개요
List, Set, Map 자료구조에 대해 공부하던 중, TreeSet, TreeMap과 같이 내부 정렬을 지원하는 자료구조가 있음을 알게 되었고, 내부 정렬의 작동 원리를 이해하고자 이 글을 작성하게 되었습니다.
TreeSet의 기본 정렬 기준
단순히 TreeSet을 생성했을 때에는 이렇다.
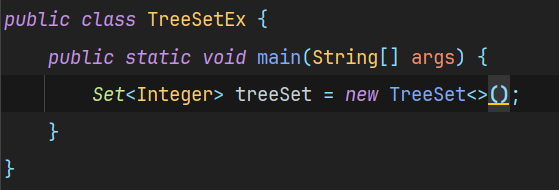
Set<Integer> treeSet = new TreeSet<>();
treeSet.add(1);
treeSet.add(2);
treeSet.add(3);
treeSet.add(4);
treeSet.add(5);
treeSet.add(0);
System.out.println(treeSet);
이런 식의 코드로 테스트해봤을 때의 결과는 오름차순 정렬된 숫자들을 확인할 수 있었다.

그렇다면 String 타입은 어떨까?
Set<String> treeSet2 = new TreeSet<>();
treeSet2.add("123");
treeSet2.add("안녕하세요");
treeSet2.add("ghi");
treeSet2.add("abc");
treeSet2.add("def");
treeSet2.add("jkl");
System.out.println(treeSet2);
이런식으로 테스트 해본 결과는 이랬다.

ASCII 코드 값 기준으로 오름차순 정렬되는 것 같다.
궁금해서 한글으로만 테스트도 해보았다.

마찬가지로 오름차순 정렬이 작동하는 것을 확인했다.
TreeSet이 제공하는 메서드
public static void main(String[] args) {
TreeSet<Integer> treeSet = new TreeSet<>();
treeSet.add(1);
treeSet.add(2);
treeSet.add(3);
treeSet.add(4);
treeSet.add(5);
treeSet.add(0);
// 맨 첫번째 값
System.out.println(treeSet.first());
// 맨 마지막 값
System.out.println(treeSet.last());
// 특정한 값 바로 앞에 있는 값 찾기
System.out.println(treeSet.lower(3));
// 특정한 값 바로 뒤에 있는 값 찾기
System.out.println(treeSet.higher(0));
// 내림차순의 Set으로
NavigableSet<Integer> newSet = treeSet.descendingSet();
/*
* floor: 특정한 값이 존재하면, 그 값 반환
* 없으면 바로 뒷 값 반환
* ceiling: 그 반대. 바로 뒷 값 반환
* */
System.out.println(treeSet.floor(6));
System.out.println(treeSet.ceiling(-1));
// 가장 첫번째 순서의 값을 추출하고 없앰.
System.out.println(treeSet.pollFirst());
// 가장 마지막 순서의 값을 추출하고 없앰.
System.out.println(treeSet.pollLast());
}참고로
NavigableSet은 TreeSet처럼First(),Last(),floor(),ceiling(),lower(),higher()메서드를 제공한다.
TreeSet 내의 객체 비교
여기까지는 단순히 자바에서 제공하는 기본 타입이기에 비교가 가능하지만, 객체를 담는 TreeSet의 경우는 조금 다르다.
이전 정리의 Set의 비교의 경우에는(Hash 기반 구현체들)
equals()와 hashCode() 메서드를 오버라이딩하여 비교 기준을 잡아주었다.
TreeSet의 경우는, Comparable<T> 인터페이스를 상속받고,
compareTo() 메서드를 오버라이딩하여 비교 기준을 정한다.
그냥 생성하면 이렇게 노란 경고 줄이 보인다.

Fruit 객체를 비교 가능하게 하기 위해, equals() 와 hashCode() 메서드를 상속받아 구현해보겠다.
우선은 TreeSet만 사용할 것이기에 compareTo() 메서드만 구현했지만, 나중에 다른 구현체로 바뀔 것을 고려한다면, equals()와 hashCode() 메서드까지 오버라이딩하는게 좋다고 한다.
public class Fruit implements Comparable<Fruit> {
private final String name;
public Fruit(String name) {
this.name = name;
}
public String getName() {
return name;
}
// 이름이 같다면 같은 객체로 판별
@Override
public int compareTo(Fruit o) {
return this.name.compareTo(o.name);
}
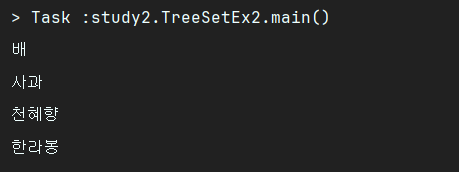
}각 객체를 저장하고, 이름을 출력해보았다.
public class TreeSetEx2 {
public static void main(String[] args) {
Set<Fruit> fruits = new TreeSet<>();
fruits.add(new Fruit("사과"));
fruits.add(new Fruit("배"));
fruits.add(new Fruit("한라봉"));
fruits.add(new Fruit("천혜향"));
fruits.forEach(fruit -> System.out.println(fruit.getName()));
}
}
마무리
추가적으로 더 조사해보니,
“비교는 Comparable/Comparator, 동등성은 equals, 해시 기반에선 hashCode는 보조 값으로 쓰이고 최종 비교는 여전히 equals가 한다.”
여기서 각 구현체마다의 비교방식은 조금씩 다르다는 결론을 얻어낼 수 있었습니다.