그래프의 탐색이란?
-
그래프의 탐색 : 하나의 정점으로부터 시작하여 차례대로 모든 정점들을 한 번씩 방문하는 것
Ex) 특정 도시에서 다른 도시로 갈 수 있는지 없는지, 전자 회로에서 특정 단자와 단자가 서로 연결되어 있는지 확인
깊이 우선 탐색 : DFS(Depth-First Search)란?

-
정의 : 그래프의 탐색 알고리즘 중 하나로 루트 노드(혹은 다른 임의의 노드)에서 시작해서 다음 분기(branch)로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법
EX) 미로를 탐색할 때 한 방향으로 갈 수 있을 때까지 계속 가다가 더 이상 갈 수 없게 되면 다시 가장 가까운 갈림길로 돌아와서 이곳으로부터 다른 방향으로 다시 탐색을 진행하는 방법과 유사하다.
- DFS의 특징
- 넓게(wide) 탐색하기 전에 깊게(deep) 탐색
- 모든 노드를 방문하고자 하는 경우에 이 방법을 선택한다
- 깊이 우선 탐색(DFS)이 너비 우선 탐색(BFS)보다 좀 더 간단하다
- 검색 속도 자체는 너비 우선 탐색(BFS)에 비해서 느리다
- 자기 자신을 호출하는 순환 알고리즘의 형태를 지님
- DFS 알고리즘을 구현할 경우 어떤 노드를 방문했었는지 여부를 반드시 검사해야한다 (이를 검사하지 않을 경우 무한루프에 빠질 위험이 있다)
DFS(Depth-First Search)의 탐색 과정
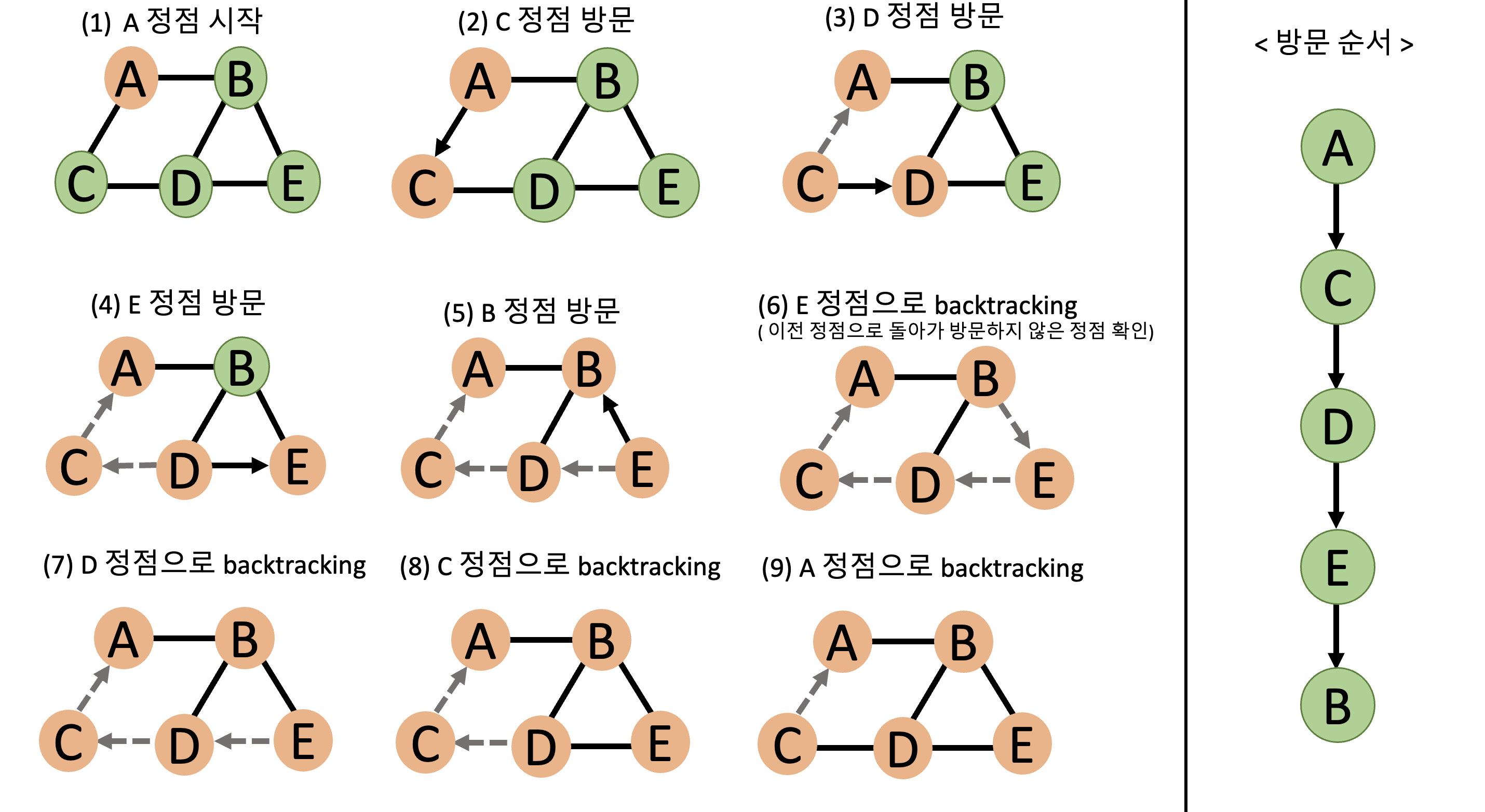
-
정점
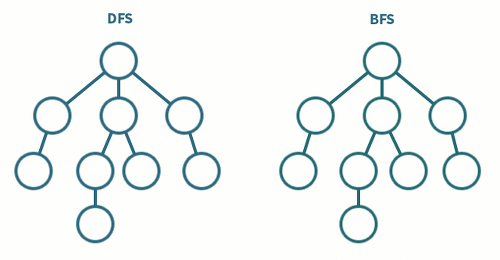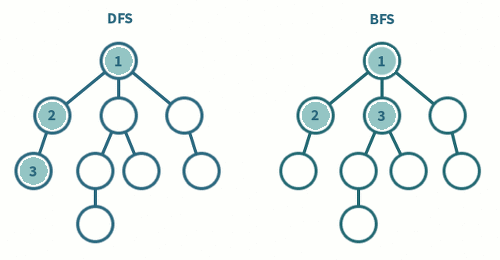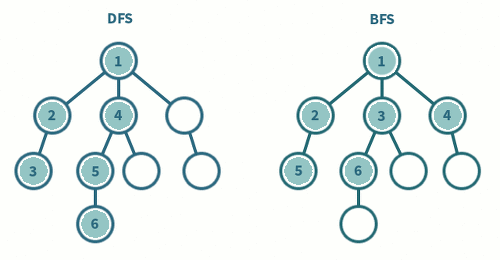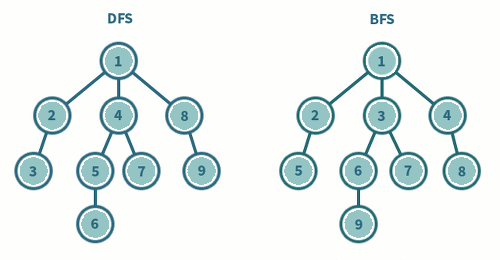
A로 부터 시작 -
정점
C를 방문 -
정점
D를 방문 -
정점
E를 방문 -
정점
B를 방문 -
정점
E로 돌아와 인접 정점 중 방문하지 않은 정점을 확인 -
정점
D로 돌아와 인접 정점 중 방문하지 않은 정점을 확인 -
정점
C로 돌아와 인접 정점 중 방문하지 않은 정점을 확인 -
정점
A로 돌아와 인접 정점 중 방문하지 않은 정점을 확인 -
탐색 완료
방문 순서 :
A→C→D→E→B
DFS(Depth-First Search)의 구현
- DFS의 구현에서 방문 순서를 기억할때 스택 자료구조를 이용한다.
- 스택을 사용하는 이유?
- DFS에서 방문 이후 방문 순서에 맞추어 다시 정점으로 돌아와 방문하지 않은 정점을 확인하여야 하기 때문에 재귀적 호출이 필요로 하며 재귀 호출을 위해 스택을 이용하는 것 이다.
- 스택을 사용하는 이유?
-
구현 방법
-
탐색 시작 노드를 스택에 삽입하고, 방문 처리한다.
-
스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면 그 인접 노드를 스택에 넣고 방문 처리하고, 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼낸다.
-
위의 1번과 2번 과정을 더 이상 수행할 수 없을 때까지 반복한다.
- ‘방문 처리': 스택에 한 번 삽입되어 처리된 노드가 다시 삽입되지 않게 체크하는 것을 의미한다. 이를 통해 각 노드를 한 번씩만 처리할 수 있다.
-
-
구현 코드
class dfsByStack { boolean sizeSetting; // 초기 세팅 Stack<Integer> stack; // 재귀적 방법을 위한 스택 HashSet<Integer> visited; // 방문 기록 ArrayList<Integer> result; // 결과 리스트 dfsByStack() { sizeSetting = false; } public List<Integer> dfs(int[][] graph, int startNode) { if (!sizeSetting) { // 초기 세팅 visited = new HashSet(); stack = new Stack<>(); result = new ArrayList<>(graph.length - 1); sizeSetting = true; } visited.add(startNode); stack.push(startNode); while (!stack.isEmpty()) { Integer node = stack.pop(); result.add(node); for (int vertex : graph[node]) { if (!visited.contains(vertex)) { stack.push(vertex); visited.add(vertex); } } } sizeSetting = false; // 초기 설정값 false return result; } }
깊이 우선 탐색(DFS)의 시간 복잡도
- DFS는 그래프(정점의 수 : V, 간선의 수: E)의 모든 간선을 조회함
- 시간 복잡도 : O(V+E)
BFS(Breadth-First Search)란?
-
정의 : 그래프의 탐색 알고리즘 중 하나로 루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법
Ex) 지구 상에 존재하는 모든 친구 관계를 그래프로 표현한 후 A 와 B 사이에 존재하는 경로를 찾는 경우
- BFS의 특징
- 깊게(deep) 탐색하기 전에 넓게(wide) 탐색하는 방법
- 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 이 방법을 선택한다
- BFS는 DFS와 달리 재귀적으로 동작하지 않는다.
- BFS 는 방문한 노드들을 차례로 저장한 후 꺼낼 수 있는 자료 구조인 큐(Queue)를 사용하여 선입선출(FIFO) 원칙으로 탐색한다.
- 시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져 있는 정점을 나중에 방문하는 순회 방법
- BFS 알고리즘을 구현 경우 어떤 노드를 방문했었는지 여부를 반드시 검사해야한다 (이를 검사하지 않을 경우 무한 루프에 빠질 위험이 있다)
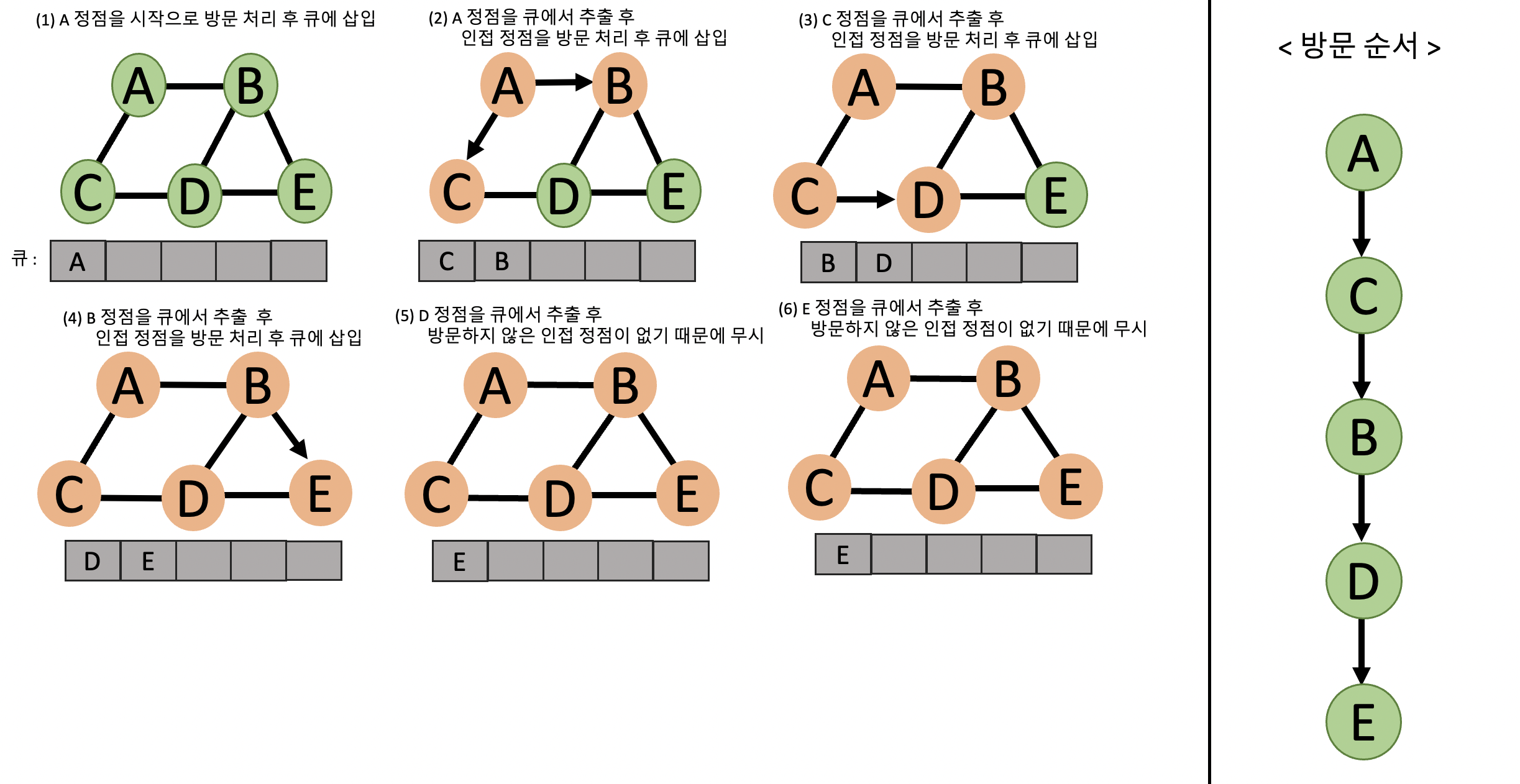
BFS(Breadth-First Search)의 탐색 과정
-
정점
A를 시작으로 방문 처리 이후 큐에 삽입 -
정점
A를 큐에서 뽑아 내고 인접 정점C,B를 방문 처리 후 큐에 삽입 -
정점
C를 큐에서 뽑아 내고 인접 정점D를 방문 처리 후 큐에 삽입
( 이미 방문한A정점은 무시한다. ) -
정점
B를 큐에서 뽑아 내고 인접 정점E를 방문 처리 후 큐에 삽입
( 이미 방문한A,D정점은 무시한다. ) -
정점
D를 큐에서 뽑아 내고 방문하지 않은 인접 정점이 없기 때문에 무시 -
정점
E큐에서 뽑아 내고 방문하지 않은 인접 정점이 없기 때문에 무시 -
탐색 완료
방문 순서 :
A→C→B→D→E
BFS(Breadth-First Search)의 구현
- BFS(Breadth First Search)의 약자로 ‘너비 우선 탐색’ 알고리즘을 의미한다.
- 즉, 가까운 노드부터 탐색하는 알고리즘이다.
- 최대한 멀리 있는 노드를 우선으로 탐색하는 DFS와는 반대이다.
- BFS의 구현에서는 선입선출 방식인 큐 자료구조를 이용하는 것이 정석이다.
- 큐를 사용하는 이유?
- 큐를 이용하여 알고리즘을 작성하면 자연스럽게 먼저 들어온 것이 먼저 나가며, 가까운 노드부터 탐색하게 되기 때문이다.
- 큐를 사용하는 이유?
- 구현방법
-
탐색 시작 노드를 큐에 삽입하고 방문 처리한다.
-
큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리한다.
-
위의 1번과 2번 과정을 더 이상 수행할 수 없을 때까지 반복한다.
-
구현코드
class bfsByQueue { boolean sizeSetting; HashSet<Integer> visited; Queue<Integer> queue; ArrayList<Integer> result; bfsByQueue() { sizeSetting = false; } public List<Integer> bfs(int[][] graph, int startNode) { if (!sizeSetting) { visited = new HashSet<>(); result = new ArrayList<>(graph.length); queue = new LinkedList<>(); sizeSetting = true; } result.add(startNode); visited.add(startNode); queue.add(startNode); while (!queue.isEmpty()) { Integer visitedNode = queue.poll(); for (Integer vertex : graph[visitedNode]) { if (!visited.contains(vertex)) { result.add(vertex); visited.add(vertex); queue.add(vertex); } } } sizeSetting = false; return result; } }
너비 우선 탐색(BFS)의 시간 복잡도
- BFS는 그래프(정점의 수 : V, 간선의 수: E)의 모든 간선을 조회함
- 시간 복잡도 : O(V+E)
DFS vs BFS
| - | DFS | BFS |
|---|---|---|
| 동작방식 | 한 방향으로 깊이 탐색하다 없으면 돌아와 탐색 | 루트 노드부터 인접 노드들을 방문하고 해당 노드들의 인접 노드를 차례로 탐색 |
| 동작 원리 | 재귀적 방식을 이용 | 큐를 이용하여 인접 노드 탐색 |
| 구현 방식 | 재귀함수나 스택을 이용 | 큐 이용 |
| 시간 복잡도 | O(V+E) | O(V+E) |
