BLIP: Bootstrapped Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Paper Review
목록 보기
3/4

Background
기존 방법의 한계
(1) Model perspective:
- 기존 방법: encoder-based model 혹은 encoder-decoder를 사용함
- 한계점: 하지만, encoder-based model의 경우 text generation에 곧바로 활용하기 어렵고 encoder-decoder는 image-text retrieval task에 사용하기 어려움
(2) Data perspective:
- 기존 방법: 많은 양의 (image, text) 데이터를 web으로 부터 얻어 모델을 pre-train 함
- 헌계점: noisy한 web text가 vision-language learning에 도움이 되지 않음
제안 방법: BLIP
Bootstrapping Language-Image Pre-training for unified vision-language understanding and generation
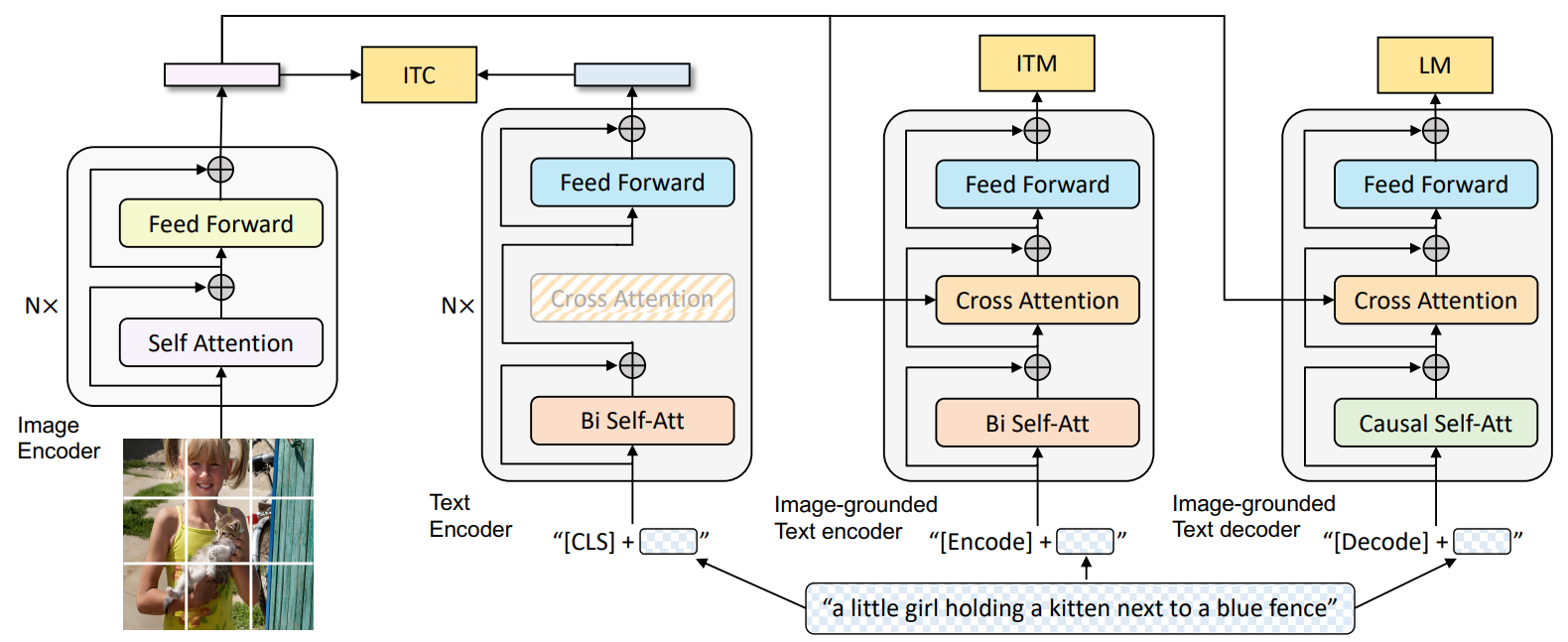
(1) Multimodal mixture of Encoder-Decoder (MED)
(1)-1 Model architecture
- 통합된 하나의 vision-language model로, 다음 세가지 기능 중 한 가지 동작을 함
- Unimodal encoder: 텍스트/이미지를 입력으로 받아 텍스트에 대한 임베딩 생성
- Image-grounded text encoder: image와 텍스트 사이의 관계를 고려한 텍스트 임베딩 생성
- Image-grounded text decoder: image의 특징을 참조하여 이미지에 대한 텍스트를 생성
Unimodal encoder.
- Encoder
- Image encoder: ViT
- Text encoder: BERT (Self-attention + FFN)
- 각 인코더의 입력으로 들어가는 시퀀스에
[CLS]토큰을 붙임- 해당 special token은 인코더를 거쳐 이미지/텍스트의 전체적인 정보를 담게 됨
Image-grounded text encoder.
- Image encoder에서 얻은 임베딩을 주입하여 visual 정보를 추가해줌
- 이를 위해, cross-attention layer를 추가함
- encoder: Self-attnetion + Cross-attention + FFN
- 각 인코더의 입력으로 들어가는 시퀀스에
[Encoder]를 붙임- 해당 special token은 인코더를 거쳐 이미지 정보가 함께 반영된 텍스트 임베딩이 됨
Image-grounded text decoder.
- Encoder를 decoder처럼 활용하기 위해 self-attention을 masked self-attention으로 교체
- Cross-attention layer 추가하여, image encoder에서 나온 image encoder를 참고함
- 시퀀스에
[Decoder]를 붙여 토큰을 생성할 수 있도록 유도함
(1)-2 Pre-training
- 세 가지 기능을 하는 모델을 학습하기 위해 세 개의 loss를 결합하여 pre-train 함
- 학습은 한 번에 일어나지만, 세 개의 loss 값을 구하기 위해 모델의 '모드'를 바꿔가며 세 번 데이터를 forward pass
- 2개의 understanding-based objective
- Image-Text Contrastive Loss: Image / Text unimodal encoder 학습
- positive image-text pair는 가까워지도록, negative pair는 멀어지도록 contrastive learning 학습함
- Image-Text Matching Loss: image-grounded text encoder 학습
- ITM head를 이용하여 binary-classification task으로 image-text pair가 positive or negative 인지 맞춤
- Image-Text Contrastive Loss: Image / Text unimodal encoder 학습
- 1개의 generation-based objective
- Language Modeling Loss : image-grounded text decoder 학습
- 주어진 이미지에 대한 textual description을 생성하도록 학습함
- cross entropy loss를 이용해 모델을 최적화
- LM loss를 통해 visual 정보를 대응되는 cation으로 변환할 수 있는 능력을 기를 수 있음
- Language Modeling Loss : image-grounded text decoder 학습
(2) Captioning and Filtering (CapFilt)
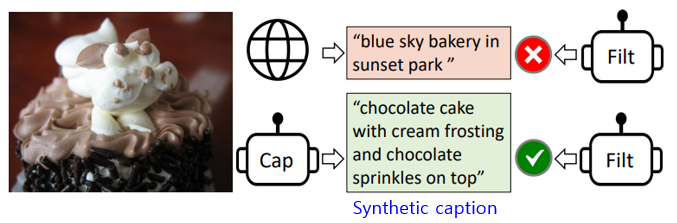
- Web에서 추출한 image-text pair의 한계점
- text가 이미지를 정확하게 묘사하고 있지 않을 때가 있음 (noisy signal)
- 이는 결국, vision-language alignment 학습에 방해가 될 것임
- Text corpus의 quality를 개선하는 방법을 제안함 (CapFilt, Captioning and Filterning)
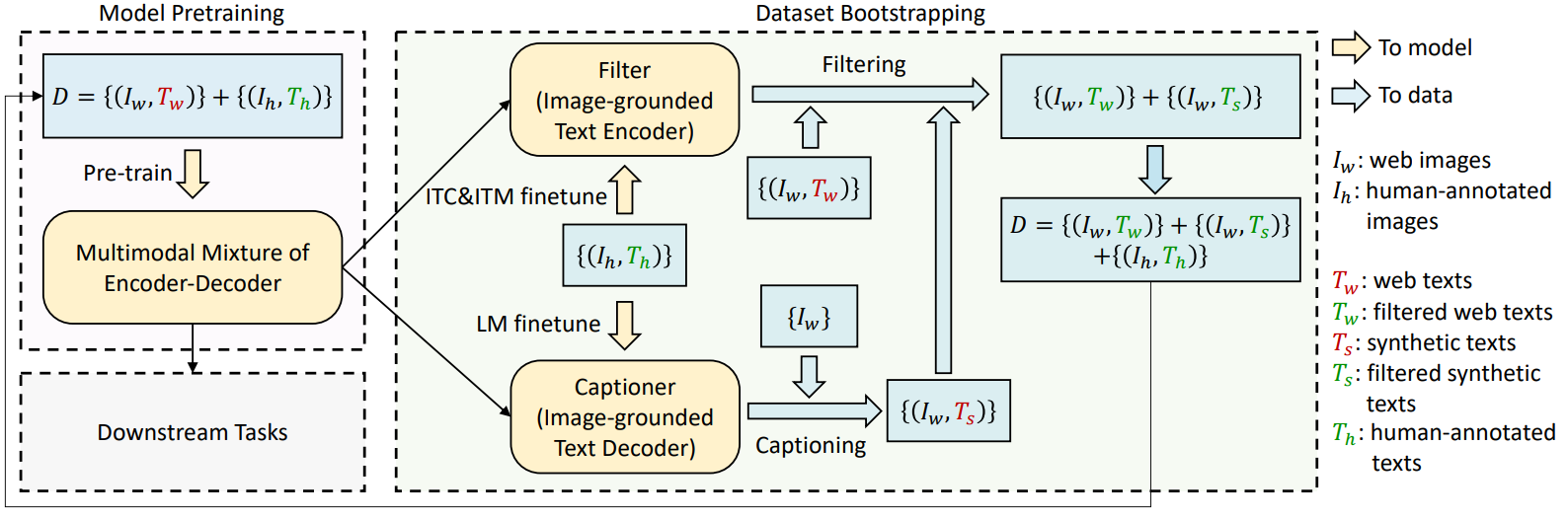
- Captioner: web 이미지에 대한 caption을 생성함
- Filter: noisy한 image-text pair를 제거함
- Step 1: pre-trained MED에게 초기화된 filter와 captioner fine-tuning
- Dataset: COCO dataset(humam-annotated) → 양질의 데이터셋으로 학습
- Captioner: image-grounded text decoder → LM objective로 fine-tune
- Filter: image-grounded text encoder → Image-Text Contrastive Loss, Image-Text Matching Loss로 fine-tune
- Dataset: COCO dataset(humam-annotated) → 양질의 데이터셋으로 학습
- Step 2: Text corpus 퀄리티 개선하기
- Captioner가 web image가 주어졌을 때 이에 대한 caption을 생성 (synthetic caption)
- ITM head를 이용하여, web text, synthetic text와 image와 매칭 여부를 판단 (positive/negative)
- negative로 판정된 데이터는 noisy한 데이터
- positive로 판정된 경우 최종 데이터셋 구성하는 image-text pair로 포함됨
- 최종적으로 얻는 데이터는 web image-filtered text pair + human annotated image-text pair
논문 정보
- Conference: ICML-2022
- Link: https://arxiv.org/abs/2201.12086

비전공자 석사 출신 AI Engineer 취준생(노션에서 벨로그로 이사중 .. 🚗)