Group by/Having Clause?

- 개요 및 특이사항: group by는 데이터 조회를 위한 세부 그룹을 설정하는 역할, having은 group by를 통해 지정된 세부 그룹을 필터링하는 역할을 수행한다. 그룹 함수들은 select절에 사용하려면 별도의 조치 없이는 일반 column 조회 및 단행함수를 사용할 수 없으나 group by에서 선언한 Column/Columns는 일반 Column이라 할지라도 선언이 가능하다. 또한 column은 다중 선언이 가능하다.
--ex
select count(*), salary, avg(salary), sum(salary)
from employee
where salary is not null
group by salary
--만약 위의 코드에서 select hire_date, emp_name등을 입력하게 되면
--에러가 발생하게 된다. (group by에 선언되지 않았기 때문)Diffrence between where and having clauses

- where/having절을 선언하는 경우의 차이: where 절에서는 group 함수의 사용이 불가능하다. 때문에 group by로 묶인 그룹 및 select의 Aggregate functions를 통해 도출된 값에 추가로 조건문을 달아 필터링 하고 싶다면 having 절에 조건문을 입력하면 된다. 조건문을 다룬다는 점에서 where와 having절은 비슷해 보이지만, where는 테이블의 실제값을 대상으로 조건문을 대입하고, having은 Aggregate Functions(그룹 함수)를 통해 도출된 결과에 조건문을 대입한다는 차이가 결정적이다.
--ex)
select dept_code, --부서코드 조회
count(*) --모든 부서코드 당 인원수 조회
from employee --employee table에서
group by dept_code --부서코드(같은 부서) 단위로 그룹형성
having count(*) >= 3 --해당 부서코드의 인원수가 3이상인 경우
order by dept_code; --부서코드 오름차순 정렬Analyzing Data with rollup/cube
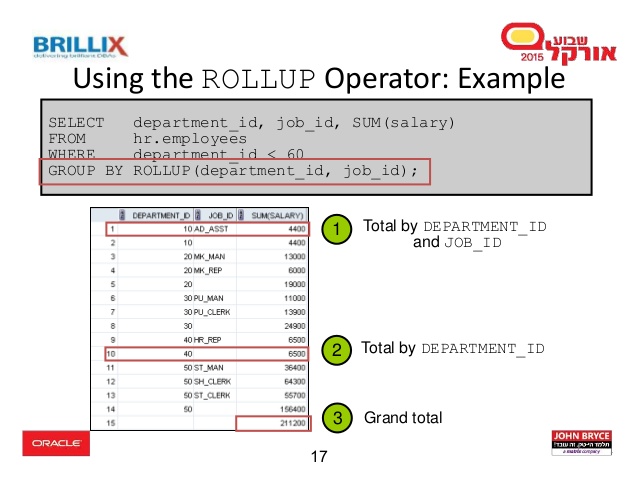

- syntax of rollup: group by rollup(Col1, Col2 ...)
- syntax of cube: group by cube(Col1, Col2 ...)
- 그룹별로 산출한 결과값의 소계를 포함하여 산출하는 함수로 rollup과 cube를 사용할 수 있다. 여기서 rollup은 지정된 Column에 대해 단방향의 소계를 제공하고, cube는 지정 column에 대해 양방향의 소계를 제공한다. 말이 좀 어렵다. 코드를 직접 보자.
analyze data: single-Col by rollup
select decode(grouping(dept_code), 1,
'Grand-total', dept_code) 총계판별,
count(*)
from employee
where dept_code is not null
group by rollup (dept_code)
order by dept_code;
analyze data: multi-Cols by rollup
select dept_code, job_codecount(*)
from employee
where dept_code is not null
group by rollup (dept_code, job_code)
order by dept_code;
select nvl(dept_code, 'dept') DEPT,
nvl(job_code, 'job') JOB,
decode(grouping(dept_code), 1,
'Total-dept', dept_code) 부서총계,
decode(grouping(job_code), 1, 'Total-Job',
'job_code') 직급총계,
count(*)
from employee
where dept_code is not null and job_code is not null
group by rollup (dept_code, job_code)
order by dept_code, job_code; 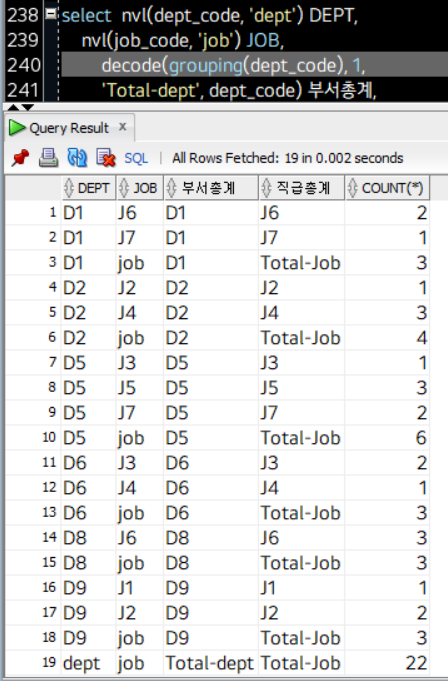
analyze data: single-Col by cube
select decode(grouping(dept_code), 1,
'Grand-total', dept_code) 총계판별,
count(*)
from employee
where dept_code is not null
group by cube (dept_code)
order by dept_code;
analyze data: multi-Cols by cube
select dept_code, job_codecount(*)
from employee
where dept_code is not null
group by rollup (dept_code, job_code)
order by dept_code;
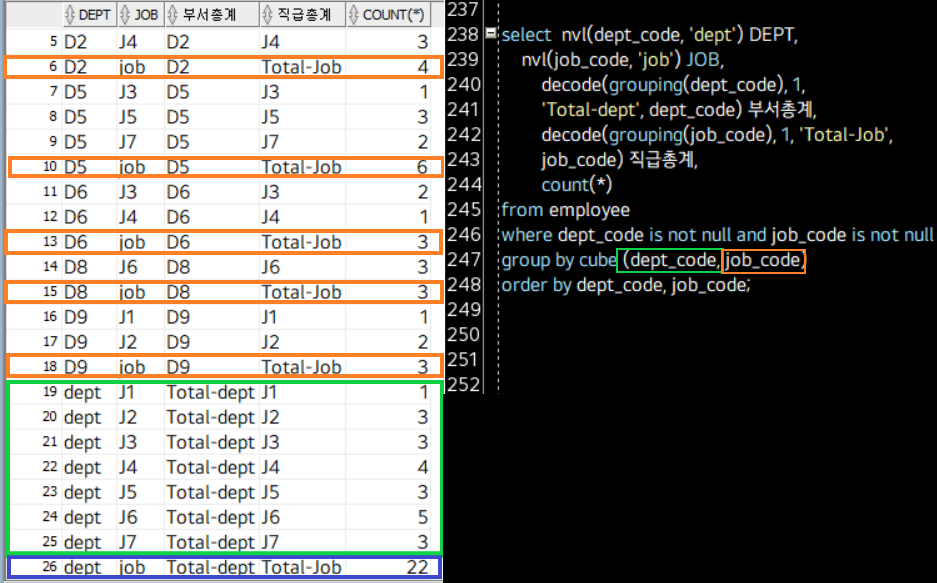
select nvl(dept_code, 'dept') DEPT,
nvl(job_code, 'job') JOB,
decode(grouping(dept_code), 1,
'Total-dept', dept_code) 부서총계,
decode(grouping(job_code), 1, 'Total-Job',
'job_code') 직급총계,
count(*)
from employee
where dept_code is not null and job_code is not null
group by cube (dept_code, job_code)
order by dept_code, job_code; 
Diffrence between rollup and cube expressions
- rollup과 cube의 단방향소계/양방향소계의 차이점을 너무나도 잘 정리한 글이 stackoverflow에 있어서 우선 링크를 소개한다:
https://stackoverflow.com/questions/7053471/understanding-the-differences-between-cube-and-rollup/27222655
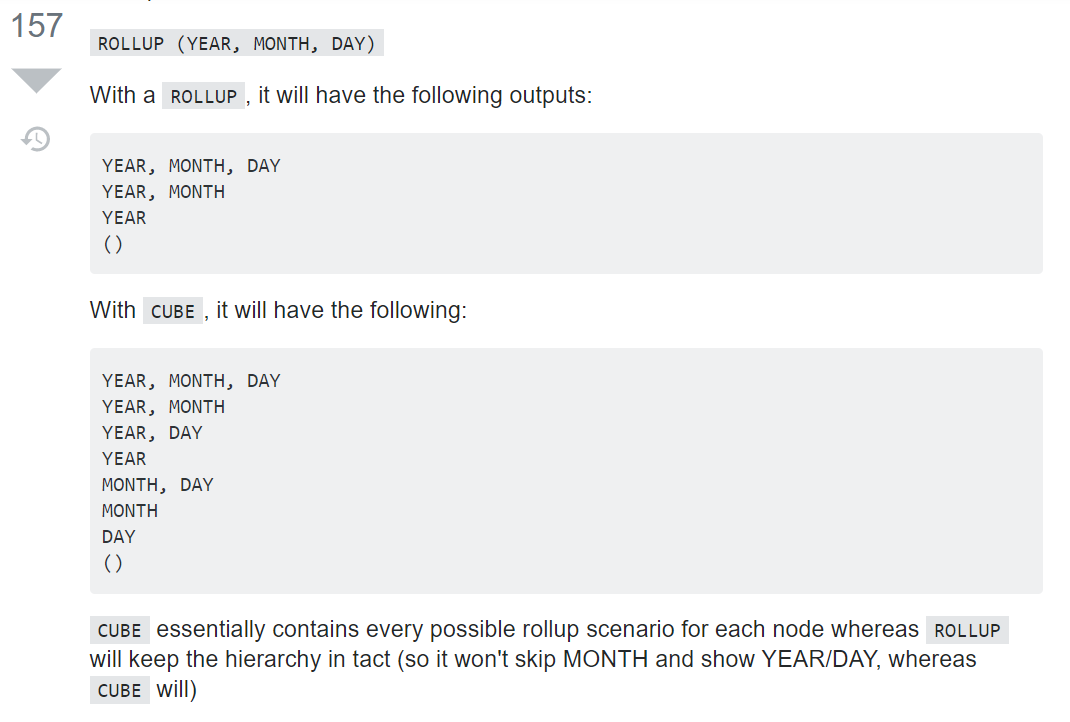
Single-Column 단위로는 rollup과 cube 둘 다 총계, 즉 전체 값의 합을 한 행으로 리턴한다. 즉, Single-Column 단위로는 rollup과 cube의 차이점은 드러나지 않으며 다중 column을 선언하는 경우 그 차이가 드러난다.
rollup w.multi-Cols: examples
다중 컬럼-rollup:
기본적으로 그룹별로 산출한 결과값의 소계를 포함하여 출력한다. 인수로 선언된 Column을 계층구조 기반으로 소계를 내기 때문에 Column의 선언 순서가 매우 중요하다. 가장 먼저 선언된 Col1의 경우 모든 경우의 소계와 합계에 포함되고, 마지막으로 선언된 Col2의 경우 오직 합계에만 그 값이 포함된다.

위의 이미지를 보면, 각 부서(각 Dept_code)에서 직급을 부여받은 사원수를 세고 있다. D1 부서에서 직급을 가진 사원은 총 3명, D2에서 4명... 끝에는 모든 부서에서 종류불문 직급을 가진 사원의 총 수를 세고 있다. 또한 오른쪽의 실제 코드를 보자. 주황색 섹션에서 세고 있는 것은 결론적으로 해당 "부서의 인원수"이다. 각 직급의 수가 아니다. 상기했듯 rollup에서는 인자로 받는 Column의 순서가 중요하고, dept_code를 첫번째 인자로 전달했기 때문에 다음과 같은 결과가 도출된 것이다.
또한 다음과 같은 예도 존재할 수 있다:
select
decode(grouping(dept_code), 1, '총합', dept_code) "부서",
decode(grouping(manager_id), 1,
'매니저에게 관리받는 인원', manager_id) "배정된 매니저",
count(*) "인원수"
from employee
where dept_code is not null and manager_id is not null
group by rollup (dept_code, manager_id)
order by dept_code, manager_id;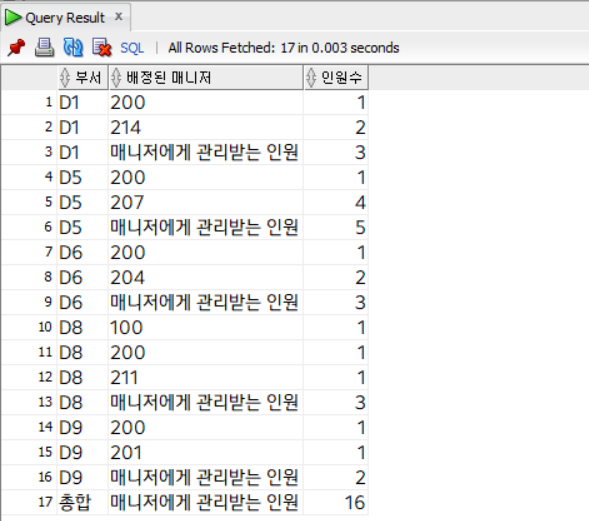
이렇게 보면 좀 더 이해가 쉽다. 마찬가지로 rollup의 인자로 먼저 dept_code를 선언했고, 그 다음에 manager_id Column을 인자로 선언했기 때문에 dept_code 중심의 소계와 합계가 도출되었다.
cube w.multi-Cols: examples
다중 컬럼-cube:
위 rollup의 예시와 다르게 초록색 섹션이 추가되었다. 초록색 섹션은 부서코드를 부여받은 모든 사원들 중에 각 직급을 가진 인원은 몇 명인지를 표시하고 있다. 다시 말해 cube는 인자로 선언한 모든 Column 간의 Cross-Tabulation(=cross-tab), 즉 다차원 집계를 제공한다. 아래의 예시에서 인자는 두 개의 Column이지만, cube는 rollup과 다르게 인자가 더 늘어나더라도 모든 경우의 수를 표시하게 될 것이다.
Aggregate Function: groupping
- syntax of grouping(1): select grouping(Col)
- syntax of grouping(2): decode(grouping(Col), 1, 'subtotal', Col)
- 특별한 조치가 없는 경우 rollup/cube 등의 함수로 소계와 총계를 낼 때에 해당되는 행은 (null)로 표시된다. 이 때 grouping을 사용하면 rollup/cube를 사용하여 도출한 행에 1, 그 외의 경우 0을 리턴한다. 여기에 decode를 함께 활용하면 (null)을 직접 지정한 값으로 대체할 수 있다.
(rollup/cube만) / (grouping추가) / (grouping+decode추가)

