개요
"이거 임원이랑 부원 초기 추가할 때, 회원이 아니어도 가능하게 해주세요"
똑똑 프로젝트 유지보수를 진행하며 받은 요청이다.
사실, 초기에 개발 진행하면서도 받았던 요청인데
그때는 릴리즈가 얼마 남지 않은 상황이었고,
거의 다 완성된 기능에서 로직을 변경하는 데 주저함이 있었다.
릴리즈 후 어느정도 시간이 지나고 유지보수 단계에 들어서며 다시 이 제안이 나왔다.
나도 어느 정도 사용자 경험 측으로 봤을 때 불편할 수 있다는 점에 동의했다.
그렇게 요청대로 개선을 진행해보았다.
작업 진행
사실 당장 실사용자가 많지 않았지만 실제로 운영 중인 서비스였어서 기능에 문제가 생기거나, API 호출 오류가 발생해서는 안 된다고 생각했다.
그래서 나름대로 이 작업을 진행하면서 세운 목표가 있다.
무중단으로 변경하기
- 위에서 언급했듯, 실제 운영 서비스이기에 작업 후 재배포 시 정상작동해야 한다.
이런 작은 목표를 가지고 작업을 시작했다.
의존성 추가
우선 DB 마이그레이션 툴은 FLYWAY를 채택했다.
이유는 아래와 같다.
- 공부 진입장벽 낮음
- 주어진 시간이 많지 않았음
-> 진입장벽 낮음이 드는 시간 감소로 이어진다 생각했음
어쩌면 막연한 이유일 수 있지만 근거가 없는 것보단 낫다고 생각한다..
// Flyway
implementation 'org.flywaydb:flyway-core'
implementation 'org.flywaydb:flyway-database-{DB_NAME}'
DB_NAME에는 본인이 사용하고 있는 DB 종류를 넣어주면 된다.
작업 진행
처음에는 기존에 존재하는 부원과 사용자(회원)의 연관관계를 없앴다.
이후 이것이 작업 진행에 영향을 주고 말았다..
FLYWAY 마이그레이션 툴을 고려하기 전에는 JPA의 ddl-auto 옵션을 변경하여 DB 스키마를 변경하려 했다.
jpa: hibernate: ddl-auto: update
이 방법은 운영 환경에서는 쓰면 안 된다고 한다.
update 옵션은 기존 스키마를 유지하면서 변경된 부분을 반영한다는데, 정상적으로 작동하지 않을 가능성이 존재한다고 한다. 즉 안정성이 떨어진다.
(ex: 컬럼 삭제 등 스키마 구조를 크게 변경하는 행위)
실제 운영환경에서 리스크를 감안할 만한가? 라는 질문을 생각해봤을 때 그럴만한 가치가 있는 것 같지 않아, 이 방법을 포기했다.
그렇게 DB 마이그레이션 툴을 이용하기로 했고, 기존에 있던 더미데이터와 마이그레이션 쿼리를 분리해 resources 패키지에 저장했다.
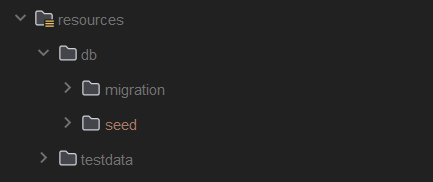
-
migration: 실제 운영환경에 사용할 마이그레이션용 쿼리 -
seed: 로컬 환경에서의 테스트를 위한 테스트용 쿼리 - gitIgnore 처리 된 것을 볼 수 있다. -
testdata: 기존에 사용하던 더미데이터 삽입용 쿼리
로컬 개발 환경에서 사용할 yml 설정을 지정해주었다.
flyway:
enabled: true
baseline-on-migrate: true
baseline-version: 0
locations:
- classpath:db/seed-
enabled: flyway 사용여부이다. -
baseline-on-migrate: flyway의 실행 기록(히스토리 테이블)을 확인하고, 현재 버전에 맞는 baseline 버전을 기반으로 그보다 높은 버전의 쿼리만 실행한다. false 처리되어 있다면, 실행 기록을 확인하지 않고, baseline-version 값 이후의 쿼리를 서버 작동마다 계속 실행한다. -
baseline-version: DB 버전 지정. 이 버전보다 높은 버전의 쿼리만 실행된다.(기본값 1, 보통은 현재 존재하는 스크립트와 버전을 맞춘다.)
겪은 문제
우선 위에서 언급했듯이, 코드 레벨에서 구조를 먼저 변경한 부분에서
문제가 생길 것 같다고 느꼈다.
현재 운영환경에서는 JPA의 ddl-auto 옵션을 none 으로 사용 중인데
분명히 운영 환경 DB와 코드의 불일치로 인한 에러 발생 가능성이 높았고,
그래서 총 3번의 작업을 거쳐 DB 마이그레이션을 진행했다.
- DB에 컬럼 추가
- 연관관계 삭제 시 영향 받는 로직 수정
- 코드레벨 연관관계 삭제와 동시에 DB 연관관계 삭제 및 백업 테이블 생성
1. DB에 컬럼 추가
V1__clubmember_add_column.sql
-> Flyway 파일명명 규칙에 따라 작성했기에 이런 이름이다
-- 부원 테이블에 사용자 이름을 추가
-- 1. club_members 테이블에 member_name 컬럼 추가
ALTER TABLE club_members ADD COLUMN member_name VARCHAR(255);
-- 2. 기존 데이터의 member_name을 users 테이블에서 가져와서 업데이트
UPDATE club_members
SET member_name = (
SELECT u.name
FROM users u
WHERE u.id = club_members.member_id
);
-- 3. member_name 컬럼을 NOT NULL로 변경
ALTER TABLE club_members ALTER COLUMN member_name SET NOT NULL;2. 영향받는 로직 수정
코드레벨의 수정이고, 크게 복잡했던 내용은 없어 생략하겠다.
3. 코드레벨 연관관계 삭제와 동시에 DB 연관관계 삭제 및 백업 테이블 생성
V2__clubmember_discard_user_join.sql
-- 1. 백업 테이블 생성
CREATE TABLE IF NOT EXISTS club_members_backup_v2 AS
SELECT * FROM club_members;
-- 2. 인덱스 삭제 (존재한다면)
DROP INDEX IF EXISTS idx_club_members_member_id;
-- 3. 외래키 제거 (있다면)
ALTER TABLE club_members DROP CONSTRAINT IF EXISTS fk_club_members_member_id;
-- 4. member_id 컬럼 삭제
ALTER TABLE club_members DROP COLUMN IF EXISTS member_id;이런 작업들을 거쳐서 기존에 존재하던 부원과 회원의 연관관계(1:N)를 안정적으로 제거하고 재배포하는 작업에 성공했다.
아쉬웠던 점
우선, 실제 사용자의 데이터가 많이 않았다는 점이 실제 환경과 큰 차이인 것 같다.
현재 운영환경은 롤링 배포 방식을 이용하고 있는데,
더 다량의 데이터와 큰 변경을 진행했다면 구조가 바뀌는데 시간이 걸렸을 테고, 이를 직접 경험해보지 못한 부분이 아쉬웠다.
또 작업을 끝내고 난 후 든 생각이었지만, '이 방식이 정말 최선이었을까?' 하는 생각이 들었다. (매번 남는 아쉬움인것 같다.)
배운 점
- 내가 생각했던 것보다, SQL은 중요했다.
-> ORM으로 인해 약간 소홀하게 생각했던 것 같다.