BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
Paper Review
목록 보기
4/4

Background
기존 VLP 연구 방법 및 한계점
- Vision-Language Pre-training(VLP) 연구에서는 모델의 사이즈를 키우면서 성능을 올려왔음
- 하지만, 이는 pre-train 과정에서 방대한 양의 computational cost를 요구함
- large-scale model과 많은 양의 데이터셋을 사용
해결방법
- VLP 연구는 vision model과 language model을 각각 사용하여 이 들의 output을 잘 align하여 이미지 표현과 텍스트 표현이 잘 연결된 지식을 학습하는 것에 목표를 두고 있음
- 그래서 새로운 모델을 학습하는 것이 아니라, 기존에 성능이 좋은 vision/language model을 가져다가 이 둘을 잘 연결하여 align되도록 하고자 함 → Q-Former
BLIP2
Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
: 이미 존재하는 강력한 모델들의 지식을 Bootstrapping
(모델이 스스로 만든 결과물을 다시 자신의 학습 데이터로 사용하여, 스스로의 성능을 끌어올리는 과정)
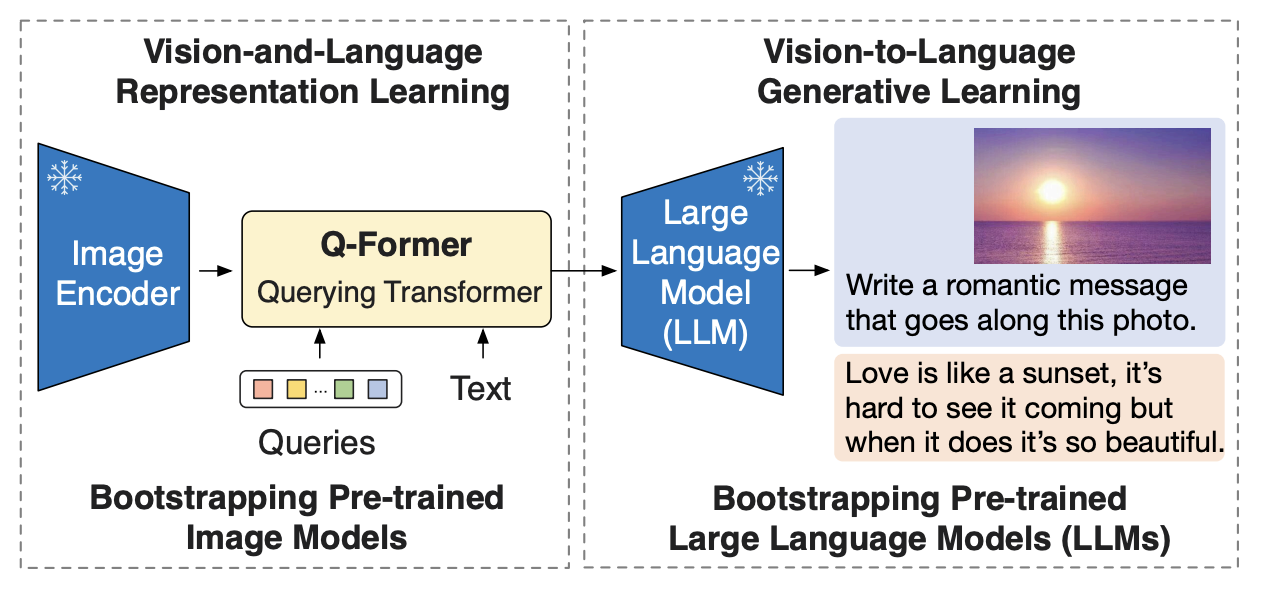
Q-Former architecture & pre-train

- 두개의 transformer submodule로 구성됨 → image transformer / text transformer
- 두 개의 module은 같은 self-attention layer를 공유함
- 파라미터는 공유하지만, 입력을 어떻게 볼지는 attention mask로 조절하게 됨
- 학습 중, 입력으로는 항상 learnable queries와 input text가 함께 들어가게 됨
- 하지만, 공유하고 있는 self-attention layer에서 특정 정보만 쓰도록 마스킹을 함
Q-Former(Querying Transformer) Pre-train
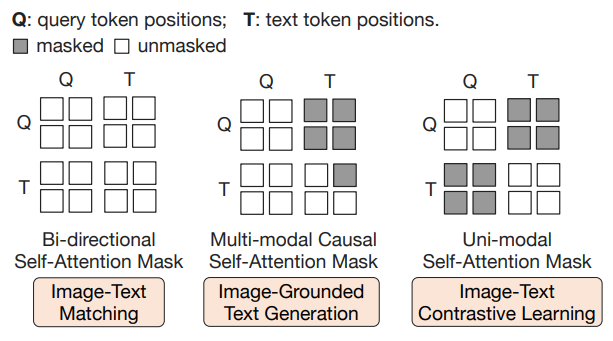
Pre-train step에 따른 shared self-attention masking 방법
- Step1: Vision-Language Representation Learning
- 이미 학습된 vision model로부터 representation을 뽑아냄
- Step 2: Vision-to-Language Generative Learning
- Q-Former가 뽑아낸 시각 정보(텍스트와 이미지가 align됨) frozen LLM이 이해할 수 있는 텍스트 형태로 넘겨줌
- Q-Former의 출력을 LLM의 입력 차원에 맞게 projection한 뒤, LLM에게 넘겨줌
논문 정보
- Conference: ICML-2023
- Link: https://arxiv.org/abs/2301.12597

비전공자 석사 출신 AI Engineer 취준생(노션에서 벨로그로 이사중 .. 🚗)