class NeRF(nn.Module):
def __init__(self, D=8, W=256, input_ch=3, input_ch_views=3, output_ch=4, skips=[4], use_viewdirs=False):
"""
"""
super(NeRF, self).__init__()
self.D = D
self.W = W
self.input_ch = input_ch
self.input_ch_views = input_ch_views
self.skips = skips
self.use_viewdirs = use_viewdirs
self.pts_linears = nn.ModuleList(
[nn.Linear(input_ch, W)] + [nn.Linear(W, W) if i not in self.skips else nn.Linear(W + input_ch, W) for i in range(D-1)])
### Implementation according to the official code release (https://github.com/bmild/nerf/blob/master/run_nerf_helpers.py#L104-L105)
self.views_linears = nn.ModuleList([nn.Linear(input_ch_views + W, W//2)])
### Implementation according to the paper
# self.views_linears = nn.ModuleList(
# [nn.Linear(input_ch_views + W, W//2)] + [nn.Linear(W//2, W//2) for i in range(D//2)])
if use_viewdirs:
self.feature_linear = nn.Linear(W, W)
self.alpha_linear = nn.Linear(W, 1)
self.rgb_linear = nn.Linear(W//2, 3)
else:
self.output_linear = nn.Linear(W, output_ch)
def forward(self, x):
input_pts, input_views = torch.split(x, [self.input_ch, self.input_ch_views], dim=-1)
h = input_pts
for i, l in enumerate(self.pts_linears):
h = self.pts_linears[i](h)
h = F.relu(h)
if i in self.skips:
h = torch.cat([input_pts, h], -1)
if self.use_viewdirs:
alpha = self.alpha_linear(h)
feature = self.feature_linear(h)
h = torch.cat([feature, input_views], -1)
for i, l in enumerate(self.views_linears):
h = self.views_linears[i](h)
h = F.relu(h)
rgb = self.rgb_linear(h)
outputs = torch.cat([rgb, alpha], -1)
else:
outputs = self.output_linear(h)
return outputs input_pts, input_views = torch.split(x, [self.input_ch,self.input_ch_views], dim=-1)
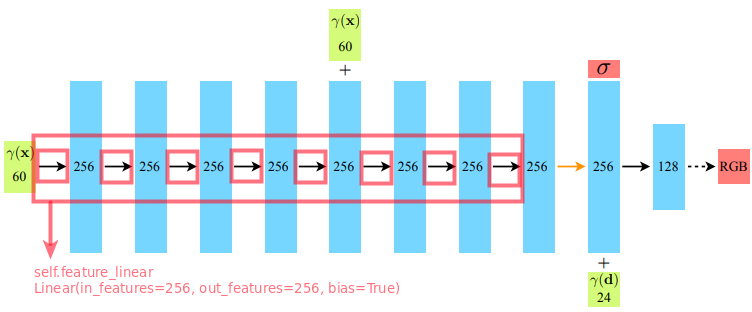
- 코드해석
- input_pts : rays_o에 해당하는 ray 위치 정보. shape = [1024*64, 63] 아마 60+3(?)
- input_views : rays_d에 해당하는 ray의 방향 정보 shape = [1024*64, 27] 아마 24+3(?)
for i, l in enumerate(self.pts_linears): h = self.pts_linears[i](h) h = F.relu(h) if i in self.skips: h = torch.cat([input_pts, h], -1)
- 코드해석
- self.pts_linears type: 'torch.nn.modules.container.ModuleList'
- NeRF 모델에서 rays_o(논문에서 ) 정보를 추가적으로 받는 network 까지의 5개의 fully-connected network 이다.
- Activation function으로 ReLU를 사용하였다.
- i가 self.skips 안에 해당되면, rays_o에 해당하는 inputs_pts가 fully connected network의 output인 h와 concatenate 되어 다시 network에 입력된다.
-
if self.use_viewdirs: alpha = self.alpha_linear(h) feature = self.feature_linear(h) h = torch.cat([feature, input_views], -1) for i, l in enumerate(self.views_linears): h = self.views_linears[i](h) h = F.relu(h) rgb = self.rgb_linear(h) outputs = torch.cat([rgb, alpha], -1) else: outputs = self.output_linear(h)
-
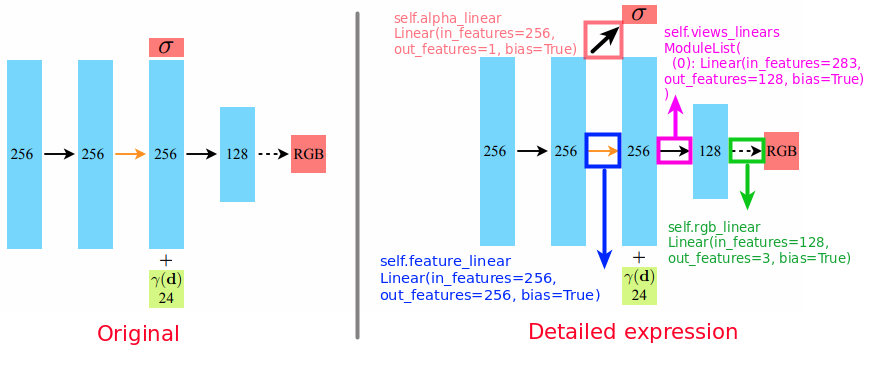
코드 해석
-
alpha = self.alpha_linear(h)
- Volume Density()를 output으로 뽑는다. Paper의 그림으로만 보았을 때, Activation function 없이 바로 feature extraction 하였을 때, Volume density값과 256 dimension의 feature가 exreact 될 것 같은데, 실제 코드에서는 그렇지 않았다.
'Detailed expression' 그림을 참조해서 코드를 설명하면, activation function skip 과정 전 단계에서 input feature가 256, output feature가 1로 뽑히는 것을 확인할 수 있다. Paper 에서도 'volume density (which is rectified using a ReLU to ensure that the output volume density is nonegative)'라고 명시되어 있다.

- Volume Density()를 output으로 뽑는다. Paper의 그림으로만 보았을 때, Activation function 없이 바로 feature extraction 하였을 때, Volume density값과 256 dimension의 feature가 exreact 될 것 같은데, 실제 코드에서는 그렇지 않았다.
-
feature = self.feature_linear(h)
- Activation Function 없이 feature extraction을 진행한다. Paper의 그림에서 주황색 화살표에 해당한다.
-
h = self.views_linears[i](h)
- ray의 direction 값을 256 dimension feature와 concatenate하여 linear layer에 input으로 넣어준다. 283 dimension의 input을 받는다.
256(feature dim) + 24(direction dim - embedded by encoding) + 3(original direction) = 283
- ray의 direction 값을 256 dimension feature와 concatenate하여 linear layer에 input으로 넣어준다. 283 dimension의 input을 받는다.
-
rgb = self.rgb_linear(h)
- 128 dimension의 feature를 통해서 3 dimension인 RGB 값을 계산한다.
-

Coputer vision, AI