공부 정리
1.Set, Dictionary가 lists보다 탐색이 빠른 이유

학생이 20명 있는 반에서 특정 학생이 있는 지 확인하려면 한 명씩 대조하여 20번 확인하면 되기 때문에 List가 O(n)인 것은 자연스럽다.그런데 어떻게 Set, Dictionary는 O(1)에 확인할 수 있을까?이는 Hash table 구조이기 때문이라고 한다.쉽
2.해시(Hash)와 충돌(Collision)

교실에 학생이 20명 있을 때 A 학생이 있는 지 찾는다고 하자.이때 학생들마다 자리가 정해져있다면 A학생의 자리만 확인하면 되기 때문에 탐색이 빠르다.이때, 각각의 학생의 자리를 정해주는 방법이 Hash라 할 수 있다.그런데 해시 함수의 출력값은 한정된 범위에서 나온
3.정규식 활용 예시

정규식 활용 예시 주요 메타 문자 .findall() | 기호 | 설명 | 패턴 | 테스트 문자열 | 결과 | |---------|----------
4.continue, pass, next, break
별 것 아니지만 가끔 헷갈린다.
5.sorted(), .sort(), key = lambda, reverse = True에 대해
iterable한 객체에 대해 사용원본 데이터는 유지정렬된 데이터를 리스트 형태로 반환reverse, key 사용 가능리스트에만 사용 가능원본을 직접 정렬반환 값은 Nonereverse, key 사용 가능reverse = True 넣으면 역순abs, len 등 기준으로
6.collections.Counter()와 PEP 8
collections.Counter() 항상 헷갈려 나만 헷갈렸을까? collections.Count()를 쓸 때마다 collection에 s가 붙었는 지 안 붙었는 지, c가 소문자였는 지 대문자였는 지 헷갈리고, Count 역시 마찬가지로 헷갈렸다. 그냥 많이
7.collections.defaultdict()에 대해
기본 dict 은 존재하지 않는 key를 조회하면 에러가 발생한다. 따라서 매번 key의 존재 여부에 따라 코드를 작성하는 불편함이 있다.
8.lists의 대소 비교에 대해
파이썬은 list끼리 크기 비교가 가능하다. 같은 인덱스끼리 사전식으로 비교한다.짧은 list의 마지막 인덱스까지 크기가 같다면, 길이가 짧은 쪽을 작다고 판단한다.같은 인덱스에 있는 두 값의 type이 다르면 error가 발생한다.따라서 list의 요소의 type을
9.파이썬의 다중 할당(Multiple Assignments)
다중 할당은 편하다.그런데 링크드 리스트(Linked List)에서 헷갈리는 부분이 있어 정리해본다.x, y = 1, 2와 y, x = 2, 1은 같은 결과를 주지만,node1, node1.next = node2, node2.next와 node1.next, node1
10.정규식 re.sub()에 대해
정규식에 조금씩 익숙해져가고 있다.문제를 풀던 중 정규식에서 실수한 부분을 정리해둔다.char = 'a'일 때 문자열에서 a를 지우고 싶은데re.sub()의 첫번째 인수로 char를 넣어야하는데 r"\[char]"를 넣는 실수를 했다. 아래는 GPT의 도움을 받아 정리
11.파이썬 연결 리스트를 다룰 때 흔히 실수하는 참조 업데이트 문제
min_head = lists\[0], min_head = min_head.next라고 하더라도 lists\[0]은 바뀌지 않는다. min_head는 복사본이라 생각하면 된다. 복사본만 바뀌는 것이다. 사실 이건 연결리스트랑 무관한다. b=\[1], a=b\[0],
12.힙(Heap)과 우선순위 큐(Priority Queue)
heap이란 여러 개의 값 중에서 가장 크거나 작은 값을 빠르게(O(1)) 찾기 위해 만든 이진 트리이다. 완전 이진 트리이며, 부모의 값은 자식의 값보다 항상 크거나(max heap) 작다(min heap). 완전 이진 트리이므로 데이터의 삭제/삽입 모두 O(log(
13.파이썬에서 *연산자와 얕은 복사(Shallow Copy)
파이썬에서 가변 객체에 \*연산은 객체가 아닌 참조를 복사한다.엑셀로 따지면 값 붙여넣기가 아니라 그냥 붙여넣기다.A1, A2, A3, A4 셀에 B1셀을 복사 붙여넣기 하여 =B1이 입력된다면, B1셀을 바꾸면 A1, A2, A3, A4가 모두 바뀐다. 같은 일이 \
14.zip과 *, **을 이용한 언패킹(unpacking)
zip은 여러 iterable한 객체를 하나로 묶어 tuple의 리스트를 생성\*는 iterable한 list, tuple 의 요소를 개별 인수로 풀어서 전달\*\*는 dictionary의 key:value를 개별 인수로 풀어서 전달
15.부모 함수의 변수에 접근할 때 유의할 점
변수의 scope 개념이 확실하지 않아서함수를 중첩하여 사용할 때어떤 경우엔 부모 함수의 변수를 그냥 쓸 수 있고어떤 경우엔 그냥 쓰면 에러가 나서 왜 그런지 찾아보았다. mutable과 immutable을 구분하는 것이 핵심이었다. mutable 예를들어 list는
16.얕은 복사와 깊은 복사의 차이
backtracking 문제를 풀다 보면 path\[:]를 결과에 추가하는 경우가 많다. path로 하면 이전에 추가한 결과들이 같이 바뀔 수 있기 때문이다. 그런데 값만 복사하기 위한 방법으로 \[:]도 있고 copy모듈을 사용하는 방법도 있는데 어떤 차이일 지 궁금
17.파이썬 클래스 메서드 총정리: 인스턴스 메서드, 정적 메서드, 클래스 메서드, 그리고 특수 메서드까지
파이썬 알고리즘 인터뷰 57번(LeetCode 336. Palindrome Pairs)의 풀이를 보던 중 처음 보는 표현이 있었다.바로 class의 @staticmethod라는 데코레이터였다.staticmethod, 그러니까 정적 메소드는 클래스나 인스턴스의 변수와 상
18.파이썬에서 a += b와 a += b, 의 차이
a += b, 콤마가 왜 들어가있지? 파이썬 알고리즘 인터뷰 59번(LeetCode 56. Merge Intervals)의 풀이에 처음보는 표현이 있었다. 바로 result += interval,처럼 += 뒤에 콤마(,)가 찍혀있는 것이다. 콤마(,)를 찍으면 튜플이
19.파이썬 모듈 임포트(import) 완벽 가이드 🚀 - PEP 8 스타일과 실용적인 방법 정리
모듈을 import할 때 여러 방법이 있다.나는 보통 리트코드를 주로 이용하고 있는데 리트코드에서 파이썬 표준 라이브러리는 import하지 않아도 된다.그래서 import를 직접 타이핑한 적이 별로 없는데, import도 방법이 여러가지 있고, 권장하는 스타일이 있다.
20.cmp_to_key를 이용하여 복잡한 정렬하기(feat. 추이성)
파이썬 알고리즘 인터뷰 61번(리트코드 179) Largest Number을 풀다보니 두 문자열의 대소를 비교할 때 기존 사전식이 아닌 직접 정의된 대소 관계가 필요했다.그런데 람다 표현 정도로는 할 수 없었다.두 문자열의 대소를 비교하긴 쉬운데 이를 이용해서 정렬을
21.Python bisect 모듈 이용한 이진 탐색
파이썬 알고리즘 인터뷰 65번(리트코드 704) Binary Search의 풀이를 보니 이진 탐색 모듈 bisect가 있었다.이진 탐색을 직접 구현하는 것은 많이 해보았는데 이 모듈을 사용해보진 않았다.bisect 모듈을 이용하는 방법을 정리해보자. 아래 내용은 GPT
22.파이썬 try-except의 기본과 응용, 그리고 에러 종류
파이썬 알고리즘 인터뷰 65번(리트코드 704) Binary Search에서 try-except 구문을 사용하는 풀이가 있었다.이 풀이 자체가 중요한 것은 아니지만, try-except 구문이 있다는 것은 알지만 잘 사용해본 적은 없어 내용을 찾아 정리해보았다. 아래는
23.파이썬 and 연산자와 & 연산자의 미묘한 차이
파이썬 알고리즘 인터뷰 67번(리트코드 349번) Intersection of Two Arrays를 풀며 두 집합을 교집합할 때 &를 써야하는데 호기심에 and를 써보았더니 예상(교집합)과 다른 결과가 나왔다.그 이유를 찾아보고 정리해보았다.먼저 간단히 집합 관련 함수
24.zfill과 rjust
프로그래머스 2018 KAKAO BLIND RECRUITMENT \[1차] 비밀지도를 풀며 zfill, rjsut를 사용하게 되었는데 익숙하지 않아 이에 대해 정리해본다. 아래 내용은 GPT의 도움을 받아 정리하였다.
25.정규식 re.findall()에 대해
관련 문제 프로그래머스 2018 KAKAO BLIND RECRUITMENT \[1차] 다트게임
26.파이썬 deque 정리: maxlen부터 rotate까지 핵심 기능 모음
27.파이썬 Counter 주요 메서드와 연산
Counter()를 자주 사용하는데 그 연산은 자주 사용하지 않아 익숙하지 않았다.관련된 내용을 찾아 정리해본다.
28.정규식 pattern 에 변수 사용하기
관련 문제 LeetCode 771. Jewels and Stones또 정규식이다.정규식은 아직 헷갈리는 부분이 많다.re.sub(r'\[abc]', '', cat)이라 하면 cat에서 a, b, c중 일치하는 것을 빈 문자열로 바꾸어 t가 된다. 그런데 abc 패턴을
29.파이썬 heapq, nsmallest vs heappop, heapify
30.Splay Tree와 Zig-Zig 연산의 순서는 왜 부모-조부모 회전을 먼저할까?(1)
Splay 트리의 zig-zig 연산은 x-p 회전보다 p-g 회전을 먼저 하는데, 그 이유는 뭘까?(접근하는 노드를 x, 그 부모를 p, p의 부모 즉, x의 조부모를 g라 하자)사실 x-p 회전 → p-g 회전으로 해도 결국 x는 루트로 잘 올라간다.그래서 “직관적
31.Splay Tree와 Zig-Zig 연산의 순서는 왜 부모-조부모 회전을 먼저할까?(2)
Splay 트리와 기본 연산(zig, zig-zig, zig-zag)에 대해 소개했다. zig-zig 연산을 할 때 x-p 회전보다 p-g 회전을 먼저 하는 것에 대한 의문을 제기했다.p-g 연산을 먼저하면 아래와 같은 장점이 있음을 구체적인 예시를 통해 확인해보았다.
32.윈도우에서 리눅스를 처음 사용하는 사람을 위해
유닉스 수업을 들으면서 실습과 과제를 위해 리눅스를 설치해야했다. 아쉽게도 수업에 실습이 없어서 책을 보며 스스로 해야했다. 처음에는 교재에 있는대로 가상머신을 깔고 록키 리눅스를 설치했다.그런데 매번 가상 머신을 키는 것이 번거로웠고, 노트북 없이 외출했을 때 태블릿
33.KMP 알고리즘을 이용한 문자열 검색
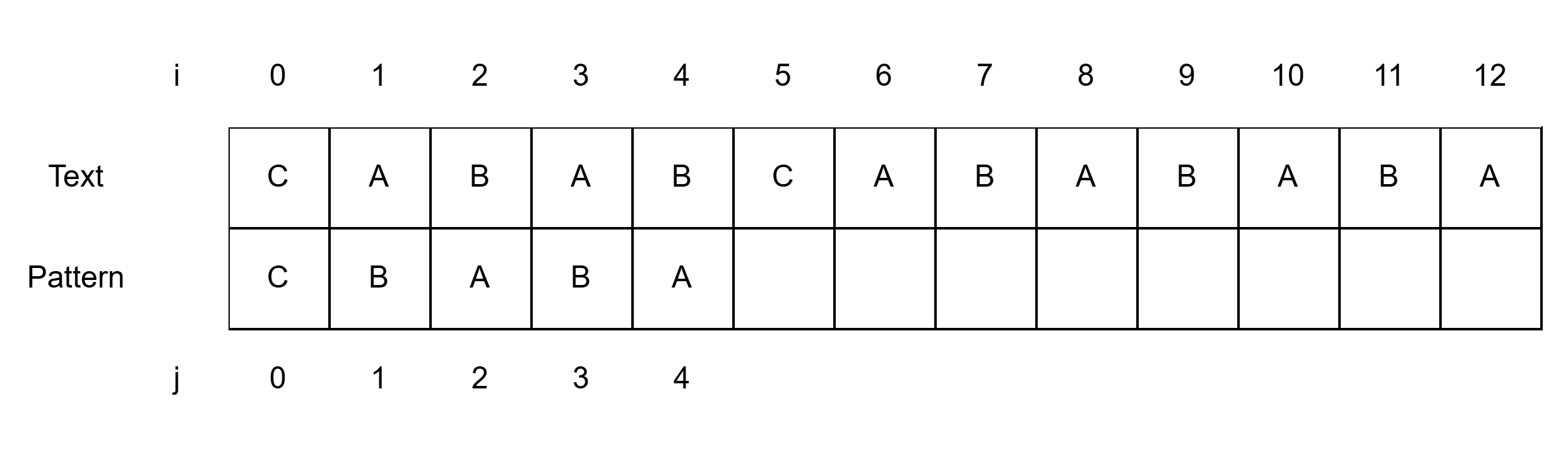
하루에도 여러 번 Ctrl + F 해서 검색하는 일이 있다. 어떻게 동작하는 지 고민해본 적이 없는데 여기에도 여러 알고리즘이 있다.그 중 KMP 알고리즘을 소개한다. KMP는 만든 사람들의 이름의 첫 글자를 따서 만든 이름이다. 이 글에서는 별 말이 없으면 길이 n인
34.[알고리즘] 거스름돈 문제: 그리디가 언제나 통할까? (필요충분조건과 증명 스케치)
알고리즘 수업에서 Greedy Algorithm 예시로 접하는 것이 바로 거스름돈 문제(Change-Making Problem) 이다. "가장 적은 개수의 동전으로 거스름돈을 주려면 어떻게 해야 할까?"가장 먼저 "가장 큰 단위의 동전부터 낼 수 있는 만큼 낸다"는 그