AI 비전 컴퓨팅
1.인공지능, 머신러닝과 딥러닝 차이
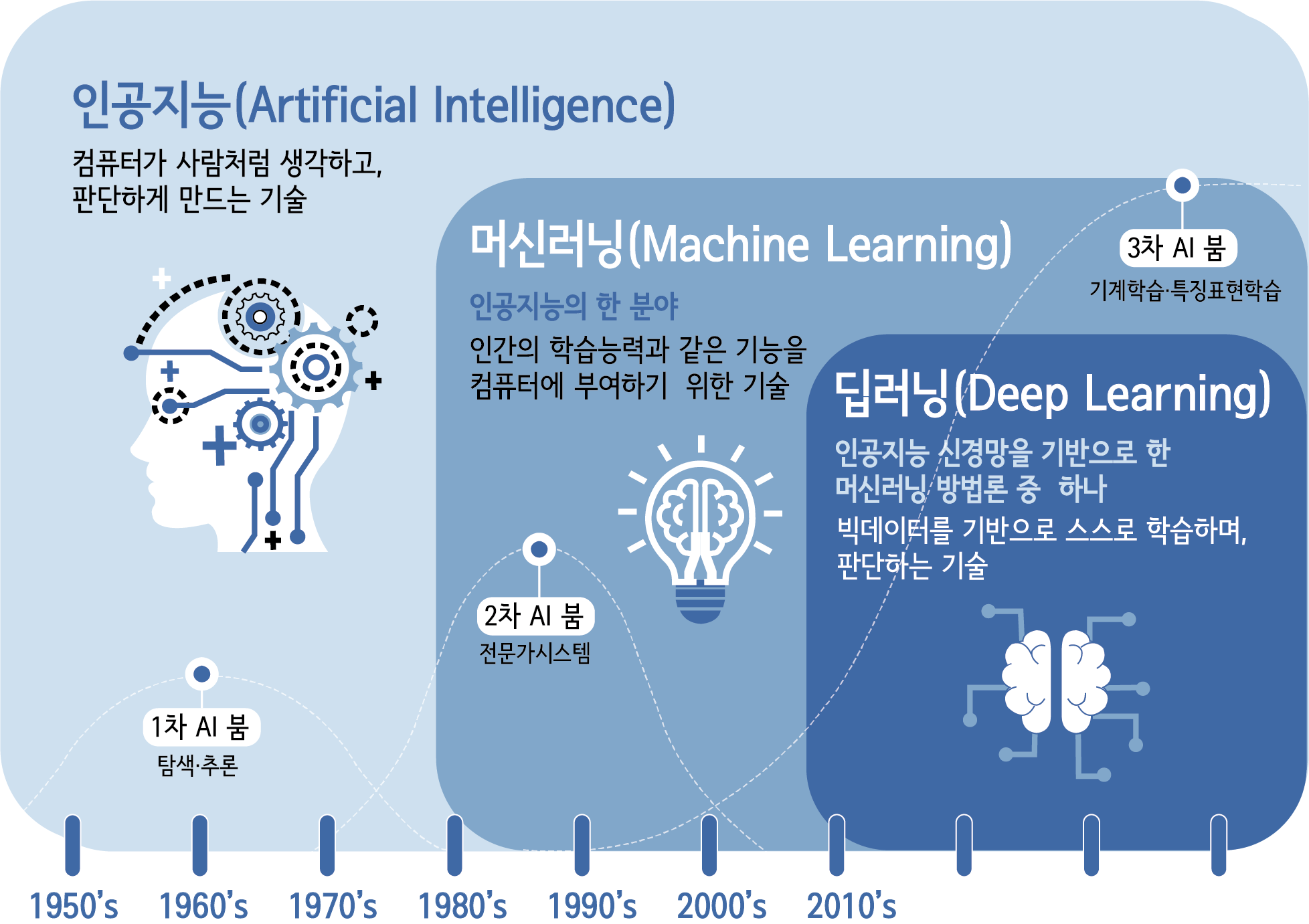
인간의 지능을 모방하여 사람이 하는 일을 컴퓨터(기계)가 할 수 있도록 하는 기술 -> 머신러닝과 딥러닝이 있음관계를 따지자면 인공지능> 머신러닝> 딥러닝 => 머신러닝과 딥러닝 모두 학습 모델을 제공하여 데이터를 분류할 수 있는 기술인데, 둘의 접근 방식에는 어떤 차
2.인공지능, 머신러닝 학습 과정
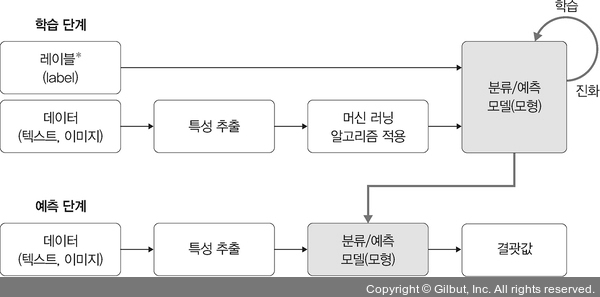
머신러닝은 학습 단계(learning)와 예측 단계(prediction)으로 나뉨.🤔 개인적으로 위에 표를 보면서 궁금했던 건, (1) 학습단계에서 분류/ 예측 모델이 예측 단계에서 어떻게 쓰이는건지? ➡️ 학습 단계에서 만들어진 분류/예측 모델은 데이터와 라벨(정답
3.인공지능, 딥러닝에 대해

이전 포스팅에서 머신러닝은 분류를 위한 특징 추출을 주로 사람이 직접 정의(예: 색상, 모양, 크기 등)하며, 반면에 딥러닝은 모델이 스스로 특징을 학습한다는 점에서 차이가 있다고 언급했다!1\. 원본 이미지 → 특징 추출: 딥러닝 모델은 처음에는 원본 이미지를 입력으
4.이미지 처리

영상(이미지): 밝기와 색상이 다른 화소(픽셀)로 구성된 데이터.화소 처리: 이미지를 구성하는 화소들을 수학적으로 조작하는 작업입력된 영상을 특정 목적(예: 품질 향상, 정보 추출)을 위해 처리.저수준 영상 처리: 잡음 제거처럼 결과가 여전히 이미지인 경우.고수준 영상
5.컴퓨터비전 개념, 주요 작업
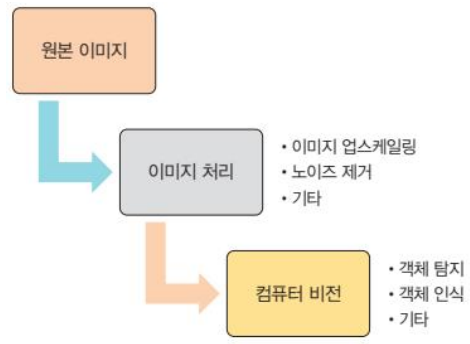
컴퓨터 비전은 컴퓨터가 사람처럼 이미지를 보고 이해하도록 만드는 기술즉, 디지털 이미지나 동영상에서 유용한 정보를 추출하고, 이를 바탕으로 사물을 인식하거나 행동을 해석하는 것을 목표로 한다이미지에서 가장자리, 모서리, 텍스처와 같은 고유한 속성을 뽑아낸다이러한 특징은
6.MNIST 데이터셋 로드 및 시각화 (기본 예제)
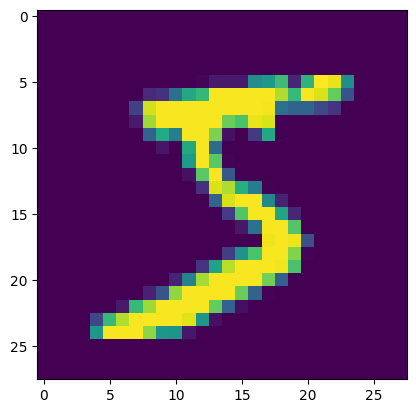
인공지능 연구의 권위자 LeCun 교수가 만든, 손으로 쓴 숫자로 구성된 대규모 데이터베이스인데, 처음 코딩 입문할 때 hello world 예제와 같은 느낌이에요!MNIST는 총 60,000개의 트레이닝 데이터와 10,000개의 테스트 데이터로 구성되어 있으며,트레이
7.Tensor의 구조, 전치, 차원 변경

일반적인 파이썬에서 제공하는 기본 리스트는 기계 학습에 적합하지 않으며, 연산 속도도 중요하기 때문에 기본 리스트 대신 Numpy를 사용하게 된다!기본 파이썬 리스트와 Numpy 차이점을 아래 사이트에서 잘 정리해놨다 ㅎㅅㅎ (모든걸 이 블로그에 담기엔 내용도 방대하고
8.CNN 구조 (Convoultional layer, Pooling layer, Fully-connected layer)
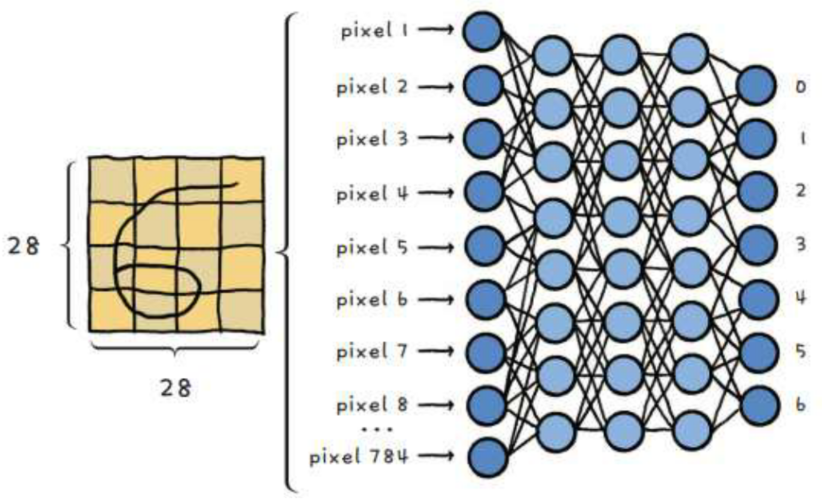
만약 fully connected layer을 이용해 MNIST 데이터셋을 분류하는 모델을 만들 때, 28 x 28 형태의 2차원 이미지를 784 크기의 1차원 벡터로 변환해서 모델에 입력 해야 한다\-> 이 때, 2차원 이미지를 1차원으로 펼치면 '6'이라는 형태가
9.합성곱 연산 심화: Stride & Zero Padding

stride란 커널(필터)이 입력 데이터를 얼마나 건너뛰면서 이동하는지를 정하는 값이다. 예를 들어, stride=1: 커널이 한 칸씩 이동 / stride=2: 커널이 두 칸씩 이동❗❗위에 예시는 stride가 2일 때이고, 파란색 영역(ROI)를 보면 커널이 한 번
10.Max Pooling & Average Pooling 함수 구현
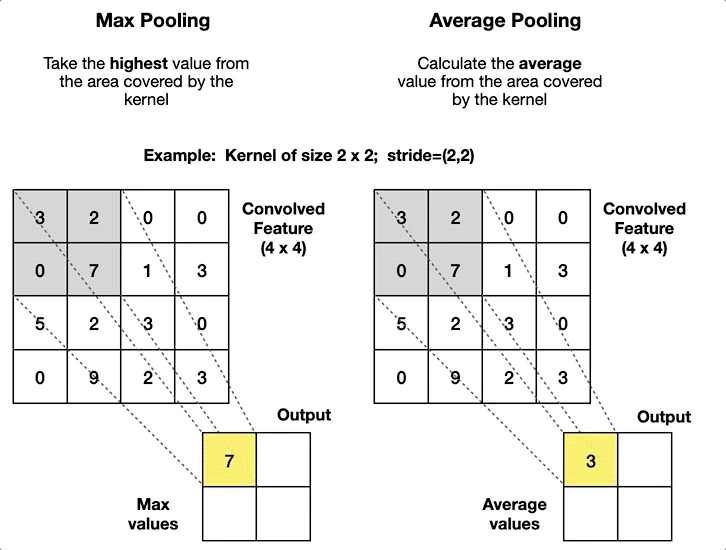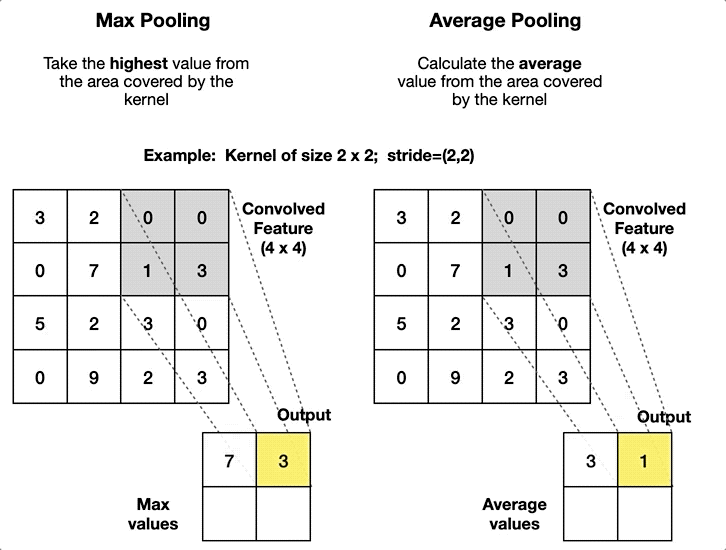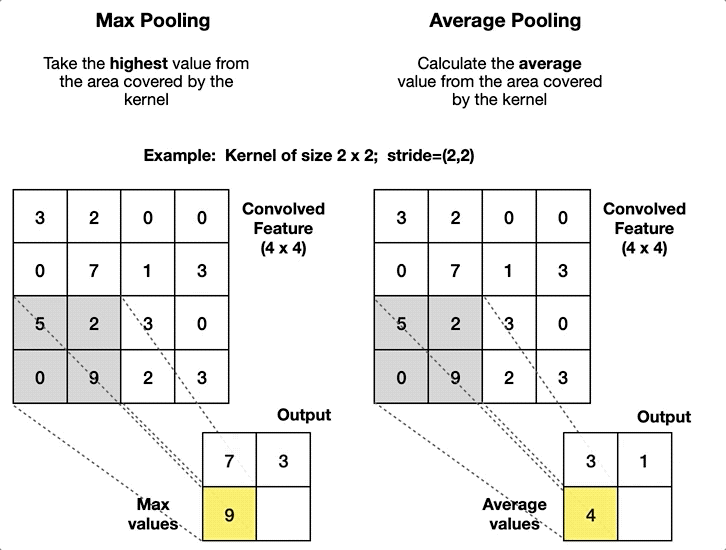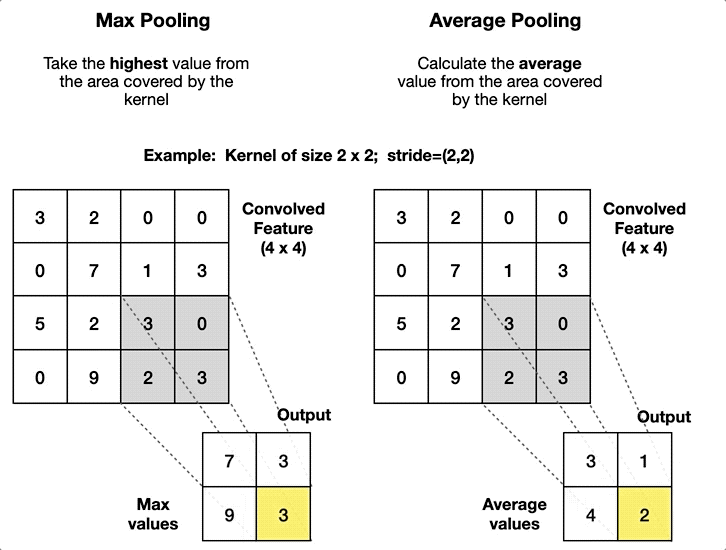
Convolutional layer에서 추출된 feature map의 크기가 너무 커지게 되면 연산량이 급증하여 학습 자체가 불가능해질 수 있기 때문에, pooling layer (풀링층)에서 feature map의 크기를 줄인다보통 stride = 2, filter(
11.CNN 성능 최적화 예제 - 오버피팅(과적합), 배치정규화(Sigmoid와 ReLu 차이)
👉 MNIST 데이터 로드tr_x, tr_y: 훈련 데이터(이미지, 레이블)tt_x, tt_y: 테스트 데이터(이미지, 레이블)👉 이미지 정규화 및 형상 변경원래 MNIST 데이터는 (60000, 28, 28) 형식이지만 CNN을 쓰려면 (배치, 높이, 너비, 채널
12.주요 CNN 알고리즘 구현(1): LeNet, AlexNet, VGGNet
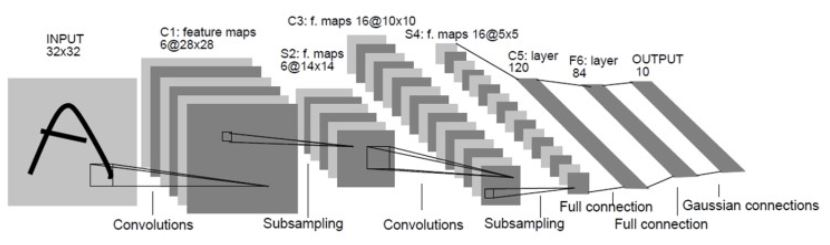
목표: 숫자 필기체(MNIST) 인식입력 크기: 32×32 (MNIST 이미지를 32×32로 확장해서 사용)구성: Conv → Pool → Conv → Pool → FC → FC → Output특징아주 작은 구조7개 레이어(Convolution, Subsampling,
13.주요 CNN 알고리즘 구현(2): AlexNet
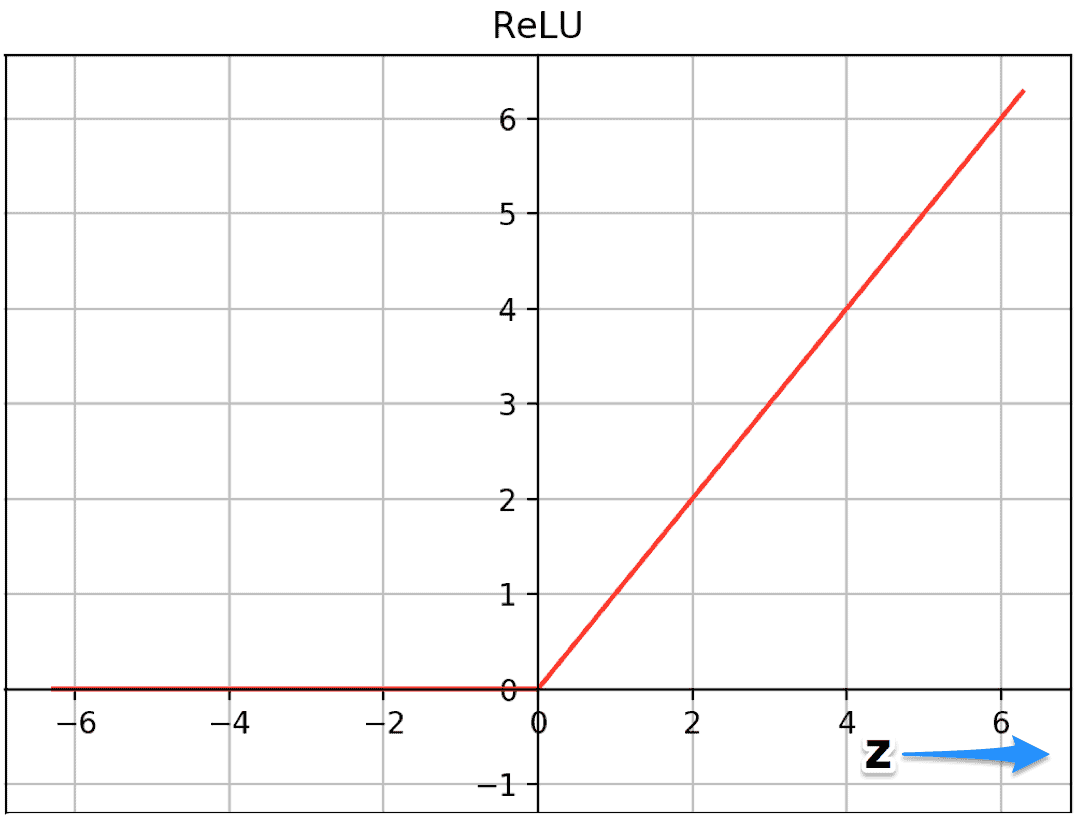
목표: 고해상도 이미지 분류 (ImageNet 데이터셋, 1000종 분류)입력 크기: 227×227×3 (RGB 이미지)구성:: Conv (ReLU 포함) → Pool → Conv... → FC → FC → FC특징ReLU 활성화 함수 사용 (Sigmoid보다 빠르고