#all tensors of each operation should be in same device
class Module(nn.Module):
def __init__(self):
super().__init__()
self.network = nn.Sequential(nn.Linear(1000, 1000), nn.Linear(1000, 100))
def forward(self, x):
return self.network(x)다음과 같이 module이 정의될 때, 아래와 같이 연산을 진행해보았다.
module = Module().to(0)
x = torch.zeros(1000, 1000).to(0)
module(x)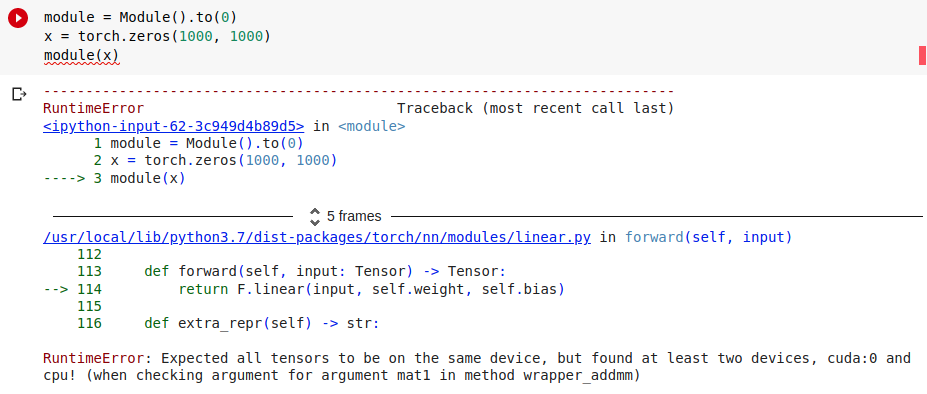
module에서 to(0)연산을 통해 module의 parameter를 GPU로 보냈지만, x는 여전히 cpu에 남아있기 때문에
'RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!' 에러가 발생하였다.
module = Module().to(0)
x = torch.zeros(1000, 1000)
module(x)
똑같이 x의 device를 GPU로 보내주면, device에서 없이 연산이 잘 된 것을 확인할 수 있다.

Coputer vision, AI