

최적화 : w와 b 값 예측
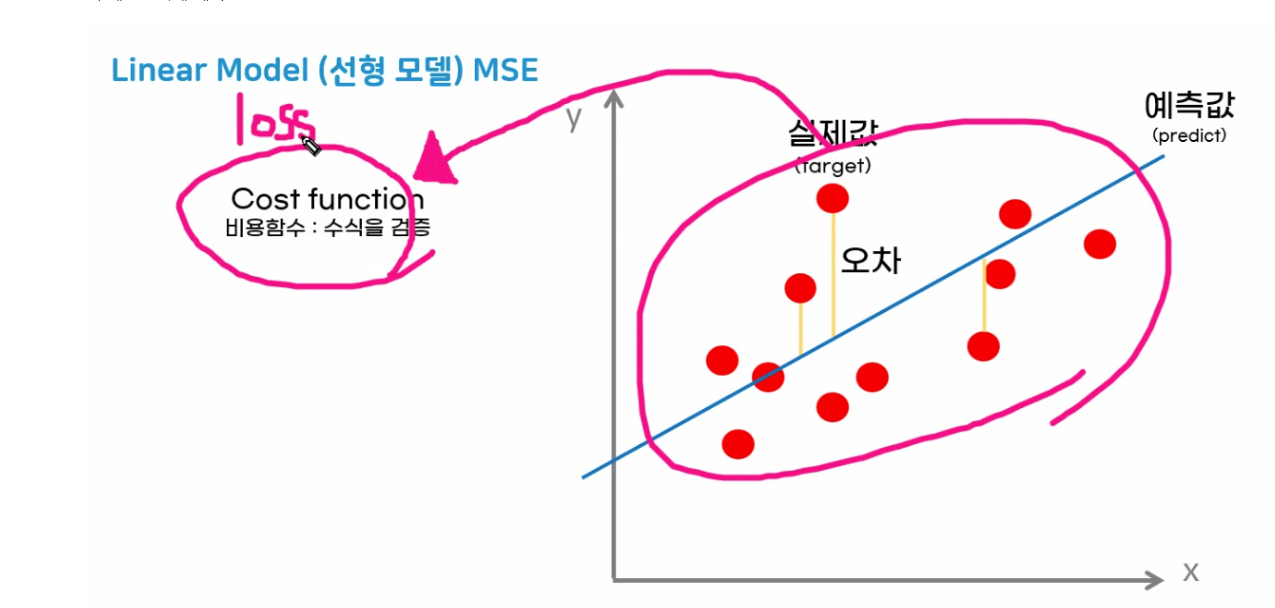
선형모델 : mse를 그어나가면서 적어지는 방향으로 수정

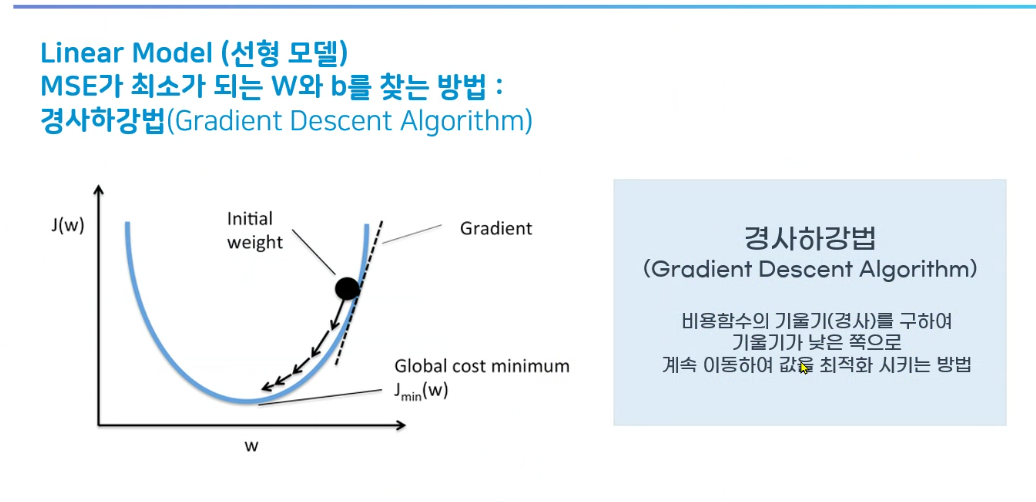
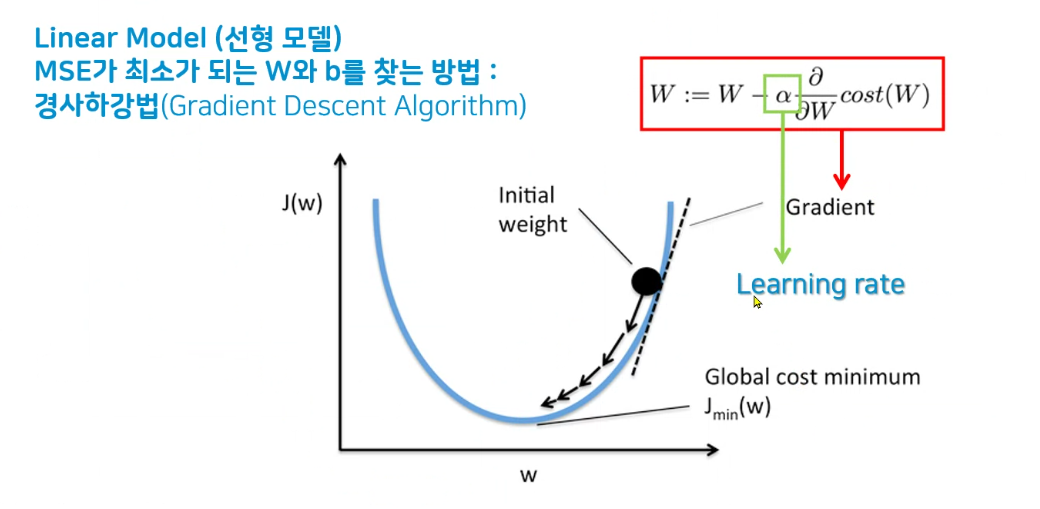
Learning rate - 학습률 - a - 보폭
순간기울기 - 미분
보폭을 낮게 하기위해서는 왼쪽으로 가야겠구나
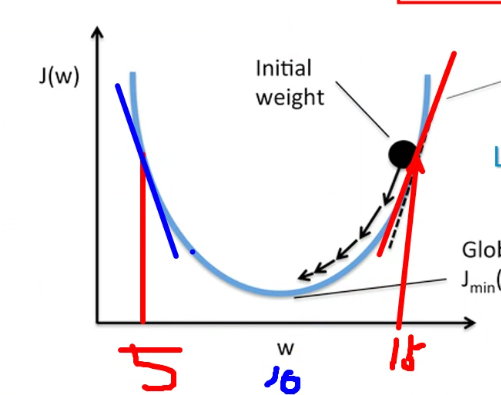
15에서 5 줬는데 다시 +해야겠습니다.
가장초기w는 랜덤입니다.
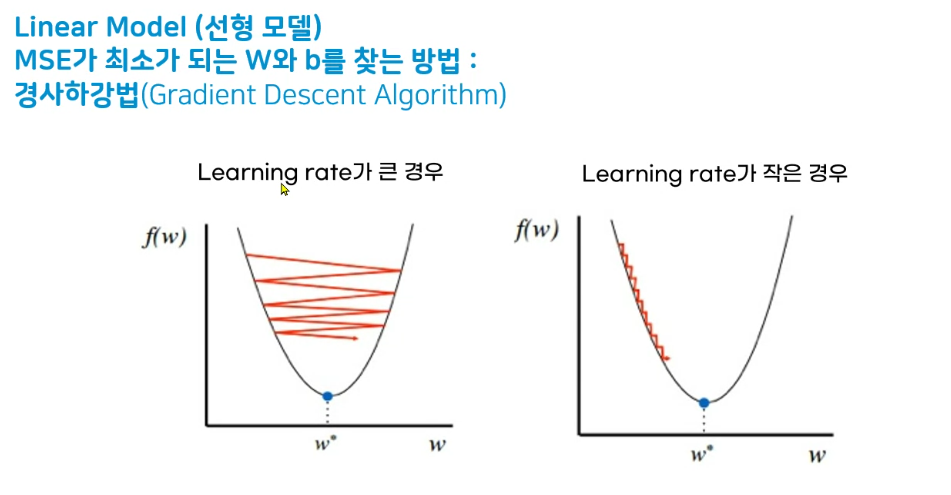
Learning rate를
너무 크게 주면 비효율
너무 와리가리를 합니다.
너무 작으면 짜잘하게 가서오래걸림니다.
(숫자맞추기 업다운스무고개)
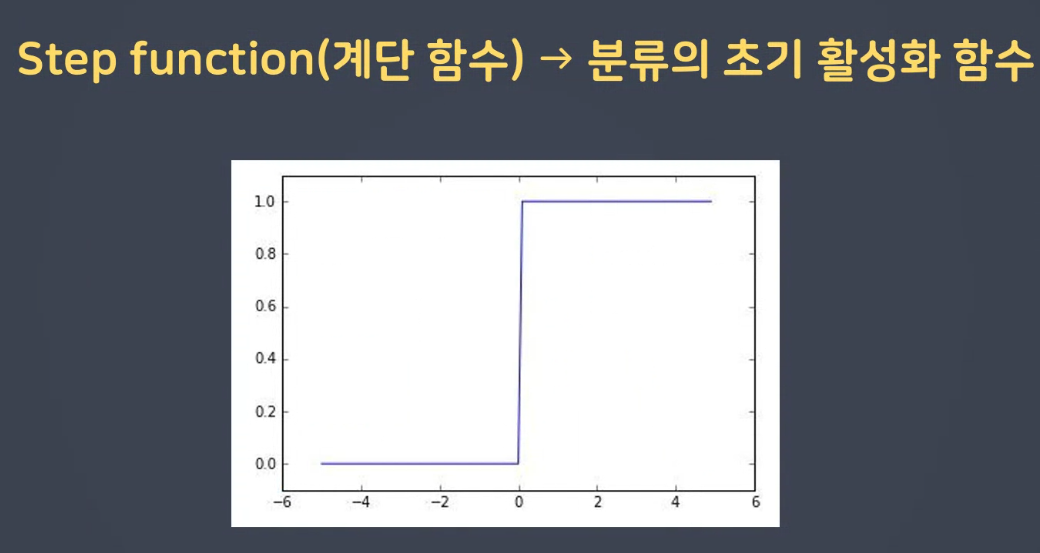
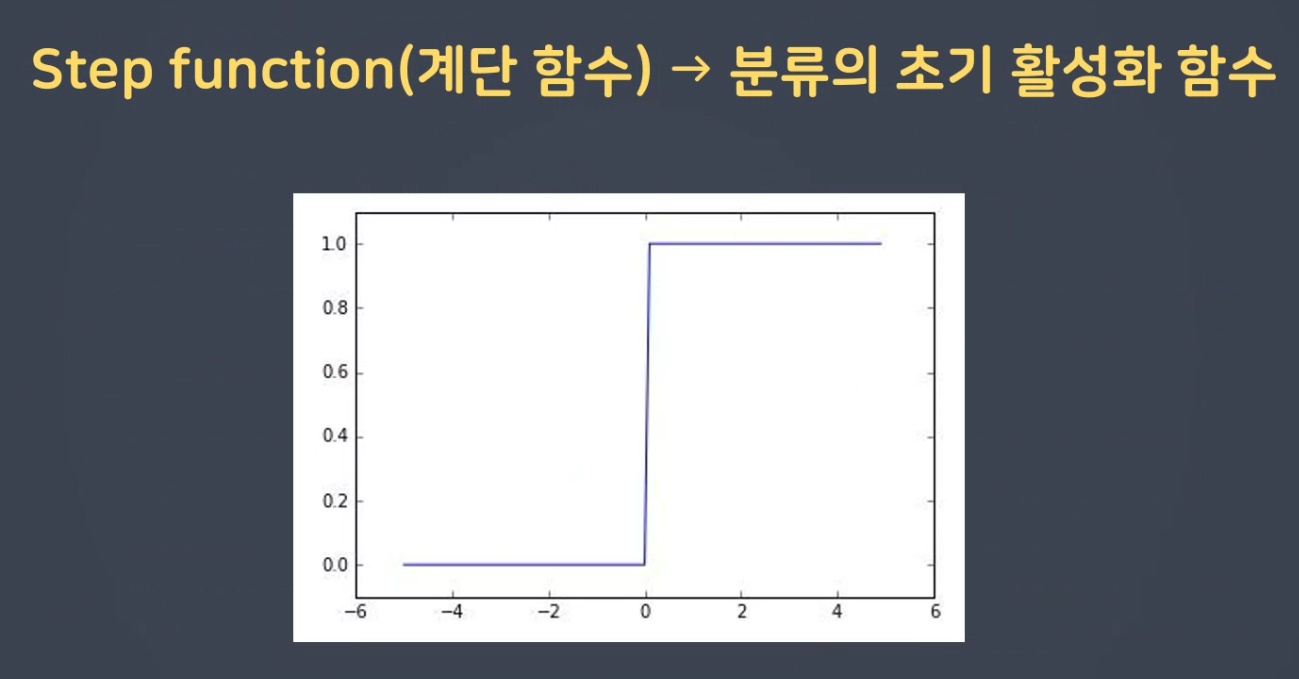
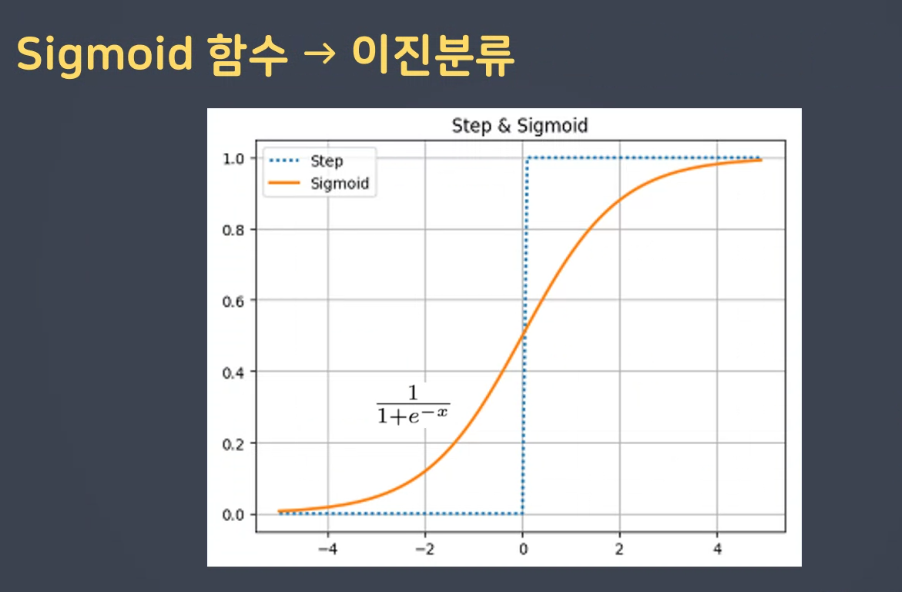
- 역치값
스텝 함수
최적 w 를 지나치면 미분 -순간기울기 가 안구해져서
- 역전파 > 옵티마이저 > 경사하강법
역치를 가져오기위해서
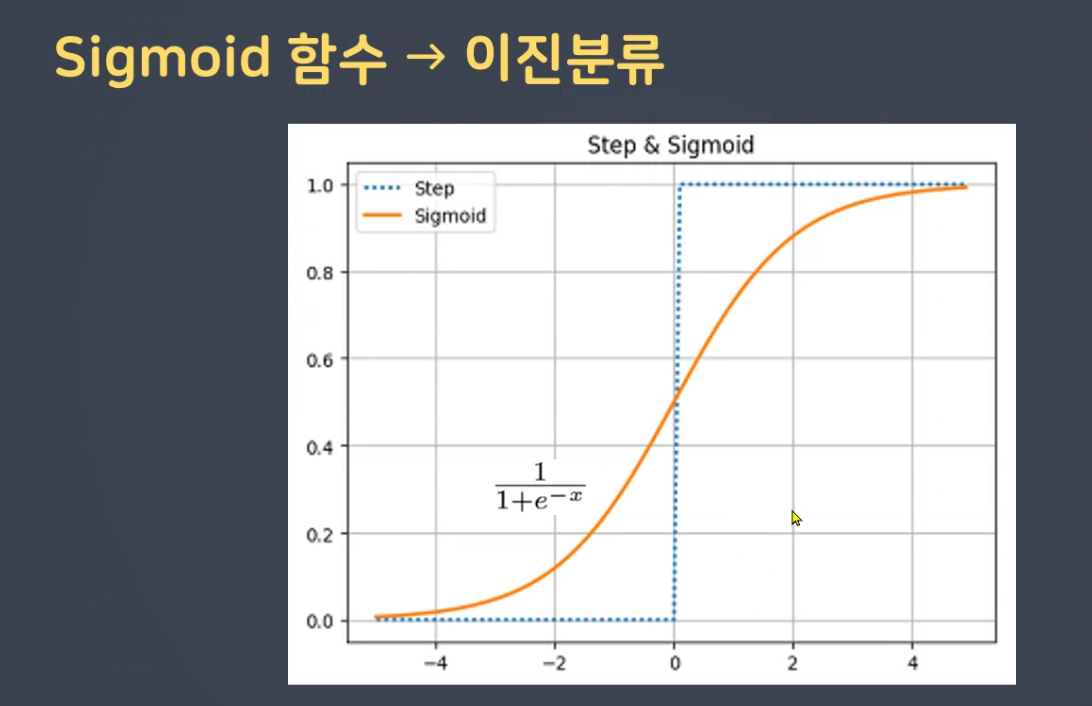
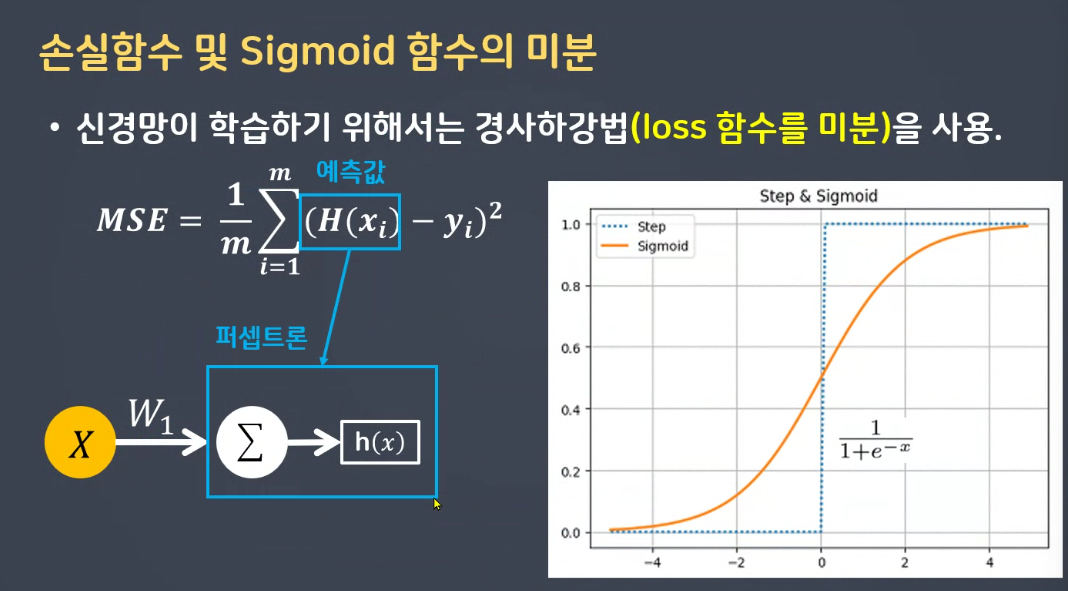
시그모이드 함수

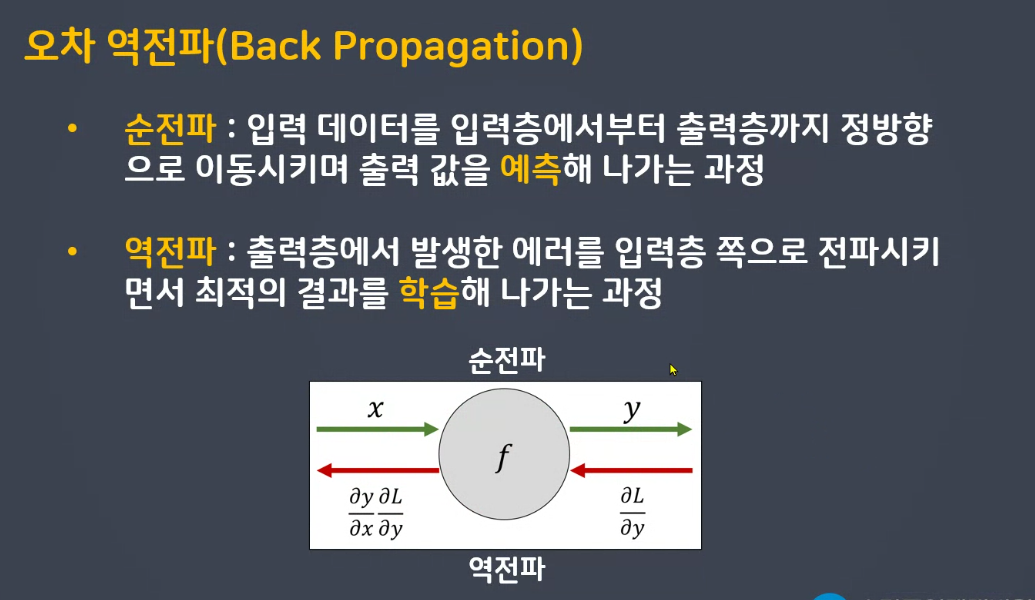
순전파 w 가중치 편향(bias) 예측
오차역전파는 경사하강법 a 순간기울기 개념이 들어갑니다. 학습
1epochs가 끝납니다.
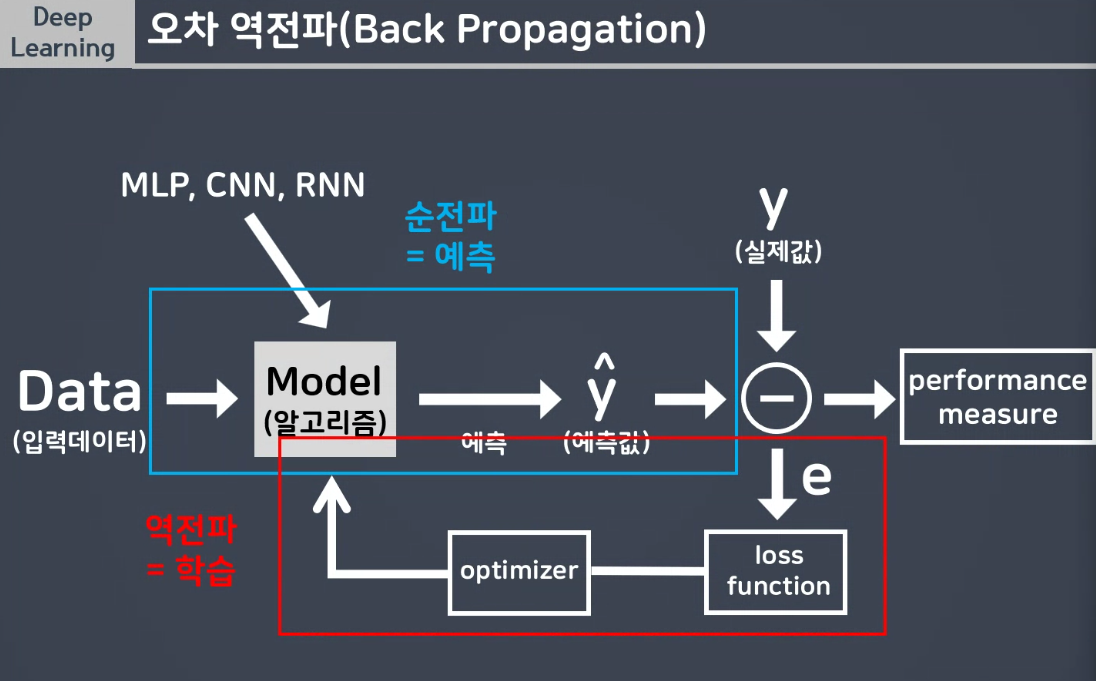
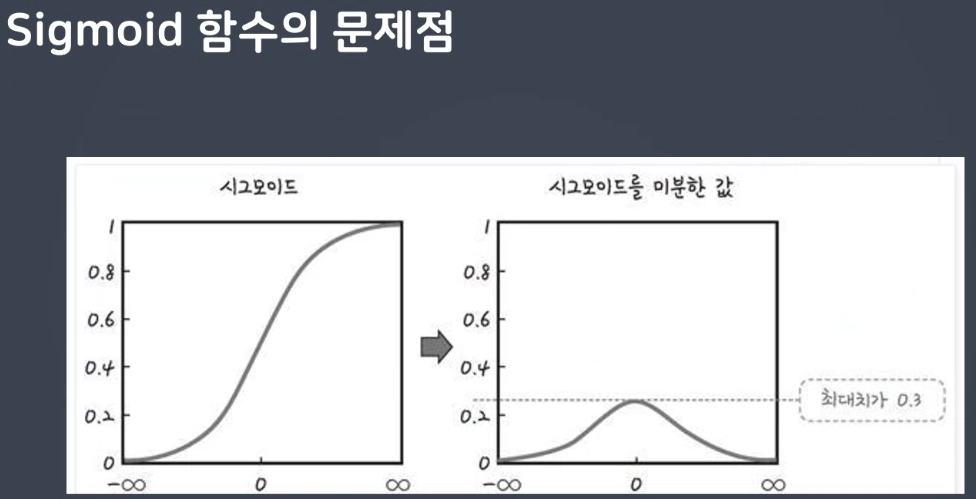
미분 최대값이 0.25입니다.
- 0.25씩 감소하게 됩니다.
너무 작게되면기울기 소실
많아지면 제대로 학습 불가

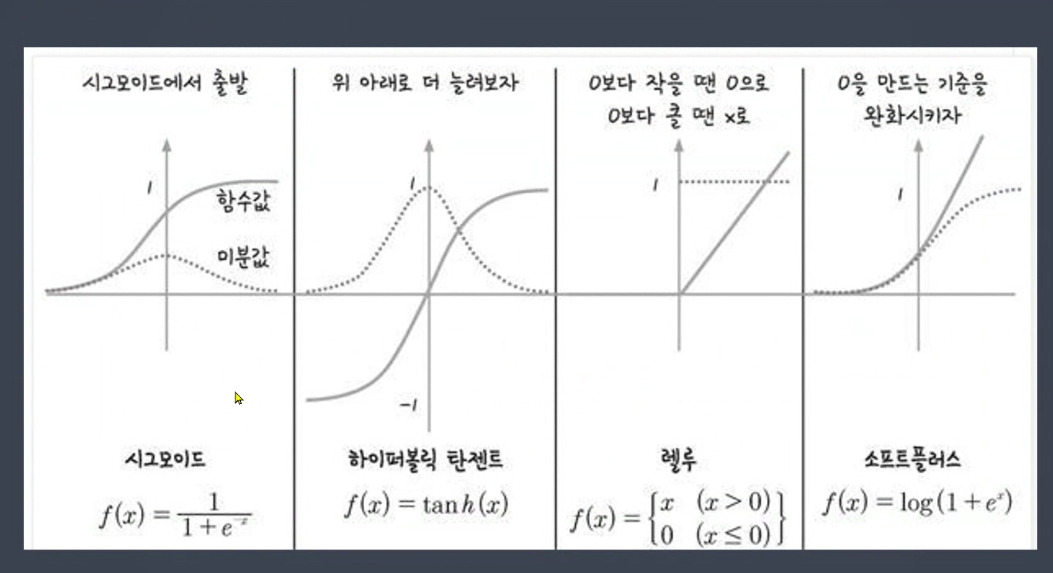
점선 : 기울기
tanh도 최대값에서 기울기 소실
lelu 사용
순간기울기가 예측한 w 값을 향해 가는 경사하강법입니다.
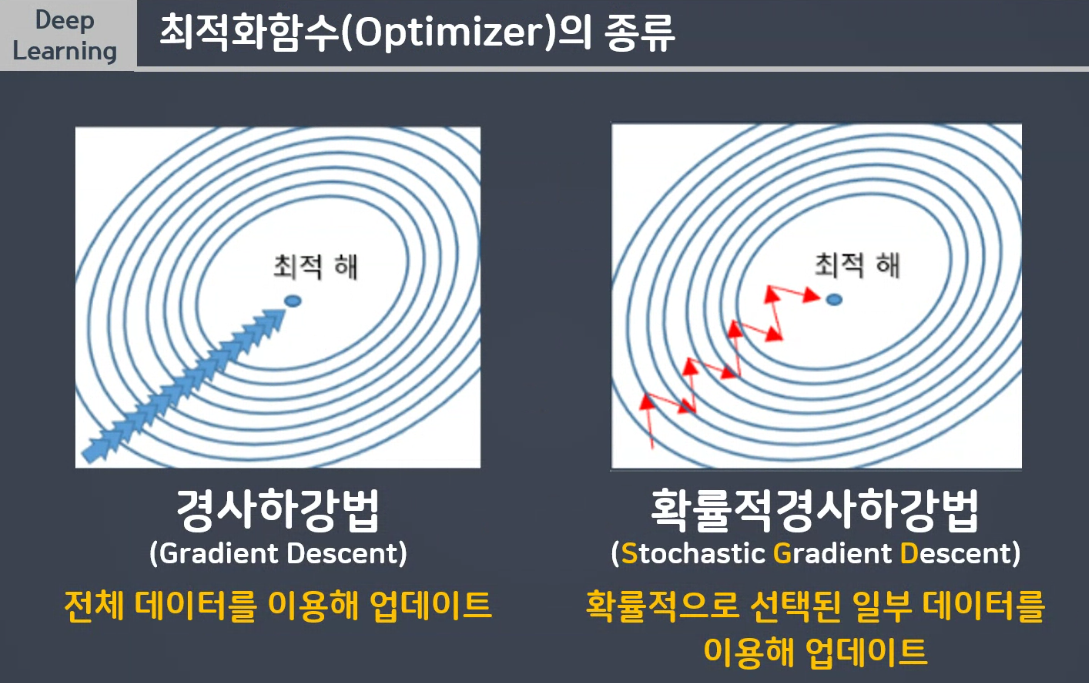
시간, 비용이 큽니다. >> 확률적 경사하강법(배치사이즈 : 일부데이터)
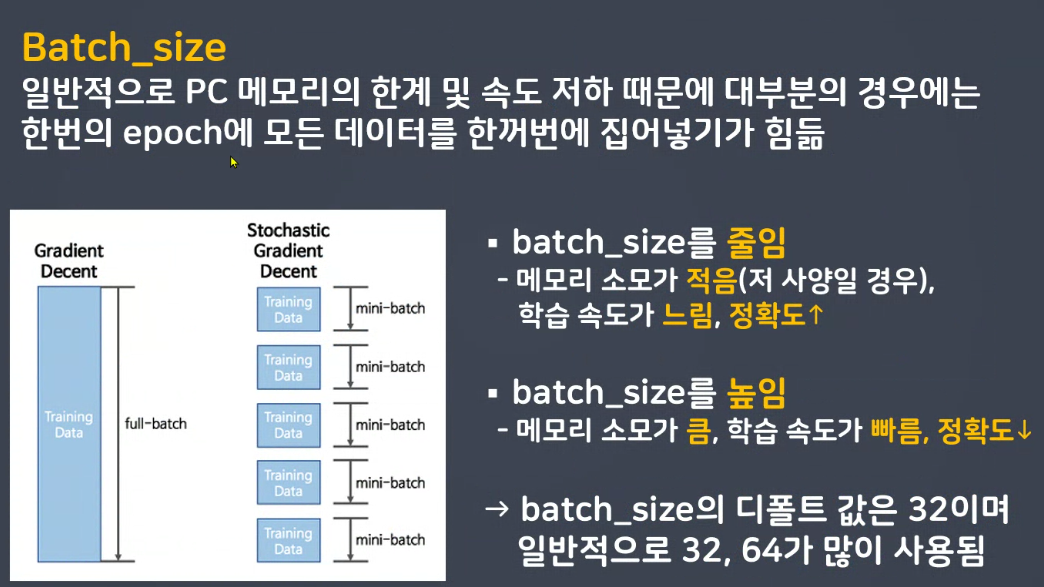

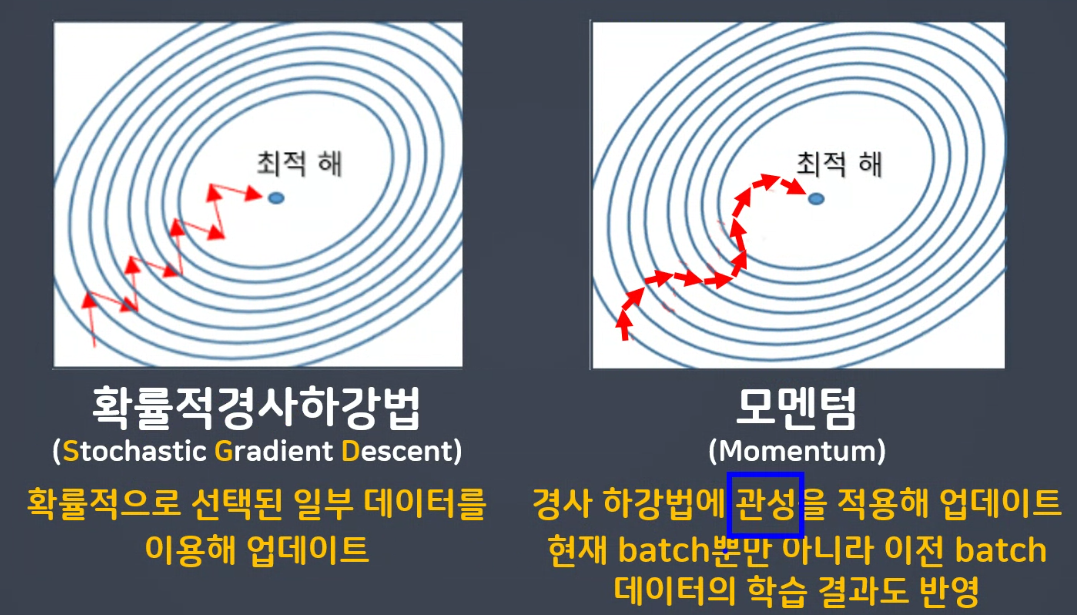
현재 배치 뿐 아니라 이전 배치도 학습결과에 반영합니다.

일부

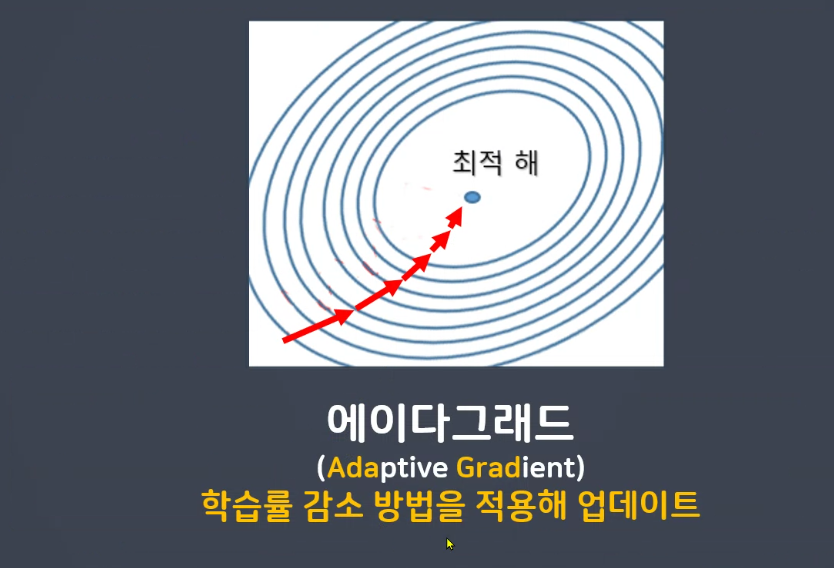

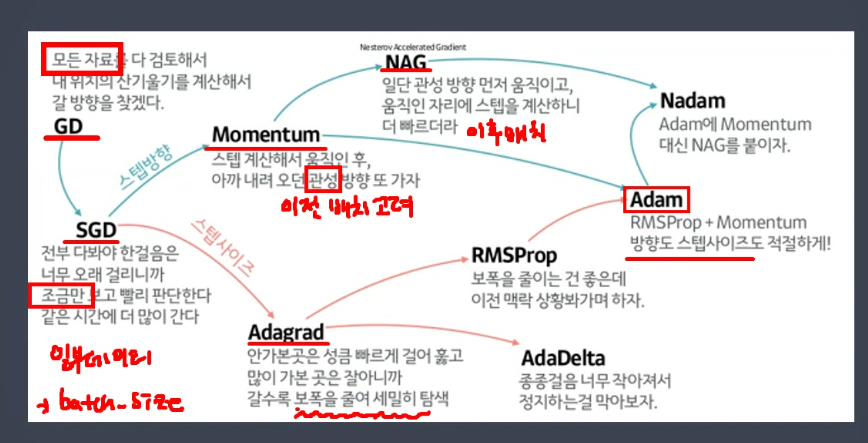
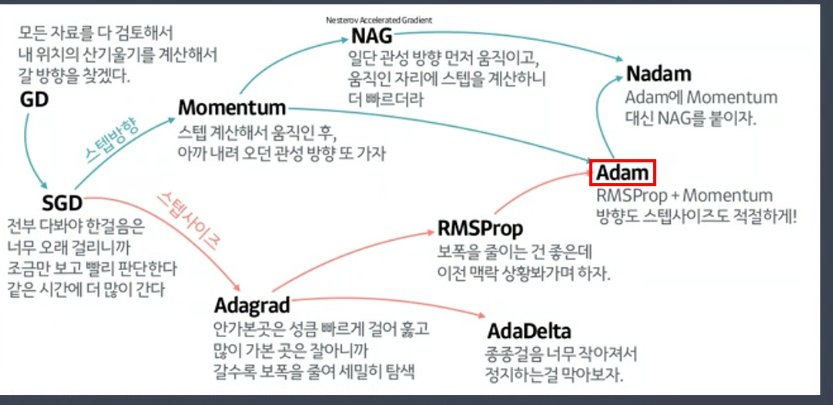
근처에 왔을때 미세조정이 필요합니다. >> 에이다 그래드
일부데이터 가져옵니다. >> SGD
이전 방향 참고 >> 모멘텀
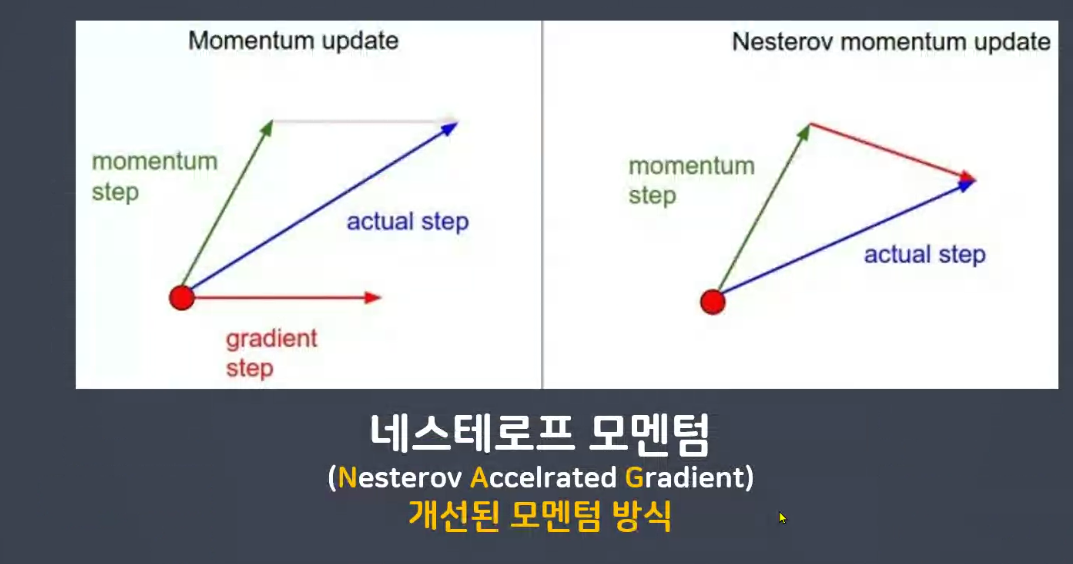
미리 방향 이동 가정 >> nag ( 개선된 모멘텀 )
최적해에 멀때는 보폭이 크고 가까울때는 보폭이 감소 >> 에이다그래드
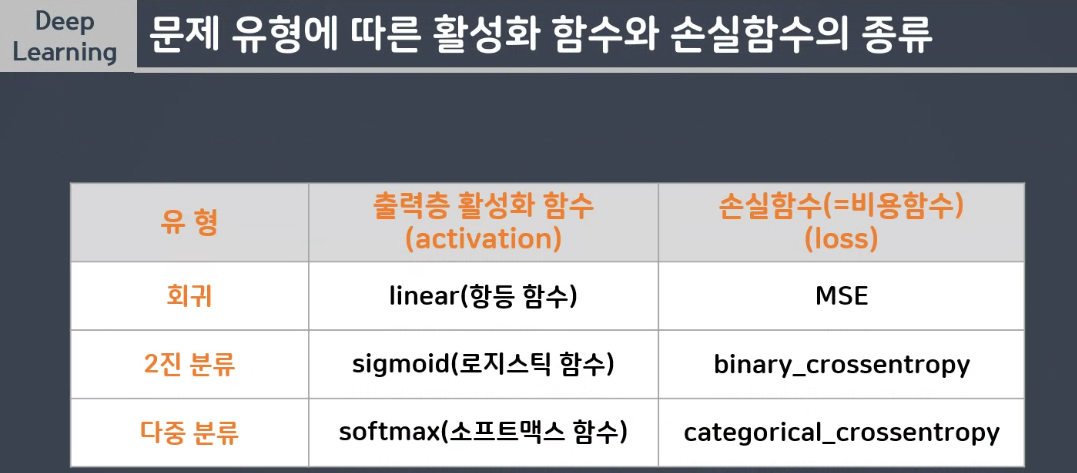
활성화함수, 최적화

성장하는 하루가 되자