
Aurora
Aurora의 DB cluster는
하나 이상의 DB 인스턴스 + 이 인스턴스의 데이터를 관리하는 클러스터 볼륨으로 구성된다. 이 때, 클러스터 볼륨은 다중 가용 영역을 아우르는 가상 데이터베이스 스토리지 볼륨이다. 각 가용 영역에는 DB 클러스터 데이터의 사본이 있다.
Aurora DB 인스턴스 구성
-
기본 DB 인스턴스(primary): Aurora DB 클러스터마다 기본 1개씩은 인스턴스를 가짐
→ 읽기 및 쓰기 작업을 지원
→ 클러스터 볼륨의 모든 데이터 수정
-
Aurora 복제본(replica): 여러개(다중 가용영역)
→ 읽기 작업만 지원함
-
Aurora 클러스터 볼륨: 다중 가용영역을 아우르는 가상 데이터베이스 스토리지 볼륨
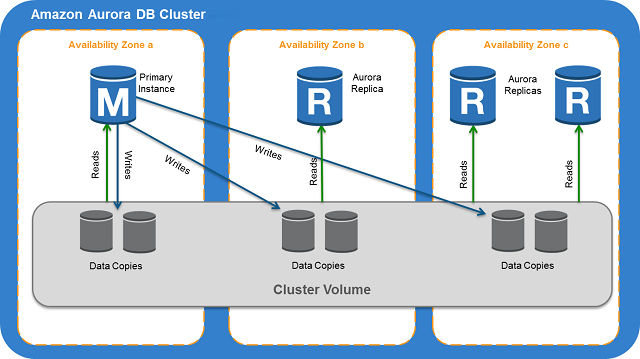
Aurora의 DB 클러스터는 기본 DB 인스턴스와 Aurora 복제본으로 구성된다. 각 가용 영역(AZ a, AZ b, AZ c...)마다 primary instance에 대한 복제본인 replicas가 존재하며 이 복제본은 최대 15개까지 구성될 수 있다.
또한, 각 복제본은 서로 별도의 가용영역에 배치되어 “고가용성”을 확보할 수 있다. 복제본들은 기본 DB 인스턴스와 동일한 스토리지 볼륨에 연결되며 읽기 작업만 지원한다.
Aurora는 기본 DB 인스턴스를 사용할 수 없으면 자동으로 복제본으로 장애 조치를 하기 때문에 여러 복제본 중 장애 조치 우선 순위를 지정할 수 있다.
Aurora는 mysql 및 postgresql과 호환되는 완전 관리형 관계형 데이터베이스 엔진으로, 관리형 데이터베이스 서비스(amazon rds)의 일부이다.
→ rds와 aurora의 가장 큰 차이점은 ‘스토리지’임
특징
-
DB 사용 용량이 늘어나면 Aurora 클러스터 볼륨은 자동으로 확장되며 최대 128tebibytes(TiB)까지 증가할 수 있다.
→ TiB는 2의 40승 bytes에 해당한다.
→ 요금은 Aurora 클러스터 볼륨에서 사용한 공간에 대해서만 청구 된다.
-
Aurora는 주요 목표가 안정성과 고가용성인 데이터베이스를 구축할 목적으로 사용하는 것이 좋다.
MySQL과 Aurora의 스토리지 저장 방식 비교
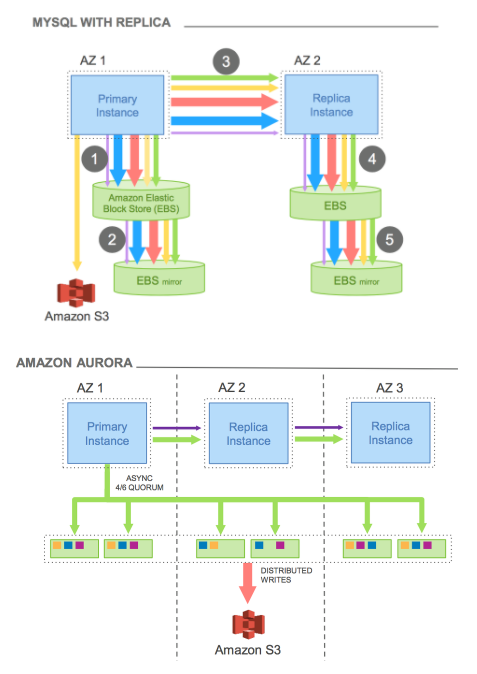
- mysql의 경우 자신의 EBS(Elastic Block Storage)로 데이터를 쌓고, 미러링 하여 replica로 데이터를 전송하며 이후 replica는 전송받은 데이터를 자신의 EBS에 저장함
- aurora는 4/6쿼럼(write 4/6 쿼럼: 6개 중 4개의 스토리지에 write 성공해야 완료)을 사용해 스토리지를 저장하고 replica로 보내 해당 데이터를 공유한다. 이 덕분에, 네트워크 사용률이 적고 또한 데이터를 빠르게 저장하는 것이 가능함. 또한, 단일 스토리지가 아닌 샤드 스토리지를 사용함
→ aurora는 mysql을 기존 처리량 대비 5배, postgresql을 기존 처리량을 대비 최대 3배 제공할 수 있다고 한다.
기존의 Mysql은 아래와 같이 2대의 인스턴스가 Master-Slave 구조인 HA 구성이라면,
Aurora의 경우는 Cluster 구조로 Writer-Reader 구조이다.
그렇다면 DB 이중화 구성에 해당하는 Master-Slave는 어떤 것일지 궁금해서 찾아봤다.
DB 이중화 구성
Master & Slave
-
Master: Master는 등록/수정/삭제 쿼리 요청이 있을 때 binarylog를 생성해 slave로 전달한다.
-
Slave: Master의 정보를 복제해 놓는 역할을 하며, 읽기 쿼리 요청을 담당함
→ 쿼리 요청을 master와 slave가 분담하여 db 부하를 분산할 수 있음
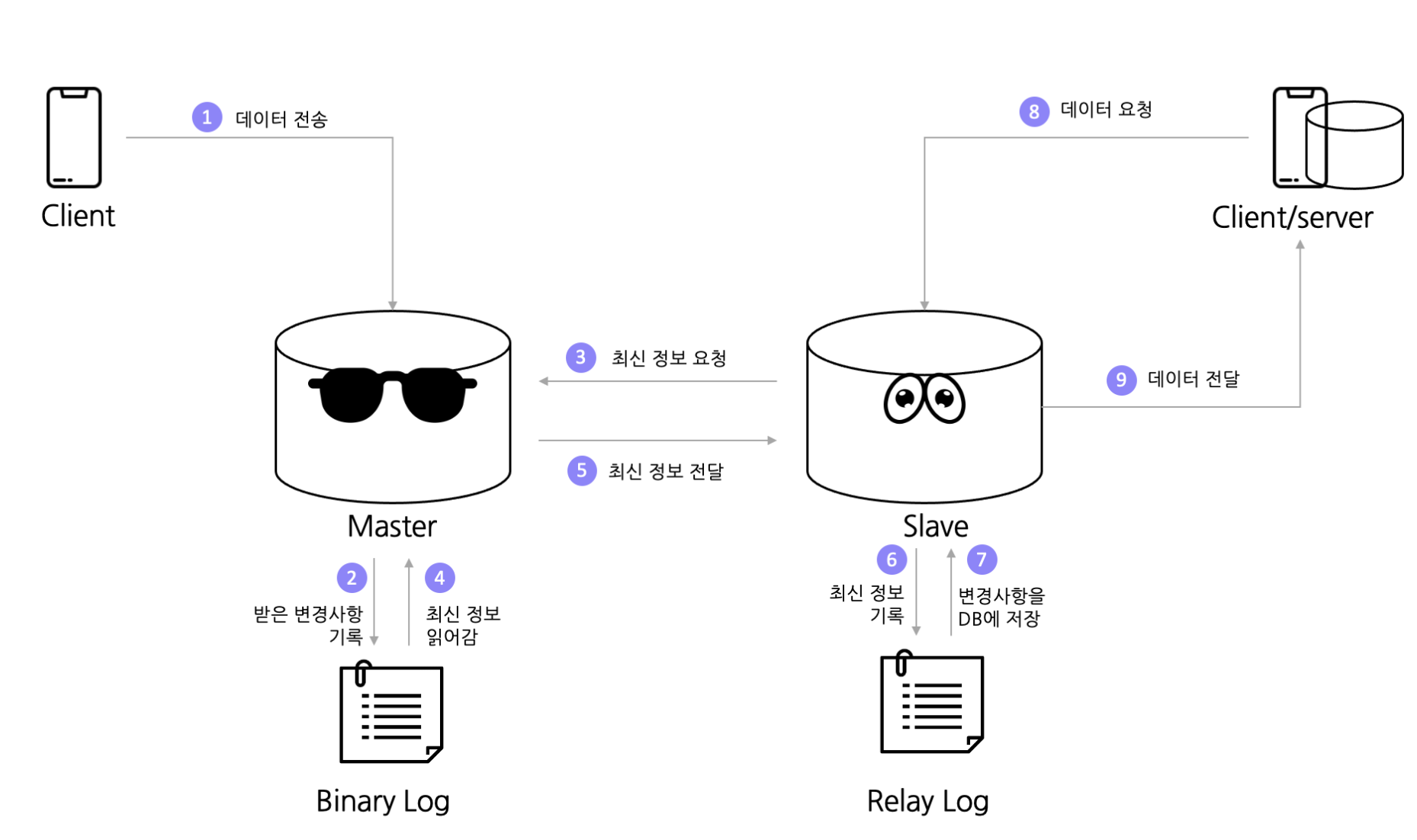
둘의 관계를 보면, master는 전송된 데이터를 slave보다 먼저 저장하고 가지고 있으며
slave는 해당 데이터를 요청해 변경사항을 저장해 놓고, 요청이 있을시 클라이언트에 전달해 준다.
Master와 Slave는 다음과 같이 상호작용 한다.
- 클라이언트가 마스터 db에 데이터를 전송한다.
- 마스터는 받은 데이터를 binary log에 일단 기록하고 나중에 db에 업데이트를 한다.
- 이와 동시에 slave가 master로부터 최신 데이터를 요청한다.
- 마스터는 binary log에 적어 놓았던 최신 정보를
- slave로 전달한다.
- 그러면 slave는 최신 정보를 relay log에 기록해 두고
- 나중에 한 번에 db에 모든 변경사항을 저장한다.
- 다른 클라이언트가 마스터에 저장해둔 데이터를 요청하면
- slave는 미리 저장해서 동기화된 데이터를 클라이언트에 전달한다.
하지만, 데이터 쌓이는 양이 갑자기 늘어나게 되면 마스터가 슬레이브에게 데이터를 제 때 주지 못하게 될 수 있으며, 이 때 복제 지연이 발생할 수 있다.
→ 예를 들어 블프 때 주문 조회가 갑자기 늘어나게 되면 마스터는 계속해 데이터를 받게 되며 slave와 싱크가 맞지 않는 순간이 생길 수 있다.
그러면 slave에 데이터 요청이 들어오더라도 제대로 된 정보를 주지 못하게 될 수 있다(데이터 누락).
-> 이럴 때를 대비해 슬레이브에서 지연으로 데이터가 없으면, 마스터로 쿼리 하도록 만들어야 한다!
참고
1) 블로그
https://brunch.co.kr/@b30afb04c9f54dc/2
2) aws 공식문서
https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.StorageReliability.html
