List, Set, Map? 명확하게 이해하기 위한 정리
개요
사실 그동안 명확하게 자료구조를 공부하고, 이해하려는 노력은 거의 하지 않았던 것 같습니다.
실제로 당장 하던 프로젝트 등에서도 List 자료 구조 외에는 거의 써본 적이 없고, 필요할 때만 대충 JAVA 언어에서 사용하는 방식만 확인하고 사용하기 급급했었습니다.
이번 정리를 통해 List, Set, Map 자료구조에 대한 이해를 명확히 하고, 상황에 맞게 사용할 수 있도록 하려 합니다.
List?
1. 핵심
순서가 있는 원소 집합을 저장하는 자료구조
특징은 아래와 같다.
- 중복 허용: 동일한 값이 여러 번 들어갈 수 있다.
- 인덱스 기반 접근: 0부터 시작하는 인덱스로, 원소를 조회 / 수정 / 삽입이 가능하다.
2. JAVA에서의 List
JAVA 컬렉션에서는 List는 인터페이스이며, 아래와 같은 구현체들로 구성된다.
-
ArrayList -
LinkedList -
Vector- 레거시, 요즘은 잘 사용하지 않음
ArrayList 특징
-> 배열 기반, 빠른 조회, 삽입 / 삭제는 느리다.(중간 원소 이동)
LinkedList 특징
-> 이중 연결 리스트 기반 (이전 노드, 이후 노드 둘 다 접근 가능),
ArrayList와 반대로 삽입 / 삭제가 빠르다.(노드 포인터만 변경),
조회는 느리다.(첫 노드부터 탐색)
두 구현체 시간 복잡도 차이
| 연산 | ArrayList | LinkedList |
|---|---|---|
get(index) | O(1) | O(n) |
add(element) (끝) | 평균 O(1) | O(1) |
add(index, elem) | O(n) | O(1) |
remove(index) | O(n) | O(1) |
contains(element) | O(n) | O(n) |
간단하게 결론 내자면,
빠른 조회에는 -> ArrayList
많은 삽입 / 삭제 -> LinkedList
다만, LinkedList는 순수하게 삽입, 삭제만 생각했을 때는 복잡도가 O(1)이 맞지만,
삽입, 삭제 과정을 진행하기 위한 위치를 알기 위해선 앞에서부터 차례대로 탐색해야 하는 과정이 필요하다.
다행히도, Java의 LinkedList는 최적화가 어느 정도 되어있어
-
찾는 인덱스가 앞쪽 -> head 부터 탐색,
-
찾는 인덱스가 뒷쪽 -> tail 부터 역순으로 탐색한다.
그래도 결국 최대는 O(n) 만큼의 시간이 소요된다.
public void add(int index, E element) {
// 1. 인덱스가 범위 내에 있는지 판단한다.
checkPositionIndex(index);
// 2. 인덱스가 길이와 같다면 바로 제일 뒷 원소에 삽입.
// 그렇지 않다면 인덱스에 위치한 노드의 바로 앞에 삽입.
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
// 인덱스가 범위 내에 존재하는 지 확인하고, 없으면 예외를 던진다.
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
// 인덱스가 범위 내의 값인지 판별한다.
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
-> linkedlist의 add 함수이다. 위에서 본대로 약간의 인덱스 보정(?)이 되어있다.
추가로, 양 끝쪽 원소의 삽입, 삭제 로직이라면
addFirst(), addLast(), removeFirst(), removeLast()와 같은 메서드도 있어서, 약간의 성능 최적화를 원한다면 위 선택지도 나쁘지 않을 것 같다!
3. Java에서의 List 사용
java.util 패키지의 List 인터페이스로 import한다.
public class ListEx {
public static void main(String[] args) {
List list = new ArrayList();
}
}제네릭을 이용해서,
List에 들어갈 특정한 타입을 명시해줄 수도 있다.
오히려, 이 방식이 더 권장되는 편이다.
public class ListEx {
public static void main(String[] args) {
Element e = new Element("객체");
// 제네릭으로 리스트에 들어갈 타입 명시
List<Element> list = new ArrayList<>();
}
}정적 메서드를 이용해서 요소들을 명시적으로 삽입하며 생성도 가능하다.
public class ListEx {
public static void main(String[] args) {
// 빈 리스트 생성
List<Element> list = List.of();
// 요소들을 명시적으로 넣어 생성
List<Element> list2 = List.of(
new Element("Hydrogen"),
new Element("Helium"),
new Element("Lithium"),
new Element("Beryllium"),
new Element("Boron"),
new Element("Carbon"),
new Element("Nitrogen"),
new Element("Oxygen"),
new Element("Fluorine"),
new Element("Neon")
);
}
}
참고로,
.of()로 생성된 List는 불변이다. 따라서 생성 이후에 추가로 값을 삽입, 삭제하려 하면UnsupportedOperationException이 발생하게 된다.
// 빈 리스트를 생성할 때의 of 메서드
static <E> List<E> of() {
return (List<E>) ImmutableCollections.EMPTY_LIST;
}
// 요소가 있을 때의 of 메서드
static <E> List<E> of(E e1) {
return new ImmutableCollections.List12<>(e1);
}
// ImmutableCollections 클래스의 필드 중 일부
private static Object[] archivedObjects;
private static final Object EMPTY;
static final ListN<?> EMPTY_LIST;
static final ListN<?> EMPTY_LIST_NULLS;
static final SetN<?> EMPTY_SET;
static final MapN<?,?> EMPTY_MAP;
// ImmutableCollections 클래스의 내부 클래스인 List12 클래스
static final class List12<E> extends AbstractImmutableList<E>
implements Serializable {
이런 식으로 삽입 테스트를 해보았다.
public class ListEx {
public static void main(String[] args) {
// 1. 빈 리스트 생성
List<Element> list = List.of();
// 2. 원소 생성 후 리스트에 추가
Element neon = new Element("Neon");
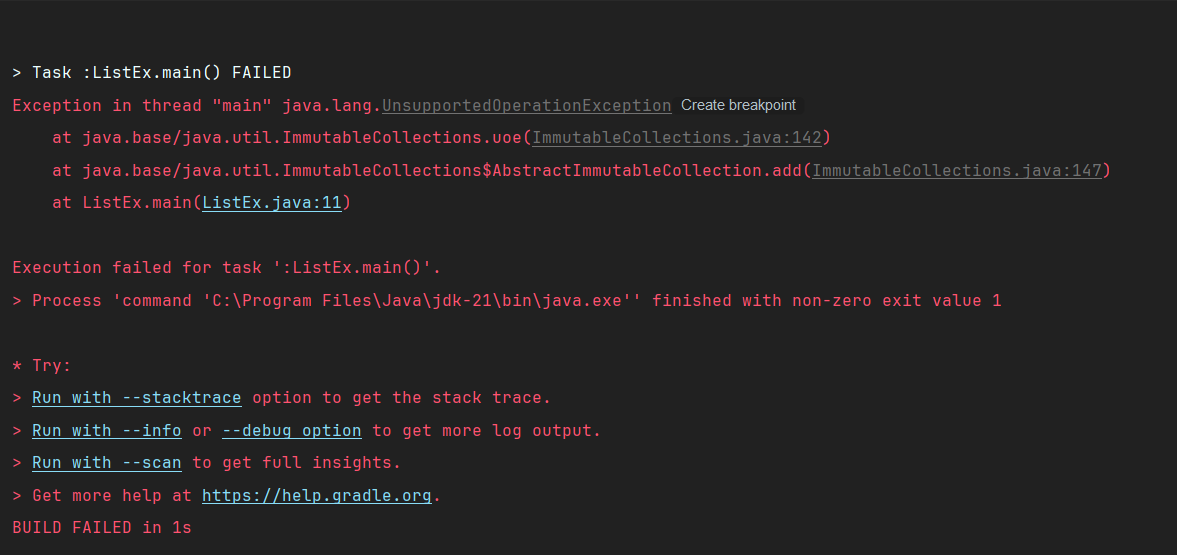
list.add(neon); // UnsupportedOperationException 발생
}
}
->
UnsupportedOperationException이 발생하는 것을 확인할 수 있다.
다만, List의 내부 요소의 변경을 불가능케 하는 것은 아니다.
요소 자체의 필드가 변경이 가능하다면, 그건 가능하다.
Set?
1. 핵심
중복을 허용하지 않는 원소 집합이다.
- 순서 없음: 저장 순서를 보장하지 않음.
- null 허용 여부: 구현체마다 다르지만,
HashSet의 경우 1개 허용,TreeSet의 경우는 null 불가능
2. Java에서의 Set
JAVA에서의 구현체는 아래와 같다.
-
HashSet
-
LinkedHashSet -
TreeSet
HashSet: HashMap을 이용하여 구현.
해시값을 이용하여 원소를 저장 검색, 삽입, 삭제 속도는 평균 O(1) 이다.
순서 유지되지 않음, null값 1개 허용
LinkedHashSet: HashSet + 이중 연결 리스트의 구조로 생각하면 편하다.
입력된 순서를 유지, 다만 HashSet보다 조금 느리다는 단점이 존재.
(순서 유지 + 중복 제거)
TreeSet: 내부적으로 TreeMap(R-B Tree) 기반, 원소가 자동으로 정렬 상태 유지
검색, 삽입, 삭제 속도는 O(log n)
null 허용 x -> 정렬이 불가능하기 때문.
| 연산 | HashSet | LinkedHashSet | TreeSet |
|---|---|---|---|
add, remove, contains | 평균 O(1) | 평균 O(1) | O(log n) |
| 순서 유지 | X | 입력 순서 유지 | 정렬 순서 유지 |
| null 허용 | 1개 가능 | 1개 가능 | 불가능 |
여기서 궁금한 점은 왜 TreeSet은 다른 구현체에 비해 더 빠른 걸까?
TreeSet
기본적으로 R-B 트리로 구현되어 있다.
R-B 트리:
- 균형 이진 탐색 트리
- 특정한 규칙을 통해 항상 균형에 가까운 depth 를 유지(log n)
- 삽입 / 삭제 시 회전과 색 변환으로 높이를 조정.
-> R-B 트리에 관한 내용은 추후에 정리해볼 예정입니다.
일단 R-B트리의 강력한 규칙에 의해 안정적인 성능이 나온다는 점만 기억해두자.
3. Java에서의 Set 사용
마찬가지로, java.util 패키지를 import 하여 사용한다.
Set도 제네릭을 이용하여 들어갈 타입의 명시가 가능하다.
public class SetEx {
public static void main(String[] args) {
Set<Element> set = Set.of();
}
}
Set도 마찬가지로
of()정적 메서드 기반 생성이 가능하고 불변 객체 이며,
조회같은 경우는, List와 다르게 인덱스가 존재하지 않아 전체 요소를 순회하며 조회해야 한다.
public class SetEx {
public static void main(String[] args) {
// HashSet 생성
Set<Element> fruits = new HashSet<>();
fruits.add(new Element("Apple"));
fruits.add(new Element("Orange"));
fruits.add(new Element("halabong"));
// 1) 반복문으로 조회
for (Element fruit : fruits) {
if (fruit.hasName("halabong")) {
System.out.println("Found element: " + fruit); // halabong
}
}
// 2) 스트림을 사용한 조회
fruits.stream()
.filter(f -> f.hasName("halabong"))
.forEach(f -> System.out.println("Found (Name is 'Halabong'): " + f));
}
}Set에는 두 컬렉션(Set)에 포함된 원소들만 유지하는 메서드도 지원한다.
(교집합, retainAll(Collection<?> c))
public class SetEx {
public static void main(String[] args) {
Element apple = new Element("Apple");
Element orange = new Element("Orange");
Element halabong = new Element("halabong");
Element pineapple = new Element("pineapple");
Set<Element> fruits = new HashSet<>();
Set<Element> fruits2 = new HashSet<>();
fruits.add(apple);
fruits.add(orange);
fruits.add(halabong);
fruits2.add(apple);
fruits2.add(orange);
fruits2.add(pineapple);
fruits.retainAll(fruits2);
for (Element fruit : fruits) {
System.out.println(fruit.getName());
}
}
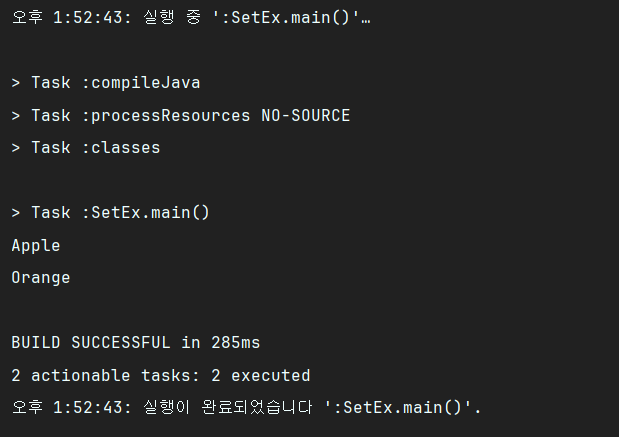
}결과는 아래와 같다. 교집합이고 이름이 Apple과 Orange인 원소만 남은 것을 확인했다.
Set의 중복판단 원리?
Set에서는 원소를 저장할 때 값이 이미 들어있나? 를 판단해야 한다.
이를 위해서 Java에서는 두 가지 메서드를 사용한다.
hashCode(): 객체의 해시 값을 반환한다.(정수)equals(Object): 두 객체가 실제로 같은지 비교한다.
여기서, hashCode()와 equals()의 규칙이 존재한다.
equals()가true면,hashCode()도 반드시 같아야 한다.
- 두 객체가 같다면, 같은 해시 버킷 안에 있어야 하기 때문이다.
hashCode()가 같다고,equals()가 반드시 true일 필요는 없다.
- 다른 객체지만 해시 충돌로 같은 값이 나올 수도 있다.
- 실행 중에 객체 상태가 변하지 않는 한, hashCode는 항상 동일해야 한다.
궁금하니, 직접
equals()와hashCode()메서드를 재정의하여 테스트해보자.
기존에 있던Element클래스의 중복 기준을 이름이 같다면 같은 요소로 판단하도록 재정의해보았다.
// 요소의 이름 해시코드 반환
@Override
public int hashCode() {
return name.hashCode();
}
// 이름 기반 비교 로직으로 변경
@Override
public boolean equals(Object obj) {
if (this==obj)
return true;
if (obj==null || getClass()!=obj.getClass())
return false;
Element e = (Element) obj;
return Objects.equals(this.name, e.name);
}
이제 다시
retainAll메서드를 테스트해보았다. 기존에는 객체를 생성할 때마다 변수로 할당 후, 삽입하여 중복 비교를 했다면 이제는 이름이 같다면 중복 취급되게 될 것이다.
public class SetEx {
public static void main(String[] args) {
Set<Element> fruits = new HashSet<>();
Set<Element> fruits2 = new HashSet<>();
fruits.add(new Element("Apple"));
fruits.add(new Element("Orange"));
fruits.add(new Element("halabong"));
fruits2.add(new Element("Apple"));
fruits2.add(new Element("Orange"));
fruits2.add(new Element("pineapple"));
fruits.retainAll(fruits2);
for (Element fruit : fruits) {
System.out.println(fruit.getName());
}
}
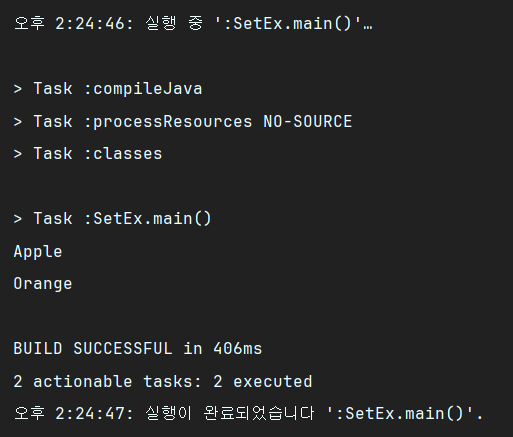
}실행 결과도 정상적으로 겹치는 요소인 Apple과 Orange 라는 name을 가진 요소만 남겼다.
이때 중요한 점은, 꼭 equals()와 hashCode()는 같이 재정의되야 한다는 것이다.
hashCode가 달라서 다른 객체로 저장되면, Set에 중복된 값이 들어가거나, 제대로 찾지 못하는 문제가 발생할 수 있다.
따라서, 사용자 정의 클래스를 비교 대상으로 이용하려면 꼭 hashCode()와 equals()를 같이 재정의 해줘야 한다.
Map?
1. 핵심
key-value 쌍을 저장하는 자료구조이다.
- key는 중복 불가, Value는 중복 허용
- key를 통해서 value를 빠르게 검색, 수정, 삭제할 수 있다.
2. Java에서의 Map
-
HashMap- 해시 테이블 기반
- 평균적으로 검색, 삽입, 삭제 O(1)
equals(),hashCode()로 Key의 중복 여부 판단- 순서 보장 X
nullKey 1개,nullValue 여러 개 허용
-
LinkedHashMap- HashMap + 이중 연결 리스트
- 삽입 순서 혹은 접근 순서 유지 가능
- 캐시 구현할 때 자주 사용(LRU 캐시)
-
TreeMap- 내부적으로
R-B트리 - Key가 정렬된 상태로 저장됨.
- 검색/삽입/삭제 O(log n)
- Key 정렬 기준:
Comparable인터페이스 혹은Comparator nullKey 불가
- 내부적으로
-
ConcurrentHashMap- 멀티스레드 환경에서 안전하게 사용 가능
HashMap을 여러 구간으로 나누어 lock 분할.(동시성 성능 향상)
Map은 기존 List, Set과는 조금 다른 구현 메서드를 사용한다.
V put(K key, V value) → Key-Value 저장
V get(Object key) → Key로 Value 조회
V remove(Object key) → 해당 Key 삭제
boolean containsKey(Object key) → Key 존재 여부
boolean containsValue(Object value) → Value 존재 여부
int size() → 엔트리 수
boolean isEmpty() → 비어있는지 확인
void clear() → 모든 엔트리 삭제
Set<K> keySet() → 모든 Key 반환
Collection<V> values() → 모든 Value 반환
Set<Map.Entry<K,V>> entrySet() → 모든 Key-Value 쌍 반환| 연산 | HashMap | LinkedHashMap | TreeMap |
|---|---|---|---|
get(key) | O(1) | O(1) | O(log n) |
put(key, value) | O(1) | O(1) | O(log n) |
remove(key) | O(1) | O(1) | O(log n) |
| 순서 유지 여부 | ❌ | 삽입/접근 순서 | 정렬 순서 |
3. Java에서 Map 사용
마찬가지로 java.util 패키지에서 import 해서 사용한다.
of() 정적 메서드를 지원하며, 이렇게 생성 시 불변 객체가 된다.
public class MapEx {
public static void main(String[] args) {
// 빈 맵 생성
Map<Integer, Element> map = Map.of();
}
}간단한 예제를 만들어보았다.
public class MapEx {
public static void main(String[] args) {
// 빈 맵 생성
Map<Integer, Element> map = new HashMap<>();
// 원소 생성 후 맵에 추가
Element element = new Element("Hydrogen");
Element helium = new Element("Helium");
Element lithium = new Element("Lithium");
Element beryllium = new Element("Beryllium");
Element boron = new Element("Boron");
map.put(1, element);
map.put(2, helium);
map.put(3, lithium);
map.put(4, beryllium);
map.put(5, boron);
// 조회
System.out.println("map.get(1) = " + map.get(1)); // Hydrogen
//containsKey
System.out.println("map.containsKey(1) = " + map.containsKey(6)); // false
// 엔트리 순회
Set<Map.Entry<Integer, Element>> elements = map.entrySet();
for (Map.Entry<Integer, Element> entry : elements) {
System.out.println("entry.getKey() = " + entry.getKey() + ", entry.getValue() = " + entry.getValue());
}
// key 순회
Set<Integer> keys = map.keySet();
for (Integer key : keys) {
System.out.println("key = " + key);
}
// value 순회
Collection<Element> values = map.values();
Set<Element> valueSet = (Set<Element>) map.values();
for (Element value : valueSet) {
System.out.println("value = " + value);
}
}
}마치며
정말 간단하게 List, Set, Map에 대한 내용을 정리해보았습니다.
이번 정리를 통해 각 자료구조의 특징에 대해 이해하고, 어떤 구현체를 어떤 상황에 쓰면 좋을지 조금이나마 고민할 수 있게 되었습니다.
다음에는 TreeSet의 정렬 기준과 ConcurrentHashMap의 동시성에 대해 정리해보겠습니다.