개요
최근, 인기 동아리 조회에 대한 체감 상으로 느린 것 같은 기분이 들었다.
다만 체감 상이라는 것 때문에, 이 모호함을 명확하게 하여 해결하면 좋은 경험이 되지않을까하는 생각에 진행하게 되었다.
기록은 아래와 같은 순서로 정리해보았다.
- 준비
- 지표 확인
- 해결 시도 1
- 해결 시도 2
- 결론
해결 진행 방식
준비
우선 AI에게 프로젝트의 엔티티 구조를 파악하여 스스로 정리해 MD 파일로 출력하게 했다.

이를 기반으로 동아리 데이터 약 110건, 사용자 1만 건, 즐겨찾기 2.5만 건의 더미데이터를 삽입하여 로컬 테스트를 진행해보았다.
데이터 삽입은 더미 SQL 파일을 로컬용 마이그레이션 패키지에 넣어 실행했다.
지표 분석
실행한 API의 속도는 놀랍게도 이랫다.
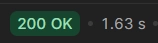
분명히 특정한 기준에 맞는 동아리를 조회하는 로직이었기에, 110건의 데이터임에도 불구하고 이 속도는 매우매우 문제가 있었다.
추출한 쿼리 로그는 이랬다.
SELECT
c1_0.id,
c1_0.name,
c1_0.club_type,
c1_0.club_category,
c1_0.custom_category,
c1_0.summary,
c1_0.profile_img,
(SELECT COUNT(cm1_0.id) FROM club_members cm1_0 WHERE cm1_0.club_id = c1_0.id) AS member_count,
COALESCE(af1_0.is_recruiting, false) AS recruiting,
af1_0.apply_end_date
FROM clubs c1_0
LEFT JOIN applyforms af1_0
ON af1_0.club_id = c1_0.id AND af1_0.status = 'ACTIVE'
WHERE
((((SELECT COUNT(cm2_0.id) FROM club_members cm2_0 WHERE cm2_0.club_id = c1_0.id) * 0.7) +
((SELECT COUNT(f1_0.id) FROM user_favorites f1_0 WHERE f1_0.club_id = c1_0.id) * 2.5)) +
(c1_0.view_count * 0.7)) >= 7.0
ORDER BY
((((SELECT COUNT(cm3_0.id) FROM club_members cm3_0 WHERE cm3_0.club_id = c1_0.id) * 0.7) +
((SELECT COUNT(f2_0.id) FROM user_favorites f2_0 WHERE f2_0.club_id = c1_0.id) * 2.5)) +
(c1_0.view_count * 0.7)) DESC,
c1_0.id DESC;확인해보니..카운트 쿼리가 확실히 많았다.
좀 더 확실한 지표와 성능을 확인하기 위해 위 쿼리에 EXPLAIN (ANALYZE, BUFFERS) 를 붙여 결과를 확인해보았다.

플랜 시간은 둘째치고, 쿼리 실행 시간이 너무 오래걸렸다.
병목 부분을 명확하게 확인해보고자 다른 부분을 탐색해보았다.

당장 보이는 문제는 이랬다.
1. 지워지는 행이 2.5만 개
2. 1의 과정이 100회 반복
어느 부분인지 정확하게 알아보고자 별칭을 기반으로 쿼리를 찾아보았다.

확인 결과, 각 동아리의 즐겨찾기 개수를 카운팅하는 과정이 있는 서브쿼리였다.
해결 시도 1
우선 쿼리의 복잡도를 낮추고, 복잡한 서브쿼리들을 JOIN로 풀어내보려했다.
SELECT
c.id,
c.name,
c.club_type,
c.club_category,
c.custom_category,
c.summary,
c.profile_img,
COUNT(DISTINCT cm.id) AS member_count,
COALESCE(af.is_recruiting, false) AS recruiting,
af.apply_end_date
FROM clubs c
LEFT JOIN club_members cm ON c.id = cm.club_id
LEFT JOIN user_favorites uf ON c.id = uf.club_id
LEFT JOIN applyforms af ON c.id = af.club_id AND af.status = 'ACTIVE'
GROUP BY
c.id,
c.name,
c.club_type,
c.club_category,
c.custom_category,
c.summary,
c.profile_img,
c.view_count,
af.is_recruiting,
af.apply_end_date
HAVING
(COUNT(DISTINCT cm.id) * 0.7 + COUNT(DISTINCT uf.id) * 2.5 + c.view_count * 0.7) >= 7.0
ORDER BY
(COUNT(DISTINCT cm.id) * 0.7 + COUNT(DISTINCT uf.id) * 2.5 + c.view_count * 0.7) DESC,
c.id DESC;기존에 있던 서브 쿼리로직을 그대로 가져와 LEFT JOIN 하고 중복을 제거하는 방식을 사용해보았다.
실행 결과는 아래와 같았다.
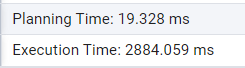
말도 안 되게 더 느려지고 말았다..
지표를 좀 더 살펴봤는데, 행의 개수가 정말 심상치 않았다.

무려 406,459 행..
생각해보니 동아리에는 여러 개의 일 대 다 관계의 필드가 있었다.
1. 즐겨찾기
2. 부원
3. 지원서
메인 테이블에 다수의 카테시안 곱을 고려하지 않고 쿼리문 단순화에만 신경써버린 탓이었다.
해결 시도 2
차라리 JOIN하는 테이블의 규모를 줄이는 게 좋겠다고 생각이 들었다.
그래서 중복되어 사용되는 연산 결과들을 CTE로 생성해서 실행해보았다.
WITH mc AS (
SELECT club_id, COUNT(*) as cnt FROM club_members GROUP BY club_id
),
fc AS (
SELECT club_id, COUNT(*) as cnt FROM user_favorites GROUP BY club_id
),
af_active AS (
SELECT club_id,
MAX(CASE WHEN is_recruiting = true THEN 1 ELSE 0 END) as is_recruiting,
MAX(apply_end_date) as apply_end_date
FROM applyforms
WHERE status = 'ACTIVE'
GROUP BY club_id
),
scored_clubs AS (
SELECT c.id, c.name, c.club_type, c.club_category, c.custom_category, c.summary, c.profile_img, c.view_count, c.created_at,
COALESCE(mc.cnt, 0) as member_count,
(COALESCE(mc.cnt, 0) * 0.7 + COALESCE(fc.cnt, 0) * 2.5 + c.view_count * 0.7) AS score,
COALESCE(af_active.is_recruiting, 0) = 1 as recruiting,
af_active.apply_end_date as apply_deadline
FROM clubs c
LEFT JOIN mc ON c.id = mc.club_id
LEFT JOIN fc ON c.id = fc.club_id
LEFT JOIN af_active ON c.id = af_active.club_id
)
SELECT id, name, club_type, club_category, custom_category, summary, profile_img,
member_count, recruiting, apply_deadline, score
FROM scored_clubs
WHERE score >= 7.0
ORDER BY score DESC, id DESC;EXPLAIN을 통해 확인해본 결과는 이랫다.
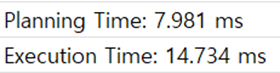
초기 쿼리에 비해 훨씬 빨라졌다!
중복된 스칼라 서브쿼리의 성능이 매우 치명적임을 알 수 있었다.
아래는 처음에 캡처했던 즐겨찾기 관련 연산과 동일한 역할을 하게 한 쿼리 부분이다.

실행 시간은 물론, 반복 횟수도 눈에 띄게 줄어들었다.
결론
우선, 이 조회 코드 자체는 개발 처음에 급하게 짰던 레거시 코드이다.
팀원이 작성한 알고리즘과 뷰에 맞춰서 작동했던 쿼리이기에, 성능 고려는 아예 하지 못한 상태였다.
무엇보다, QueryDsl을 통한 hibernate가 자동으로 생성한 쿼리였기에 단순히 '작동한다', '긴 쿼리문보다 낫다' 라는 안일한 마인드로 임한 우리 BE 팀의 실책이다.
다만 이번 기회를 통해
- 모호한 문제를 구체화
- 명확한 수치를 비교한 개선
이러한 유의미한 경험을 쌓을 수 있었다.