
Intro
예전부터 너무 해보고 싶었던 해커톤에 처음으로 참가를 하게 되었다! Prompter Day Seoul 2023 해커톤은 SK Telecom와 Open AI가 함께 개최한 해커톤으로 인류를 위한 generative AI가 주제이다.
Process
해당 해커톤은 서류 예선 -> 발표 예선 -> 본선 프로세스를 가진다. 해당 프로세스마다 준비했던 과정을 정리를 해보고자 한다.
1️⃣ 서류
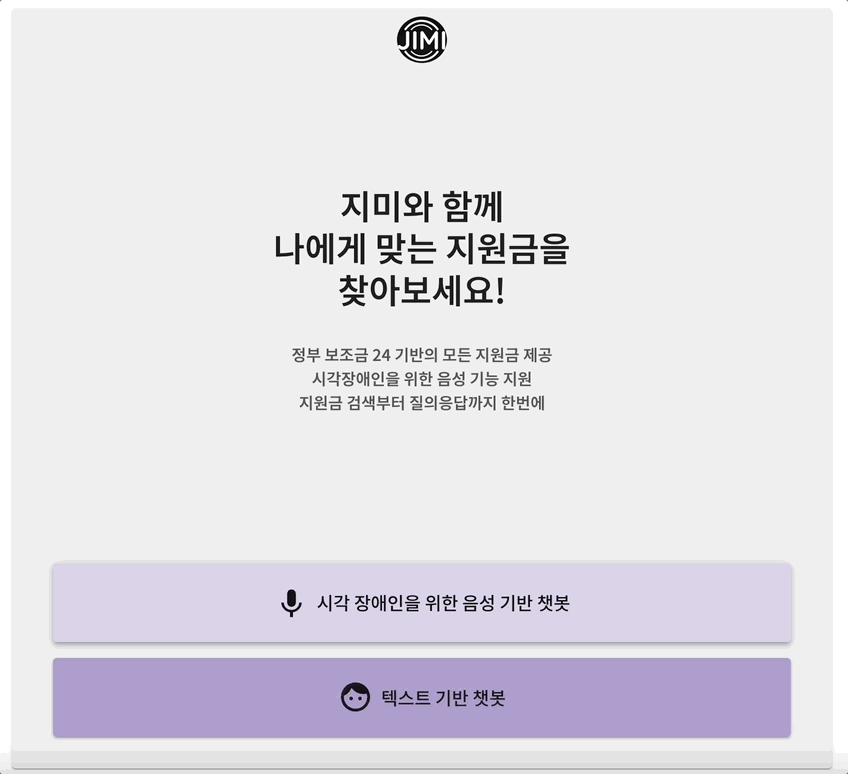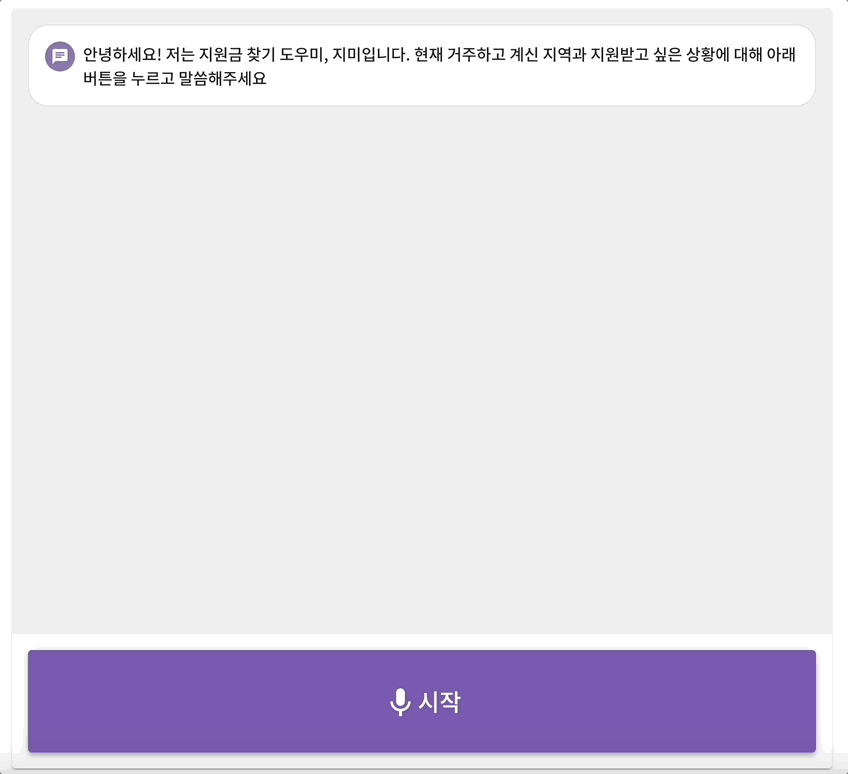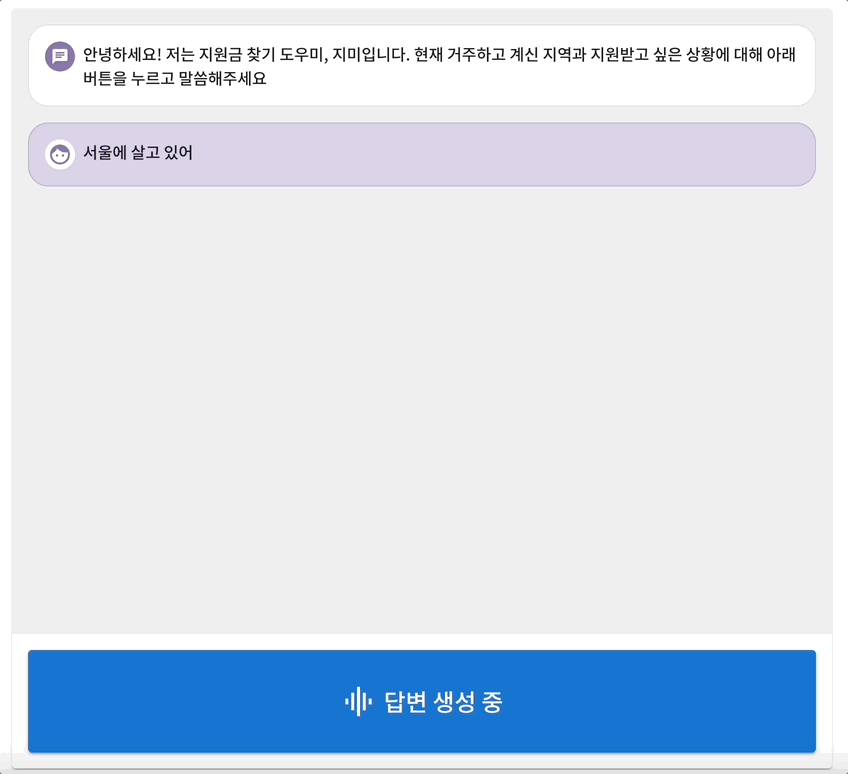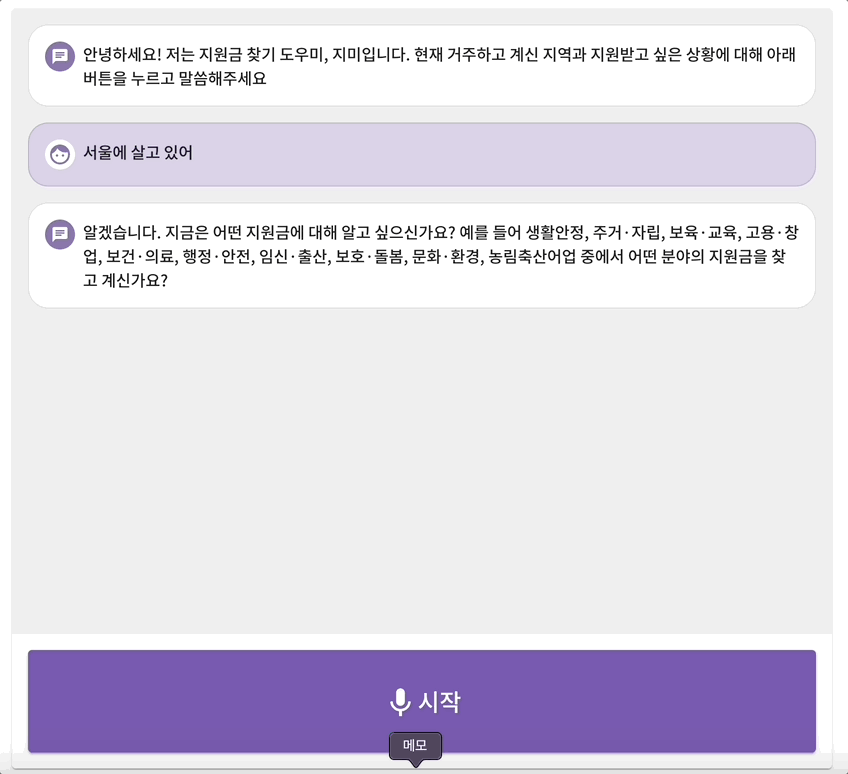
가장 중요한 것은 주제를 정하는 것이었다. 왜냐하면 독창성 부문이 중요하게 평가되기 때문이다. 나와 팀원은 인사이트를 얻기 위해 교보문고까지 가면서 열심히 기획했다ㅎ 최종적으로 우리는 사회적 약자를 위한 지원금 도우미 서비스, 지미를 기획하였다. 정부 지원금의 경우에 관련 내용이 어려운 용어로 적혀있어 이해하기 어려운 문제가 있었고 현재 존재하는 국민 비서 챗봇은 정형화된 답변을 제공하여 성능이 좋지 않았기 때문이다.
서류에 MVP 주소를 제출해야 했기에 우리는 바로 개발에 돌입했다.
우리 팀은 프론트엔드(나)와 AI 두명으로 구성되어 있었다. 따라서 최대한 DB를 사용하지 않는 서비스 구성을 해야했다. 먼저 통신을 위해 AWS 서버 구축을 하였다. 단순히 S3 버킷 엔드포인드를 서비스 url로 사용하였다.
지미의 mvp 서비스는 크게 세부분으로 구성되어 있었다. 첫번째 페이지에서 검색어 및 조건을 입력하면 두번째 페이지에서 그에 맞는 지원금 제도들이 제공된다. 그 중 하나를 선택하게 되면 세번째 페이지의 채팅으로 이동하게 된다. 그러면 채팅을 통해 해당 지원금에 대해 자세하게 질문하고 답변 받을 수 있다. 이때 gpt 3.5을 사용하여 프롬프트에 선택된 지원금의 정보를 넣어서 gpt가 적절한 답변을 생성할 수 있도록 하였다. 프롬프트의 정보로는 답변하지 못할 경우 구글 검색 api를 호출하여 답변할 수 있게 구현하였다.
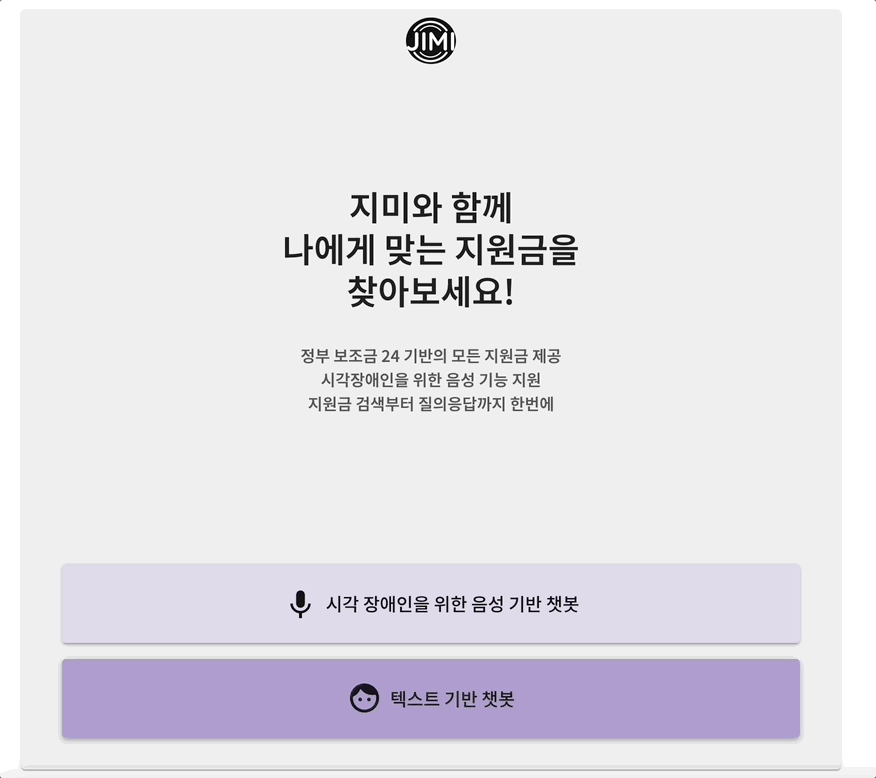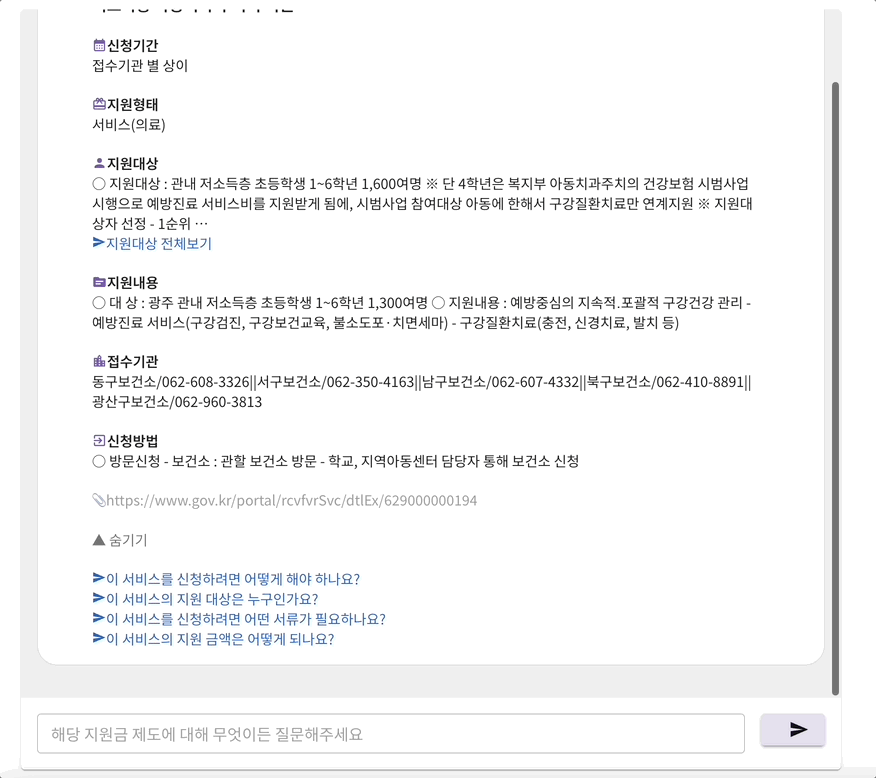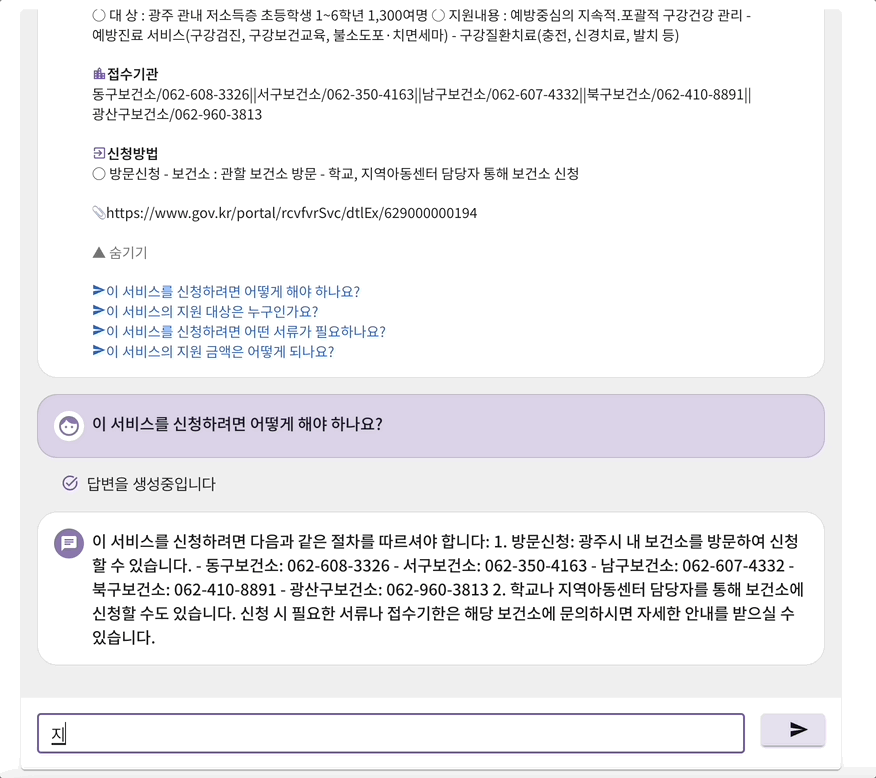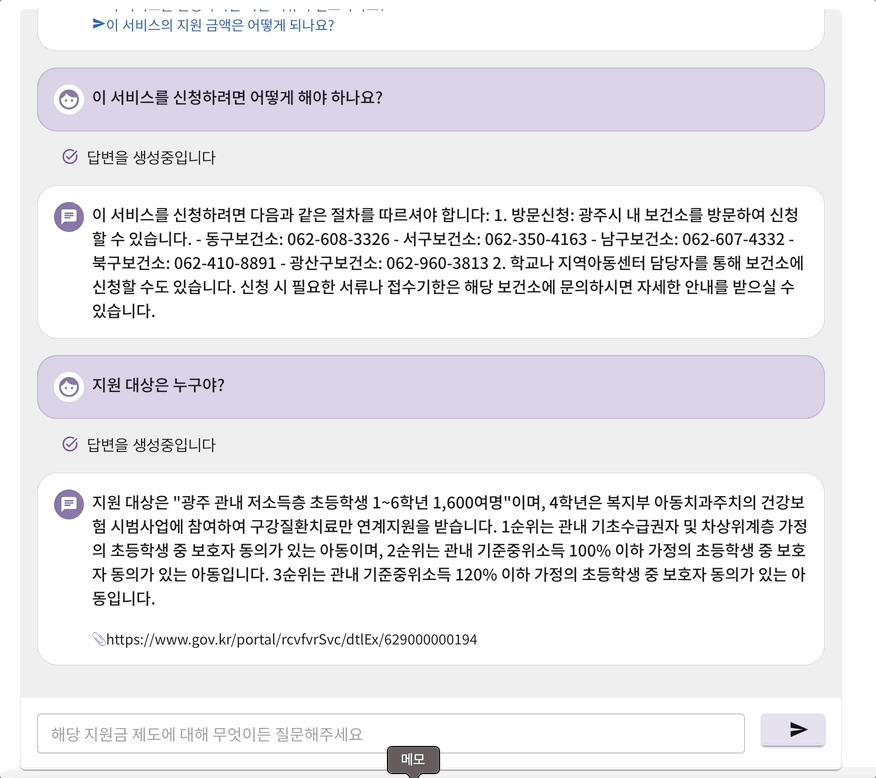
풀페이지 스크롤링을 적용시켜 보고자 react-fullpage 라이브러리를 사용하였다. 하지만 한가지 치명적인 문제점이 있었다. 마지막 채팅 페이지에서 채팅 내부 스크롤을 하게 되면, 채팅창이 스크롤 되는 것이 아니라 전체 창이 함께 스크롤되는 문제점이 있었다. 그와 관련된 옵션은 따로 없었기에 결국 해당 라이브러리 사용을 포기하고 직접 구현했다.
const NonVoice = () => {
const supportList= useSelector((state) => state.supportList)
const summary = useSelector((state) => state.summary)
const dispatch = useDispatch()
React.useEffect(()=> {
if(supportList === null){
window.scrollTo({top: 0, behavior: 'smooth' })
alert("검색 결과가 없습니다.")
dispatch({
type: SET_SUPPORT_LIST,
data: ""
})
}
else if (supportList.length > 0){
window.scrollTo({top: window.innerHeight, behavior: 'smooth' })
}
}, [supportList])
React.useEffect(()=> {
if (summary !==""){
window.scrollTo({top: window.innerHeight*2, behavior: 'smooth' })
}
}, [summary])
return (
<div>
<Box sx={{overflow: 'auto'}}>
<Box sx={{height: "100vh"}}>
<Intro/>
</Box>
{(supportList && supportList.length>0) && <Box sx={{height: "100vh"}}>
<SupportList />
</Box>}
{summary !=="" && <Box sx={{height: "100vh"}}>
<Chat/>
</Box>}
</Box>
</div>
)
}
export default NonVoiceRedux를 사용해서 다른 컴포넌트에서 supportList가 생기게 되면 아래로 부드럽게 스크롤되어 두번째 페이지( < SupportList /> )가 등장하도록 하였다. 그리고 두번째 페이지에서 summary가 생기게 되면 세번째 페이지(< Chat />)로 스크롤 되도록 구현하였다. 풀페이지 스크롤링과의 기능은 다르지만, 내부 스크롤을 가능하게 하여 사용성을 높일 수 있었다.
2️⃣ 발표
우리 서비스 지미는 다행이 서류에 통과를 하였다. 나중에 알고보니 서류에 지원한 팀은 무려 230팀이었다고 한다. 그 중 40팀 안에 선발이 된 것이다! 선발된 가장 큰 이유를 생각해보자면 서류의 완성도와 주제가 아니었을까 싶다.
발표는 온라인으로 진행되었다. 발표시간은 10분인데 질의응답을 포함한 시간이라 적절히 발표시간을 정해야 했다. 우리는 7분 내외로 발표를 하였다.
3️⃣ 본선
발표 평가에서도 통과하여 우리는 20팀 안에 선발이 되었다! 본선은 무박 2일 오프라인으로 진행되었다. 우리는 본선을 위한 개발 준비를 시작하였다. 시각장애인을 위한 음성 지원 피쳐를 기획하여 구현하고 하였다. 음성지원 피쳐는 마치 시리처럼 대화하듯이 진행되도록 구현하고자 하였기에 mvp가 세페이지로 나누어진 것과 달리 한페이지로 구현하였다. 이를 개발하기 위해 많은 시행착오가 있었다.
1. 오디오 녹음
react로 음성 녹음 기능을 구현해보자 글을 많이 참고하여 구현했다.
const onRecAudio = () => {
startAudio.play()
const audioCtx = new (window.AudioContext || window.webkitAudioContext)();
dispatch({
type: SET_JIMI,
data: [...jimi, {text: '', sender: 'user'}]
})
const analyser = audioCtx.createScriptProcessor(0, 1, 1);
setAnalyser(analyser);
function makeSound(stream) {
const source = audioCtx.createMediaStreamSource(stream);
setSource(source);
source.connect(analyser);
analyser.connect(audioCtx.destination);
}
navigator.mediaDevices.getUserMedia({ audio: true }).then((stream) => {
const mediaRecorder = new MediaRecorder(stream);
SpeechRecognition.startListening()
mediaRecorder.start();
setStream(stream);
setMedia(mediaRecorder);
makeSound(stream);
setAudioCtx(audioCtx)
analyser.onaudioprocess = function (e) {
if (e.playbackTime > 15) {
stream.getAudioTracks().forEach(function (track) {
track.stop();
});
mediaRecorder.stop();
analyser.disconnect();
audioCtx.createMediaStreamSource(stream).disconnect();
mediaRecorder.ondataavailable = function (e) {
setAudioUrl(e.data);
setOnRec(true);
};
setAudioState(3)
endAudio.play()
}
}
setAudioState(2)
} );
};
const offRecAudio = async() => {
// dataavailable 이벤트로 Blob 데이터에 대한 응답을 받을 수 있음
media.ondataavailable = function (e) {
setAudioUrl(e.data);
setOnRec(true);
};
// 모든 트랙에서 stop()을 호출해 오디오 스트림을 정지
stream.getAudioTracks().forEach(function (track) {
track.stop();
});
SpeechRecognition.stopListening()
// 미디어 캡처 중지
media.stop();
// 메서드가 호출 된 노드 연결 해제
analyser.disconnect();
source.disconnect();
setAudioState(1)
setIsUserOff(true)
// setIsAudioEnd(true)
};추가한 점은 offRecAudio의 일정부분을 다른 경우에서도 써야 했기에 사용되는 변수들을 상태관리를 해주었다. 그리고 onRecAudio시에 SpeechRecognition.startListening() 로 stt도 함께 진행했다. (3번 참고)
2. api 오디오 파일 전송
항상 json만 전달했지 오디오 파일을 전송하는 것은 처음이라 많이 헤맸다. FormData를 사용해주면 된다.
const sound = new File([audioUrl], username +".wav", { lastModified: new Date().getTime(), type: "audio" });
const formData = new FormData();
formData.append("file", sound)
const response = await fetch(`${apiEndPoint}/api/voice/chat`,{
method: "POST",
body: formData
})주의사항은 파일명을 통해 확장자를 꼭 지정해주어야 한다. 그래야 서버에서 받을 수 있다. 그렇지 않으면 서버에서 자신이 받을 수 없는 확장자라고 거부한다.
3. stt
react-speech-recognition 라이브러리를 활용하였다.
const {
transcript,
listening
} = useSpeechRecognition();transcript 파라미터는 stt된 텍스트이다. listening 파라미터는 사용자의 말이 끝났는지 자동으로 감지하여 true false를 뱉는다. listening을 이용하여 나는 사용자의 말이 끝나면 자동으로 사용자의 질문을 담아 api를 호출하고 답변을 제공할 수 있도록 하였다. 하지만 여기서 문제가 있었는데 transcript가 초기화가 된 후에 listening이 false가 되는 것이다. 그래서 false가 된 후에 transcript를 담아서 화면에 표시해줄 수가 없었다. 왜냐면 언제 transcript가 완성되었는지 감지할 수가 없기 때문이다. 따라서 나는 userText라는 상태를 만들어 관리하여 해결하였다.
useEffect(()=> {
setUserText(transcript)
if (transcript && listening){ //transcript 없어진후 -> listening: false
const lastItem = jimi[jimi.length - 1]
var result
if (lastItem.sender === 'user') {
const updatedJimi = jimi.slice(0, -1)
result = [...updatedJimi, {text: transcript, sender: 'user'}]
} else {
result = jimi
}
dispatch({
type: SET_JIMI,
data: result
})
}
}, [transcript])userText에 계속 업데이트된 transcript을 담아준다. 그리고 transcript가 있고 listening 중일 때는 그때그때 transcript를 받아서 화면에 나타내준다. (jimi가 화면에 나타내지는 채팅 리스트이다.)
useEffect(()=>{
if (userText && !listening) {
stream.getAudioTracks().forEach(function (track) {
track.stop();
});
media.stop();
analyser.disconnect();
audioCtx.createMediaStreamSource(stream).disconnect();
media.ondataavailable = function (e) {
setAudioUrl(e.data);
setOnRec(true);
};
setAudioState(3)
endAudio.play()
dispatch({
type: SET_JIMI,
data: [...jimi.slice(0, -1), {text: userText, sender: 'user'}]
})
setUserText('')
}
}, [listening])listening이 끝나면 오디오 녹음을 중지하고 userText의 값을 최종적으로 담아서 페이지에 나타내준다.
해당 라이브러리는 모바일에서는 작동하지 않는 문제가 있다.
4. tts
tts를 구현하고자 window.speechSynthesis를 활용하였다. 블로그를 참고하여 구현하였다.
const getSpeech = (text) => {
let voices = [];
//디바이스에 내장된 voice를 가져온다.
const setVoiceList = () => {
voices = window.speechSynthesis.getVoices();
};
setVoiceList();
//console.log(voices)
if (window.speechSynthesis.onvoiceschanged !== undefined) {
//voice list에 변경됐을때, voice를 다시 가져온다.
window.speechSynthesis.onvoiceschanged = setVoiceList;
}
const speech = (txt) => {
const lang = "ko-KR";
const utterThis = new SpeechSynthesisUtterance(txt);
utterThis.lang = lang;
utterThis.rate = 0.9;
const kor_voice = voices.find(
(elem) => elem.lang === lang || elem.lang === lang.replace("-", "_")
);
if (kor_voice) {
utterThis.voice = kor_voice;
} else {
return;
}
if (text){
utterThis.onstart = () => {
setIsSpeechOnEnd(false)
setIsUserOff(false)
}
utterThis.onend = () => {
setIsSpeechOnEnd(true)
}
}
window.speechSynthesis.speak(utterThis);
};
speech(text);
};useEffect(()=> {
if (jimi.length> 0 && jimi.slice(-1)[0].sender === 'bot' && isSpeechOnEnd && !isUserOff){
setIsSpeechOnEnd(false)
onRecAudio()
}
}, [jimi, isSpeechOnEnd])추가한 부분은 utterThis.onstart와 onend를 활용하여 speech가 언제 끝나는지 감지하여 speech가 끝나면 바로 녹음 및 stt가 시작되어 사용자의 음성을 받도록 하였다.
speechSynthesis는 사용자의 이벤트가 있어야만 실행할 수 있다. 즉, useEffect내에는 못쓴다. 하지만 나는 음성 기능 페이지에 들어가자마자 음성이 나와야 했다. 따라서 나는 어쩔 수 없이 랜딩페이지도 하나의 큰 페이지안에 구현하여 사용자가 랜딩 페이지내의 음성 기능 버튼을 누르면 아래로 내려가서(mvp 처럼)음성이 나오도록 구현하였다.
Retrospect
감사하게도 본선까지 진출할 수 있었지만 수상을 하지는 못했다. 하지만 이번 해커톤으로 정말 많은 것을 얻고 배울 수 있었다. 단기간 내에 정말 많은 것을 구현하였고 처음 도전해보는 음성 기능은 순간순간이 챌린지였다. 하지만 못하는 것은 없다! 라는 것을 이번 해커톤을 통해 배운 것 같다.
그리고 본선에서 내가 발표를 했는데 이렇게 큰 규모의 대회에서 발표하는 것은 처음이라 너무 떨렸지만 그만큼 또 성장했다. 그리고 다른 참가자의 발표를 보면서 많이 배웠다. 기술도 중요하지만 프레젠테이션을 하는 능력도 그만큼 중요하다는 것을 깨달았다.
아쉬웠던 점은 우리 팀에 디자이너가 없었다는 점이다. 나는 디자인 분야에 큰 재능은 없어서 서비스의 디자인이 만족스럽지 않았다. 그리고 본선 해커톤에서도 개발하느라 바빠서 ppt 준비를 할 시간이 없었다.
다음 번에 다른 해커톤에 참가하게 된다면 발표 준비를 더 열심히 준비할 것이고, 디자이너와 함께 할 것이다.
하지만, 스타트업과 회사원 팀들 사이에서 학생 둘이서 정말 최선을 다해서 준비한 것 같고 후회는 없다! 수고했다, 나 자신!
