optimizer.zero_grad()는 왜 사용하는가?

optimizer.zero_grad()는 왜 사용하는가?
답은 간단하다. loss.backward()를 통해서 tensor의 gradient가 연산될 때, gradient값이 축적되는걸 막아주기 위해서이다.
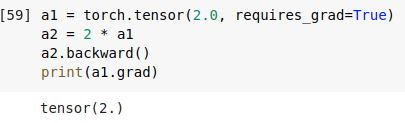
다음과 같이 으로 정의한 후, backward()를 진행하면, print(a1.grad)를 통해서 a1의 gradient를 알 수 있다. a1.grad의 결과가 tensor(2.)로 나온 것을 확인할 수 있다.
하지만, 똑같이 a2.backward()를 실행해주면,
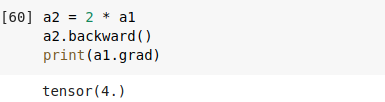 다음과 같이 a1의 gradient값이 4로 나온 것을 확인할 수 있다.
다음과 같이 a1의 gradient값이 4로 나온 것을 확인할 수 있다.
원래는 이기 때문에 a1.grad값이 2가 나와야 하지만 optimizer.zero_grad()를 통해서 gradient 값이 축적되는 걸 막지 않았기 때문에, a1.grad 값이 4가 나온 것을 확인할 수 있다.

Coputer vision, AI