
순서
1. 메모리가 관리되는 방법(내용이 길어서 빠르게 슥 보고 넘기자)
2. 리눅스가 메모리를 관리하는 방법
3. 메모리 고갈 상황과 CPU사용률을 계속 체크하는 이유
유튜브 [10분 테코톡] 🤷♂️ 현구막의 리눅스 메모리 관리 의 내용
메모리가 관리되는 방법
메모리와 CPU
메모리는 주소덩어리, 주소로 인덱싱을 하는 커다란 배열이다
컴퓨터가 부팅되면 비어있던 메모리에 운영체제, 사용자 프로그램이 차곡차곡 채워져 CPU를 사용할 기회를 기다린다
CPU가 메모리에 체워진 프로그램 속 코드들을 바로 읽을 수 있으면 좋겠지만, CPU는 코드를 읽지 못한다
그래서 코드들을 컴파일러를 통해 숫자(0,1)로 바꿔줘야한다

논리 주소
위처럼 컴파일러가 동작하는 과정 중 코드들의 주소를 결정한다
이 때 코드의 main, a, b 와 같은 메서드와 변수들을 심볼릭 주소라 하고, 컴파일러가 변환시킨 숫자주소를 논리 주소라고 한다

위처럼 프로그램1이 컴파일 되어 코드주소 0~19번 까지 메겨졌다, 이 후 두 번째로 프로그램2가 컴파일 되면 코드주소는 20~39가 아닌 0~19번 까지 메겨진다
가상 주소
즉, 각각 프로그램마다 중복되는 논리 주소를 가지고 있다 그래서 논리주소를 가상주소라고도 부른다
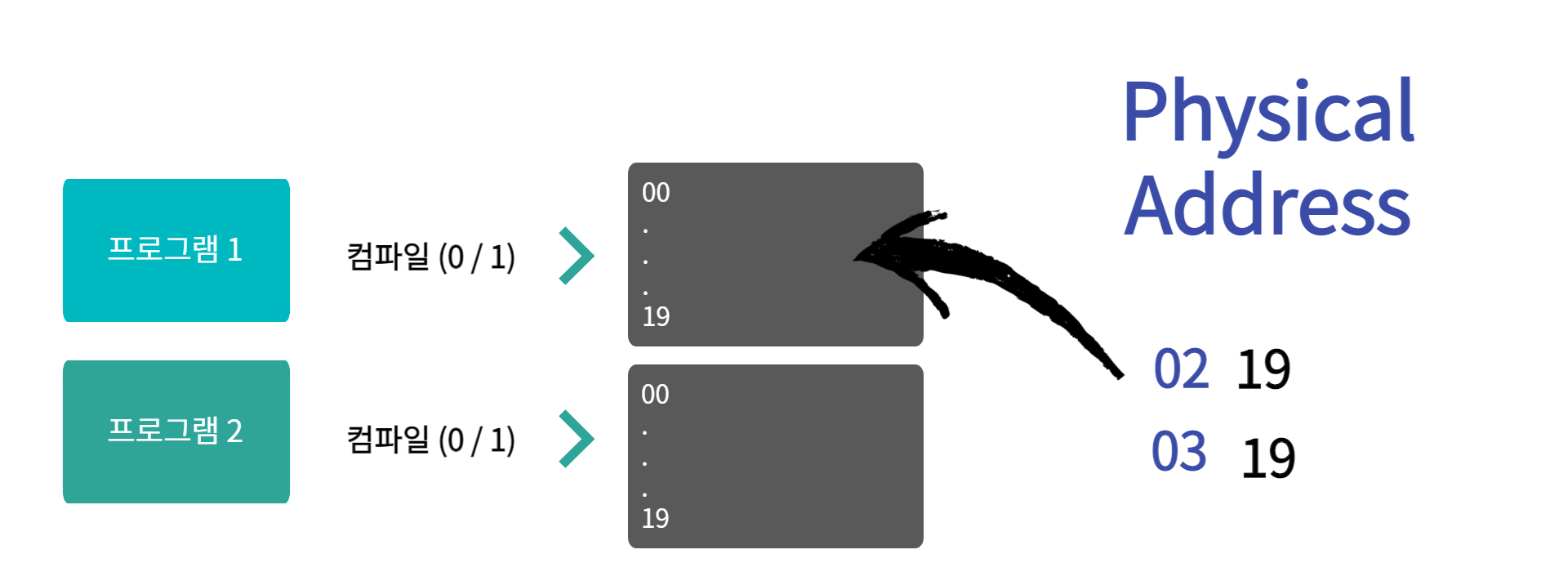
모두 같은 주소를 사용하면 메모리에서는 어떻게 이를 구별할까?
물리 주소
논리 주소에 하나의 주소값이 더 더해진다 그래서 각각의 독립적인 주소가 생긴다 이를 물리 주소라고 부른다
그러면, 심볼릭 주소에서 바로 물리 주소로 변환하면 더 좋을거 같은데 왜 중간에 논리주소로 한 번 더 분리하는 이유가 무었일까?
바로 CPU가 논리 주소만 읽기 때문이다
CPU는 현제 활동중인 프로세스의 내부 주소만 알면 되지, 어떤 프로세스인지는 중요하지 않기 때문이다
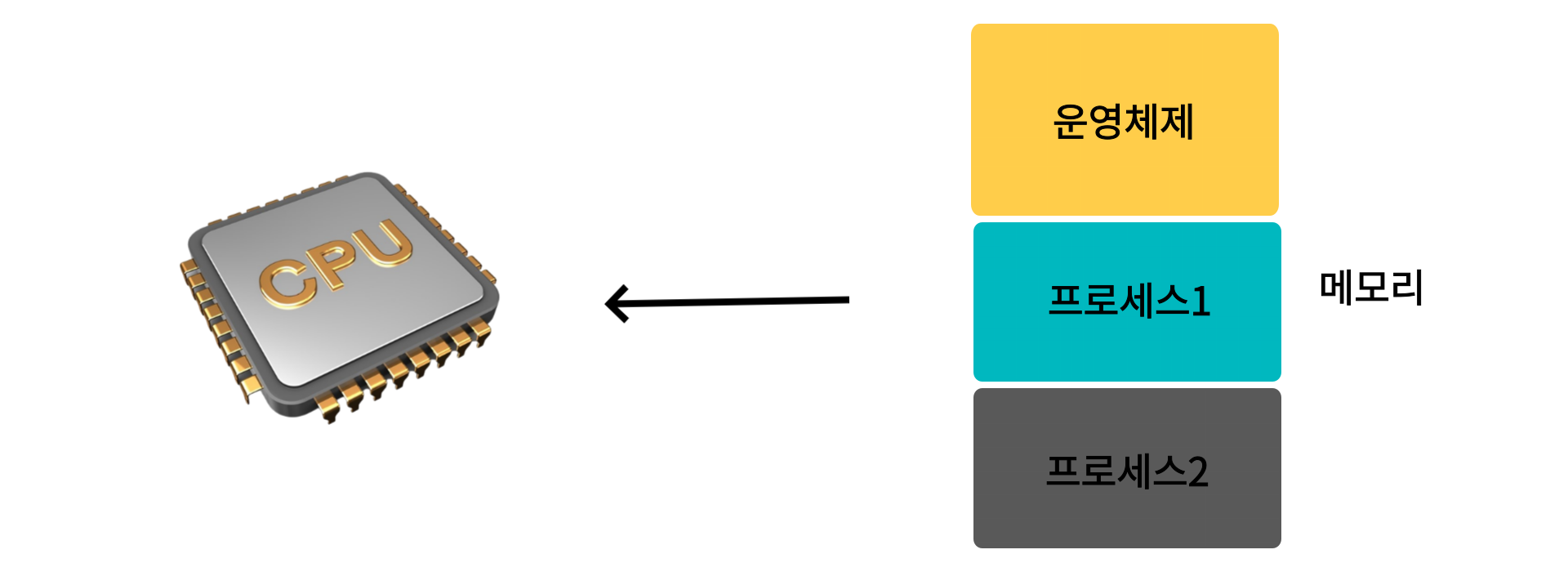
그러면 CPU는 논리주소 만으로 프로세스들의 정보를 읽고있고, 어떤 프로세스인지 모르는 상태에서 정보를 읽는것이 어떻게 가능할까?(운영체제가 도와준다 생각할 수 있지만 운영체제도 메모리에 올라와 동작하는 프로세스 중 하나이다)
즉 소프트웨어적으로는 물리주소를 찾도록 도와줄 방법이 없다 = 하드웨어적 도움이 필요
MMU
그 도움을 주는 것이 MMU, Memory Management Unit이다

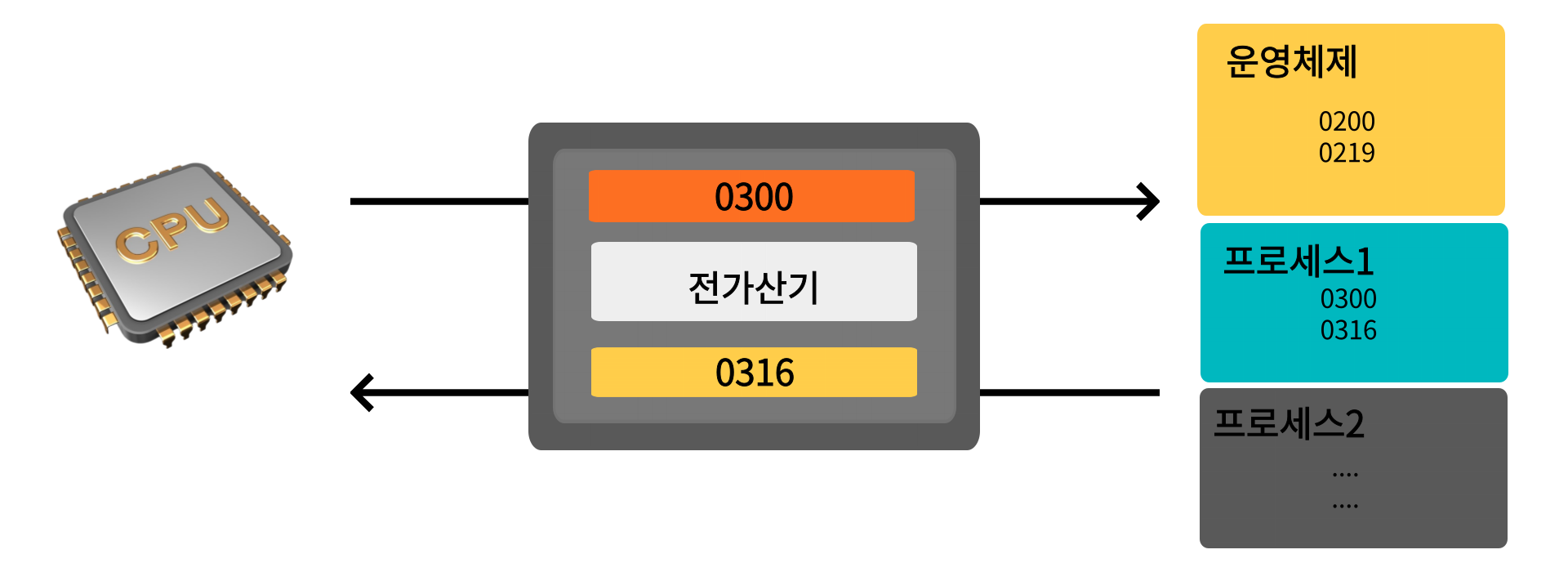
위는 MMU이고
base register = 프로그램 시작주소
limit register = 프로그램 마지막 주소
와 간단한 산술 연산기로 이루어져 있다
이러한 MMU는 "CPU를 사용하는 프로세스가 요청하는 논리주소" 가 요청하는 논리주소에 "MMU의 base register에 들어있는 시작주소"를 더해 물리주소로 변환 시킨다
이렇게 완성한 물리주소로 메모리에서 프로세스가 가진 정보를 찾을 수 있다
(limit register는 프로세스가 요청하는 논리 주소가 올바른지 base register가 동작하기 전 확인한다)
메모리가 프로세스들이 차례대로 채워지고 이렇게 MMU를 통해 고정된 주소를 더하면서 주소를 참조하는 간단한 작업이 이루어질 것 같지만 차례차례 프로세스를 쌓을 경우 메모리에 아무도 사용하지 못하는 구멍들이 생기게 된다
Swapping
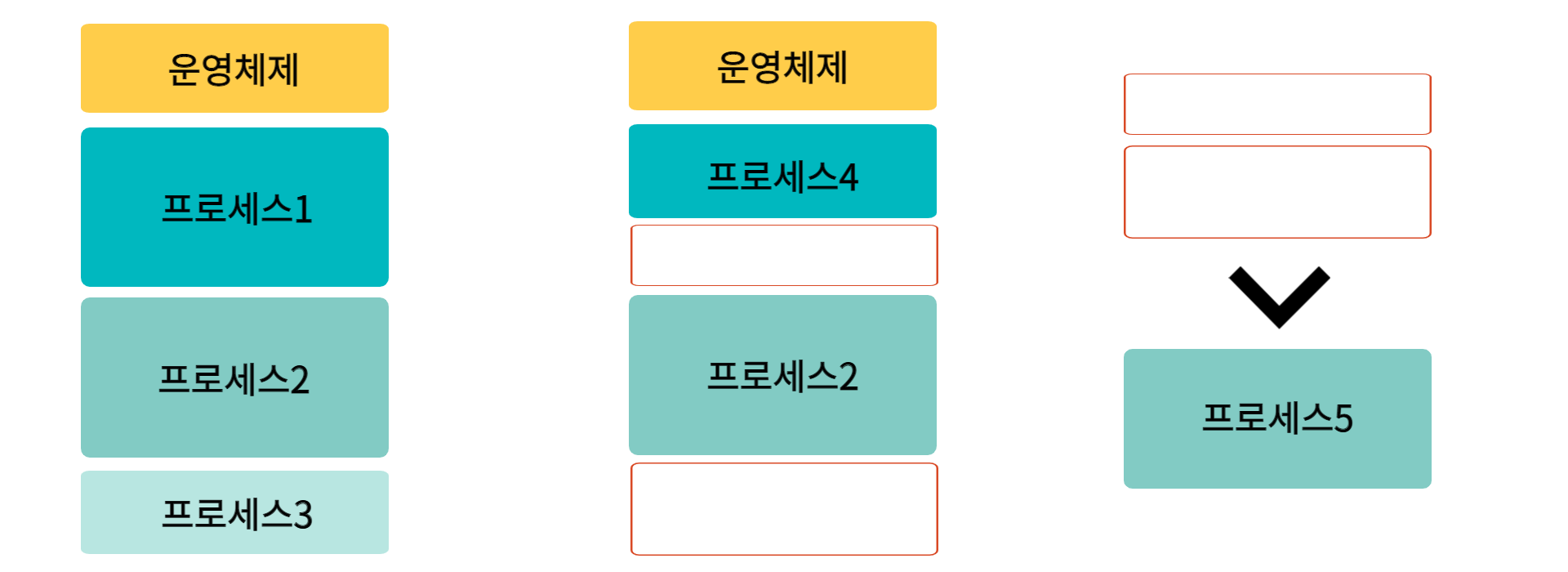
프로세스가 메모리에 차있다
프로세스1 / 프로세스3이 나가고, 프로세스 4가 들어왔다
위 처럼 프로세스5는 전체 메모리 공간으로 보면 들어갈 수 있지만 메모리에서는 들어갈 공간이 없다
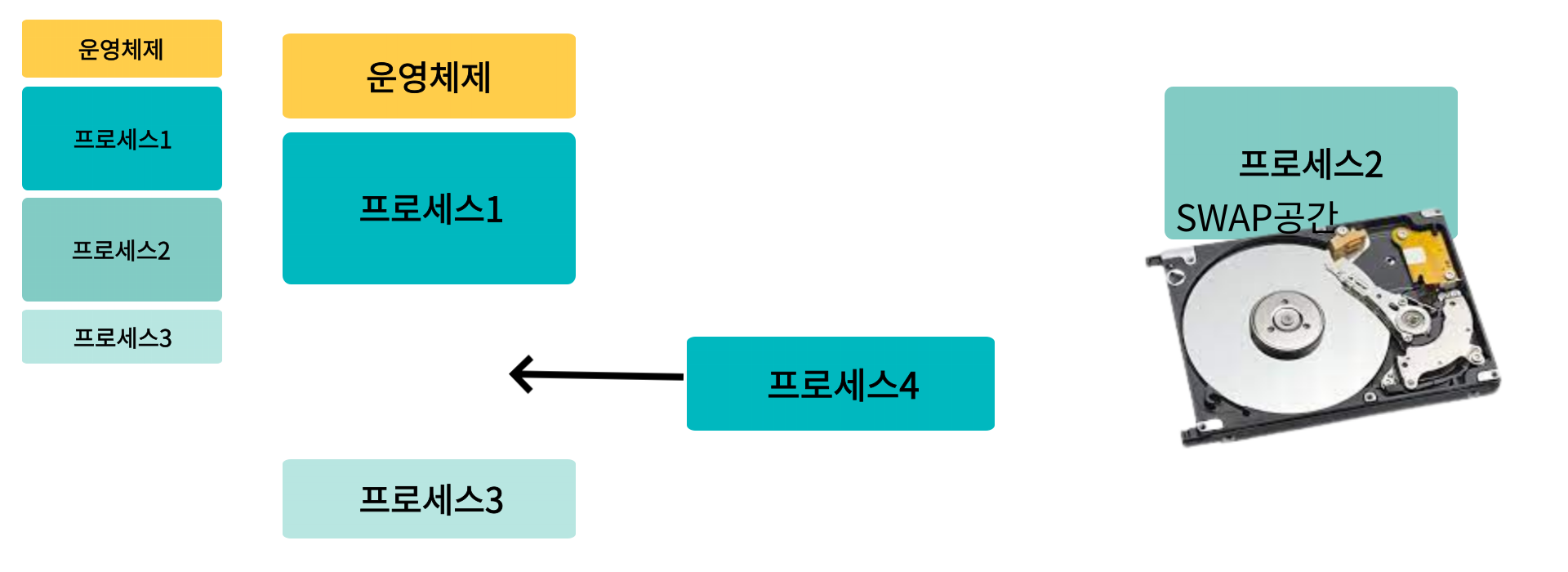
만약 위처럼 메모리가 프로세스로 차있는 상태에서 다른 프로세스가 들어오려면 당장 불필요한 프로세스를 내리고, 당장 필요한 프로세스를 올려야 한다
이 때 프로세스를 일시적으로 하드디스크에 있는 SWAP공간으로 쫓아내는 SWAPPING기법을 사용한다
하지만 SWAPPING할 프로세스를 고르는 것도 문제다(중요도에 따라 검사해도 시간이 걸린다)
SWAPPING할 때도 하드디스크에서 프로세스가 오고가는 시간이 많이 걸린다
그래서 메모리 공간을 일정하게 잘라두고, 그에 맞춰 프로그램을 조금씩 잘라 올리자는 결론이 나온다
Frame과 Page
그렇게 메모리를 일정하게 자른 공간들을 Frame라 한다, 그리고 그램들을 Frame과 동일한 크기로 자르는데 잘린 하나하나를 Page라 한다
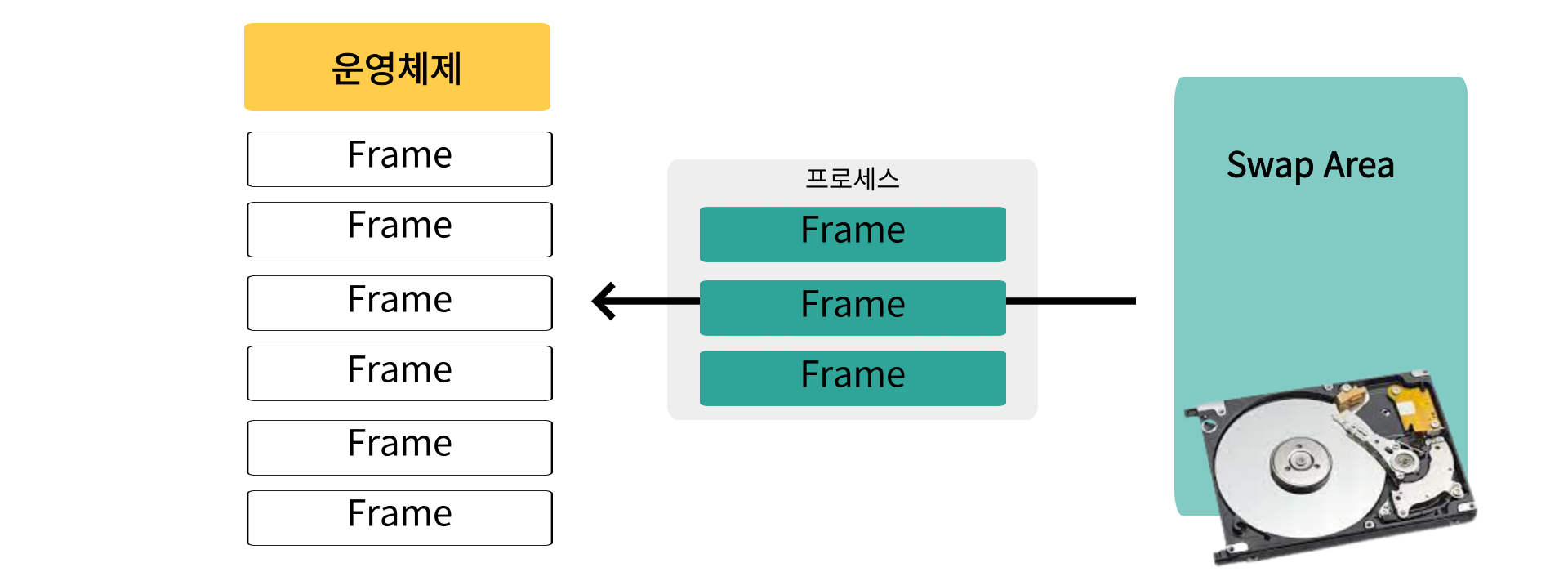
잘린 Page들 중 당장 프로그램이 실행되는데 필요한 Page만 놔두고 다시 메모리의 Swap Area로 이동한다
이런 Paging기법덕분에 메모리에 낭비되는 구멍은 거의 없어졌지만, 한 프로그램의 Page가 여기저기 분포한다는 점, Page들의 순서를 보장할 수 없다는 등의 문제점이 생겼다
이는 MMU의 계산도 복잡하게 만들었다
Page Table
이런 계산도 복잡해진 Page들을 조회하기 위해 논리/물리 주소 변화를 위한 별도의 Page Table을 사용한다
그래서 MMU레지스터의 이름과 역할이 아래와 같이 조금씩 달라졌다
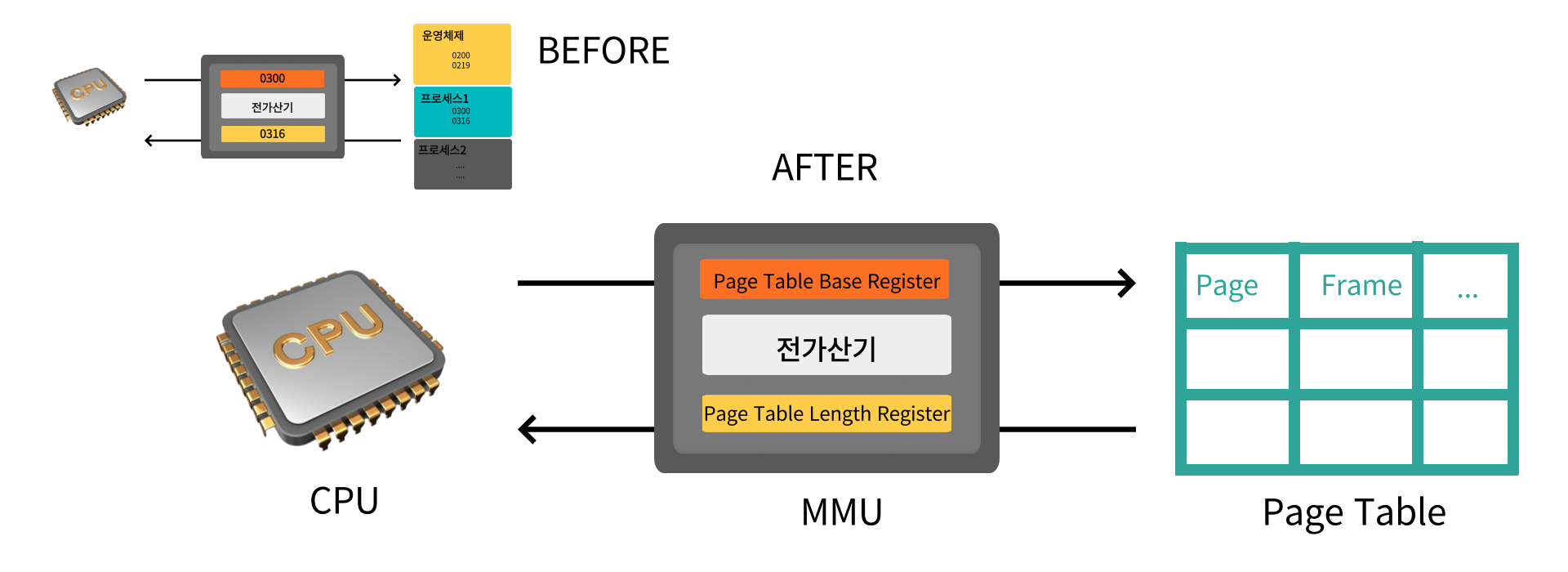
이전에 프로세스의 시작주소를 더해주던 base register는 page table의 시작 주소를 더하고
이전에 프로세스의 마지막 주소를 검증하던 limit register는 page table의 크기를 검증한다
이 Page Table의 행 개수 = 해당 프로그램을 일정한 간격으로 나눈 수이고 이 수는 100만개가 넘는 경우가 대다수이다
이런 백만개가 넘는 Page Table가 프로세스마다 한 개씩 존재하는데, 이걸 모두 CPU에 넣을 순 없다
하드디스크에 넣는 건 시간이 오래걸린다
그래서 Page Table은 메모리에 저장된다
메모리 공간을 알차게 사용하기 위해 페이징 기법을 적용, Page Table을 사용하게 됐는데,
Page Table이 메모리 공간을 차지하게 된다(크기도 제법크다)
그래서 최대한 메모리를 아끼기 위해 프로세스들 끼리 공통되게 사용하는 부분들을 신경쓰게 된다
그래서 자주쓰는 System.out과 같은 라이브러리를 메모리에 1개씩만올리고 공통적으로 사용하는 프로세스들이 나눠쓰게 하는 등 공용으로 사용하는 페이지인 Shared Page를 사용한다(Shared Page는 절대 변하면 안 되기 때문에 read-only를 부여)
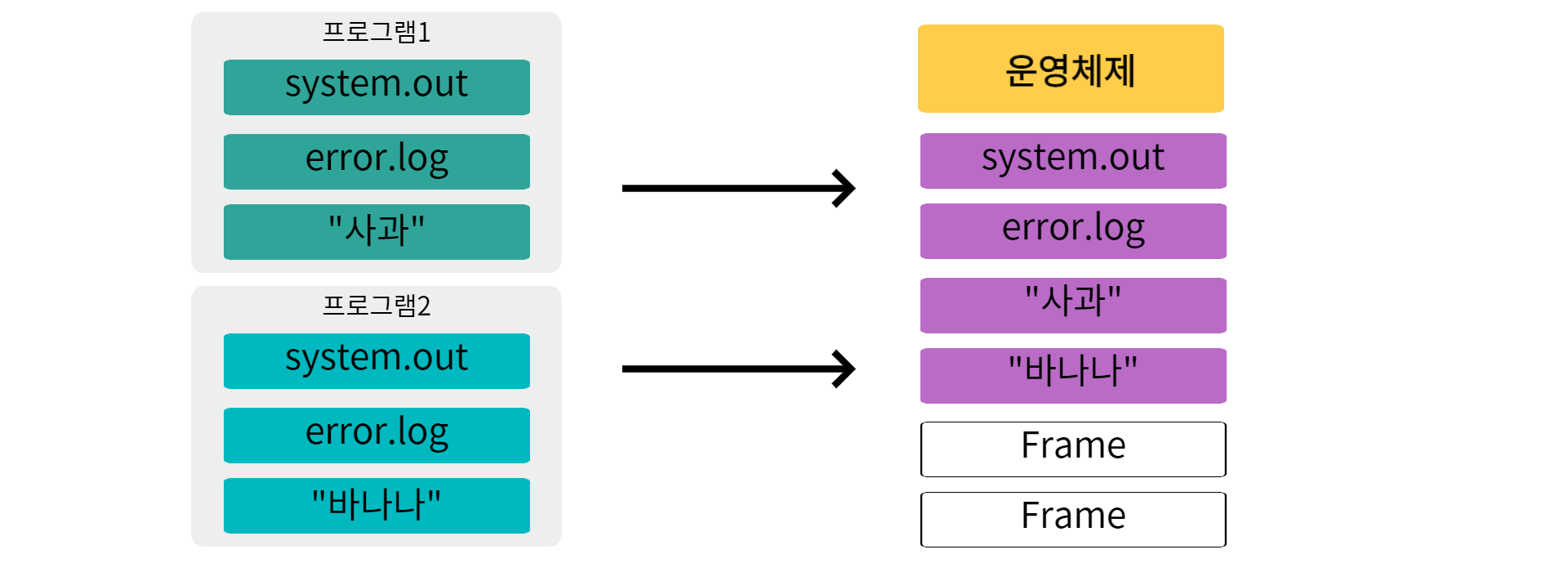
Page Table은 메모리에 위치, Page도 메모리도 위치한다
즉 CPU가 정보 요청을 한 번 할 때 메모리에 2번씩 접근해야만 하게된다
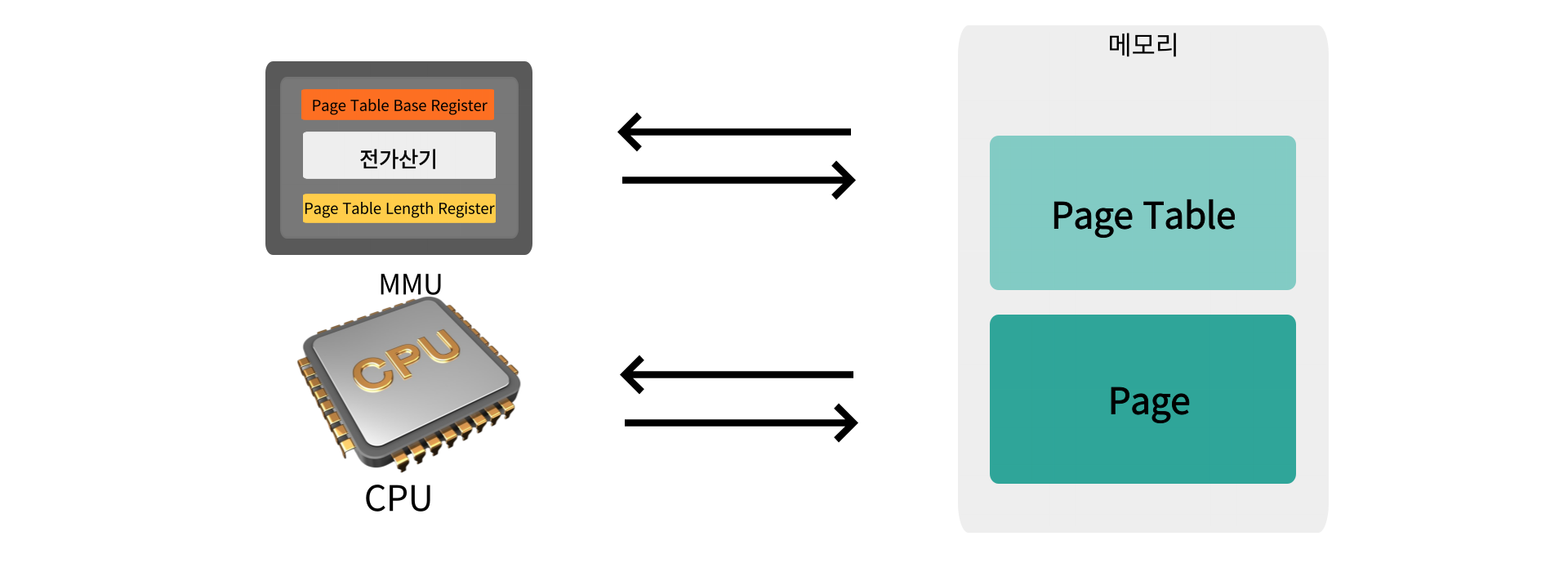
메모리 공간을 아끼기 위해 2배 느려진 컴퓨터를 사용해야 하게 된 것이다
TLB
그래서 하드웨어의 도움을 받아 TLB(Translation Look-aside Buffers)를 사용하게 된다
이 TLB는 병렬적으로 한꺼번에 자신이 가진 정보를 조회해 작고, 속도향상을 위해 존재한다
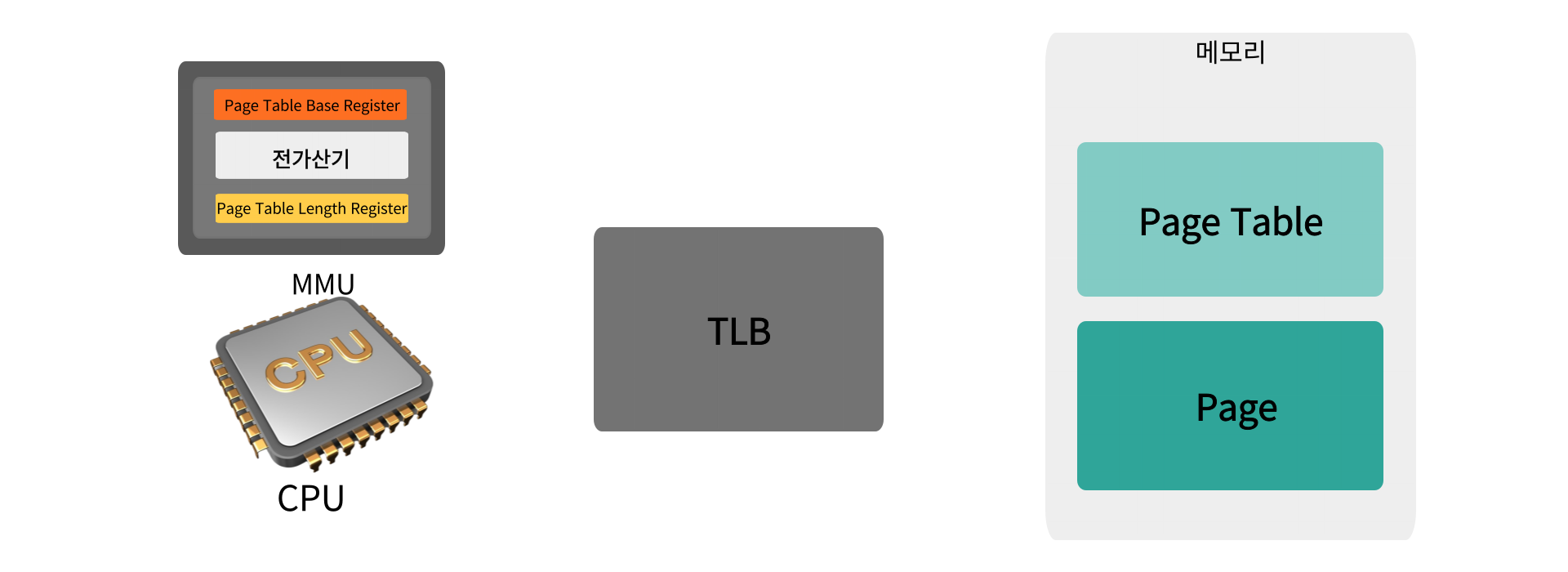
그래서 cpu가 논리 주소로 정보를 요청하면 Page Table에 접근하기 전 TLB부터 확인해서 매칭되는 주소가 있다면 Hit(TLB에 있는 Frame주소로 바로 변환, 메모리에서 가져옴)을 한다
즉 메모리에 1번 접근으로 끝낼 수 있다
TLB를 확인했을 때 매칭되는 주소가 없다면 Miss(Page Table을 참고해서 주소변환)을 하는데 이 때는 어쩔 수 없이 메모리에 2번 접근해야 한다
이 과정의 수행시간 차이가 별로 없을거라 생각할 수 있지만 대부분의 프로세스는 한 번 참조했던 곳을 다시 참조할 가능성이 크다 = TLB Hit확률이 대단히 높다
메모리가 관리되는 방법 정리
-
현대 메모리는 Paging을 베이스로 한 기법을 채택
-
하드디스크를 Swap area로 사용
-
MMU, TLB같은 하드웨어들의 지원을 받아 Page Table을 확인, 메모리를 참조
리눅스가 메모리를 관리하는 방법
리눅스 메모리 관리는 그러면 앞의 과정에서 어디서 나올까?
페이징 기법에서 숨겨진 기능을 하고 있었다
가상 메모리
- 가상 메모리로 사용자 프로세스 속이기
- I/O 장치 관리
CPU를 점유중인 프로세스는 자신이 온전한 메모리에 올라와있다고 생각하지만,
위에서도 봤듯 사실은 필요한 부분만 물리 메모리, 나머지는 SWAP공간에 저장되어있다
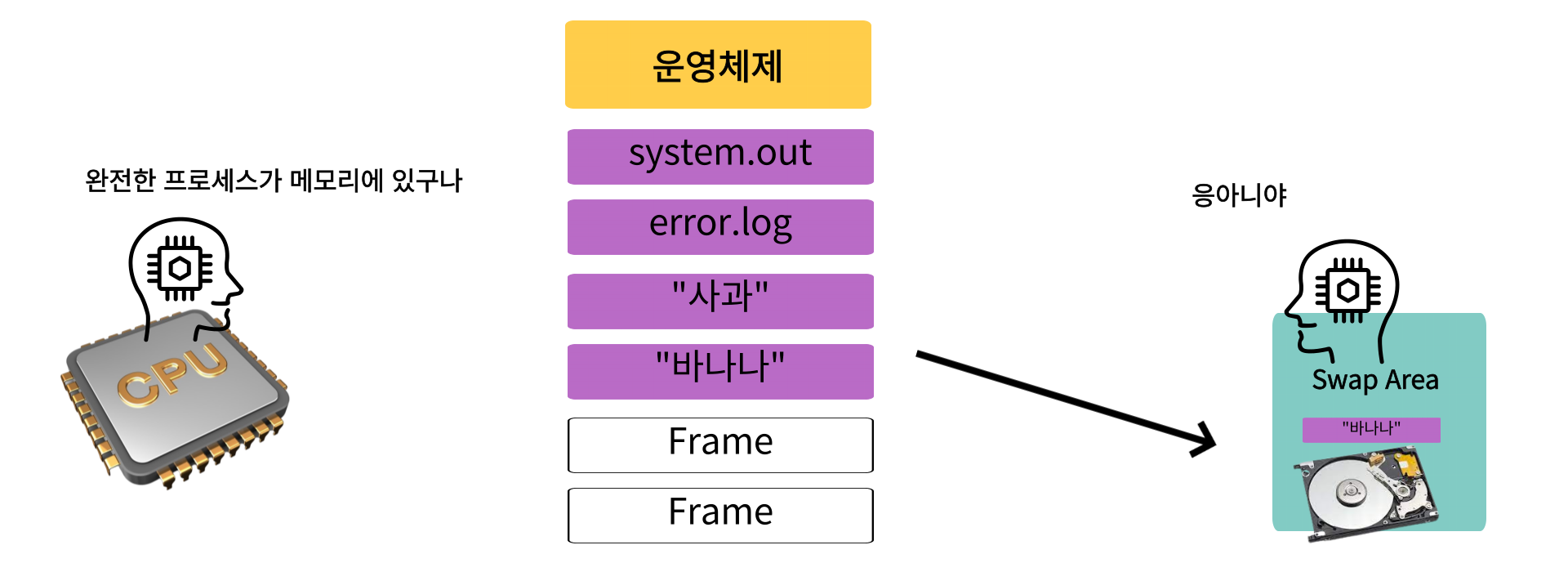
이런 물리메모리, SWAP공간을 합쳐 만들어낸 가짜 메모리를 가상 메모리(Virtual Memory)라고 부른다
주소를 변환하고, 메모리에서 Page를 찾아내는건 사용자 프로세스, 하드웨어에서 진행되지만 하드디스크 같은 입출력 장치를 건드리는 것은 운영체제의 관할이다
즉 SWAP공간에서 Page를 꺼내려면 운영체제의 도움이 필요하다
Page Fault
프로세스가 CPU를 점유, 작업을 하던 중 TLB와 메모리에 없는 Page를 요구하게 된다
이 때 메모리에 페이지가 없다는걸 알아차린 MMU가 프로세스를 일시정지시키고, 운영체제가 CPU를 점령하고, 프로세스가 멈춘 이유를 진단한다
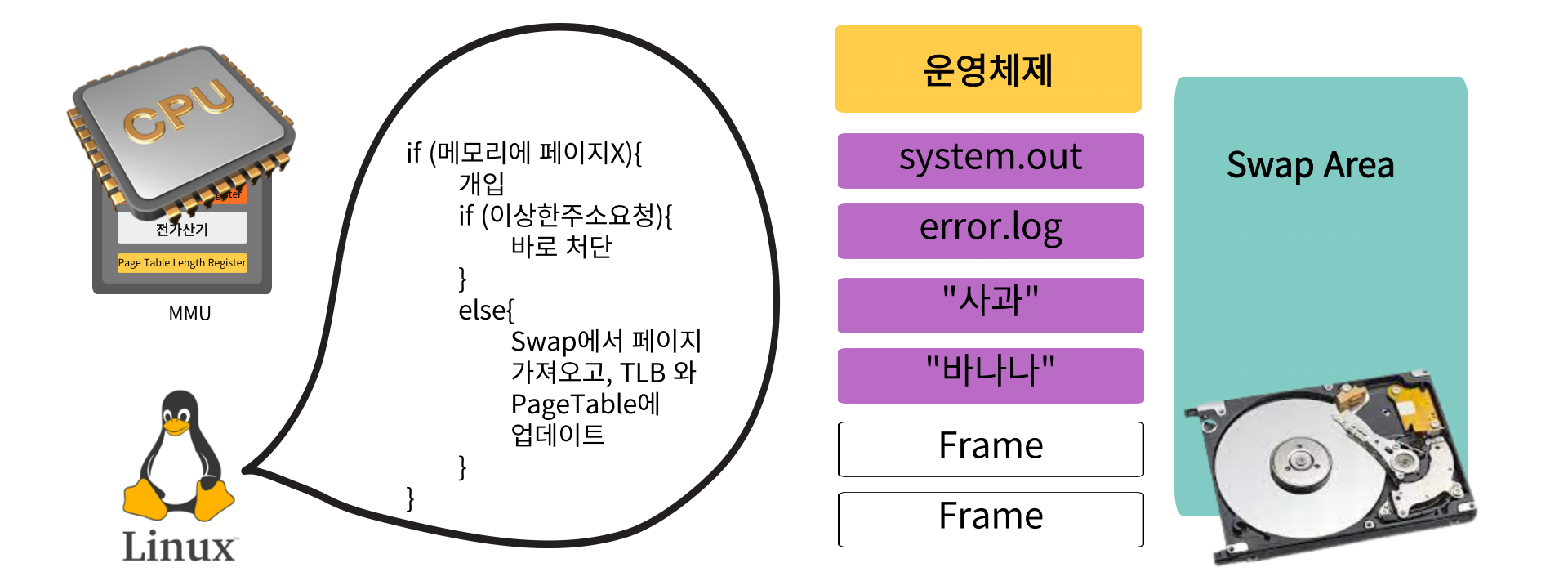
프로세스가 멈춘 이유가 이상한 주소를 요청한 것이라면 처단, 아니라면 운영체제가 하드디스크 Swap공간에서 페이지를 메모리로 가져오고, TLB에 주소를 등록, Page Table도 업데이트하게 된다
Page Fault가 일어나면 CPU가 다른 프로세스로 넘어갈 만큼 시간이 오래 걸리게 된다
그래서 Page Fault 확률이 곧 성능이 된다
하지만 위의 메모리가 관리되는 방법 에서 봤듯 중복된 내용의 참조가 많아서 fault확률이 낮다
Page replacement
Page Fault때문에 SWAP공간에서 페이지를 가져오다가 물리 메모리의 frame이 가득차면?
기존 메모리의 frame을 차지한 page중 하나를 쫓아야 하고, 이 행위를 Page replacement라고 한다
어떤 페이지를 replacement할지는 운영체젝가 결정한다
페이지를 버리는 알고리즘 중 LRU, 마지막으로 참조된 것 을 고르는 것이 가장 적절하지만 운영체제는 이미 물리 메모리에 있었고, Page Fault를 회피한 page들에 대한 정보는 알 수 없고 자신이 Page Fault에 참여한 기억만 있다(page fault가 일어나지 않을 땐 잠들어있는다zzz)
대신 Clock algorithm을 사용한다
Clock algorithm
Clock algorithm이란 메모리에 올라와있는 모든 페이지마다 한 개의 reference bit를 갖게 하는 것이다
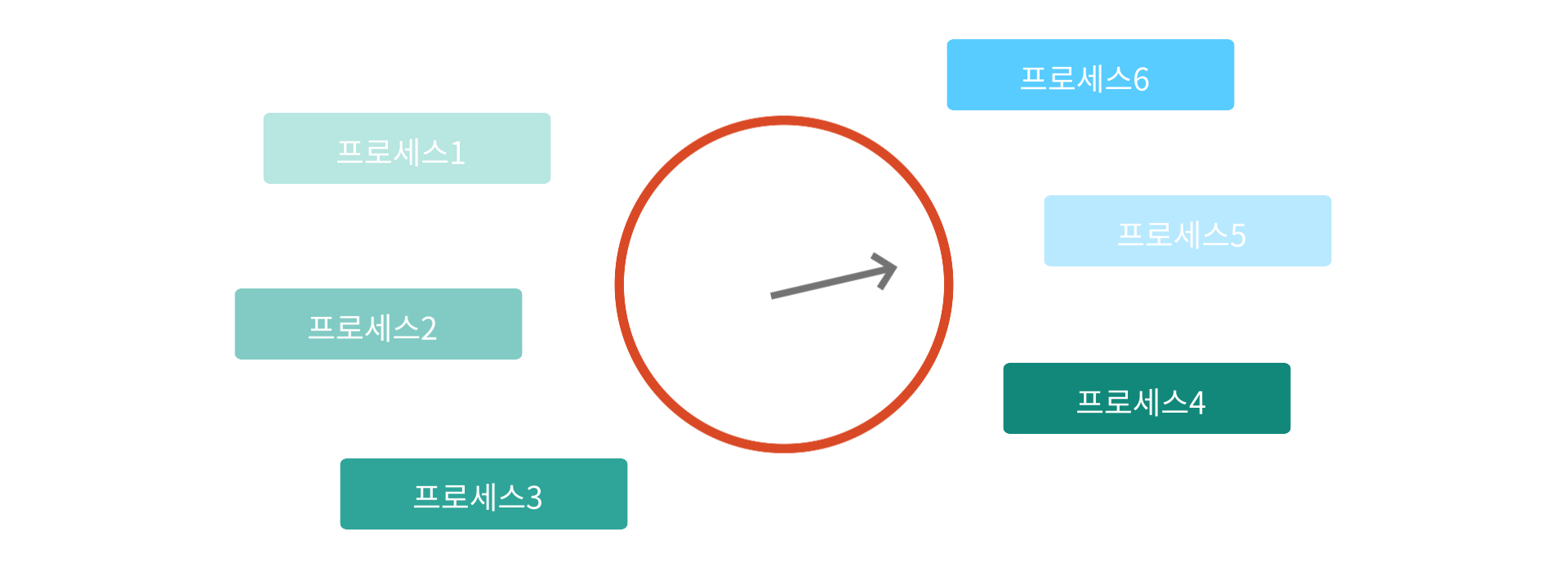
초기의 reference bit은 모두 0이다가, CPU를 점유중인 프로세스로부터 참조되면 bit가 1로 올라오게 된다
이 때 Page replacement가 실행될 경우 한쪽 방향으로 Page들을 참조하기 시작한다
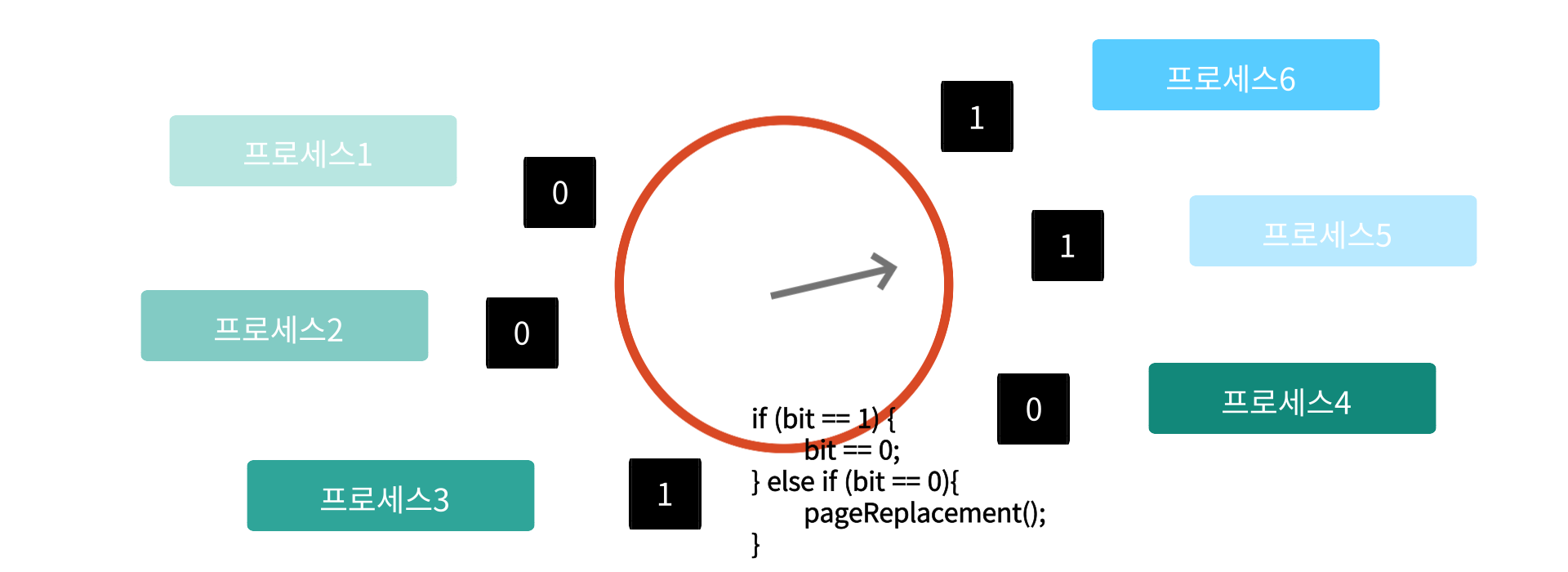
참조하는 과정에서 위와같이 1bit를 만나면 0bit로 내리고, 0bit를 만나면 page replacement 대상이다
이러한 Clock algorithm은 가장 오래동안 참조되지 않은 페이지는 못 잡아내지만, 가장 최근의 페이지는 피할 수 있는 LRU와 근사한 알고리즘이 된다
그리고 이 reference bit은 또 Page table에 추가가 된다
즉, Clock algorithm은 운영체제가 하드웨어의 도움을 받는 알고리즘 이다
하지만 이렇게 clock algorithm으로 내쫓을 Page를 정해도 함부로 못 쫓아낸다
CPU를 점유한 프로그램으로부터 참조되는 동안 변경사항이 있었는지 확인해야한다
변경사항이 없으면 그냥 쫓고, 변경사항이 있다면 하드디스크에도 변경된 내용을 반영한다
그리고 이는 Page table에 하나의 속성이 더 추가된다
이렇게 하드디스크에 변경사항을 기록, Page Table에 기록하는 것 모두 운영체게가 수행한다
Thrashing
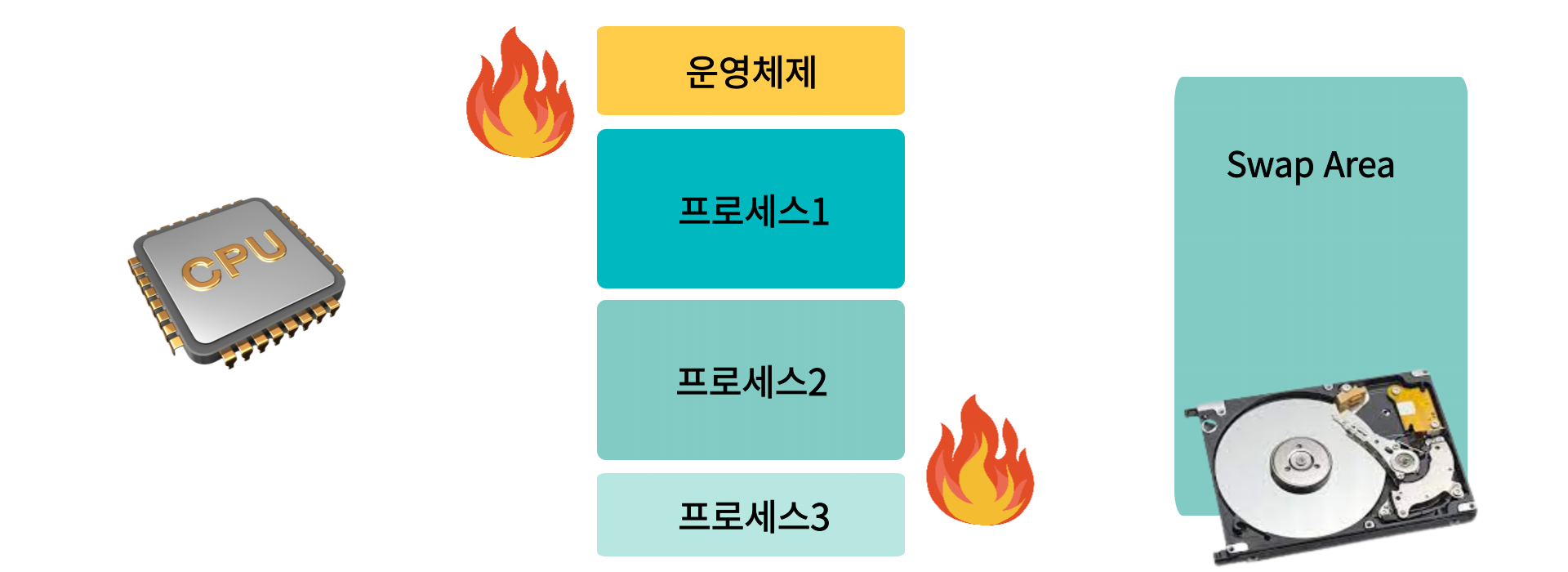
이렇게 Page Fault, Page replcement를 반복하며, 다양한 프로그램들이 메모리에 올라오고, 메모리의 여유공간은 줄어들고, CPU가동시간이 올라가며 자원을 최대한 활용하는 상태에 도달한다
이는 CPU를 최대로 활용하고 있다고 생각해서 긍정적일 수 있지만,
조금 있으면 CPU사용률은 뚝 떨어진다
그 이유는 메모리에 프로세스가 많아질수록 프로세스당 물리메모리에서 사용할 수 있는 frame의 개수가 줄어들고 page가 메모리에 적게 올라온 프로세스는 명령을 조금만 수행한 후 page fault에 걸려 replacement를 진행한다
그 후 다른 프로세스도 CPU를 넘겨받지만 page fault에 걸리고 replacement를 진행한다
즉 이렇게 되면 모든 프로세스들이 page교체에만 바쁘고 CPU는 할 일이 없어서 쉰다
게다가 CPU가 놀고있는 모습을 본 운영체제는 더 많은 프로세스를 메모리에 올린다
이런 악순환이 반복되는 현상을 Thrashing이라 부른다
Thrashing을 해소하는 방법
Thrashing을 해결하기 위해 Working-set알고리즘과 Page Fault Frequency알고리즘을 사용한다
- Working-set이란
알고리즘이 대부분의 프로세스가 일정한 페이지만 집중적으로 참조하는 성격을 이용해 특정 시간동안 참조되는 페이지의 개수를 파악하고 그 페이지의 개수만큼 Frame이 확보되면 그 때 Page를 메모리에 올리는 알고리즘이다
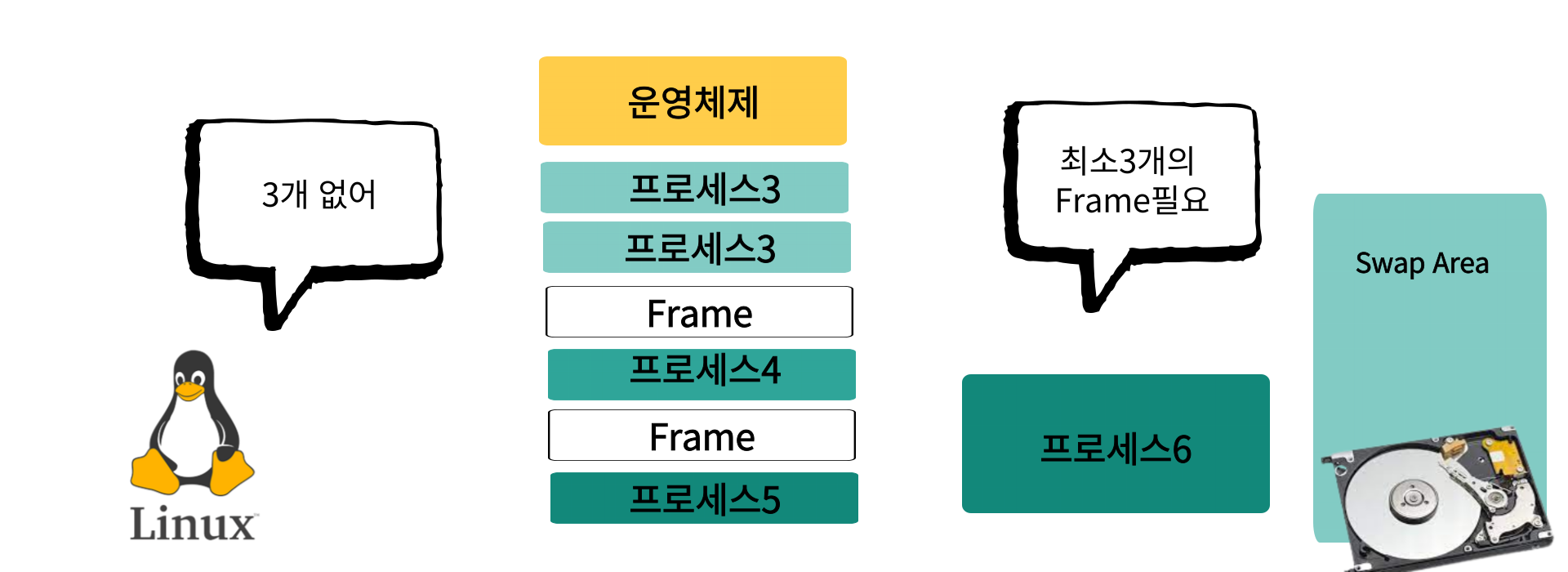
만일 페이지가 3개 필요할 때 Frame을 2개밖에 못준다면, 2개 올리지 않고 Swap Area에서 기다린다
Frame이 3개 확보되면 그 때 올리게 되고 frame이 가득차면 replacement활동을 하는데 프로세스마다의 working-set단위로 프로세스를 쫓아낸다
- PFF(Page Fault Frequency)알고리즘이란
PFF는 Page Fault퍼센트에 상한과 하한을 둔다, 상한선을 넘으면 지급하는 frame의 개수를 늘리고, 하한을 넘으면 줄인다

메모리 고갈 상황과 CPU사용률을 계속 체크하는 이유
현구막님의 뇌피셜이라 밝혔다
메모리가 고갈되면?
위의 리눅스가 메모리를 관리하는 방법에서 나온 내용과 같이
- 프로세스들의 Swap이 활발해져서 CPU사용률 하락
- 운영체제가 프로세스 추가, 쓰레싱 발생
- 쓰레싱이 해소되지 않으면 Out of Memory 상태로 판다
- 중요도가 낮은 프로세스를 찾아 강제 종료(상용중인 서버가 강제종료될 수도 있다)

CPU사용률을 계속해서 체크하는 이유는?
- 특정 시점만 체크한다면 CPU사용률이 높아보일 수 있음
- 연속 체크시 CPU 사용률이 급격하게 덜어지는 구간 발견 가능성
- 메모리 적재량을 함께 체크해서 쓰레싱 유무 확인
- 추가적인 서버자원을 배치하는 등 해결방안 마련
정리하며 더 궁금한 점, 느낀점 🙃
-
거의 모든 내용들이 새롭게 알게되는 개념들이여서 영상정리하는데 조금 오래걸린거 같다, 임베디드 소프트웨어 학과를 진학중인 나에게는 더 유익한 내용이 된거같다
-
애초에 나는 운영체제가 하는 일이 정확히 무었인지 몰랐어서 메모리 관리를 한다는 생각을 한 적이 없었는데, 이번 정리로 운영체제가 하는 일이 또 무었이 있는지 궁금해졌다
