Aggregate Functions?
https://docs.oracle.com/database/121/SQLRF/functions003.htm#SQLRF20035
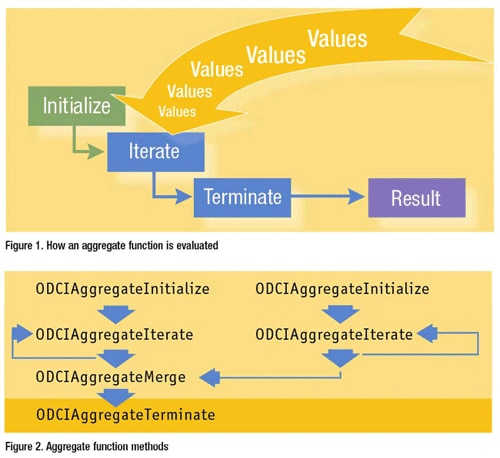
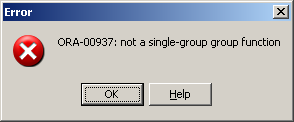
- 개요 및 특이사항: Aggregate Function, 즉 그룹 함수는 다수의 행을 바탕으로 단행의 결과를 리턴한다. 또한 select 절에 사용하려면 별도의 조치 없이는 일반 Column 조회 및 Single-row Function과 동시에 선언할 수 없다. (선언시 ora-00937: not a single-group group function 발생함)
Aggregate Function: Sum/Avg
- syntax of the sum/avg: sum(Col) / avg(Col)
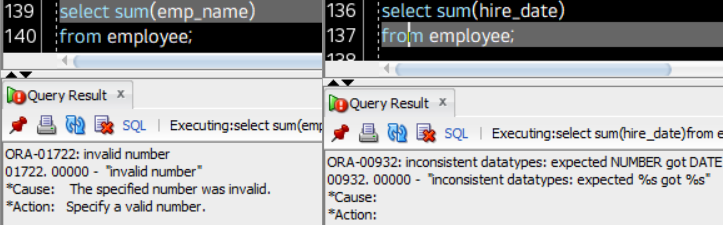
- 인자로 받은 Column의 합계/평균을 산출하며, group by clause를 선언하지 않은 상태에서도 사용이 가능하다. 단, 산술 연산 기반의 함수이므로 인자로 받은 Col의 값들은 반드시 숫자여야 한다. (Col의 값이 char/date일 경우 다음과 같은 에러가 발생함.)
sum(salary) || '원'
from employee;
trunc(avg(salary)) || '원'
from employee;Aggregate Function: max/min
- syntax of the max/min: max(Col) / min(Col)
- 인자로 받은 Col의 값을 정순(min, asc), 역순(max, desc)으로 판별하여 1순위의 값을 리턴한다. 즉 인자로 받은 Column의 값이 문자(character)인 경우 사전 등재순의 첫 값(min), 사전등재역순의 첫 값(max)을 리턴하며, Column의 값이 date인 경우 가장 오래된 날짜(min), 가장 최신의 날짜(max), Column의 값이 Numeric(숫자)인 경우 가장 작은 수(min), 가장 큰 수(max)를 리턴하게 된다.
Aggregate Function: count
- syntax of count: count(Col/Condition)
- 행(row)의 수를 센다. 예를 들어 count(emp_name)를 작성하였을 때 수 24가 리턴된다면 이는 Column emp_name에 24개의 행이 존재한다는 의미가 된다. (= 24명의 직원이 해당 테이블에 등록되어 있다는 뜻) 결과값은 항상 숫자의 형태로 리턴되며, 인자로 조건문을 작성하여 해당 조건에 해당되는 경우의 수를 전부 세어줄 수도 있다. 단 주의할 점은, 인자로 조건문을 작성하고 해당 조건문 내에 else/default value를 작성하는 경우 모든 경우에 조건문이 발동되므로 count(*)와 같은 효력을 가지게 된다.
--employee 테이블에서 모든 행의 수를 세기
select count(*) -- = count all
from employee;
--조건문에 해당하는 경우의 수만 세기(manager_id의 값이 200인 경우만 세기)
select manager_id, count(decode(manager_id, '200', 'a'))
from employee
where manager_id is not null
group by manager_id
order by manager_id asc;
--조건문을 인자로 받지만 사실상 모든 경우의 수를 세기
select manager_id, count(decode(manager_id, '200', 'a',
'else'))
--defaultValue로 'else'를 선언하여 조건문이 모든 경우에 발동하므로
--count가 모든 경우의 수를 세게 된다. = count(*)
from employee
where manager_id is not null
group by manager_id
order by manager_id asc;
아! 응애에요!