MNIST란❓
인공지능 연구의 권위자 LeCun 교수가 만든, 손으로 쓴 숫자로 구성된 대규모 데이터베이스인데, 처음 코딩 입문할 때 hello world 예제와 같은 느낌이에요!
MNIST는 총 60,000개의 트레이닝 데이터와 10,000개의 테스트 데이터로 구성되어 있으며,
- 트레이닝 데이터: 모델 학습에 사용
- 테스트 데이터: 모델의 성능 검증에 사용
되고 있습니다
특징으로는 28x28 크기의 흑백 이미지로 구성된 데이터셋이며, 딥러닝 모델의 분류 문제를 연습하기에 최적화된 데이터입니다!
1. MNIST 데이터셋 로드 및 시각화
import tensorflow as tf
import keras
from keras.datasets import mnist
(tr_x, tr_y), (tt_x, tt_y) = mnist.load_data()
import matplotlib.pyplot as plt
plt.imshow(tr_x[0])
* 컬러로 나오는 이유는 imshow는 기본적으로 데이터에 색상을 매핑하는 **컬러맵(colormap)**을 사용하기 때문에, plt.imshow(tr_x[0], cmap='gray') 으로 하면 흑백으로 결과가 출력됩니다, 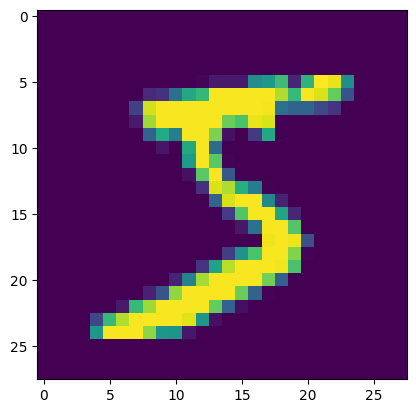
- 설명
- MNIST 데이터셋: 손글씨 숫자(0~9)의 이미지와 레이블로 구성된 데이터셋.
- tr_x[0]: 첫 번째 훈련 데이터(이미지)를 시각화.
- 결과: 손글씨 숫자 이미지가 화면에 출력
1-1. 데이터 형태 확인

1. tr_x.shape을 통해 28x28 크기의 이미지 60,000개를 알 수 있음
2. tr_y[0]: 라벨 값은 0~9의 정수 중 하나. (첫 번째 이미지 → 5)
3. 28*28 = 784: 이미지를 평탄화(flatten)하여 1차원으로 변환 시 사용 -> 이유: 이미지는 28x28 형태로 제공되지만, 신경망에 입력하기 위해 1차원 배열로 변환한다!
📌 Flatten이란?
- Flatten은 다차원 데이터를 1차원으로 변환하는 과정
- 쉽게 말해, 행렬(2D)이나 텐서(3D 이상)를 하나의 긴 배열(1D)로 펼치는 것임
📌 왜 Flatten이 필요한가?
- 딥러닝 모델(특히 완전 연결층, Fully Connected Layer)은 1차원 벡터 형태의 데이터를 입력으로 받기 때문에, 이미지(ex.28x28형태)를 모델에 넣기 전에 1차원 형태(784)로 변환해야 함!
2. MNIST 데이터셋을 활용한 간단한 신경망 구현 및 학습
다음은 Keras를 사용해 MNIST 데이터셋에 대해 간단한 신경망 모델을 구축, 학습, 평가하는 실습 코드를 리뷰하고 정리해볼게요!
2-1. MNIST 데이터셋 로드 및 전처리
from keras.datasets import mnist
(tr_x, tr_y), (tt_x, tt_y) = mnist.load_data()
s_tr_x = tr_x.reshape(-1, 784) # 입력 이미지를 28x28에서 784(1차원 벡터)로 변환
s_tt_x = tt_x.reshape(-1, 784)-
데이터셋 로드: MNIST 데이터셋을 학습용(tr_x, tr_y)과 테스트용(tt_x, tt_y)으로 불러옵니다
-
데이터 형태 변환: 입력 데이터를 (28x28) 형태에서 (784,)의 1차원 벡터로 변환하여 신경망에 입력 가능하게 만듭니다
2-2. 신경망 모델 구성
from keras import Sequential
from keras.layers import Dense
m = Sequential()
m.add(Dense(100, input_shape=(784,), activation='sigmoid'))
m.add(Dense(10, activation='softmax'))- 모델 정의
- Sequential 객체를 생성하여 계층(layer)을 순차적으로 쌓기
- 첫 번째 은닉층
- Dense(100)으로 100개의 뉴런을 가진 은닉층 추가
- 입력 크기는 input_shape=(784,)로 지정
- 활성화 함수로 sigmoid 사용
- 출력층
- Dense(10)으로 10개의 뉴런을 가진 출력층 추가
- 활성화 함수로 softmax를 사용하여 각 클래스(숫자 0~9)의 확률을 계산
2-3. 모델 요약 확인
m.summary()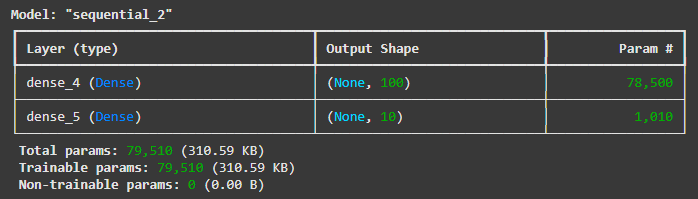
- 신경망의 레이어 구성 및 파라미터 개수를 요약해서 출력
- Dense(100): 파라미터 수 = (784+1) 100 = 78,500
- Dense(10): 파라미터 수 = (100+1) 10 = 1,010
- 총 학습 가능한 파라미터: 79,510
2-4. 컴파일
from keras.losses import sparse_categorical_crossentropy
from keras.optimizers import SGD
m.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics=['acc'])- Optimizer: 경사하강법(SGD) 사용
- Loss Function: sparse_categorical_crossentropy로 다중 클래스 분류 손실 계산
- Metrics: 학습 중 정확도(acc)를 측정
2-5. 모델
m.fit(s_tr_x, tr_y, epochs=10)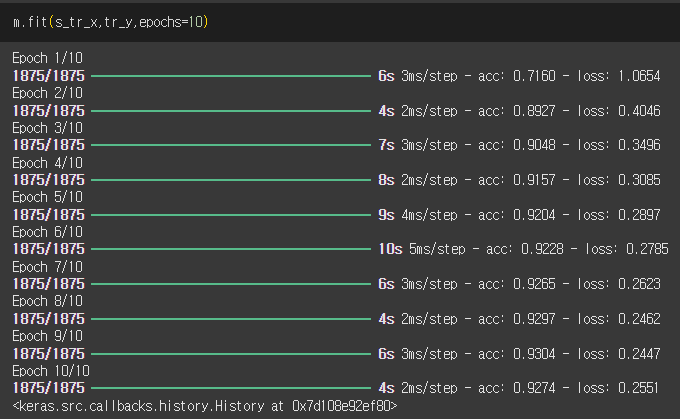
- 학습 데이터를 사용해 10번(epochs=10) 학습을 진행함
- 각 epoch마다 손실(loss)과 정확도(acc)가 출력됨
2-6. 모델 평가
m.evaluate(s_tt_x, tt_y)
- 테스트 데이터로 모델 성능을 평가함
- 출력 결과: [손실값, 정확도]
- 손실값: 0.2423
- 정확도: 0.9319 (약 93.2%)
2-7. 결과 요약
- 학습 데이터 정확도: 약 92.7%
- 테스트 데이터 정확도: 약 93.2%
3. 코드 주요 단계 요약
-
MNIST 데이터셋 로드 및 전처리
- 28x28 이미지를 784 크기의 벡터로 변환.
-
신경망 모델 구성
- 100개의 뉴런을 가진 은닉층(
sigmoid활성화 함수). - 10개의 클래스를 가진 출력층(
softmax활성화 함수).
- 100개의 뉴런을 가진 은닉층(
-
모델 컴파일
SGD옵티마이저와sparse_categorical_crossentropy손실 함수 사용.
-
모델 학습 및 평가
- 학습 데이터 정확도: 92.7%
- 테스트 데이터 정확도: 93.2%

결국 난 잘될사람🍀 아자아자🥔