ViT: An Image Is Worth 16X16 Words: Transformaers for Image Recognition at Scale
Paper Review
목록 보기
1/4

ViT 핵심 아이디어
(1) 입력 이미지를 패치 단위로 분할
(2) 패치의 embedding을 생성함
(3) 얻은 embedding 시퀀스를 Transformer의 입력으로 넣어줌
→ 이미지 패치를 NLP의 토큰처럼 처리하는 것
ViT 아키텍처
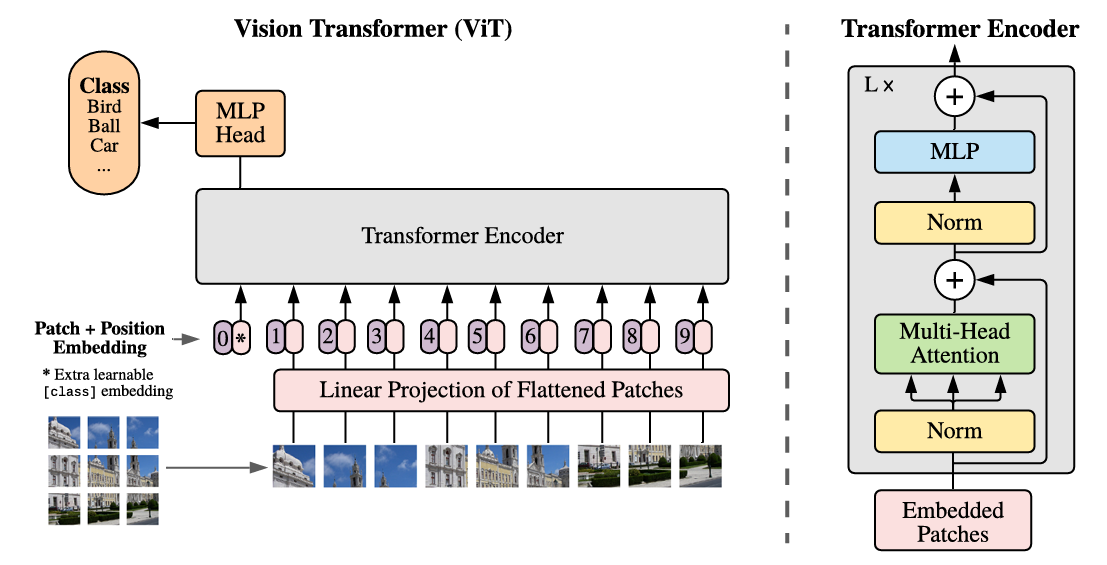
(1) 입력 이미지 처리: 이미지를 패치 시퀀스로 변환
- 기존 Transformer는 1D 토큰 임베딩 시퀀스를 입력으로 받음. 하지만, 이미지 사이즈는 2D
- 해결책: 2D 이미지를 1D 시퀀스로 재구성함
- 원본 이미지:
- 패치 분할:
- : 각 이미지 패치의 해상도
- : 패치 개수 (Transformer의 유효 입력 길이 시퀀스)
- Transformer에 입력되는 시퀀스의 길이는 [CLS] 임베딩까지 개수가 +1 됨
(2) 임베딩 생성
패치 임베딩 생성
- 2D 사이즈의 패치를 flatten 함
- Flatten 결과 하나의 패치:
- Transformer의 모든 layer의 input size인 D차원으로 mapping 함 (trainable linear projection)
- Linear projection: (: Trainable Projection Matrix, 차원: )
CLS Token
- Learnable embedding [CLS]를 임베딩 패치 시퀀스 가장 앞에 추가
- Transformer 인코더 출력에서의 상태 가 이미지 표현 로 사용됨
- 특정 패치를 이미지 representation으로 사용하지 않는 이유 → 특정 정보에 bias 가 들어간 것
- 예: ‘고양이 귀’가 있는 패치 토큰을 골라 전체 이미지의 대표로 사용할 경우, 토큰은 본래 가지고 있던 ‘귀’에 대한 정보와 ‘전체 이미지’에 대한 정보가 섞이게 됨
- [CLS] 토큰은 처음부터 끝까지 모든 패치의 정보와 계산되며, “어떤 정보가 중요한지”를 판단하여 핵심적인 정보를 위주로 토큰 내용을 구성하게 됨
- 특정 패치를 이미지 representation으로 사용하지 않는 이유 → 특정 정보에 bias 가 들어간 것
Position 임베딩
- 앞서 만들어진 임베딩 시퀀스 순서대로 위치 정보를 부여할 수 있는 임베딩을 패치 임베딩에 더해줌
- 2D 이미지에서의 위치 임베딩 정보가 아닌, 1D 시퀀스 정보만 주더라도 성능 확보 가능함
(3) 학습
- 패치 임베딩 + position 임베딩을 Transformer 인코더의 입력으로 사용함
- Transformer 인코더를 거친 [CLS] 토큰인 로 classification 학습
- Pre-train: 하나의 hidden layer를 가진 MLP
- Fine-tuning: 단일 linear layer

비전공자 석사 출신 AI Engineer 취준생(노션에서 벨로그로 이사중 .. 🚗)