
Background
NLP 분야에서의 학습
- NLP 분야에서 raw text로부터 pre-training 하는 방법이 큰 발전을 가지고 옴
- 더하여, text-to-text 인터페이스의 개발은 범용성을 확보하며, 특정 downstream dataset에 대한 zero-shot이 가능하고, 특화된 crowd-labeld dataset이 필요하지 않음을 보임
기존 CV의 한계
- ImageNet과 같은 crowd-labeled 데이터셋에서 모델을 사전학습하는 것이 관행임
- 학습된 정답 class 외에는 인식하지 못하는 폐쇄적인 시스템임
- text로부터 image representation을 학습하는 시도도 있었음
Scale의 중요성
- NLP 분야에서 pre-train 방법의 성공을 이끌었던, web으로부터 수집된 방대한 양의 데이터셋을 바탕으로, (image, text) 데이터를 web으로부터 만드는 시도를 함
CLIP 핵심 아이디어
(CLIP, Contrastive Language-Image Pre-training)
- Natural Language supervision
- 정해진 class가 아닌, web 상의 방대한 텍스트 정보를 학습 신호로 활용함
- Image representation이 무엇인가에 대한 정보를 텍스트로부터 얻어 학습하게 됨
- Contrastive learning
- 이미지와 그에 대응하는 텍스트 쌍은 가깝게, 관련 없는 쌍은 멀게 위치하도록 학습함
- Scalability
- 4억 개의 (image, text) 쌍으로 구성된 WIT(WebImage Text) 데이터셋을 구축하여 사용함
CLIP 학습
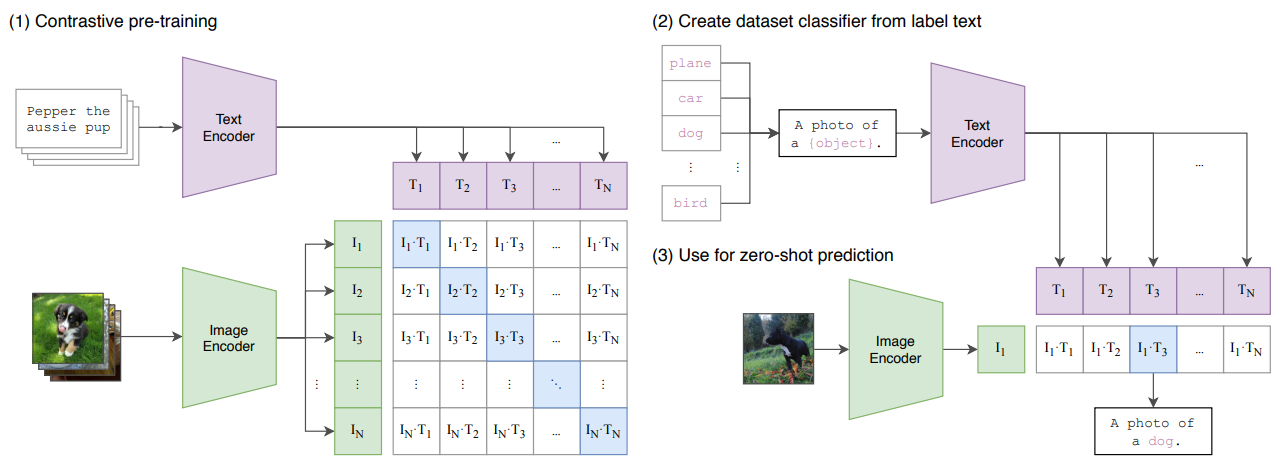
(1) Contrastive pre-training
- 배치 N개에 대한 contrastive learning 진행
- Step 1: 배치 임베딩 얻기
- Text Encoder로 얻은 N개의 text 임베딩, Image Encoder로 얻은 N개의 image 임베딩
- Text Encoder: Transformer
- Image Encoder: ViT 등등 (큰 모델일수록 효율성이 더 좋았음)
- Text Encoder로 얻은 N개의 text 임베딩, Image Encoder로 얻은 N개의 image 임베딩
- Step 2: image encoder와 text encoder 함께 학습
- 앞서 얻은 N쌍의 배치 임베딩 (image emb., text emb.) 을 contrastive learning으로 학습
- Image emb와 text emb dot product → multi-modal embedding space: N x N
- 대각 행렬의 cosine similarity는 최대가 되도록 학습함
- 대각 행렬을 제외한 개의 값들은 최소화 되도록 학습함
- Step 1: 배치 임베딩 얻기
(2) Image / Text Encoder
- Image Encoder
- ViT
- Text Encoder: Masked Self-Attention (Transformer 디코더)
- Auto-regressive 모델의 특징을 그대로 사용함
- 시퀀스의 각 토큰이 자기 자신보다 뒤에 나오는 미래의 토큰들을 보지 못하도록 가림
- [SOS][EOS] 토큰을 사용하고, [EOS] 토큰은 텍스트의 정보를 담고 있도록 인코딩 됨
- [EOS] 토큰보다 앞에 나온 모든 단어들을 참조할 수 있음 → 특정 단어의 의미에 치우치지 않고, 문장 전체의 문맥을 통합하여 학습하도록 설계된 것임
논문 정보
- Conference: ICML-2021
- Link: 링크

비전공자 석사 출신 AI Engineer 취준생(노션에서 벨로그로 이사중 .. 🚗)