지금까지 항해를 하면서 개념정리 하나는 예쁘게 잘 할 수 있을 것같음.
하지만 문제는 그게 머릿속에 있다는게 아님ㅎ..
완전하게 내 것으로 만들기 위해 더욱 노력하자!
아직도 MySQL을 쓰기에 어려워한다는게 속상할 따름이다..
몽고DB에 너무 익숙해져있는 탓에 변화가 어렵구만!
하지만 해야지 어쩌겠어..
나자신 화이팅!😖
(TMI하나 하자면, ORM 개념정리하면서 계속 OMR이라고해서 자꾸 컴싸꺼내야할 것같음)
ORM(Object Relational Mapping)
객체-관계 매핑의 줄임말이다.
객체-관계 매핑을 풀어서 설명하자면 우리가 OOP(Object Oriented Programming)에서 쓰이는 객체라는 개념을 구현한 클래스와 RDB(Relational DataBase)에서 쓰이는 데이터인 테이블자동으로 매핑(연결)하는 것을 의미한다.
그러나 클래스와 테이블은 서로가 기존부터 호환가능성을 두고 만들어진 것이 아니기 때문에 불일치가 발생하는데,
이를 ORM을 통해 객체 간의 관계를 바탕으로 SQL문을 자동으로 생성하여 불일치를 해결한다.
따라서 ORM을 이용하면 따로 SQL문을 짤 필요없이 객체를 통해 간접적으로 데이터베이스를 조작할 수 있게 된다.
Sequelize
Postgres, MySQL, MariaDB, SQLite 등을 지원하는Promise에 기반한 비동기로 동작하는 Node.js ORM이다.
관계형 DB(SQL) - 구조화 된 쿼리언어
테이블, 행, 열을 가진 DB에 A데이터와 B데이터가 있다고 가정하면,
A데이터에 B데이터의 위치를 저장하는 방식으로,
행과 열로 구성된 테이블과의 관계를 나타낼 때 사용한다.
Mysql, Oracle, Mssql
앱의 여러 부분에서 관련 데이터가 비교적 자주 변경되는 경우 사용하기 좋음
(NoSQL이라면 항상 여러 컬렉션을 수정해야 함)명확한 스키마가 중요하며, 데이터구조가 극적으로 변경되지 않을때 사용
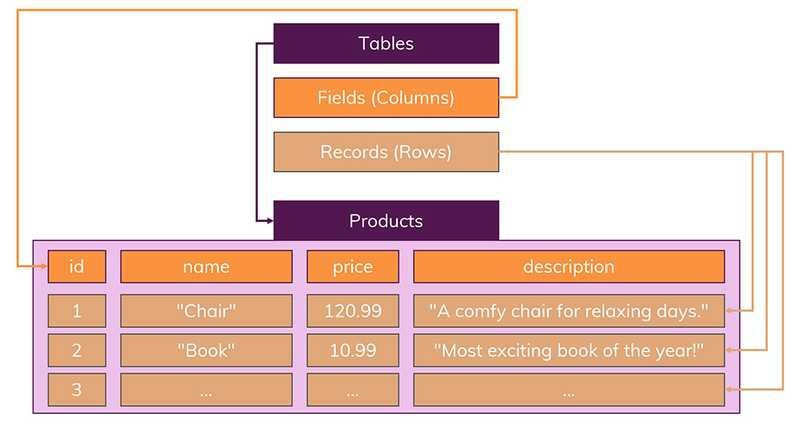
📍특징
- 트랜잭션(전부 아니면 무) : 전체 트랜잭션이 하나의 단위로 기록. 실패 시 전체 롤백
- 정규화: DB설계 시 중복을 최소화해서 구조화하는 프로세스
(데이터들을 여러 테이블로 나누어 저장)
장점
- 데이터의 성능이 일반적으로 좋아 정렬, 탐색, 분류가 빠름
- 신뢰성이 높아 데이터의 무결성을 보장(명확하게 정의된 스키마)
- 정규화에 따른 따른 갱신 비용을 최소화
단점
- 기존에 작성된 스키마를 수정하기 어려움
- 데이터베이스의 부하를 분석하기 어려움
(JOIN문이 많은 경우 매우 복잡한 쿼리가 만들어 질 수 있다.) - 빅데이터를 처리하는데 매우 비효율적
(수평 확장이 어렵고, 보통 수직 확장만 가능! - 어느 시점에서 처리량 & 처리 능력과 관련하여 성장의 한계에 직면)
비관계형 DB(NoSQL)
관계형 데이터베이스보다 더 융통성 있는 데이터 모델을 사용하며, 데이터의 저장 및 검색에 특화된 메커니즘을 제공.
분산환경에서의 데이터 처리를 더욱 빠르게 하기 위해 개발되었다.
MongoDB, CouchDB 등
정확한 데이터 요구사항을 알 수 없거나 관계를 맺고 있는 데이터가 자주 변경(수정)되는 경우 사용
읽기(Read)처리를 자주 하지만, 데이터를 자주 변경하지 않는 경우 사용
(한번의 변경으로 수십 개의 문서를 수정 할 필요가 없는 경우)데이터베이스를 수평으로 확장해야 하는 경우 사용
(막대한 양의 데이터를 다뤄야 하는 경우, 읽기/쓰기 처리량이 큰 경우)

📍특징
- 거대한 Map으로서 key-value 형식을 지원한다.
- 관계형 db와 달리 PK, FK, JOIN등 관계를 정의하지 않는다.
- 스키마에 대한 정의가 없다.
장점
- 대용량 데이터 처리를 하는데 효율적이다.
- 읽기 작업보다 쓰기 작업이 더 빠르고 관계형 데이터베이스에 비해 쓰기와 읽기 성능이 빠르다.
(수직 및 수평 확장이 가능하다.) - 데이터 모델링이 유연하다.
(스카마가 없기 때문에 저장된 데이터를 언제든지 조정하고 새로운 필드 추가 가능!) - 뛰어난 확장성으로 검색에 유리하다.
- 최적화된 키 값 저장 기법을 사용하여 응답속도나 처리 효율 등에서 성능이 뛰어나다.
- 복잡한 데이터 구조를 표현할 수 있다.
단점
- 쿼리 처리시 데이터를 파싱 후 연산을 해야해서 큰 크기의 document를 다룰 때는 성능이 저하된다.
