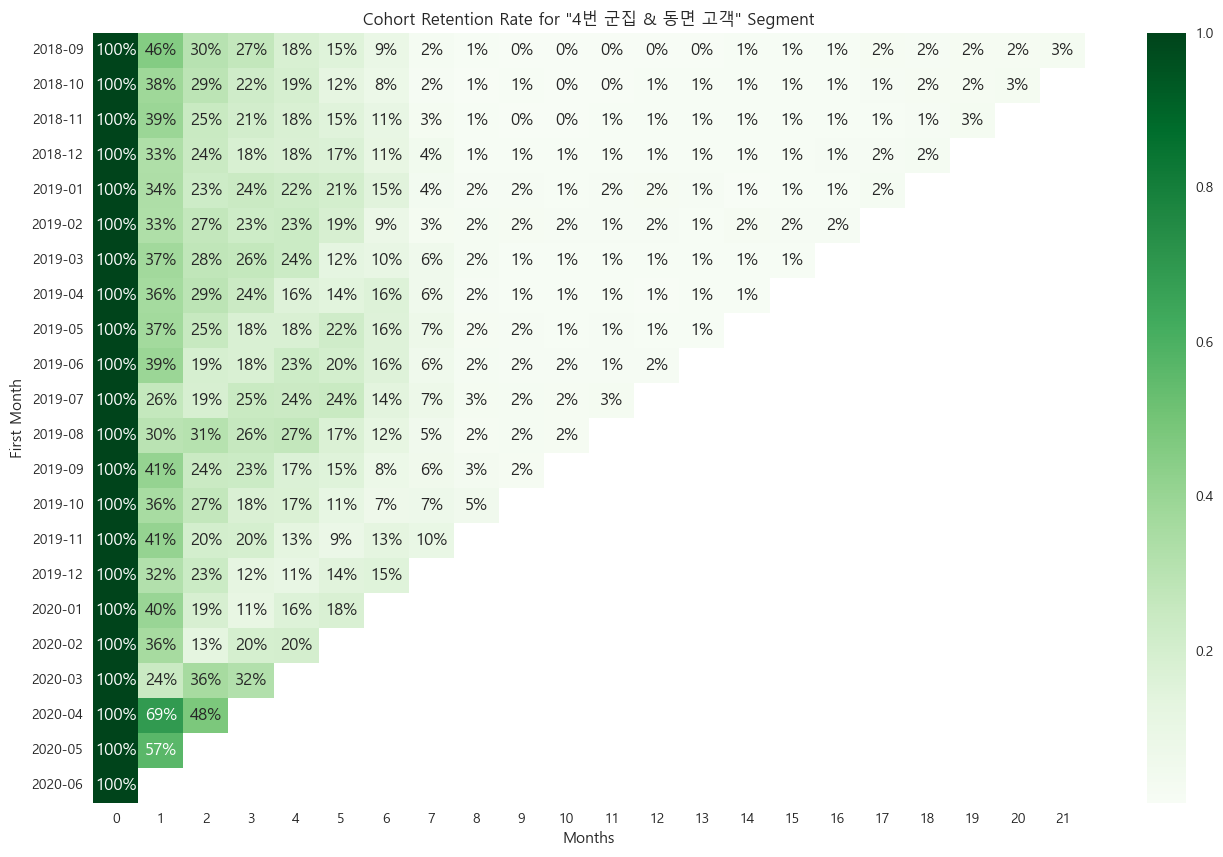
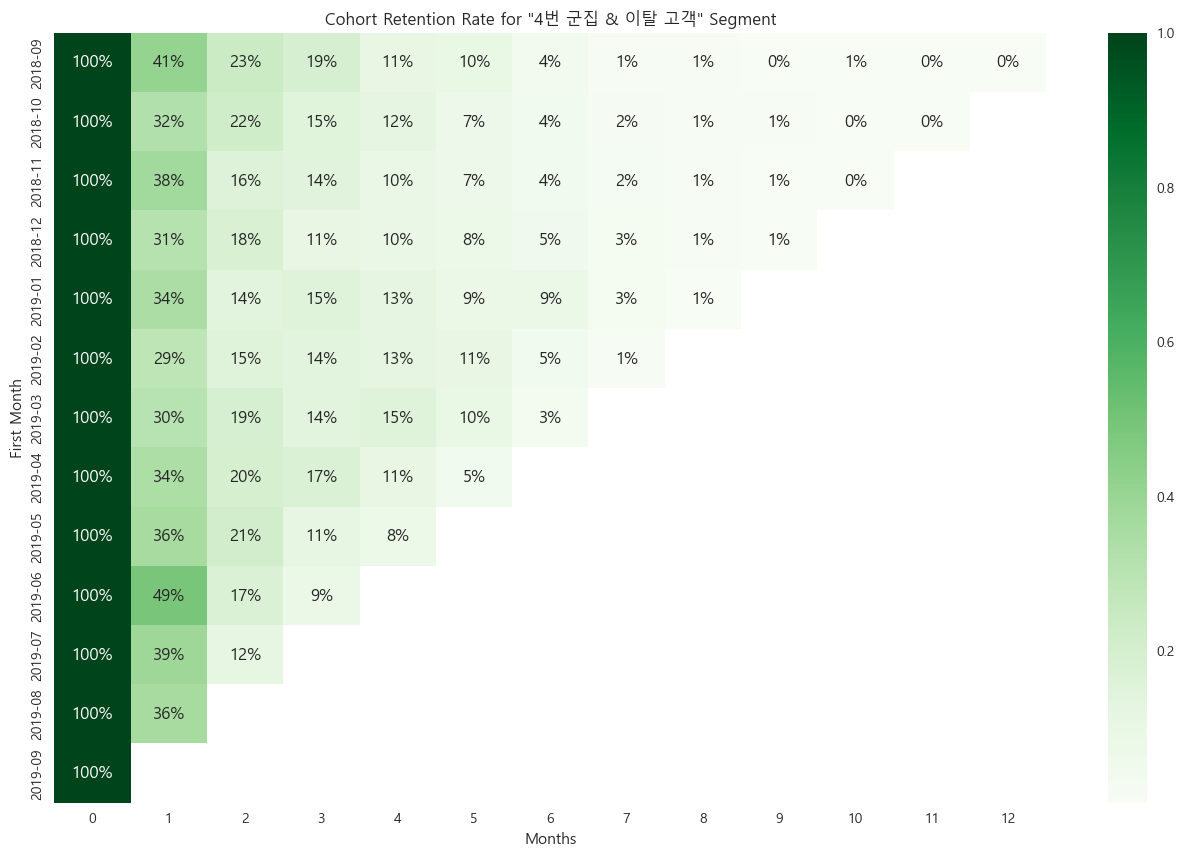
각 교차하는 고객들의 코호트 리텐션이 모두
이탈 고객의 특성을 잘 나타내는 것으로 판단했다.
따라서 아래와 같이 데이터셋을 재정리 후 모델링을 하였다.
데이터셋 재정리
-
기본 데이터 셋 :
Transactions 테이블 + Customers 테이블
= 2년 동안 구매한 이력이 있는 고객 中 ‘club_member_status’ 가
LEFT_CLUB인 고객 제외 (현재 데이터 기준 약 135만개 행) -
5번 군집 제외 :
1회성 구매 고객에 해당하는 5번 군집 고객 제외 (약 44만개 행) -
이탈여부 컬럼 부여 :
3, 4번 군집 + RFM 세그먼트 ('동면 고객', '이탈 고객') =1
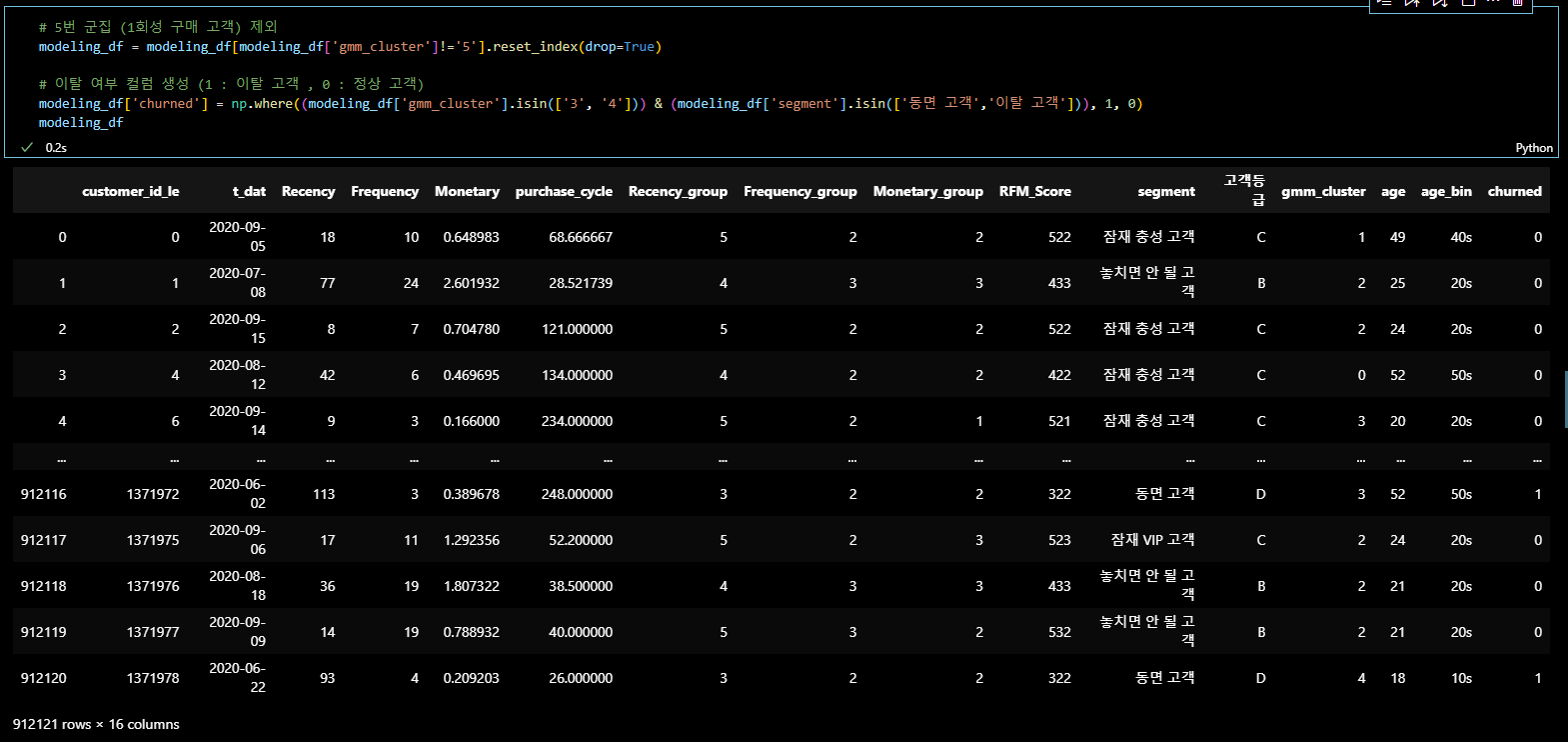
# 5번 군집 (1회성 구매 고객) 제외
modeling_df = modeling_df[modeling_df['gmm_cluster']!='5'].reset_index(drop=True)
# 이탈 여부 컬럼 생성 (1 : 이탈 고객 , 0 : 정상 고객)
modeling_df['churned'] = np.where((modeling_df['gmm_cluster'].isin(['3', '4'])) & (modeling_df['segment'].isin(['동면 고객','이탈 고객'])), 1, 0)
modeling_df모델링 데이터 전처리
- age 컬럼 → age_bin (나이대)로 변환
# modeling_df → 나이대 변환
bin = [10,20,30,40,50,60,float('inf')]
label = ['10s','20s','30s','40s','50s','over 60s']
modeling_df['age_bin'] = pd.cut(modeling_df['age'], bins=bin, labels=label, right=False)- age_bin 컬럼 레이블 인코딩
# age_bin 의 레이블 인코딩 진행
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
print(modeling_df['age_bin'].head())
print("\n", f"레이블 인코딩 전 customer_id의 고유값 개수 : {modeling_df['age_bin'].nunique()}")
# 레이블 인코딩
modeling_df['age_bin'] = le.fit_transform(modeling_df['age_bin'])
print("\n", "\n", modeling_df['age_bin'].head())
print("\n", f"레이블 인코딩 후 customer_id의 고유값 개수 : {modeling_df['age_bin'].nunique()}")- 데이터 분리 후
Monetary,purchase_cycle컬럼 로그화 및 스케일링
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 데이터 로드
modeling_df = pd.read_csv('C:/Users/BAEK/Desktop/CSV DB/ML/data_files/h&m/preprocessed/modeling_df.csv')
# 특성과 타겟 분리
X = modeling_df.drop(columns=['churned', 'customer_id_le'])
y = modeling_df['churned']
# 학습 데이터와 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify = y)
# Monetary, purchase_cycle = 로그화 / 전체 컬럼 스탠다드 스케일링 진행
X_train_num_log = pd.DataFrame(np.log10(X_train[['Monetary','purchase_cycle']]),columns=['Monetary','purchase_cycle'])
X_train_num = X_train[['Recency','Frequency', 'age_bin']]
X_train_concat = pd.concat([X_train_num_log,X_train_num],axis=1)
X_test_num_log = pd.DataFrame(np.log10(X_test[['Monetary','purchase_cycle']]),columns=['Monetary','purchase_cycle'])
X_test_num = X_test[['Recency','Frequency', 'age_bin']]
X_test_concat = pd.concat([X_test_num_log,X_test_num],axis=1)
# 데이터 스케일링
sd = StandardScaler()
X_train_scaled = sd.fit_transform(X_train_concat)
X_test_scaled = sd.transform(X_test_concat)
# 데이터프레임화
X_train = pd.DataFrame(X_train_scaled,columns=X_train_concat.columns)
X_test = pd.DataFrame(X_test_scaled,columns=X_test_concat.columns)
print(X_train.head(3))
print(X_test.head(3))모델링 결과
-
로지스틱 회귀 모델 ( f1_score : 0.7 )

-
랜덤 포레스트 모델 ( f1_score : 0.83 )

결과
성능이 많! 이! 좋아졌다.
이탈 고객에 대한 재정의를 통해 데이터 불균형 문제를 해결하고,
80% 이상의 예측 성능을 가진 모델링까지 완료.
이제 팀원들이 진행한 다른 모델링( LGBM / XGB ) 결과를 비교하여
성능이 가장 좋은 모델을 선택하고, 최종적으로 이탈 예측 확률 모델을 구축하여
BI 대시보드에 활용할 수 있게 하면 된다.
#OUTRO
오늘의 한 줄.
고생했다!
